- The paper introduces TriMix, a framework that fuses logits from a continually pretrained LRL model, a large instruction-tuned model, and a small baseline to enhance adaptation.
- It employs perplexity and entropy-guided weight selection to dynamically balance language competence, task execution, and scaling effects, achieving notable improvements.
- The method eliminates the need for annotated task data, offering a resource-efficient approach for adapting open-source models across diverse low-resource languages.
Multi-Source Logit Fusion for Efficient Low-Resource LLM Adaptation
The adaptation of LLMs to LRLs is severely constrained by two factors: scarcity of labeled task data and limited computational resources. Conventional approaches either require substantial annotated data for fine-tuning or demand continual pretraining on large-scale models, both of which are infeasible for most LRLs. Proxy Tuning, which fuses small domain-adapted models with larger instruction-tuned models at the logit level, has been shown effective in other domains but exhibits degradation in LRL settings due to the dominant influence of the large model’s weak target-language representations. The presented work introduces TriMix, a test-time logit fusion framework that explicitly integrates language competence, task competence, and scaling benefits, requiring only continual pretraining of small models and no annotated LRL data.
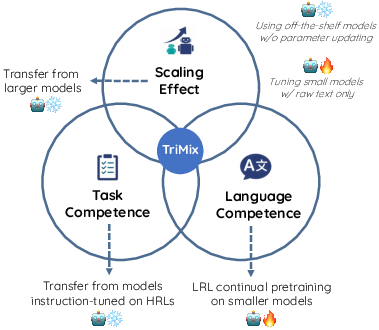
Figure 1: TriMix integrates three sources of benefit for LRL adaptation while minimizing the need for annotating task data and tuning larger models.
TriMix: Tri-Source Dynamic Logit Fusion
TriMix determines an inference-time linear combination of logits from three distinct sources: a small model continually pretrained on the LRL (language competence), a large instruction-tuned model (task and scaling competence), and a baseline small model. The logit fusion is parameterized as:
L=αLlarge-ins+βLsmall-cpt+(1−α−β)Lsmall-base
where α and β are dynamically selected fusion weights. The decomposition is designed to disentangle and recombine language adaptation, instruction-following behavior, and scaling advantages (capacity gains), enabling systematic integration at each generation step. Efficiency considerations mean that only the small model undergoes CPT on raw LRL text, while the task and scaling effects are exploited through the large instruction-tuned model.
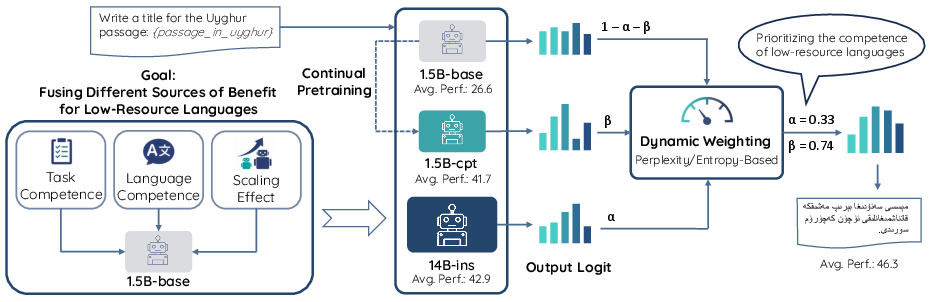
Figure 2: The TriMix framework dynamically fuses the logits of three models for LRL adaptation, balancing language, task, and scaling benefits.
Adaptive Weighting via Perplexity and Entropy
TriMix introduces two unsupervised hyperparameter selection strategies for the fusion coefficients:
- Perplexity-guided: α and β are chosen to minimize the perplexity of the prompt, allowing dynamic adaptation to the input’s distribution.
- Entropy-guided: Hyperparameters are selected to minimize the entropy of the next-token distribution, aligning fusion behavior with model predictive confidence.
Empirically, minimizing perplexity over the entire prompt delivers more robust performance and better approximation to the theoretical upper bound than entropy minimization, which only considers the initial token generation.
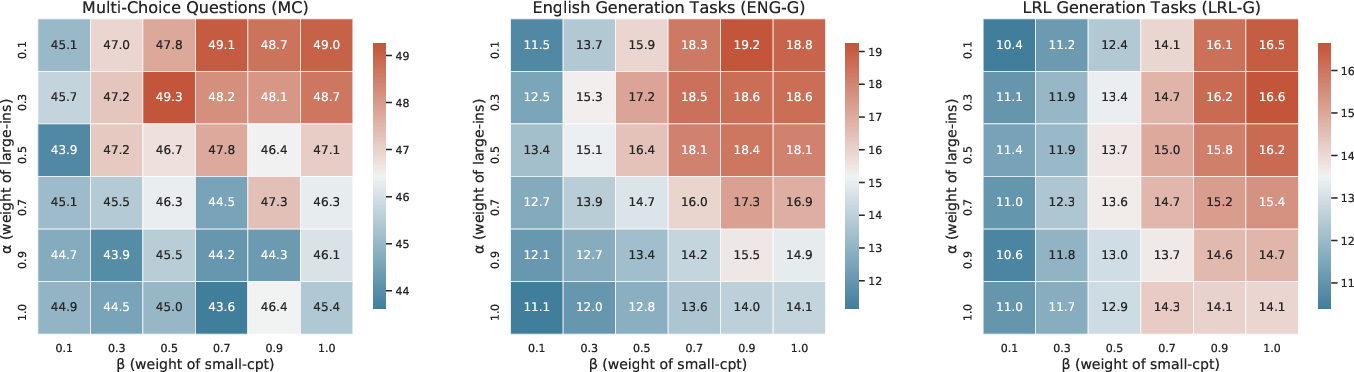
Figure 3: Grid search reveals TriMix performance peaks at high β, low α regions, indicating the necessity of upweighting LRL competence.
Empirical Evaluation and Contradictory Findings
TriMix is benchmarked across four open-source LLM series (Qwen2.5, Llama2, Llama3.2, Gemma3) and eight LRLs including Tibetan, Uyghur, Kazakh, and Mongolian (using MC2 and MiLiC-Eval), as well as Indian languages (Belebele, SIB-200). Key findings include:
Mechanistic and Theoretical Insights
KL divergence analysis demonstrates asymmetric specialization: instruction-tuned models diverge sharply from the base, while LRL CPT models remain close—this discrepancy undermines large-model-dominant fusion, explaining the failure of Proxy Tuning in LRL scenarios. TriMix’s adaptive approach grounds fusion in empirical divergence, producing superior outcomes. Ablation studies confirm the primacy of language modeling in overall performance in LRLs, with scaling effects providing additive gains.
Practical Implications and Applications
TriMix eliminates the need for task data annotation and high-cost large model CPT, making LRL adaptation attainable for resource-constrained environments. The framework's test-time nature and modular logit fusion are compatible with a wide range of open-source LLMs, requiring only access to output token distributions. TriMix is robust to incomplete CPT—partially trained models still benefit from fusion, acting as performance multipliers given limited training budgets.
The method is not directly applicable to closed-source or API-based LLMs lacking logit access; inference-time fusion introduces latency and memory overhead but is mitigable via quantization and compression techniques. Future directions include vocabulary expansion for script-diverse LRLs, more sophisticated fusion routers, and extension to scenarios involving more than three model sources.
Theoretical Implications and Future Directions
TriMix challenges the prevailing assumption that scaling and instruction-following dominate adaptation in LRLs, demonstrating that language-specific competence must be prioritized via logit fusion. Its empirical divergence-based weighting mechanism offers a principled path forward for cross-domain model collaboration, with implications for both parameter-efficient and test-time adaptation. The observed performance saturation and bottlenecks in languages with low tokenization fertility suggest future research into tokenizer alignment and vocabulary augmentation mechanisms.
The approach advocates for broader investigation into logit-level fusion for multilingual adaptation, opening lines of inquiry into learned fusion weights, reinforcement-based strategy selection, and context-sensitive fusion across disparate language domains.
Conclusion
TriMix advances efficient LRL adaptation by dynamically balancing language, task, and scaling signals at the logit level, requiring only small-model CPT and off-the-shelf instruction-tuned models. It empirically refutes large-model-dominant fusion for LRLs, establishing language-specialized CPT as the primary driver of adaptation. TriMix’s scalable, flexible, and resource-efficient nature opens new horizons for equitable language technology deployment across the linguistic spectrum.