VLA Foundry: A Unified Framework for Training Vision-Language-Action Models
Abstract: We present VLA Foundry, an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. Most open-source VLA efforts specialize on the action training stage, often stitching together incompatible pretraining pipelines. VLA Foundry instead provides a shared training stack with end-to-end control, from language pretraining to action-expert fine-tuning. VLA Foundry supports both from-scratch training and pretrained backbones from Hugging Face. To demonstrate the utility of our framework, we train and release two types of models: the first trained fully from scratch through our LLM-->VLM-->VLA pipeline and the second built on the pretrained Qwen3-VL backbone. We evaluate closed-loop policy performance of both models on LBM Eval, an open-data, open-source simulator. We also contribute usability improvements to the simulator and the STEP analysis tools for easier public use. In the nominal evaluation setting, our fully-open from-scratch model is on par with our prior closed-source work and substituting in the Qwen3-VL backbone leads to a strong multi-task table top manipulation policy outperforming our baseline by a wide margin. The VLA Foundry codebase is available at https://github.com/TRI-ML/vla_foundry and all multi-task model weights are released on https://huggingface.co/collections/TRI-ML/vla-foundry. Additional qualitative videos are available on the project website https://tri-ml.github.io/vla_foundry.
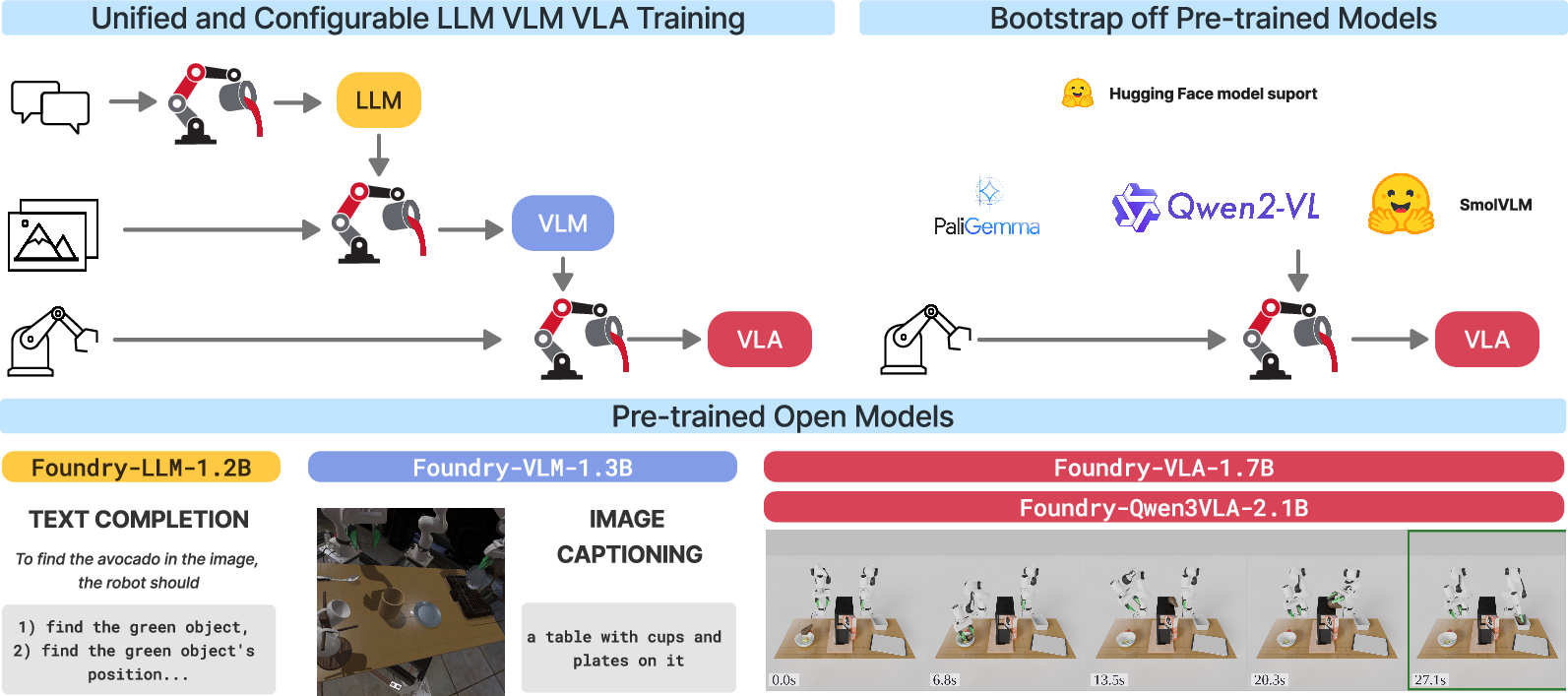





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VLA Foundry, an open-source “factory” for building robot brains that can see, read, and act. It puts everything needed to train these models in one place, so researchers don’t have to stitch together lots of different tools. The team also shows the framework in action by training and releasing two robot-control models and testing them in a realistic simulator.
To keep terms simple:
- An LLM is like the language “brain.”
- A VLM (Vision-LLM) is like “eyes + language,” understanding images and words together.
- A VLA (Vision-Language-Action Model) is like “eyes + language + hands,” connecting seeing and understanding to actual movements.
What questions were they trying to answer?
- Can we build one simple, flexible system to train LLMs, VLMs, and full robot action models (VLAs) end to end?
- Does training everything in a unified way (instead of piecing together separate parts) make research faster and more reliable?
- If we swap in a stronger “vision-language backbone” (the eyes + reading part), do the robot’s actions get better?
How did they do it?
Think of training a robot’s brain like teaching a student:
- First, you teach them language (LLM).
- Then you teach them to connect pictures with words (VLM).
- Finally, you train them to use what they see and read to move their hands and complete tasks (VLA).
Here’s their approach in everyday terms:
- One codebase, many stages: The same training system handles language, vision+language, and action. You can start from scratch or plug in a strong, already-trained “backbone” from public model hubs.
- Mix-and-match data: The system can combine text, image–caption pairs, and robot demonstrations (both simulated and real) using simple settings. Think of it as choosing a recipe for how much of each ingredient to use.
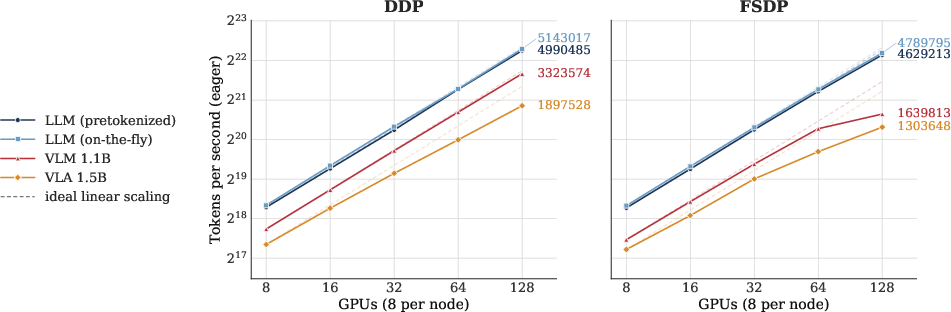
- Scales up to big runs: It supports multi-GPU, multi-computer training so researchers can handle large models and datasets.
- Fair, repeatable testing: They evaluate in a high-quality robot simulator with clear statistics, so results are comparable and trustworthy.
They trained two model families:
- A full “from-scratch” pipeline (LLM → VLM → VLA) to show complete control of every step.
- A pipeline that reuses a strong existing VLM (Qwen3-VL) and adds the action head on top, to test if a better backbone leads to better robot actions.
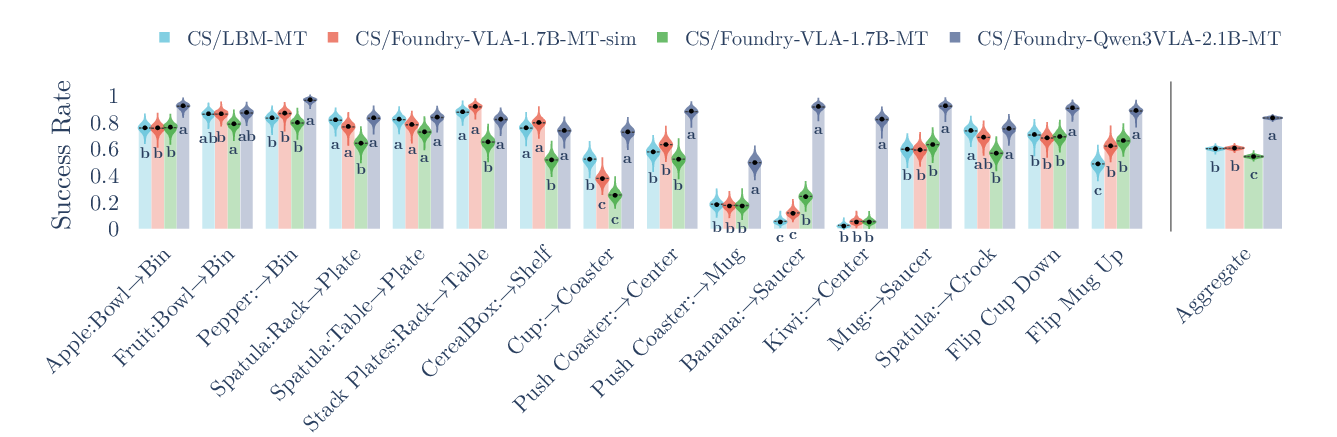
They tested the models on LBM, a tough tabletop manipulation simulator with many tasks (like picking up objects, placing them, pushing items, or coordinating two robot arms). They used careful statistics to judge which models really performed better.
What did they find?
In simple terms:
- The unified framework works: They successfully trained language, vision-language, and full action models in one system, from start to finish, or by plugging in pretrained parts.
- The “from-scratch” VLA did well: In the standard simulator setup, their fully open, from-scratch model performed about as well as their earlier closed-source system.
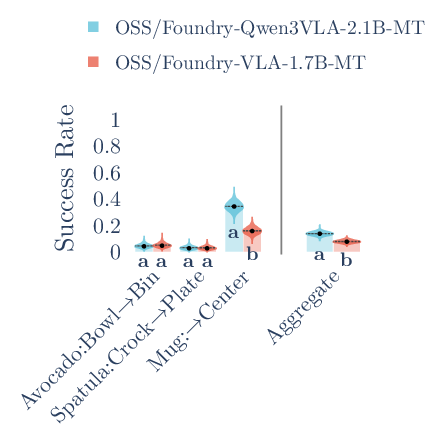
- Stronger eyes help the hands: When they swapped in a stronger vision-language backbone (Qwen3-VL), the robot’s action model clearly improved and beat their baseline by a large margin across many tasks.
- Training style matters:
- For the Qwen3-based model, training on many tasks together (multi-task) and then fine-tuning on a specific task often improved performance.
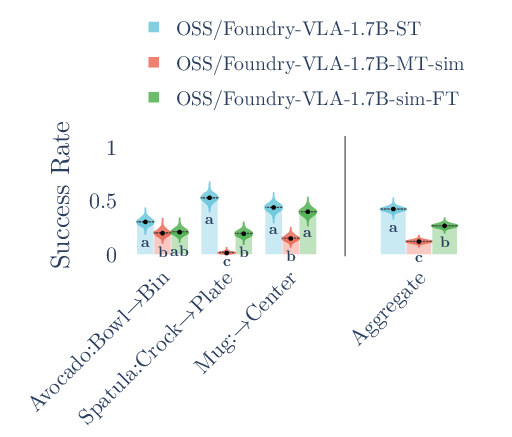
- For the from-scratch model, single-task training sometimes did better than multi-task fine-tuning, suggesting the backbone strength and data choices can change what works best.
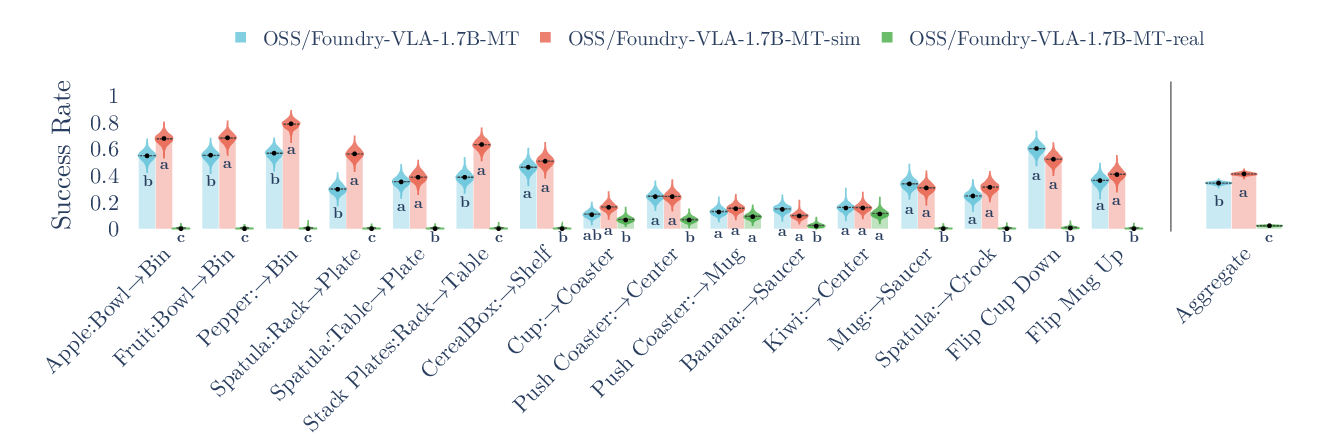
- Real vs. sim data: Models trained only on real robot data didn’t do well in simulation (the “worlds” differ), while simulation-only training did best in simulation—showing why matching your training data to your testing world matters.
Why this is important:
- It proves that using a better “eyes + language” part can directly lead to smarter, more capable robot actions.
- It gives the community a single, flexible toolkit to explore which data mixes and designs work best.
What could this change in the future?
- Faster progress: Researchers can try new ideas quickly—swap parts, change data mixes, and compare fairly—without rebuilding tools each time.
- Better robots: The results suggest that improving the vision-language backbone is a powerful way to boost real robot skills.
- Open science: The code, models, and evaluation tools are released openly, making it easier for others to reproduce, improve, and build on this work.
A few limits to keep in mind:
- Most results here are from simulation; more on-robot testing is still needed.
- They mainly used one kind of action head in the experiments (flow matching), though the code supports others.
- They didn’t focus on safety or failure detection yet—important topics for future work.
In short: VLA Foundry is like a well-organized workshop for building robot brains that see, read, and act. It lets you train everything together, try different parts, and test fairly. The team shows that a stronger “eyes + language” backbone makes a real difference, and they give the community the tools and models to keep pushing forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved in the paper and can guide future research:
- [Evaluation] No on-robot evaluation: the models are not validated on real hardware despite training with real data; quantify closed-loop real-world performance, stability, and failure modes across the 361 real tasks.
- [Evaluation] Narrow embodiment scope: results are limited to stationary, bimanual tabletop manipulation; assess generalization to different arms, grippers, mobile manipulation, and heterogeneous morphologies.
- [Evaluation] Benchmark coverage is limited: evaluation focuses on LBM; integrate and report results on other simulators and suites (e.g., LIBERO, RoboCasa, ManiSkill2, IsaacGym) to test cross-benchmark robustness.
- [Evaluation] No tests under distribution shift or long-horizon settings: evaluate robustness to perturbed environments and longer task horizons (explicitly omitted), including multi-stage and reset-free tasks.
- [Evaluation] Minimal generalization assessment: only 3 unseen tasks are tested; design larger held-out suites to probe compositional generalization to new objects, instructions, and task variants.
- [Evaluation] Inference-time performance is unreported: measure real-time latency, throughput, and memory footprint for deployment on robot hardware.
- [Evaluation] Statistical analysis sensitivity unstudied: analyze how STEP conclusions vary with episode budget, seed distributions (including “default-success” seeds), and CLD parameters.
- [Data & recipes] Sim+real mixture decreased performance for the from-scratch model: diagnose root causes (e.g., sampling ratios, weighting, normalization, domain gaps) and systematically ablate mixing strategies.
- [Data & recipes] Optimal multi-stage data recipes are unknown: characterize how LLM and VLM pretraining data choices (domains, sizes, instruction tuning) causally affect downstream VLA performance.
- [Data & recipes] Normalization choices are not ablated: quantify the impact of global vs per-timestep and percentile-based normalization schemes on stability and multi-dataset training.
- [Data & recipes] Domain adaptation techniques are untested: evaluate augmentation, domain randomization, and feature-level alignment to improve sim-to-real transfer within the unified pipeline.
- [Data & recipes] Reproducibility of VLM setup is fragile: DataCompDR link rot prevents exact replication; provide mirrored or fixed datasets and study sensitivity to data drift.
- [Backbones & architectures] Vision backbone alternatives are not evaluated in the from-scratch path: compare SigLIP/DINO/CLIP-sized encoders and larger ViTs on VLA performance under fixed training budgets.
- [Backbones & architectures] Pooling design untested: assess pixel-shuffle vs attention pooling, learned adapters (e.g., Q-Former), and token pruning on efficiency/accuracy trade-offs.
- [Backbones & architectures] Action head diversity not explored experimentally: benchmark diffusion heads, autoregressive discrete tokenizations, continuous decoders, and conditioning mechanisms (cross-attention vs concatenation).
- [Backbones & architectures] Action representation choices are not ablated: study absolute vs relative frames, rotation parameterizations, chunk/horizon lengths, and denoising schedules on policy quality.
- [Backbones & architectures] Proprioceptive inputs are optional but unstudied: ablate the presence/encoding of proprioception to quantify its contribution across tasks.
- [Sensing & inputs] Camera configuration is fixed (2 wrist + 2 external at 224 px): ablate number/viewpoints, resolution, temporal span, and frame rate; evaluate robustness to camera dropout and miscalibration.
- [Sensing & inputs] Additional modalities are not incorporated: explore depth, point clouds, force/torque, tactile, and audio, and measure their incremental value for manipulation.
- [Training strategy] LLM/VLM instruction tuning is absent: test whether instruction-tuned or reasoning-augmented backbones (e.g., CoT) yield better downstream policies.
- [Training strategy] Scaling relationships are unknown: derive scaling curves linking LLM/VLM size/tokens and VLA data to closed-loop policy success.
- [Training strategy] Joint vs staged optimization untested: compare staged LLM→VLM→VLA against joint co-training and curriculum schedules in the unified stack.
- [Training strategy] Catastrophic forgetting not measured: quantify multi-task interference and how single-task finetuning affects performance on other tasks.
- [Systems & scaling] Distributed training guidance is limited to ~2B models: evaluate larger scales and longer sequences where FSDP/sharding strategies may dominate, and provide cost/performance trade-offs.
- [Systems & scaling] Token budget and camera/time-window scaling not ablated: study how vision token count, number of cameras, and temporal context impact throughput and success.
- [Robustness & safety] Safety, alignment, and failure-mode detection are not addressed: integrate constraint handling, confidence/OOD detection, and safety checks into training and closed-loop execution.
- [Analysis] No standardized error taxonomy: provide structured qualitative and quantitative failure analyses to guide architecture and data recipe improvements.
- [Ecosystem] Cross-framework comparisons are missing: evaluate against other open VLAs (e.g., OpenVLA, SmolVLA, GR00T) under a unified protocol to contextualize gains.
- [Ecosystem] New-embodiment support is not demonstrated end-to-end: supply templates, schemas, and tutorials for adding novel robots/datasets (e.g., OXE, RoboSet) and report results.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases enabled by VLA Foundry’s unified LLM→VLM→VLA pipeline, released weights, data tooling, and evaluation stack.
- Bold: Fine-tune released VLAs for enterprise tabletop manipulation
- Description: Start from Foundry-Qwen3VLA-2.1B-MT or Foundry-VLA-1.7B and fine-tune on in-house demonstrations for tasks like bin-picking, kitting, sorting, rack loading, and light assembly on stationary bimanual cells.
- Sectors: Robotics (manufacturing, warehousing, lab automation), Supply chain
- Tools/Products/Workflows: Hugging Face checkpoints; YAML recipes for task-specific fine-tunes; flow-matching action head; WebDataset-based ETL
- Assumptions/Dependencies: Real-robot demos for target tasks; compatible camera setups (wrist/external cams); sufficient GPU (single to few GPUs for fine-tunes); safety interlocks and cell guarding; sim-to-real calibration if bootstrapping from sim
- Bold: Reproducible benchmarking and A/B testing of robot policies
- Description: Use the Dockerized lbm simulator + dashboard with STEP statistical analysis to compare policies, run sequential evaluations, and make statistically principled early/stop decisions without p-hacking.
- Sectors: Robotics R&D, QA/Validation, Standards/compliance
- Tools/Products/Workflows: Dockerized simulator; STEP-based analysis with CLD letters; evaluation dashboard; runbooks for budgeted rollouts
- Assumptions/Dependencies: Access to lbm containers; GPU for accelerated vision inference; process discipline to follow STEP guidelines; understanding that reported results are simulation-based
- Bold: Rapid backbone swapping to accelerate model governance and performance tuning
- Description: Swap vision-language backbones (e.g., Qwen3-VL) via configuration only to test performance/cost trade-offs and set policy baselines for new tasks.
- Sectors: Robotics, Software/ML platforms (MLOps), Academia
- Tools/Products/Workflows: Registry-based plug-ins; HF model loaders; Hydra/Draccus YAML includes; internal “model zoo” governance
- Assumptions/Dependencies: License-compliant access to backbone weights; compute to validate alternatives; monitoring to detect regressions
- Bold: Unified data ETL and normalization for heterogeneous robotics datasets
- Description: Adopt the WebDataset preprocessing, percentile/t-digest normalization, SE(3) action handling, and time-chunking to co-train across sim + real in a single pipeline.
- Sectors: Robotics software platforms, Data engineering for embodied AI
- Tools/Products/Workflows: Ray-parallel ETL; dataset-mixing with probabilistic sampling; per-dataset stats merging; reproducible seeds/checkpoints
- Assumptions/Dependencies: Consistent observation/action schema across sources; quality metadata (calibration, timestamping); storage bandwidth for shard IO
- Bold: Cloud-scale training runs on managed infrastructure
- Description: Train LLM/VLM/VLA stages using FSDP2 on AWS SageMaker with S3-backed checkpoints, auto grad accumulation, mixed precision, and multi-node orchestration.
- Sectors: Cloud (AWS and equivalents), Enterprise R&D, Startups
- Tools/Products/Workflows: SageMaker jobs; DDP/FSDP knobs; cost dashboards; checkpoint/version control
- Assumptions/Dependencies: Cloud budget; H100/A100 availability; reproducible configs; team familiarity with distributed training
- Bold: Curriculum design and ablations for data-scarce robotics
- Description: Systematically study the impact of non-robotics pretraining (LLM/VLM stages) on downstream policy performance using a single training stack to co-train/mix datasets.
- Sectors: Academia, Corporate labs
- Tools/Products/Workflows: Unified LLM→VLM→VLA experiments; ablation scripts; standardized reporting via STEP
- Assumptions/Dependencies: Access to curated text/image corpora (e.g., DCLM, DataComp) under proper licenses; compute for multiple experimental branches
- Bold: Course modules and skill-building for embodied AI
- Description: Use the tutorial and open models to teach end-to-end multi-modal training (tokenization, image-text alignment, action learning), evaluation design, and distributed training basics.
- Sectors: Higher education, Workforce upskilling, Robotics clubs
- Tools/Products/Workflows: Training notebooks; Dockerized eval; small-model configs for single-GPU labs
- Assumptions/Dependencies: Modest GPUs; simplified curriculum tasks; educator familiarity with PyTorch and YAML-based configs
- Bold: Internal “robot policy factory” MLOps pattern
- Description: Turn the framework into an internal product: standard YAML presets for stations, datasets, and tasks; automated ETL; reproducible training/eval; artifact registry for policies.
- Sectors: Robotics integrators, Enterprises with multiple cells/lines
- Tools/Products/Workflows: CI/CD for models; dataset/version registries; policy promotion gates driven by STEP significance; HF-based model catalog
- Assumptions/Dependencies: Organizational MLOps maturity; role-based access and governance; safety & compliance processes for deployment
Long-Term Applications
These opportunities require further research, scaling, safety work, or ecosystem maturation before broad deployment.
- Bold: General-purpose household assistants trained via unified multimodal pipelines
- Description: Extend beyond stationary bimanual cells to diverse embodiments (mobile manipulators) and unstructured homes, leveraging large non-robotics pretraining and rich real-world demos.
- Sectors: Consumer robotics, Assistive tech
- Tools/Products/Workflows: Additional simulators (RoboCasa, LIBERO); domain randomization; large-scale real data collection; on-device safety monitors
- Assumptions/Dependencies: Substantial datasets; robust sim-to-real transfer; safety/ethics alignment; long-horizon planning support
- Bold: Cross-embodiment, vendor-agnostic policy backbones
- Description: Train VLAs that transfer across robot arms/grippers/cameras through unified representations and normalization, minimizing per-embodiment fine-tuning.
- Sectors: Robotics OEMs, System integrators
- Tools/Products/Workflows: Embodiment adapters; capability conditioning; calibration-unaware normalization; shared evaluation suites
- Assumptions/Dependencies: Diverse multi-robot datasets; standardized interfaces; rigorous calibration handling
- Bold: Continual/active learning loops with on-robot data collection
- Description: Close the loop from deployment to training: mine failure cases, schedule targeted collection in sim/real, and update policies under evaluation guardrails.
- Sectors: Industrial robotics, Logistics automation
- Tools/Products/Workflows: Data flywheels; labeling/teleop tools; online STEP monitors; rollback-safe deployment pipelines
- Assumptions/Dependencies: Robust telemetry; human-in-the-loop infrastructure; drift detection; regulatory acceptance for iterative updates
- Bold: Safety-, alignment-, and failure-aware VLA training
- Description: Integrate uncertainty estimation, constraint-aware action heads, and safety shields into the unified training/eval stack for certifiable embodied AI.
- Sectors: Healthcare, Manufacturing with strict safety, Defense
- Tools/Products/Workflows: Failure-mode datasets; constrained decoding; risk dashboards; formal verification hooks
- Assumptions/Dependencies: New datasets and metrics for safety; cross-disciplinary methods; standards alignment (e.g., ISO/ANSI robotics safety)
- Bold: Standardized, open evaluation protocols for embodied AI policy procurement
- Description: Use STEP-style Bayesian significance and open simulators to define procurement benchmarks and reporting requirements for vendors.
- Sectors: Public sector, Large enterprises, Standards bodies
- Tools/Products/Workflows: Reference tasks; reporting templates; community leaderboards; audit-ready artifacts (configs, seeds, shards)
- Assumptions/Dependencies: Consensus among stakeholders; governance for versioning benchmarks; legal clarity on data/weights
- Bold: VLA-as-a-Service platforms
- Description: Offer managed services where users upload demonstrations and receive optimized policies, backed by cloud-scale FSDP training and standardized eval.
- Sectors: Cloud providers, Robotics startups
- Tools/Products/Workflows: Multi-tenant training clusters; HF model hub integration; dataset isolation; usage-based billing
- Assumptions/Dependencies: Strong isolation for data/IP; cost-effective GPU supply; SLAs for training and eval turnaround
- Bold: Expanded action heads and world-model integration
- Description: Incorporate diffusion/autoregressive/flow hybrids and world models for long-horizon reasoning, while keeping the same data/training abstractions.
- Sectors: Research labs, Advanced automation
- Tools/Products/Workflows: Modular action head registry; joint training recipes; planning-time rollout evaluators
- Assumptions/Dependencies: Algorithmic maturity; compute for large-scale experiments; benchmarks for long-horizon tasks
- Bold: Sector-specific adapted VLAs (e.g., healthcare, semiconductor, biotech labs)
- Description: Tailor policies and workflows for sterile handling, micro-assembly, or lab protocols using the unified pipeline and rigorous eval.
- Sectors: Healthcare delivery, Pharma/biotech, Semiconductor manufacturing
- Tools/Products/Workflows: Domain-specific datasets; protocol encoders; compliance-oriented eval suites
- Assumptions/Dependencies: Strict regulatory approvals; high-fidelity sim environments; expert data collection at scale
Notes on Feasibility Across Applications
- Compute and cost: While the framework targets moderate-to-medium compute, many impactful use cases still require multi-GPU training or cloud resources (DDP/FSDP).
- Data availability and licensing: Non-robotics corpora and image-text datasets (e.g., DCLM, DataComp) and released sim data must be license-compliant; image-link churn can hinder exact reproducibility.
- Domain gap: Current results are simulation-based; real-world performance depends on demonstration quality, calibration, and sim-to-real strategies.
- Safety and compliance: The paper does not address deployment safety; any operational use must layer on safety engineering, monitoring, and compliance procedures.
- Embodiment scope: Present focus is stationary bimanual tabletop tasks; extending to other embodiments will require additional adapters, data, and evaluation suites.
Glossary
- 6D continuous rotation representation: A smooth, minimal-ambiguity representation of 3D rotations using six parameters to avoid discontinuities. "rotations in the 6D continuous format"
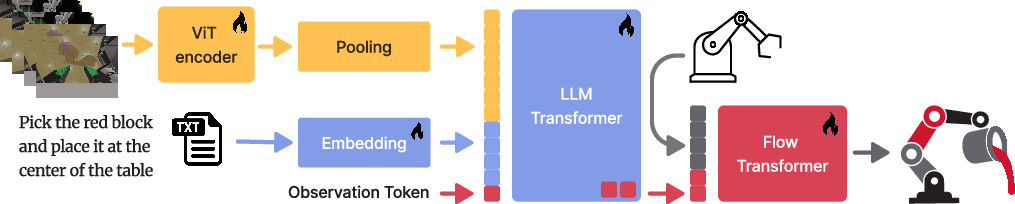
- Action head: The model submodule that maps encoded observations into action outputs for control. "This action head is a 325 million parameter transformer"
- Anchor end effector pose: A reference pose of the robot’s tool (end effector) relative to which other poses or actions are expressed. "relative to an anchor end effector pose"
- Autoregressive: A modeling approach that predicts each token conditioned on previously generated tokens. "enable the training of autoregressive VLMs on web-scale data."
- Barnard's test: An exact statistical test for 2×2 contingency tables used to compare proportions. "Barnard's test"
- Bayesian estimates: Probability-based estimates that incorporate prior beliefs and update them with observed data. "violin plots for Bayesian estimates of individual success rates"
- Bimanual manipulation: Coordinated control and planning involving two robot arms to perform a task. "table top bimanual manipulation policies"
- Checkpoint synchronization: Coordinating saved training states across distributed workers to ensure consistent recovery and evaluation. "checkpoint synchronization"
- Closed-loop: A control or evaluation setting where actions are continually conditioned on feedback from the environment. "We evaluate closed-loop policy performance"
- Compact Letter Display (CLD): A post-hoc grouping annotation used in statistical plots to indicate which groups differ significantly. "with Compact Letter Display (CLD) attached for comparison."
- CPU offloading: Moving model states or gradients from GPU to CPU memory during training to reduce GPU memory pressure. "with optional CPU offloading"
- Draccus: A configuration system built on Python dataclasses that supports YAML presets and command-line overrides. "We base it on Draccus"
- Drake physics engine: A high-fidelity robotics simulation engine for modeling rigid-body dynamics and control. "Drake physics engine"
- DDP (Distributed Data Parallel): A parallel training paradigm that synchronizes gradients across multiple processes or devices. "with either DDP or FSDP parallelization."
- FSDP (Fully Sharded Data Parallel): A memory-efficient distributed training technique that shards model parameters, gradients, and optimizer states across devices. "FSDP (with optional CPU offloading)"
- FSDP2: A next-generation implementation of Fully Sharded Data Parallel in PyTorch with improved performance and ergonomics. "built on FSDP2"
- Family-wise error rate (FWER): The probability of making at least one Type I error across multiple hypothesis tests. "significantly different at 5% family-wise error rate (FWER)."
- Flow-matching action head: An action generator trained via flow-matching to denoise actions toward expert trajectories. "All experiments in this report use a flow-matching action head;"
- Flow-matching objective: A training objective that learns a continuous-time vector field to transform noise into data samples. "trained with the flow-matching objective"
- Flow transformer: A transformer module that models denoising dynamics (flows) to produce actions from noisy inputs. "The flow transformer outputs the predicted denoising direction."
- Gradient accumulation: A technique that simulates larger batch sizes by accumulating gradients over multiple mini-batches before an optimizer step. "automatic gradient accumulation"
- Gradient checkpointing: A memory-saving method that recomputes intermediate activations during backpropagation instead of storing them. "gradient checkpointing"
- Meshcat: A web-based 3D visualization tool commonly used with robotics simulators for rendering scenes. "Meshcat scenes"
- Mixed precision: Training with a mix of numerical precisions (e.g., FP16/FP32) to increase throughput and reduce memory. "mixed precision"
- Pixel-shuffle: A feature rearrangement operation originally used for super-resolution; here used as a pooling strategy to reduce token length. "pixel-shuffle"
- Proprioceptive observations: Sensor readings about the robot’s internal state (e.g., joint positions/velocities) used as inputs. "Proprioceptive observations are causally restricted to past and current time steps."
- Q-former: A learned query-based bridging module that aligns vision and language representations while decoupling backbones. "a modular bridging component (Q-former)"
- Ray: A distributed execution framework used to parallelize data preprocessing and other tasks. "Preprocessing runs in parallel with Ray"
- Rollout: A full episode of interaction in a simulator or environment used to evaluate or collect data for a policy. "200 rollout episodes"
- SE(3): The Lie group of 3D rigid-body transformations combining rotations and translations. "SE(3)"
- t-digest: A data structure for accurate, memory-efficient estimation of quantiles and percentiles on streaming data. "we use t-digest"
- Tokenization: Converting raw text into discrete tokens as input for LLMs. "Text was tokenized"
- torch.compile: A PyTorch feature that compiles model graphs for potential speedups via ahead-of-time optimizations. "torch.compile"
- ViT (Vision Transformer): A transformer-based vision backbone that treats images as sequences of patch tokens. "vision transformer (ViT)"
- Violin plots: Statistical graphics that show distributions, combining a box plot with a kernel density estimate. "violin plots for Bayesian estimates"
- WebDataset: A dataset format that stores samples as tar shard archives for efficient streaming and distributed loading. "WebDataset"
- World-frame coordinates: Expressing positions and orientations in a fixed, global coordinate frame of the environment. "world-frame coordinates"
- Zero-shot (0-shot): Evaluating or transferring to tasks without task-specific training or finetuning. "non-zero success rates 0-shot"
Collections
Sign up for free to add this paper to one or more collections.

