- The paper introduces DoGraph, a gradient-based framework that dynamically redefines domain boundaries for adaptive data mixing in LLM pretraining.
- The paper shows that human-defined domain labels lose significance as training progresses, with gradient structures evolving into domain-agnostic clusters.
- Empirical results demonstrate that DoGraph outperforms static baselines by reducing validation perplexity and improving reasoning performance with minimal overhead.
Rethinking Data Mixing from the Perspective of LLMs
The paper "Rethinking Data Mixing from the Perspective of LLMs" (2604.07963) rigorously addresses limitations in existing data mixing strategies for LLM pretraining, focusing on the disconnect between human-defined domain taxonomies and the representations that arise naturally during model optimization. Empirically, it is shown that human domain boundaries (e.g., C4, Wiki, ArXiv, Book) are prominent only at initialization, but become conflated as training progresses, leading to domain-agnostic gradient structures.
Figure 1: PCA projections of gradient directions at different training epochs; distinct clustering at initialization converges to a homogenized manifold as training evolves.
This observation motivates a formal redefinition of domain rooted in the distribution of gradients rather than in predefined metadata. The paper establishes a mathematical equivalence between the difference in gradient means across two data distributions and the squared Maximum Mean Discrepancy (MMD) with a gradient-induced kernel. This result demonstrates that the geometry of gradient space is not only sufficient to distinguish domains but also captures their evolution as LLMs learn, arguing for adaptive, model-centric domain definitions. The authors provide a tractable, linearized analysis for the Transformer, highlighting that gradient clusters reflect the model’s effective perceptual boundaries.
DoGraph: A Model-Centric Data Reweighting Framework
Building on this foundation, the paper introduces DoGraph, a framework that formalizes per-epoch data scheduling as a graph-constrained optimization in model-centric gradient space. The pipeline begins by extracting per-sample gradients, projects them to reduced dimensions via randomized projections (ensuring geometric fidelity per Johnson-Lindenstrauss), then conducts K-means clustering to discover m domains in this latent structure. Each node in the graph reflects a model-defined domain, and domain weights are optimized to minimize auxiliary objectives—such as maintaining gradient balance or optimizing robust generalization—rather than fixed human labels.
Figure 2: Per-sample gradients colored by original domain labels; as optimization progresses, cluster membership determined by DoGraph (with m=11) reveals emergent model-centric domains distinct from human annotations.
The pipeline iteratively updates both the domain partition and the associated weighting, yielding a highly adaptive data-mixing policy that evolves with the model’s inductive bias.
Empirical Analysis
Experiments are conducted on SlimPajama and The Pile, spanning a range of model scales (GPT-2 Mini, Medium, LLaMA 1.1B, 3B), with carefully controlled computational budgets and consistent protocols. Benchmarks encompass commonsense reasoning (HellaSwag, PiQA, OBQA, LogiQA), reading comprehension (SciQ, ARC-E), and language modeling (Lambada), ensuring robustness across task variations.
Across the board, DoGraph consistently outperforms competitive baselines such as uniform mixing, DoReMi, DOGE, RegMix, and Dynamic Loss-based Sample Reweighting. The most pronounced gains are observed on reasoning tasks, underscoring the method's advantage for tasks requiring semantic and logical integration across multiple domains. Notably, DoGraph achieves lower validation perplexity even as model scale increases, with the performance gap widening with more complex models.
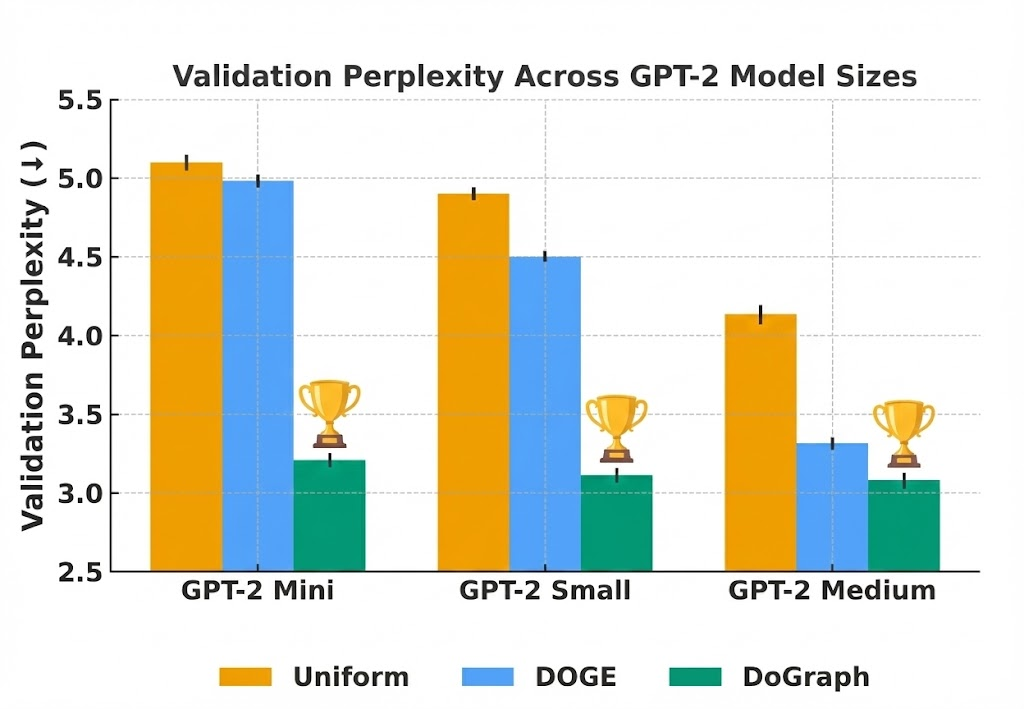
Figure 3: Perplexity reductions persist as GPT-2 size increases, with DoGraph exhibiting scale-invariant improvements relative to fixed or static baselines.
Hyperparameter Sensitivity and Efficiency
An extensive ablation of cluster granularity m reveals a clear U-shaped relationship: setting m=11 optimally resolves gradient structures without diluting signal through over-partitioning.
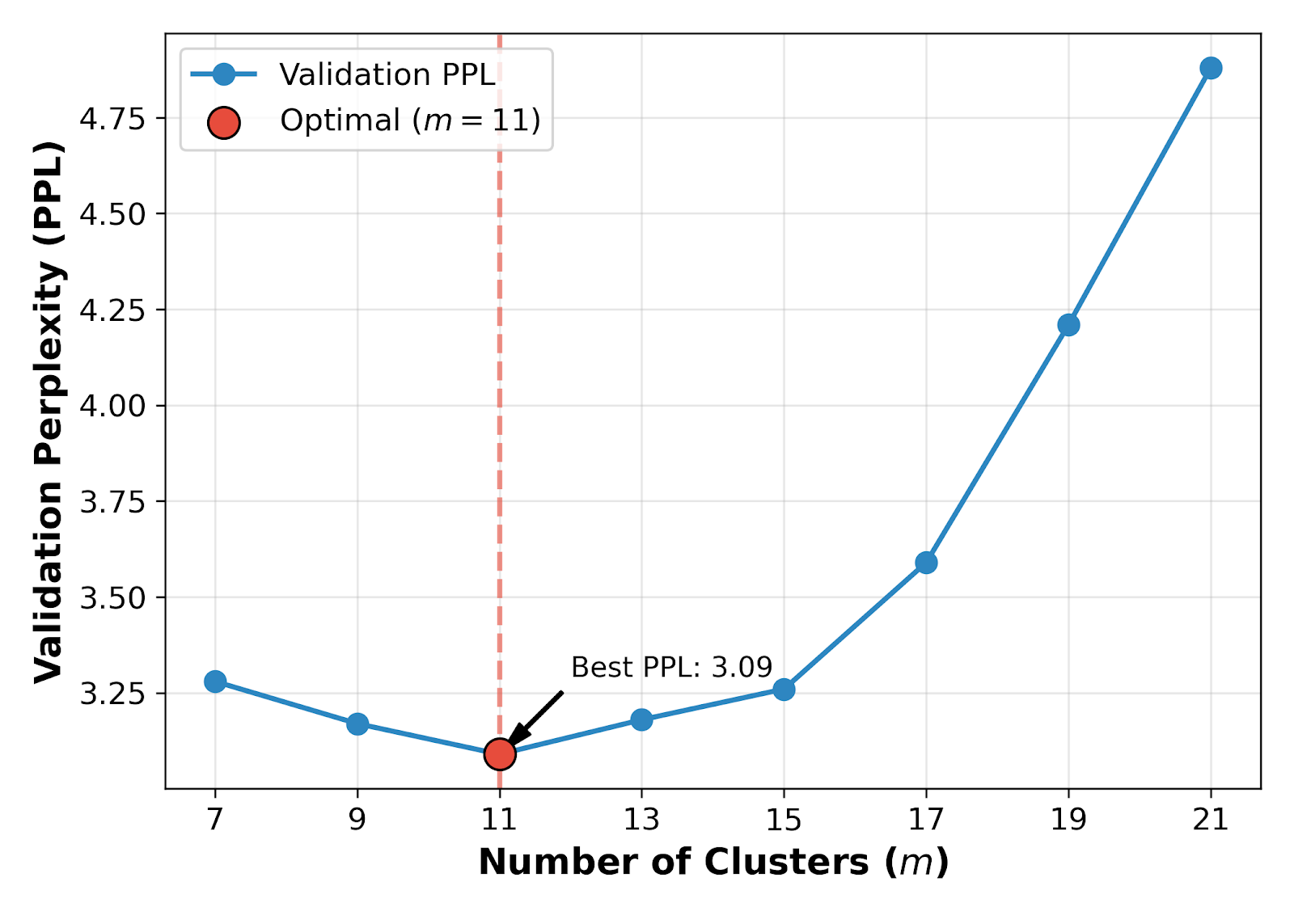
Figure 4: Validation perplexity as a function of cluster granularity m; optimal performance occurs at m=11.
Computationally, DoGraph introduces only a 4.51% overhead relative to the next best method (RegMix) when benchmarking on a 100B-token pretraining budget using dual H200 GPUs—a negligible cost against the observed generalization gains.
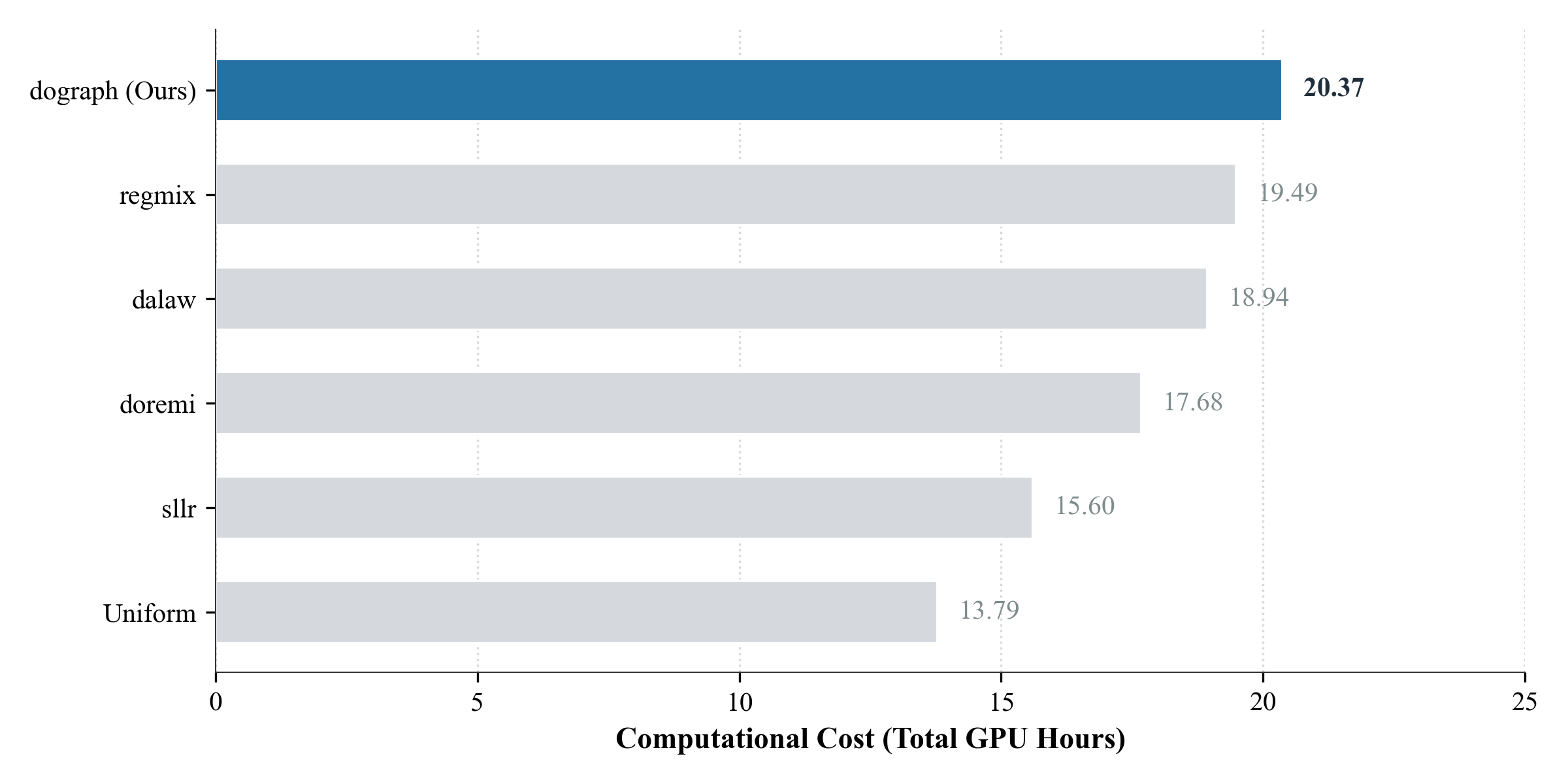
Figure 5: Pre-training runtime versus final perplexity; DoGraph achieves a new SOTA tradeoff with modest cost increase.
Broader Implications and Future Perspectives
This work has direct implications for dataset curation, LLM pretraining regimes, and the formulation of training curricula for multi-domain generalization. The demonstrated disconnect between human and model-perceived domains questions the validity of traditional dataset partition strategies, especially when scaling to LLMs, suggesting that future work should prioritize online, model-internal measurements such as gradient geometry.
Theoretically, this approach opens avenues for more principled meta-learning protocols, data valuation pipelines (where sample importance is outcome-driven), and new forms of robustness analysis (where adversarial hypotheses may be constructed in gradient space rather than input or label space). Moreover, since DoGraph's machinery operates without requiring explicit labels or handcrafted features, it is naturally extensible to multimodal and instruction-tuned settings.
Conclusion
"Rethinking Data Mixing from the Perspective of LLMs" (2604.07963) establishes that LLMs dynamically re-interpret domain boundaries throughout training, invalidating static or human-imposed data mixture heuristics. By proposing gradient geometry as the foundation for model-centric domains, and making data mixing a continually adaptive optimization in this space, DoGraph delivers state-of-the-art balance and generalization with minimal overhead. This paradigm shift in data scheduling is likely to shape the next generation of scalable, robust, and efficient LLM pretraining strategies.