- The paper demonstrates that bilingual post-training consistently outperforms English-only setups, yielding median improvements of 8-9% across tasks.
- It uses 220 controlled fine-tuning runs on mixtures of diverse languages to isolate the impact of language diversity from data volume.
- Quantitative results refute the negative interference hypothesis by showing that increased multilinguality benefits both low-resource and high-resource languages, including English.
Systematic Evaluation of Multilinguality in LLM Post-Training
Motivation and Problem Statement
Despite the multilingual deployment of LLMs in practical applications, supervised post-training pipelines remain heavily skewed toward English-centric data. This English dominance contributes to significant inequities in performance across languages, particularly disadvantaging low-resource languages. Previous studies present a fractured understanding, as they typically focus on limited language sets, tasks, or model scales, making it difficult to generalize findings and to disentangle the effect of data diversity from data volume. Furthermore, the “curse of multilinguality”—the hypothesis that increasing language coverage under constrained capacity dilutes performance, especially for high-resource languages—remains insufficiently studied in the post-training stage.
Experimental Framework
The authors present an extensive, controlled study involving 220 supervised fine-tuning runs on mixtures of up to ten typologically diverse languages. Two primary tasks are used to capture different aspects of model capabilities: mathematical reasoning (via mCoT-MATH and MGSM) and API calling (using the newly constructed mAPICall-Bank). Five core languages (English, Spanish, Japanese, Bengali, Swahili) span key typological, script, and resource-level differences, with additional languages incrementally introduced to assess scalability and diversity effects.
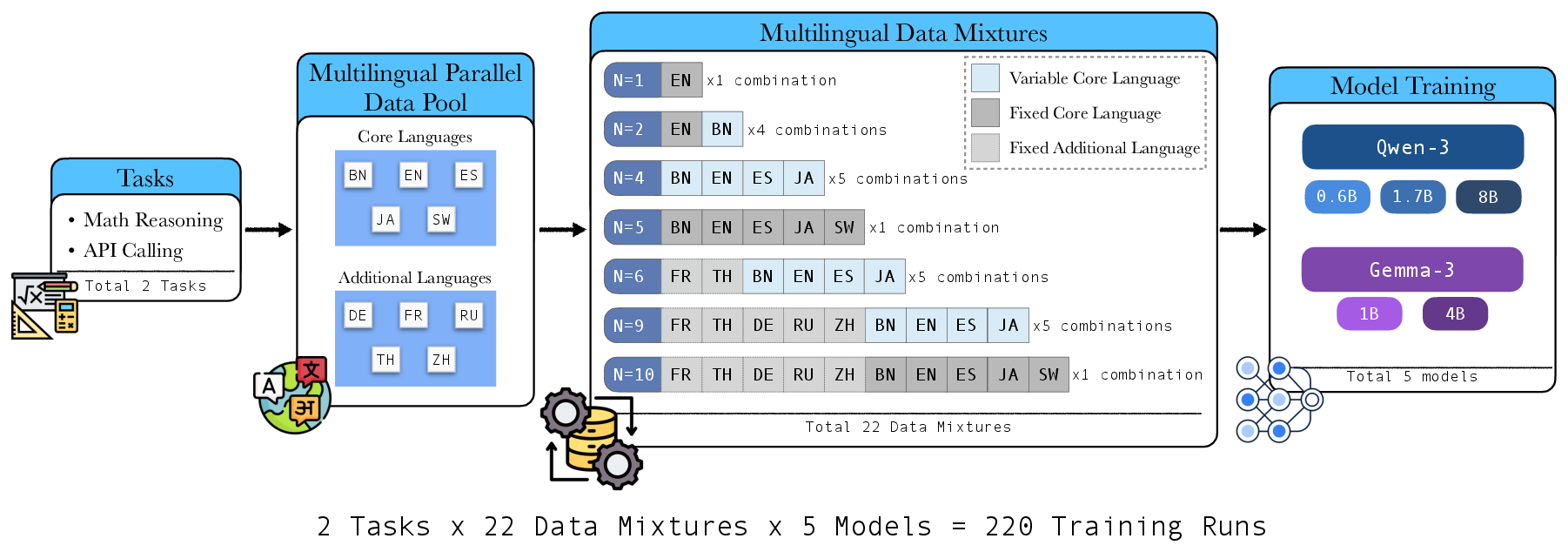
Figure 1: Overview of the experimental protocol, illustrating the parallel data pool, diversity-controlled mixtures, and scaling design.
Two prominent LLM families—Qwen-3 (0.6B, 1.7B, 8B) and Gemma-3 (1B, 4B)—were post-trained and evaluated under controlled batch, optimizer, and scheduler settings, ensuring that observed effects reflect only the impact of language coverage.
Quantitative Results: Scaling and Diversity Effects
Across all model sizes (≥1B) and tasks, increasing the number of languages included in post-training typically improves or preserves performance for both high- and low-resource languages. The largest improvements are observed for low-resource languages, while high-resource languages reach a performance plateau rather than showing the hypothesized degradation with increased coverage.
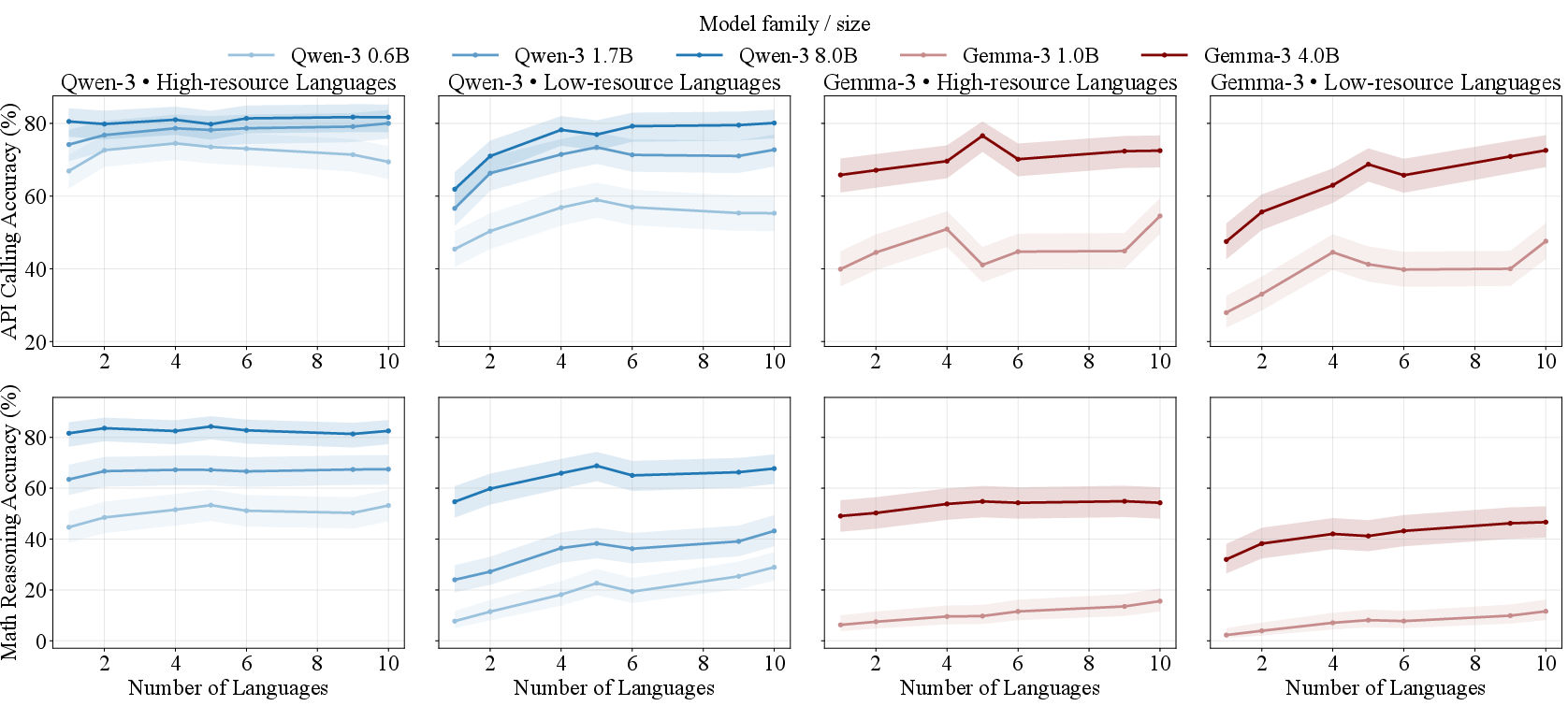
Figure 2: Accuracy trends as a function of training language count for high- and low-resource languages in API calling and math reasoning.
A notable divergence occurs for sub-1B models (Qwen-3 0.6B), where increasing multilinguality in API calling initially helps but eventually induces a mild drop, suggesting model capacity bottlenecks drive negative interference primarily in resource-constrained regimes.
Minimal Multilinguality: Substantial Gains Beyond English
Direct comparison of English-only post-training with bilingual (English + 1 language) post-training demonstrates that even minimal multilinguality consistently outperforms the English-only baseline for all evaluation settings and tasks. Median improvements for direct exposure reach 9.27% in API calling and 8.4% in math reasoning, with clear performance wins in the majority of configurations.
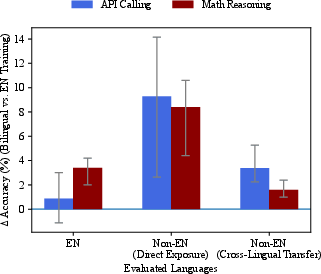
Figure 3: Median accuracy change from bilingual versus English-only post-training across tasks, highlighting robust improvements in cross-lingual transfer and even English itself.
Surprisingly, these gains extend to English performance (0.88% API, 3.4% math), directly contradicting the assumption that “adding multilingual data harms English.” Thus, English-only post-training is shown to be systematically suboptimal, with even a single non-English addition conferring generalized benefits.
High Diversity and Zero-Shot Transfer
Experiments that compare high-diversity settings (training on many languages, but excluding the target language) with direct-inclusion (bilingual) settings reveal that, for high-resource and English targets, sufficiently diverse mixtures allow zero-shot transfer to match or exceed direct inclusion. This effect is most robust at higher model capacities (≥4B) and mixture sizes (6 or 9 languages).
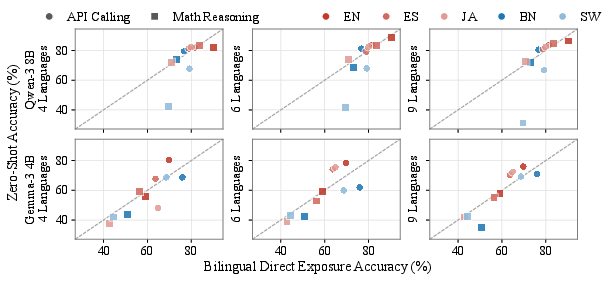
Figure 4: Comparison of zero-shot cross-lingual transfer and direct exposure at varied diversity for Qwen-3 8B and Gemma-3 4B, showing near parity for high-resource languages.
However, for typologically distant, low-resource targets, diversity-driven zero-shot transfer provides only partial compensation. Direct target language inclusion remains important to obtain maximal performance on these languages.
This parity between zero-shot transfer and direct exposure for high-resource languages, and the broad improvement in English performance without explicit English fine-tuning at high diversity, strongly challenge the negative interference hypothesis at realistic scales and diversity levels.
Construction and Significance of mAPICall-Bank
To extend evaluation beyond previous English-centric tool-use datasets, the paper introduces mAPICall-Bank, a parallel multi-turn API calling benchmark in eleven languages. Data is translated using a state-of-the-art LLM with strict preservation of structural constraints, helping study structured generation transfer in a controlled multilingual setting.
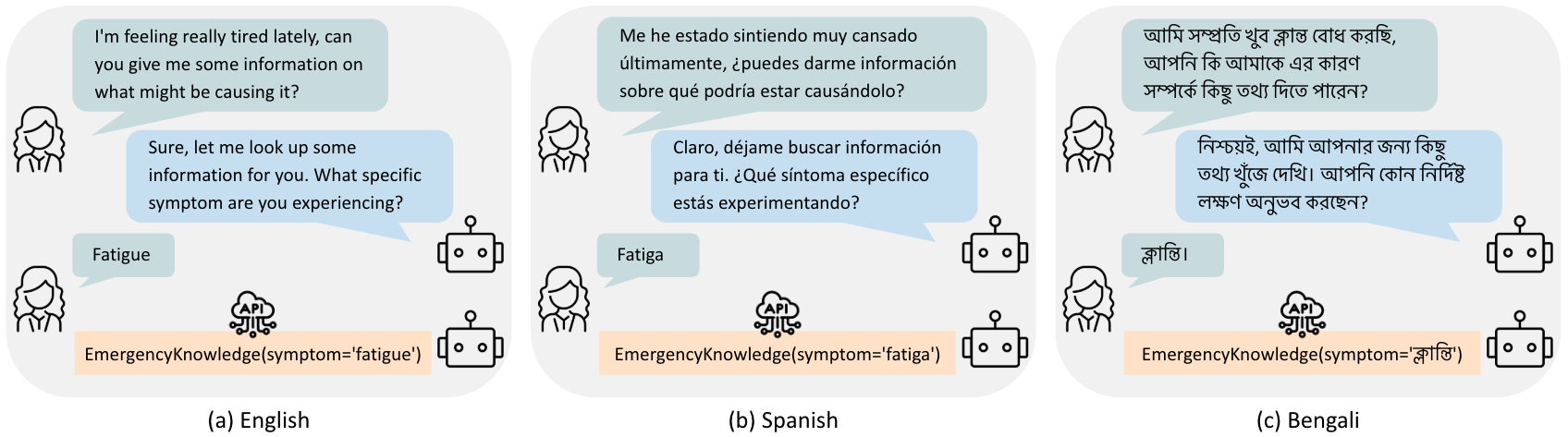
Figure 5: Example of a parallel API-calling interaction in mAPICall-Bank, demonstrating the dataset’s structural preservation across English, Spanish, and Bengali.
Regression Analysis and Aggregate Interpretation
A pooled regression controlling for direct language inclusion, model family, task, and log-scale model size further supports these observations. The coefficient for training-language coverage remains positive and statistically significant, indicating that the observed benefits derive from increased diversity itself, beyond what could be explained by direct exposure or mere increase in data volume.
Practical, Theoretical Implications and Future Directions
The empirical evidence presented demonstrates that English-centric supervised post-training is detrimental to both English and non-English performance. Increased language diversity yields pronounced improvements, especially for low-resource settings, and can allow strong zero-shot transfer for high-resource and English evaluation targets. These findings undermine the universality of the “curse of multilinguality” in the post-training stage for models with sufficient capacity.
Practically, these results mandate reevaluation of best practices for LLM post-training in global deployment scenarios. For equitable and robust cross-lingual performance, even minimal inclusion of additional languages is warranted, and broader linguistic diversity should be actively pursued. The findings also suggest that multilingual benchmarks and evaluations should involve both direct-inclusion and zero-shot paradigms to capture transfer ceilings.
Theoretically, these results call for new scaling laws and curriculum strategies that account for the joint effects of language typology, data diversity, and structured versus generative task types. As model scale increases beyond 8B parameters (the largest used here), it remains an open question to what extent these benefits plateau or further amplify, and whether similar effects arise for more naturalistic and low-resource data.
Conclusion
This comprehensive study offers a detailed, quantitative analysis of supervised multilingual post-training in LLMs, employing controlled mixtures, parallel data, and two disparate tasks. Key findings include consistent multilingual gains without performance degradation for high-resource languages, robust benefits to English itself, and strong zero-shot transfer under high diversity. Direct inclusion remains crucial for typologically distant, low-resource languages. The work challenges prevailing assumptions about negative interference from multilinguality, providing actionable insight for the design of equitable, high-performing multilingual LLMs and guidance for future methodological advances (2604.13286).

