Mix, Don't Tune: Bilingual Pre-Training Outperforms Hyperparameter Search in Data-Constrained Settings
Abstract: For most languages of the world, LLM pre-training operates in a data-constrained regime where models must repeat their training data many times, degrading generalization. Two remedies exist: aggressive hyperparameter tuning such as high weight decay, and mixing in data from a high-resource auxiliary language to directly aid the low-resource target. While hyperparameter tuning regularizes the model by shrinking weights to restrict network capacity, auxiliary data mixing uses a tunable mixing ratio to expand the training distribution and diversify the training signal with new knowledge. Both offer a principled way to improve training in a data-constrained domain. We compare these levers systematically across four model scales from 150M to 1.43B parameters, using Arabic as the low-resource target and English as the auxiliary, over approximately 1000 pre-training runs. Three findings emerge. First, mixing yields larger improvements than hyperparameter tuning on both validation loss and downstream task accuracy, and the gap grows with model size. Second, we quantify how much mixing helps: it boosts performance by an amount equivalent to 2--3$\times$ the unique target data on validation loss and 2--13$\times$ on downstream task accuracy, with the gain scaling steeply with model size. Third, this divergence reveals that target-language validation loss systematically underestimates mixing's value. Mixing regularizes by diversifying the training signal and contributes knowledge the repeated target corpus cannot supply; validation loss captures only the first effect. Our practical recommendations are: mix in a high-resource language, prioritize the mixing ratio over hyperparameter tuning, and transfer hyperparameters from a small proxy model via $μ$P.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: If you’re training a LLM for a language that doesn’t have much text available (like Arabic compared to English), what helps more?
- Carefully tuning training knobs (called hyperparameters), or
- Mixing in lots of text from a big, related source (like English) during training
Their short answer: Mix, don’t (just) tune. Adding English helps much more than tweaking knobs, and the advantage grows as models get bigger.
What were the main questions?
The authors focused on three easy-to-understand questions:
- Which helps more when Arabic data is limited: tuning hyperparameters or mixing in English text?
- How much can English mixing “make up for” the lack of Arabic data?
- Does a common score used during training (validation loss) accurately reflect the real benefits, or does it miss important gains?
How did they test it?
Think of training a LLM like studying for a test:
- “Validation loss” is like practicing with fill‑in‑the‑blank worksheets from the same textbook (predicting the next word in Arabic).
- “Downstream tasks” are like a real exam (answering science questions).
Here’s the setup, explained simply:
- Target language: Arabic (limited data).
- Helper language: English (lots of data).
- Models: Four sizes, from small to medium (150 million to 1.43 billion parameters).
- Training styles compared:
- Monolingual: Train on Arabic only (reusing the same Arabic data many times).
- Bilingual: Mix Arabic with English in different proportions (the “mixing ratio”).
- Knobs (hyperparameters) tuned:
- Learning rate: how big a step the model takes when it learns.
- Weight decay: a “don’t memorize too hard” rule that gently shrinks the model’s weights so it generalizes better.
- Two hyperparameter strategies:
- Basic HP: Pick good knobs on the small model once, then copy them to bigger models using a trick called μP (mu‑P). μP rescales those knobs so they still make sense for larger models.
- Tuned HP: Search for the best knobs separately at each model size (more expensive).
- What they measured:
- Validation loss in Arabic (the practice score).
- Accuracy on ARC‑Easy (a multiple‑choice science test), evaluated in Arabic and English. The Arabic questions were translated from English.
They ran about 1,000 training runs to get solid, fair comparisons.
What did they find?
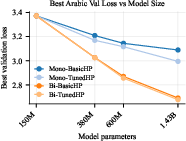
- Mixing in English beats hyperparameter tuning—and the gap grows with model size
- With only Arabic, larger models tend to overfit (memorize) when they see the same data over and over.
- Mixing English acts like a powerful regularizer (it diversifies what the model sees), and it also teaches the model knowledge that isn’t present in the small Arabic set.
- Result: Bigger models benefited the most from mixing. Tuning alone helped a little; mixing helped a lot.
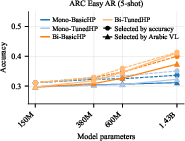
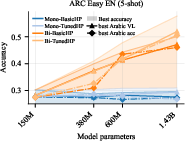
- Real‑world performance improves with mixing, not with monolingual scaling
- On the real exam (ARC‑Easy), Arabic‑only training barely improved as models got larger.
- Bilingual training improved quickly in both Arabic and English. Even when choosing checkpoints using Arabic’s validation score, the models got much better at English too—“for free.”
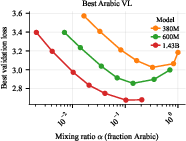
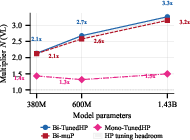
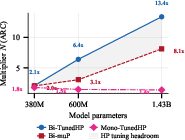
- How much does mixing “replace” Arabic data? A lot—especially for real tasks
- The authors define a “data multiplier”: how many times more unique Arabic data you’d need to match the bilingual model’s performance without mixing.
- On the practice score (validation loss): mixing was worth about 2–3× more Arabic data.
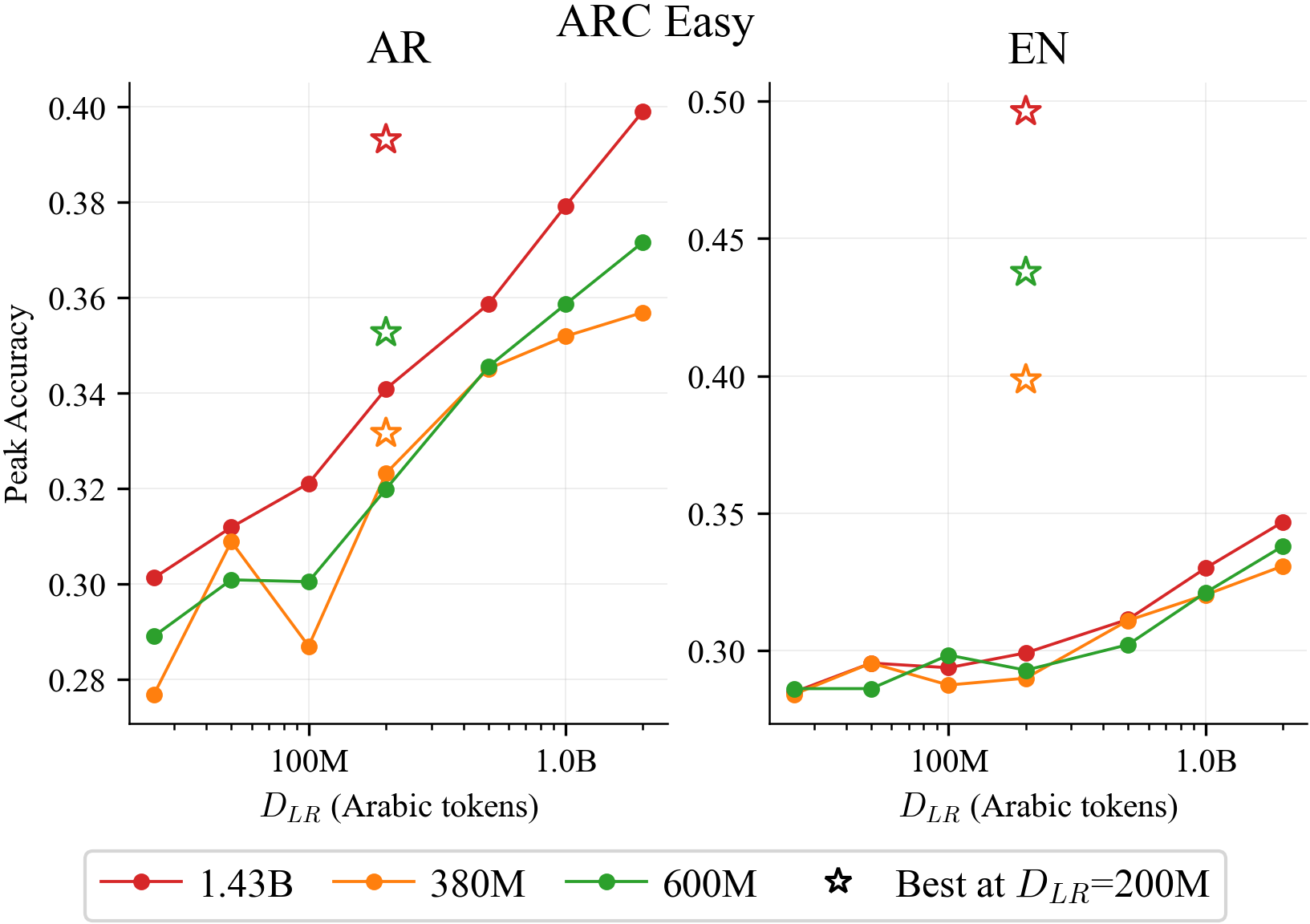
- On the real exam: mixing was worth about 2–13× more Arabic data, with the multiplier getting larger for bigger models.
- Example: At the largest model size, mixing with just 200M Arabic tokens matched the test accuracy of a monolingual model that needed up to billions of unique Arabic tokens.
- Validation loss underestimates the true value of mixing
- Validation loss mainly measures “not overfitting” to Arabic.
- But mixing also adds new knowledge from English—validation loss doesn’t capture that.
- So, judging only by validation loss can make mixing look less useful than it really is for real tasks.
- You don’t need to search hyperparameters at every scale—μP works well
- Copying good knobs from the small model to big ones using μP stayed very close to the best possible tuning, especially in bilingual training.
- This saves a lot of trial‑and‑error time. Spend your effort choosing the mixing ratio instead.
Why is this important?
- For most languages, we don’t have endless high‑quality text. If you only repeat a small dataset, big models tend to memorize instead of generalize.
- Mixing in a high‑resource language like English:
- Prevents overfitting by adding variety,
- Supplies missing knowledge the small target language can’t provide,
- And scales much better as models get bigger.
- Practical takeaway for anyone training models with limited data:
- Mix in a strong auxiliary language.
- Focus on picking a good mixing ratio.
- Reuse hyperparameters from a small model via μP instead of doing expensive searches at every size.
- Don’t rely on validation loss alone to compare monolingual vs bilingual training—check real tasks too.
In short: If your target language doesn’t have much data, adding a well‑chosen amount of English during training is a powerful and efficient way to build a better model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains uncertain or unexplored, framed to be actionable for follow-up work:
- External validity across languages: results are shown only for Arabic (target) and English (auxiliary). It is unknown how typological distance, script differences, and morphology (e.g., agglutinative or polysynthetic languages) affect optimal mixing and gains.
- Auxiliary language choice: only English was used as the high-resource source. The impact of alternative auxiliary languages (e.g., French, Chinese, typologically closer Arabic dialect corpora) on gains and the optimal mixing ratio is untested.
- Multiple auxiliaries: the paper does not examine mixing several high-resource languages simultaneously or compute-optimal allocations among them.
- Transfer to third languages: whether mixing English benefits other unseen low-resource languages (tri-lingual transfer) is not evaluated.
- Benchmark breadth: downstream evaluation relies on machine-translated ARC Easy (5-shot). Performance on diverse Arabic-native tasks (reasoning, reading comprehension, QA, morphology, dialectal Arabic), code, math, and open-ended generation remains unknown.
- Translation artifacts: reliance on NLLB-translated ARC may inject translation bias or simplify/alter item difficulty. Human-vetted Arabic benchmarks or bilingual human verification are needed to validate conclusions.
- Contamination checks: no explicit deduplication against ARC (English or Arabic) or related QA sources is reported; potential data leakage could inflate benchmark gains.
- Seed variance and statistical confidence: large pre-training grids are single-seed; confidence intervals, seed sensitivity, and effect size robustness (especially on small benchmarks) are not reported.
- Validation-loss mismatch: while VL underestimates benchmark gains, the paper does not propose or evaluate better pre-training-time proxies that capture “knowledge addition” (e.g., multilingual perplexity profiles, probe-based knowledge tests, retrieval-augmented validation).
- Mechanism disentanglement: the relative contribution of “regularization via diversity” vs “new knowledge acquisition” from English is inferred but not causally separated (e.g., via ablations with shuffled/syntax-preserved-but-semanticless English to isolate regularization effects).
- Data multiplier methodology: the log-linear fit used to derive multipliers lacks uncertainty quantification (CIs), goodness-of-fit diagnostics, or comparison to alternative functional forms (e.g., power laws with saturation).
- Compute-budget generality: experiments fix total tokens at 100× non-embedding parameters. It remains unknown how conclusions change under different compute budgets or training-duration regimes (short vs long training).
- Decoupling α and repetition: α is tied to the Arabic repetition budget (Rmax). Independent control of α and repeated epochs (and varying English budget) could clarify their separate effects under different compute settings.
- Dynamic mixing schedules: only static mixing ratios are explored. The efficacy of curricula that increase/decrease English proportion over time is untested.
- Data quality and domain matching: English and Arabic corpora may differ in quality and domain mix. Controlled experiments with matched domain distributions or varying English data quality are needed to attribute gains correctly.
- Tokenization choices: only an XGLM joint tokenizer is used. Effects of tokenizer type (BPE vs unigram), vocabulary size, language-specific subwording, or morphological segmentation for Arabic on mixing efficacy are not studied.
- Objective and architecture scope: conclusions are for decoder-only next-token LM with LLaMA-style models. Masked LMs, translation-augmented tasks, multi-task setups, or Mixture-of-Experts architectures could change the mixing–tuning tradeoff.
- Hyperparameter scope: only weight decay and base learning rate are tuned (constant LR, default AdamW β’s). The roles of LR schedules (cosine/linear), warmup, batch size, gradient clipping, dropout/activation dropout, label smoothing, and optimizer β’s remain unexplored.
- µP limits: µP transfer is tested up to 1.43B parameters and two HPs. Its robustness at larger scales (e.g., 7B+), with richer HP sets, other architectures, or dynamic schedules is unknown.
- Sensitivity at larger scales: the HP landscape sharpens at 1.43B. Whether this trend accelerates at larger models (and whether µP remains near-optimal) is an open question.
- Memorization and privacy: repeated-data regimes raise memorization risks. The effect of mixing on memorization propensity and privacy leakage was not measured (e.g., canary exposure, extraction attacks).
- Catastrophic interference: potential negative transfer from English on Arabic-specific competencies (e.g., morphology, named entities, dialects, orthographic variants) is not explicitly evaluated.
- Code-switching behavior: how mixing impacts robustness to code-switching or mixed-script Arabic is not assessed.
- Efficiency metrics: analysis focuses on final performance; sample-efficiency and wall-clock efficiency (tokens/compute to reach a target VL or accuracy) and energy/CO2 costs of mixing vs tuning are unreported.
- Larger-scale benchmarks: models were too small for MMLU-type evaluations. Whether the VL–benchmark divergence persists at larger parameter counts remains unanswered.
- Post-pretraining adaptation: effects of instruction tuning, RLHF, or domain adaptation on the mixing advantage are not studied.
- Data licensing and governance: practical constraints (licensing, compliance, safety) when importing large English datasets are not discussed; their impact on the recommended recipe is unclear.
Practical Applications
Immediate Applications
This paper provides operational recipes and measurable gains for training LLMs when target-language data is scarce. The following applications can be deployed now, with clear sector links, tools/workflows, and caveats.
Industry
- Bilingual pre-training for low-resource markets
- What to do: Train base models for low-resource languages by mixing in a high-resource auxiliary language (e.g., English), prioritize the mixing ratio over classic hyperparameter (HP) sweeps, and transfer HPs via μP from a small proxy model.
- Sectors: Software, consumer tech, mobile, cloud AI, localization, customer support.
- Tools/workflows:
- Implement bilingual data loaders with a per-batch mixing parameter α tied to an Arabic repeat budget Rmax (generalizable to any LR-HR pair).
- Automate α (or Rmax) sweeps; keep HPs fixed via μP from a tuned small model.
- Use target-language validation loss (VL) for checkpoint selection within each run; avoid using VL alone to compare mono vs bilingual.
- Assumptions/dependencies: Access to legally usable, high-quality HR corpora; tokenizer that handles both scripts well; compute budget where data is the constraining factor; architectural consistency for μP.
- Cost–performance planning with the “data multiplier”
- What to do: Use the paper’s “data multiplier” concept to forecast how much performance uplift mixing provides relative to collecting more target-language data (2–3× on VL; 2–13× on downstream tasks at ~1.4B params).
- Sectors: AI platform strategy, budgeting, data acquisition.
- Tools/workflows:
- Internal planning calculators that map model size and α to equivalent target-data needs.
- Replace expensive data collection/scraping for LR languages with controlled HR mixing where permitted.
- Assumptions/dependencies: Multipliers measured up to 1.43B parameters (extrapolation to much larger scales is plausible but should be verified); transferability to other language pairs depends on HR data quality and linguistic distance.
- Domain-limited pre-training with auxiliary knowledge
- What to do: For small domain corpora (legal, medical, finance) in a local language, mix in large HR-domain corpora to inject missing knowledge while curbing overfitting.
- Sectors: Healthcare, legal tech, finance, enterprise search.
- Tools/workflows:
- Curate domain-aligned HR corpora and set α to cap LR repetitions (avoid overfitting).
- Keep μP-transferred HPs; spend compute on α sweeps rather than large HP grids.
- Assumptions/dependencies: Domain–language alignment matters (auxiliary data should carry relevant knowledge); safety and compliance review is essential in regulated sectors.
- Shipping multilingual support with smaller models
- What to do: Use bilingual mixing to achieve LR-language gains with smaller models; e.g., a bilingual 600M model can outperform a monolingual 1.43B on target VL and benchmarks in the study.
- Sectors: On-device AI, edge, robotics interfaces, call centers.
- Tools/workflows:
- Target α ranges that shift toward more HR data as models grow (optima moved toward α≈0.10 at 1.43B in the study).
- Deploy LR-capable micro-models on constrained hardware.
- Assumptions/dependencies: Tokenization efficiency on-device; privacy constraints on auxiliary data.
- Streamlined training operations
- What to do: Standardize on μP for HP transfer from a 150M-ish proxy; predefine a narrow HP set and invest in α/Rmax sweeps.
- Sectors: MLOps, platform engineering.
- Tools/workflows:
- μP-compatible config templates; one-click Rmax sweep pipelines; per-run checkpoint selection via VL.
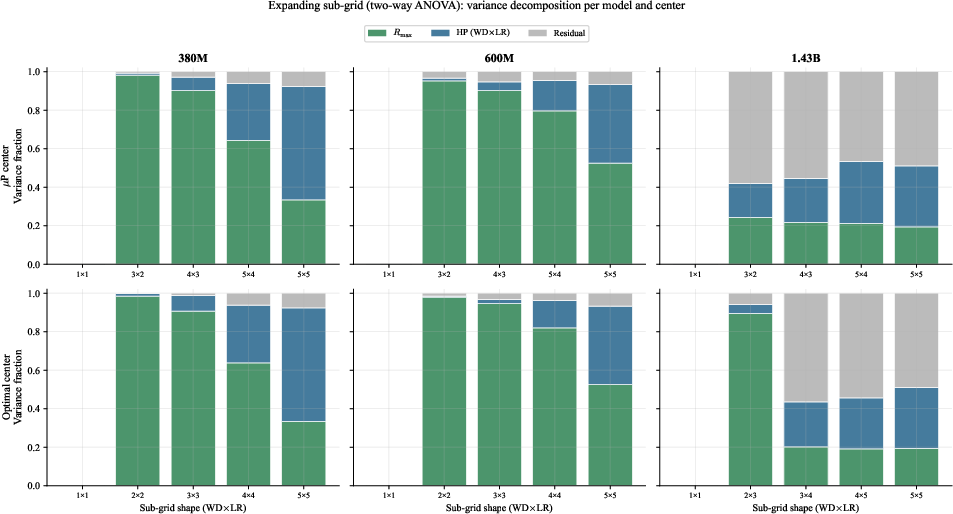
- ANOVA-style post-hoc variance decomposition to confirm α drives most variance near operational points.
- Assumptions/dependencies: Same architecture family across scales; stable optimizer choices; reproducible data pipelines.
Academia
- Reproducible evaluation protocols for data-constrained pre-training
- What to do: Adopt this paper’s four-paradigm comparison (mono/bilingual × basic/tuned HP), VL vs. downstream evaluation, and per-run VL-based checkpoint selection.
- Sectors: NLP research, ML methodology.
- Tools/workflows:
- Release bilingual pre-training configs and α-sweep scripts.
- Use ANOVA to attribute performance variance to α vs. HPs; report “data multiplier” alongside metrics.
- Assumptions/dependencies: Availability of LR corpora and suitable HR corpora; standardized tokenizers.
- Rapid baselining for new LR languages
- What to do: Start with bilingual mixing and μP HPs; run minimal α sweeps; measure both target VL and simple downstream tasks (e.g., translated ARC Easy) as a stopgap.
- Sectors: Computational linguistics, low-resource NLP.
- Tools/workflows:
- Translation-based proxy benchmarks to track knowledge transfer; open-source evaluation scripts.
- Assumptions/dependencies: Translation quality can bias measurement; invest in native benchmarks when possible.
Policy
- Procurement and funding guidance for public-sector LLMs in local languages
- What to do: Require bilingual pre-training strategies in RFPs; fund compute grants prioritizing α sweeps over large HP searches; use the data multiplier to justify costs vs. new data collection.
- Sectors: Government AI adoption, development agencies.
- Tools/workflows:
- Checklists mandating disclosure of mixing ratios, HR data sources, and evaluation beyond VL.
- Assumptions/dependencies: Legal frameworks for cross-border data usage; ethical sourcing of HR data; cultural adequacy checks.
- Language equity with practical efficiency
- What to do: Support bilingual approaches as a near-term bridge while investing in native corpora; create standards to report mixing ratios and target-language coverage.
- Sectors: Cultural policy, digital inclusion.
- Tools/workflows:
- Benchmark suites and documentation standards capturing cultural/linguistic adequacy.
- Assumptions/dependencies: Avoid long-term dependence on HR-language world knowledge; monitor bias transfer.
Daily Life
- Faster rollout of local-language assistants and chatbots
- What to do: Startups and NGOs can launch assistants in LR languages sooner by training bilingual base models, then apply modest instruction tuning.
- Sectors: SMB tech, civic tech, education.
- Tools/workflows:
- Use off-the-shelf μP libraries, simple α sweeps, and VL-based checkpoint selection.
- Assumptions/dependencies: Responsible deployment practices; continuous improvement with community feedback.
- Education and healthcare information access
- What to do: Build LR-language tutoring or health information tools by mixing in reputable HR-language educational/medical corpora to fill knowledge gaps.
- Sectors: Education tech, public health outreach.
- Tools/workflows:
- Domain-focused auxiliary corpora; safety filters; clinician/teacher review loops.
- Assumptions/dependencies: Strong safeguards against misinformation; regulatory compliance.
Long-Term Applications
These opportunities require further research, scaling, dataset investments, or engineering to mature.
Industry
- “Mixing-as-a-service” and turnkey bilingual base models
- What to build: Managed platforms that ingest LR corpora and automatically determine optimal α schedules and μP-transferred HPs; deliver LR-ready base models.
- Sectors: AI platforms, cloud providers, localization vendors.
- Dependencies: Generalization across many language pairs and scripts; automated quality/ethics checks for HR data.
- Dynamic and curriculum-based cross-lingual schedules
- What to build: Training curricula that adapt α over time or by layer, optimizing knowledge transfer while limiting interference.
- Sectors: Foundation model training, enterprise AI.
- Dependencies: Robustness of dynamic schedules; tooling to monitor interference and catastrophic forgetting.
- Cross-lingual domain adaptation at scale
- What to build: Pipelines that mix HR-domain corpora (e.g., English finance) to strengthen LR-domain models (e.g., Swahili finance) with controllable α and safety checks.
- Sectors: Finance, legal, biotech.
- Dependencies: Domain-relevant HR corpora; regulatory approvals; multilingual safety alignment.
Academia
- Standardized LR benchmark suites beyond translated proxies
- What to build: Native, culturally grounded benchmarks for reasoning and knowledge in LR languages to replace reliance on translated ARC Easy.
- Sectors: NLP evaluation, dataset curation.
- Dependencies: Community participation; annotation funding; reproducibility standards.
- Tokenization and architecture co-design for bilingual pre-training
- What to study: Tokenizers that optimally cover LR-HR pairs and architectures that exploit cross-lingual transfer more efficiently.
- Sectors: Core ML research.
- Dependencies: Multi-script coverage; fair performance across morphologically rich languages.
- Scaling studies to frontier sizes and more language pairs
- What to study: Whether the 2–13× benchmark multiplier grows or saturates at larger parameter counts and for typologically distant languages.
- Dependencies: Compute access; diverse HR corpora; rigorous cross-lingual measurement.
Policy
- Governance standards for cross-lingual data use
- What to develop: Policies on consent, jurisdiction, bias auditing, and transparency specific to training on HR corpora to serve LR users.
- Sectors: Data protection, AI ethics.
- Dependencies: International harmonization; auditable data provenance; community oversight.
- Sustainable language support programs
- What to develop: Balanced investments that pair bilingual efficiency with long-term native corpus development and capacity building.
- Sectors: Development policy, cultural preservation.
- Dependencies: Funding mechanisms; partnerships with local institutions.
Daily Life
- Edge and robotics assistants in LR languages
- What to build: On-device assistants and robots using small bilingual models with optimized α for strong LR performance under tight compute.
- Sectors: Robotics, smart devices, accessibility tech.
- Dependencies: Efficient inference stacks; privacy-preserving training; continual learning to reduce drift.
- Community-led corpora and evaluation networks
- What to build: Local initiatives to curate LR corpora and community benchmarks, complemented by safe HR mixing.
- Sectors: Civil society, education.
- Dependencies: Training, tooling, and funding for community contributors.
Cross-cutting Assumptions and Dependencies
- Data availability and legality: Access to high-quality, legally usable HR corpora (often English) and appropriate licenses for cross-border use.
- Data–task alignment: Auxiliary HR data should contain knowledge relevant to the LR task/domain; otherwise gains may shrink.
- Tokenization and scripts: Multiscript tokenizers (like XGLM in the paper) or improved designs for typologically distant pairs.
- Compute regime: Benefits are greatest when unique LR data is the bottleneck (data-constrained setting); trade-offs change if compute is scarce.
- Model scale: Findings demonstrated up to 1.43B parameters; verify at larger scales and with different architectures.
- Evaluation validity: VL is reliable for per-run checkpoint selection but underestimates cross-lingual mixing benefits on downstream tasks; maintain benchmark-based evaluation.
- Safety and alignment: Injected HR knowledge may carry biases; require sector-specific safety reviews (especially in healthcare/finance).
- μP applicability: Requires consistent architecture scaling; HPs tuned at a small proxy transfer best within the same family and optimizer settings.
Glossary
- AdamW: An optimization algorithm that combines Adam with decoupled weight decay to improve generalization. "We optimize with AdamW using default -values."
- ANOVA: Analysis of variance; a statistical method to partition observed variance into components attributable to different factors. "We apply variance decomposition (classical ANOVA, since our grid is exhaustively trained)"
- ARC Easy: A multiple-choice science question answering benchmark designed to test basic knowledge and reasoning. "We therefore use ARC Easy \citep{clark2018thinksolvedquestionanswering} for downstream evaluation, translating it from English to Arabic with NLLB-200-3.3B \citep{nllbteam2022languageleftbehindscaling}."
- auxiliary language: A high-resource language mixed into training to support a low-resource target language. "mixing in data from a high-resource auxiliary language to directly aid the low-resource target."
- Chinchilla scaling laws: Empirical rules relating model and data scale to performance, originally introduced by Chinchilla, here extended to data-constrained settings. "\citet{muennighoff2025scalingdataconstrainedlanguagemodels} generalize Chinchilla scaling laws to the data-constrained regime,"
- compute-optimal sampling: Choosing data mixture proportions that maximize performance given a fixed compute budget. "These studies target compute-optimal sampling across many languages rather than the data-constrained bilingual regime."
- continued pre-training: Further pre-training an existing model on new data to adapt it to new domains or languages. "the continued pre-training approach of \citet{lin2024mala500massivelanguageadaptation} cannot isolate the value of bilingual mixing because it starts from a strong English model."
- curse-of-multilinguality: The phenomenon where adding many languages can hurt performance due to capacity dilution. "in the curse-of-multilinguality regime across 250 languages"
- data-constrained regime: A setting where available unique training data is limited relative to compute, forcing repeated passes over data. "LLM pre-training increasingly operates in a data-constrained regime"
- data multiplier: A measure of how much unique target-language data a strategy (e.g., mixing) is equivalent to in performance terms. "we define the data multiplier "
- decoder-only transformer: A transformer architecture that uses only the decoder stack for autoregressive language modeling. "We train LLaMA-style decoder-only transformers at four scales (150M, 380M, 600M, 1.43B) with the XGLM tokenizer \citep{lin2022xglm} and sequence length 2048."
- distributionally robust optimization: An optimization framework that seeks good performance under worst-case or shifted distributions. "DoReMi \citep{xie2023doremioptimizingdatamixtures} uses distributionally robust optimization,"
- DoReMi: A method for optimizing data mixture weights during pre-training to improve efficiency and performance. "DoReMi \citep{xie2023doremioptimizingdatamixtures} uses distributionally robust optimization,"
- FineWeb: A large-scale English web text dataset used for LLM pre-training. "The English corpus comes from FineWeb \citep{penedo2024fineweb} and is effectively unlimited at our training scales (approximately 350B tokens)."
- FineWeb2: A multilingual web-scale corpus with improved processing pipeline, here used for Arabic data. "The Arabic corpus is a subset of FineWeb2 \citep{penedo2025fineweb2},"
- induction heads: Attention patterns/mechanisms in transformers that support in-context pattern induction, which can be harmed by data repetition. "\citet{hernandez2022scalinglawsinterpretabilitylearning} study partial repetition and find that it damages induction heads,"
- LLaMA-style: Refers to model architectures following design choices popularized by LLaMA models. "We train LLaMA-style decoder-only transformers at four scales (150M, 380M, 600M, 1.43B) with the XGLM tokenizer \citep{lin2022xglm} and sequence length 2048."
- Maximal Update Parametrization (μP): A parameterization scheme enabling hyperparameter transfer across model widths by keeping update magnitudes scale-invariant. "We use Maximal Update Parametrization (P) to tune once at a cheap proxy and transfer the base pair to larger scales."
- multilingual scaling laws: Empirical relationships describing how performance scales with model/data across multiple languages. "Multilingual scaling laws have been studied at the level of language families"
- NLLB-200-3.3B: A large-scale multilingual machine translation model from the No Language Left Behind project. "translating it from English to Arabic with NLLB-200-3.3B \citep{nllbteam2022languageleftbehindscaling}."
- non-embedding parameters: All model parameters excluding token embeddings, often used to define compute budgets. "where is the number of non-embedding parameters"
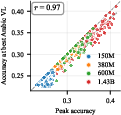
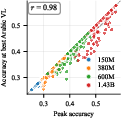
- oracle selection: Selecting the best-performing checkpoint using ground-truth (post-hoc) knowledge, e.g., peak accuracy. "Under oracle selection (peak accuracy across all checkpoints), HP tuning adds little on Arabic:"
- over-training regime: A regime where training continues beyond the typical compute-optimal point, often with repeated data. "\citet{gadre2024languagemodelsscalereliably} show that scaling laws extrapolate reliably in the over-training regime and can predict downstream performance."
- parametric mixing laws: Predictive formulas relating performance to data mixture proportions via parameterized models. "\citet{ye2025datamixinglawsoptimizing} derive parametric mixing laws predicting loss as a function of domain proportions,"
- PED-ANOVA: A procedure for efficient, threshold-based ANOVA to quantify hyperparameter importance near top-performing regions. "PED-ANOVA's lens, \citet{watanabe2023pedanovaefficientlyquantifyinghyperparameter}"
- RegMix: A data-mixture optimization approach that uses regression from proxy models to set mixture weights. "RegMix \citep{liu2025regmixdatamixtureregression} uses regression from small proxy models,"
- scaling laws: Empirical relationships that predict performance as a function of model size, data size, or compute. "\citet{gadre2024languagemodelsscalereliably} show that scaling laws extrapolate reliably in the over-training regime and can predict downstream performance."
- U-shaped loss curve: A curve where performance first worsens then improves (or vice versa) as a variable like model size increases. "\citet{kim2025pretraininginfinitecompute} show that under extreme repetition, naive scaling produces a U-shaped loss curve as model size grows,"
- variance decomposition: Breaking down total performance variance into contributions from different factors (e.g., mixing ratio, hyperparameters). "we quantify their relative contributions via variance decomposition."
- weight decay: An L2-regularization technique applied during optimization to discourage large weights and reduce overfitting. "aggressive regularization (weight decay up to standard practice) restores monotonically decreasing scaling,"
- XGLM tokenizer: A subword tokenization scheme used with multilingual models like XGLM. "with the XGLM tokenizer \citep{lin2022xglm}"
Collections
Sign up for free to add this paper to one or more collections.