Task-Adaptive Embedding Refinement via Test-time LLM Guidance
Abstract: We explore the effectiveness of an LLM-guided query refinement paradigm for extending the usability of embedding models to challenging zero-shot search and classification tasks. Our approach refines the embedding representation of a user query using feedback from a generative LLM on a small set of documents, enabling embeddings to adapt in real time to the target task. We conduct extensive experiments with state-of-the-art text embedding models across a diverse set of challenging search and classification benchmarks. Empirical results indicate that LLM-guided query refinement yields consistent gains across all models and datasets, with relative improvements of up to +25% in literature search, intent detection, key-point matching, and nuanced query-instruction following. The refined queries improve ranking quality and induce clearer binary separation across the corpus, enabling the embedding space to better reflect the nuanced, task-specific constraints of each ad-hoc user query. Importantly, this expands the range of practical settings in which embedding models can be effectively deployed, making them a compelling alternative when costly LLM pipelines are not viable at corpus-scale. We release our experimental code for reproducibility, at https://github.com/IBM/task-aware-embedding-refinement.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Explanation of the Paper: “Task‑Adaptive Embedding Refinement via Test‑time LLM Guidance”
Overview (What this paper is about)
This paper shows a simple way to make fast search systems smarter without retraining them. It uses a “big brain” AI (a LLM, or LLM) to give quick feedback that helps a fast search system (called an embedding model) better understand a user’s request on the fly. The result: more relevant results in searches and better yes/no (binary) classification across huge collections of documents, without paying the high cost of running a big AI on every document.
The Main Questions (What the authors wanted to find out)
- Can a fast search system that uses vectors/embeddings be improved at the moment of the search by getting a little help from a larger, more powerful AI?
- Can this “test-time” help make it good at tricky tasks like:
- finding all the academic papers that match a very specific question,
- spotting customer intent in chat messages,
- matching people’s comments to high‑level key points,
- following complicated instructions that include rules like “include this but not that”?
How It Works (Methods in simple words)
Think of documents and queries as pins on a map. An embedding model puts every text (your query and each document) as a point in this map so that similar things sit close together. Normally, the system finds documents closest to your query point. But sometimes your query is complex or unusual, and the system doesn’t “get” what you truly mean.
Here’s their trick: they ask a wiser “teacher” (an LLM) to judge a small handful of top documents and then use that feedback to nudge the query point to a better place on the map—just for this one search.
In short, the approach is:
- Start with a normal embedding search to get the top K (e.g., 20) likely documents.
- Ask a powerful LLM to score how well each of these K documents matches the query (like an expert giving ratings).
- Adjust the query’s position (its vector) slightly so the fast model’s preferences over those K documents better match the LLM’s preferences.
- In math terms, they make the two “preference lists” (probabilities over the K documents) line up better by reducing KL divergence. Think of KL divergence as a measure of “how different two opinions are”; they make that difference smaller.
- The adjustment happens in tiny steps (gradient descent), like tuning a radio dial until the signal sounds right.
- Use the newly refined query to re-rank the entire collection quickly.
Important details:
- Only the query is adjusted; the document embeddings and the model itself stay the same. No retraining is needed.
- The extra time is small (well under a second for the adjustment, plus the time to ask the LLM for K scores), so it’s practical.
What They Found (Results and why they matter)
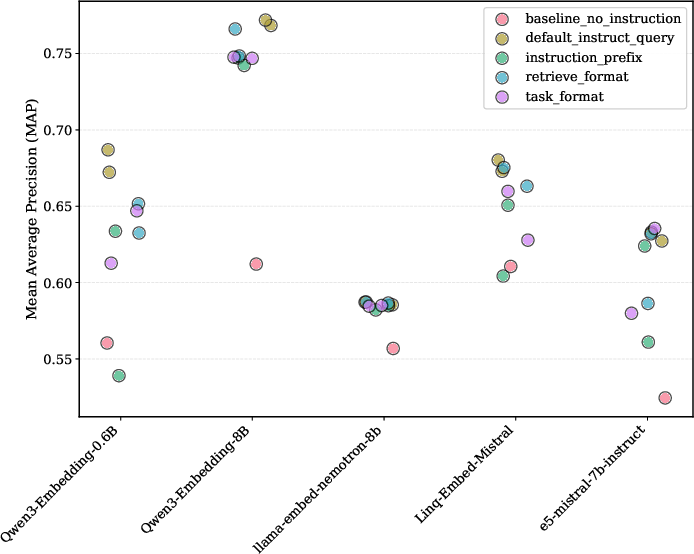
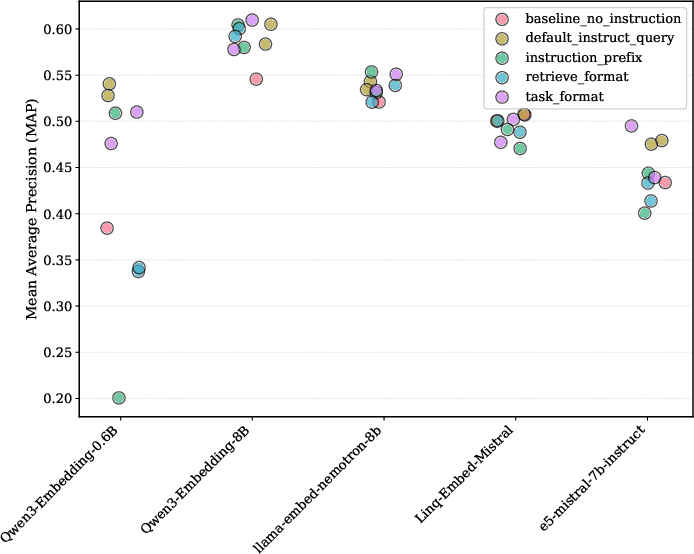
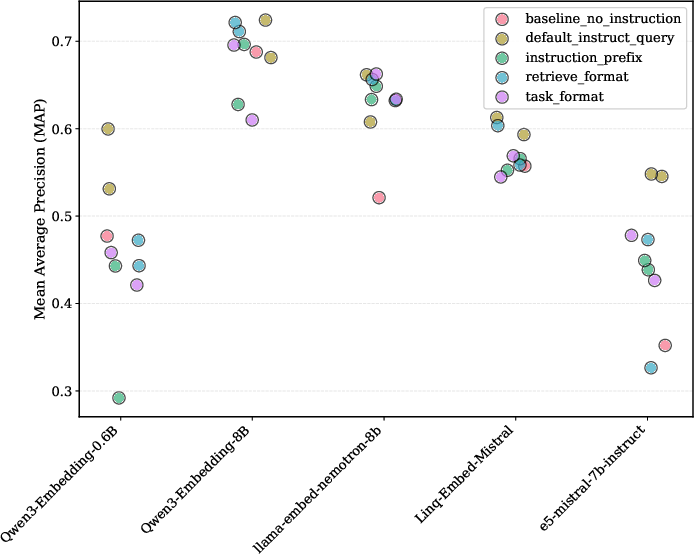
By adding this brief LLM feedback and refining the query, the system ranked relevant documents higher and more consistently. They measured this using Mean Average Precision (MAP), a score that rewards putting the right answers earlier in the list.
Across multiple tasks and modern embedding models, they saw consistent improvements. Typical relative gains included:
- Literature search: about +16.9%
- Intent detection: about +9.4%
- Key‑point matching: about +15%
- Following nuanced instructions: about +7.4%
- On average across all settings: about +12%, with some cases up to +25%
Why this matters:
- Better rankings make it easier to separate “yes” from “no” documents in huge collections.
- Users (like researchers or business analysts) can find what they need more reliably, even with complex queries.
- It keeps costs low because the heavy LLM is only used to judge a small number of documents, not the whole corpus.
Why This Is Useful (Impact and future possibilities)
- Practical at scale: You get near‑LLM quality guidance with embedding‑model speed—great for large libraries of documents or company chat logs.
- Flexible: Works “zero‑shot,” meaning it adapts to new queries and categories without extra training.
- Hybrid approach: Combines the strengths of two model types—speed from embeddings, nuance from LLMs.
Simple limitations and next steps:
- If the LLM’s feedback is wrong, the query might be nudged the wrong way.
- If the best documents aren’t in the initial top K, the feedback might miss them.
- Future work could choose better K documents for feedback, try smaller or specialized teachers for faster scoring, or extend the idea beyond text (e.g., images).
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to strengthen and extend the proposed LLM-guided test-time query refinement approach.
- Thresholding for binary separation is not addressed: how to set per-query decision thresholds to convert improved rankings into / at scale (e.g., calibration with LLM feedback, unsupervised thresholding, or joint optimization of threshold and query vector).
- Feedback set construction is naive (top-): no exploration of active/uncertainty sampling, diversity-aware selection, or iterative expansion beyond initial to handle extreme class imbalance and hard positives outside the top-.
- Hyperparameter robustness is underexplored: limited ablations beyond ; no systematic study of sensitivity to , learning rate , optimizer choice, temperature/softmax scaling, and initialization strategies.
- Objective choice is restrictive: only KL divergence over a softmax-normalized top- list is used; alternatives (pairwise/listwise losses, margin-based objectives, NDCG/MAP surrogates, contrastive gradients anchored on teacher preferences) remain untested.
- Teacher score calibration and prompt sensitivity are not examined: how token-logprob-derived scores relate to calibrated probabilities, and how prompts/instructions, decoding settings, and output formats affect stability and quality.
- Dependence on teacher quality and bias is acknowledged but unquantified: no analysis of systematic biases, domain drift, or hallucination effects, nor mechanisms for debiasing, outlier rejection, or ensembling teachers.
- Cost/latency dominated by teacher calls is not fully characterized: no amortization strategies (batching, caching, pre-scoring, approximate teachers), nor cost–quality tradeoff curves across teacher sizes/domains.
- Failure modes are not analyzed: notably, optimization fails to help for Linq-Embed-Mistral; missing diagnostics to predict when refinement helps, early stopping criteria, regularization to prevent overfitting to noisy feedback, or guardrails against degradation.
- Limited exploration of –performance frontier: only one dataset/embedding shown; need cross-dataset curves, diminishing returns characterization, and guidance to pick under latency budgets.
- Feedback confined to top- may entrench initial ranking errors: investigate iterative retrieve–score–refine loops, randomization to escape local optima, and inclusion of global hard negatives/positives sampled outside initial .
- Corpus-scale practicality not demonstrated: while query optimization is sub-second (excluding LLM), the approach is not validated on truly web-scale corpora (107–109 docs) and does not profile end-to-end latency under production ANN search.
- Multi-label, graded relevance, and non-binary settings are untested: extend to multi-class/multi-label classification, graded relevance levels, and scenarios requiring recall at strict coverage targets.
- Generality beyond English and text is not evaluated: no experiments on multilingual/cross-lingual corpora, domain-shifted data, or multimodal (image/audio) retrieval/classification where teacher feedback may behave differently.
- Long-document handling is unclear: how chunking, aggregation of document scores, and teacher scoring cost scale with document length; strategies for segment selection and score fusion are unstudied.
- Privacy and governance constraints are not addressed: sending potentially sensitive documents to external LLMs poses compliance risks; need on-prem teachers, redaction, or synthetic proxies and their impact on effectiveness.
- Reproducibility of teacher signals is uncertain: no variance analysis across random seeds/decoding temperatures or across time (model updates), and no methods for stabilizing scores (e.g., consensus over multiple prompts).
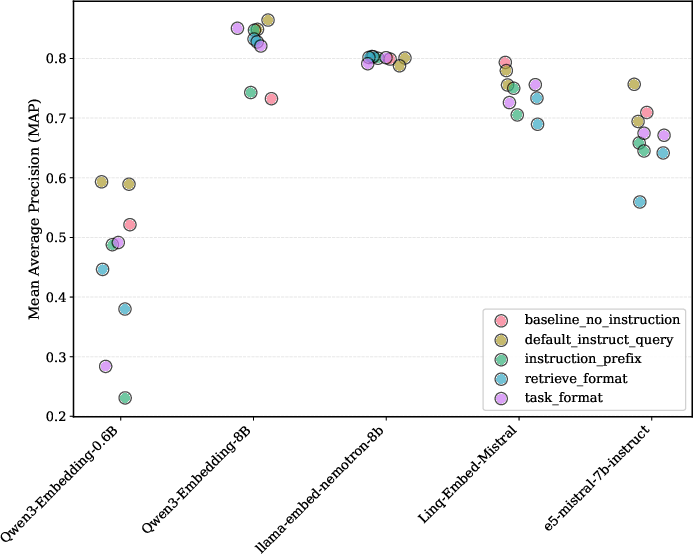
- Interaction with instruction templates lacks systematic study: the paper notes sensitivity but does not provide a principled methodology for instruction selection, nor automated tuning at test-time.
- Comparison breadth is limited: aside from HyDE, baseline coverage omits strong PRF methods with cross-encoders, query expansion via term-weighted PRF, learned rerankers, and prior test-time adaptation methods.
- Theoretical understanding of optimization dynamics is missing: no analysis of convergence properties, geometry of the embedding space traversal, conditions under which refinement improves MAP, or risk of overfitting to a small .
- Only ranking metrics (MAP, R@K) are reported: downstream utility metrics (e.g., calibrated precision at user-defined recall, F1 with automated thresholding, human-in-the-loop evaluation for literature search) are not examined.
- Integration with threshold tuning remains unexplored: joint procedures where the teacher helps calibrate similarity scores or produce per-query thresholds are only discussed qualitatively.
- Teacher–student selection tradeoffs are not mapped: no systematic evaluation of domain-specific small teachers vs large general teachers, nor mixed teacher strategies (e.g., route queries by domain/complexity).
- Robustness to noisy/adversarial feedback is untested: evaluate performance when a portion of teacher labels are incorrect, include noise-aware objectives, or apply smoothing/regularization of the teacher distribution.
- Interaction with HyDE and text-level rewriting is shallow: deeper combinations (e.g., applying representation refinement after multi-hypothesis synthetic queries, or co-optimizing text prompts and embeddings) are not assessed.
- Opportunities for distillation are untouched: how to convert repeated test-time feedback into a lightweight adapter or to fine-tune the embedder offline, reducing future teacher dependence.
- Initial retriever dependence is unquantified: how different first-stage retrievers (BM25, hybrid sparse–dense, alternative embedders) affect feedback quality and final performance remains unclear.
- Memory and session-level adaptation are not considered: caching refined query vectors, incremental refinement over multi-turn user interactions, and mechanisms to reuse feedback across similar queries are open.
- Safety and fairness impacts are not measured: potential disparate performance across intents/topics or demographic content due to teacher bias, and mitigation strategies, are not evaluated.
Practical Applications
Immediate Applications
The paper proposes a fast, test-time procedure that uses a handful of LLM relevance scores to refine a query embedding and rerank a full corpus, improving zero-shot separation without retraining or modifying document embeddings. Below are deployable use cases and workflows.
- Academic literature search recall booster (sector: healthcare, life sciences, CS research, legal)
- What: Improve high-recall queries (e.g., “all papers proposing hierarchical neural models for sign videos”) against large scholarly indexes with nuanced constraints.
- Workflow: Offline embed papers → at query time embed query → retrieve top‑K → get LLM relevance scores for those pairs → refine query vector via KL-minimization → rerank full corpus → optionally set threshold or show ranked list.
- Tools/products: Plugins for library portals and arXiv-like services; add-on for vector DBs (FAISS/Milvus/Elastic/OpenSearch/Pinecone).
- Assumptions/dependencies: LLM must reliably score domain content; privacy/compliance for sending top‑K texts to LLM; presence of at least a few true positives in the initial top‑K; modest LLM cost/latency for K≈20.
- Enterprise intent analytics and corpus separation (sector: customer support, CX, operations)
- What: Zero-shot detection/quantification of specific intents in chat, email, tickets (e.g., “threat to churn,” “refund request”) without training a classifier.
- Workflow: Embed historical corpora; analysts issue ad‑hoc intent queries; refine query with LLM feedback; count positives above a tunable threshold; slice by segment/region.
- Tools/products: “Intent Explorer” dashboard for CX stacks (Salesforce, Zendesk), BI integrations.
- Assumptions/dependencies: Thresholding policy per query; data governance for sending small snippets to LLM; teacher LLM accuracy on short, noisy texts.
- Key‑point matching at scale for survey analytics (sector: market research, HR, policy)
- What: Map free-text responses to predefined key points to generate quantitative summaries without bespoke training.
- Workflow: Treat each key point as a query; refine per-key-point query using LLM feedback on top‑K matches; rerank corpus; aggregate matches for distributions.
- Tools/products: Qualtrics/Medallia add-ons; research agency toolkits; internal VoC platforms.
- Assumptions/dependencies: Quality of key points; careful handling of near-duplicates and negations; teacher LLM disambiguation ability.
- Instruction-aware enterprise/eDiscovery retrieval (sector: legal, compliance, public sector)
- What: Execute complex “include/exclude” searches (e.g., “accomplishments of Hubble excluding repair details”) over document stores with improved adherence to logic/negation.
- Workflow: Users craft narrative queries; top‑K pairs scored by LLM; refined query reranks entire collection; export hit sets for review.
- Tools/products: eDiscovery/FOIA tooling; document management search upgrades.
- Assumptions/dependencies: Teacher LLM must parse nuanced instructions; risk of teacher bias in relevance judgments; auditable scoring trail may be needed.
- RAG retriever optimization with minimal LLM overhead (sector: software, LLM apps)
- What: Improve first-stage recall in RAG without heavy cross-encoders by refining the query vector using brief LLM scoring on a few candidates.
- Workflow: Baseline RAG → before generation, refine the query embedding using top‑K LLM feedback → retrieve expanded passages → generate/answer.
- Tools/products: LangChain/LlamaIndex/Vector DB integrations; “retrieval booster” modules.
- Assumptions/dependencies: Availability of token-level logprobs or reliable scoring from the LLM; added per-query latency budget for K LLM calls.
- Healthcare document triage and signal detection (sector: healthcare, pharma)
- What: Zero-shot separation of clinical notes/messages for triage (e.g., “possible adverse event mentions”) or literature scans for regulatory submissions.
- Workflow: On-prem embedding index; refine clinician query with a domain-competent teacher LLM; rerank; route top results; optionally human-in-the-loop validation.
- Tools/products: EHR inbox triage assistants; safety surveillance screening tools.
- Assumptions/dependencies: HIPAA/GDPR compliance; likely need an on-prem or private teacher LLM; medical-domain teacher competency.
- Financial communications surveillance and compliance (sector: finance)
- What: Detect ad‑hoc behaviors (e.g., MNPI mentions, collusion signals) across email/chat logs with high recall and tunable precision.
- Workflow: Embed comms; compliance analyst defines narrative criteria; refine and rerank; triage top items for review; adjust threshold/criteria iteratively.
- Tools/products: Trade/compliance surveillance suites; audit-ready relevance pipelines.
- Assumptions/dependencies: Strict data residency and auditability; teacher risk calibration; elevated false-positive cost considerations.
- Code search with nuanced constraints (sector: software engineering)
- What: Retrieve code snippets meeting multi-faceted criteria (e.g., “Python implementation of X using y but excluding z dependency”) more reliably than plain semantic search.
- Workflow: Embed repositories; refine code-aware query with LLM scoring on code+query pairs; rerank; surface candidates to developers.
- Tools/products: IDE/search extensions for GitHub/GitLab; internal code search portals.
- Assumptions/dependencies: Teacher LLM must be code-aware; embedding model trained for code-text; license scanning constraints.
- Personal knowledge base and email search (sector: consumer productivity, enterprise productivity)
- What: Execute precise searches over notes/emails with complex constraints (“find meeting notes mentioning budget increases but excluding Q2”).
- Workflow: Local or enterprise index of content; refine user query using a local or private LLM teacher on top‑K snippets; rerank; present results.
- Tools/products: Add-ons for Notion, Obsidian, Outlook/Google Workspace; on-device variants.
- Assumptions/dependencies: On-device or private teacher to protect privacy; reduced K to fit latency budget; teacher quality on personal context.
- Security log “threat hunting” with logical scoping (sector: cybersecurity, IT ops)
- What: Find complex patterns in logs (“failed root login followed by success, excluding maintenance windows”) when labels are unavailable.
- Workflow: Embed logs/events; SOC analyst crafts narrative; refine with LLM feedback; rerank streams; triage top hits in SIEM/SOAR.
- Tools/products: SIEM plugins (Splunk, Elastic, Chronicle); observability platforms (Datadog).
- Assumptions/dependencies: Tokenization/embedding for logs; sensitive data handling; teacher LLM must reason over temporal and scoped patterns.
Long-Term Applications
These opportunities require further research, scaling, or engineering before widespread deployment.
- Active feedback selection and list-wise scoring
- What: Replace naive top‑K selection with active/query-informative sampling and use list-wise/set-wise LLM judgments to reduce LLM calls and improve guidance.
- Potential products: “Smart feedback selector” for vector DBs; LLM list-wise scoring APIs.
- Dependencies: New acquisition strategies; reliable list-wise prompting; evaluation at scale.
- Domain-specialized or lightweight teacher models (“teacher-lite”)
- What: Distill domain-relevance scoring into small, on-prem LLMs to cut latency/cost while preserving guidance quality.
- Potential products: Fin/healthcare “relevance scorers” distributed as secure containers.
- Dependencies: Domain data for distillation; robustness vs. generalist teachers; MLOps for periodic refresh.
- Multimodal extension (text–image–audio–video)
- What: Apply the same test-time refinement to embeddings in multimodal corpora (e.g., medical images, surveillance video clips).
- Potential products: Visual retrieval boosters for DAM systems; manufacturing defect triage.
- Dependencies: Strong multimodal embedders; teacher models that can score cross-modal relevance.
- Cross-lingual/multilingual retrieval adaptation
- What: Use teacher guidance to align queries and documents across languages for global search/analytics.
- Potential products: Multilingual enterprise search; international customer care analytics.
- Dependencies: Multilingual teachers; consistent tokenization/embedding across languages; evaluation across MMTEB-like benchmarks.
- Automated thresholding and calibration for binary separation
- What: Build generalizable threshold-tuning modules leveraging small additional LLM samples per query for precise recall/precision trade-offs.
- Potential products: “Auto-calibrator” plugins for compliance/CX analytics.
- Dependencies: Query-wise calibration policies; cost-aware sampling; governance for decisions.
- Continual improvement via synthetic labels and retraining
- What: Use teacher feedback and refined rankings to generate pseudo-labels, then periodically fine-tune embedders to reduce reliance on LLMs over time.
- Potential products: Self-improving vector search platforms; scheduled fine-tune jobs.
- Dependencies: Label quality control; drift detection; evaluation pipelines to prevent degenerate behaviors.
- Privacy-preserving and federated feedback
- What: Secure enclaves/on-device teachers or federated setup to enable refinement without exposing sensitive text to external services.
- Potential products: Confidential computing integrations; on-device relevance scoring on laptops/edge.
- Dependencies: Efficient small teachers; hardware support (TEEs/GPU on edge); strict telemetry policies.
- Real-time/streaming adaptation
- What: Apply refinement to streaming data and dynamic corpora, with incremental indexing and adaptive K to meet tight SLAs.
- Potential products: Streaming search for observability, news monitoring; low-latency alerting.
- Dependencies: Incremental vector indexes; budget-aware controllers for K and steps; backpressure handling.
- Retrieval orchestration policies and meta-controllers
- What: Controllers that decide when to invoke refinement, choose K, pick the teacher, or skip refinement based on query difficulty and cost constraints.
- Potential products: “Retrieval policy engines” for cost–quality optimization.
- Dependencies: Query difficulty estimators; A/B feedback loops; governance and transparency.
Cross-cutting assumptions and dependencies
- Teacher model quality and bias: Refinement inherits teacher judgments; domain-fit of the teacher is critical.
- Initial top‑K quality: The method assumes some positives appear in top‑K; extreme class imbalance may require better candidate selection.
- Latency/cost budget: Each query typically uses K≈20 LLM scorings; budgets must accommodate this (or use lighter teachers).
- Data governance: Ensure compliance when sending content to teachers; prefer on-prem/private LLMs for sensitive sectors.
- Embedding access: Need access to raw embeddings (or API) to compute cosine similarities and update the query vector; no model weight updates required.
- Thresholding: For classification-style separations, per-query thresholding strategies influence end-to-end utility and must be chosen to fit the domain.
Glossary
- Active learning: A strategy that selects the most informative instances for labeling to maximize model improvement with minimal annotation effort. "This evokes the established field of active learning"
- ArgKP-21: A dataset for key-point matching from the 2021 Key Point Analysis shared task. "Here we experiment with ArgKP-21, key-point matching data from the 2021 KPA shared task"
- Average precision (AP): The area under the precision–recall curve for a single query, summarizing ranking quality. "The plot legend denotes the corresponding average precision (AP) scores."
- Cosine similarity: A similarity measure that compares the angle between two vectors, commonly used for embedding similarity. "we use the cosine similarity between the embeddings of and ."
- Cross-encoder (reranker): A model that jointly encodes the query and document to score relevance for reranking retrieved candidates. "scores from a separate retriever or cross-encoder reranker for some top-ranked documents"
- Dense retriever: A retrieval model that uses dense (neural) embeddings instead of sparse term matching to find relevant documents. "The advances in general-purpose dense retriever models have partly been driven by progress in generative LLMs"
- Entailment (in NLP): A semantic relation where one text logically implies or supports another. "where entails "
- Few-shot demonstrations: A small set of example pairs provided with the query to condition or guide the model at inference time. "have explored an option of supplying the embedder with few-shot demonstrations with each query."
- HyDE: A retrieval method that replaces the user query with an LLM-generated hypothetical document to improve matching. "A popular approach for improving zero-shot retrieval performance is HyDE"
- Instruction-tuning: Fine-tuning models on instruction-formatted data to improve instruction following and generalization. "have incorporated this approach into large-scale instruction-tuning pipelines"
- Key-point analysis: A framework that maps many free-text opinions onto a set of concise key points to enable quantitative summarization. "Key-point analysis \citep{bar-haim-etal-2020-arguments} is an approach for obtaining a high-level quantitative summary of a large collection of opinions."
- Kullback–Leibler (KL) divergence: An information-theoretic measure of how one probability distribution differs from another. "where is the KullbackâLeibler divergence,"
- List-wise scoring: A ranking approach that evaluates or optimizes over a list of items jointly rather than individually. "by replacing pointwise relevance scoring with list-wise or set-wise scoring strategies"
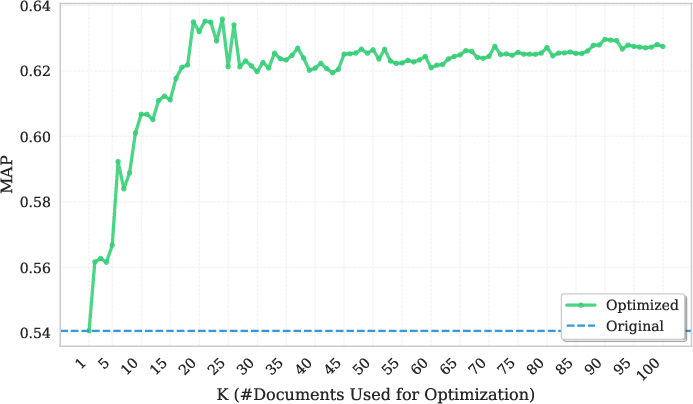
- Mean Average Precision (MAP): The mean of average precision across queries; a standard metric for evaluating ranking quality over a dataset. "Our primary metric for task separation quality is the mean average precision (MAP) across the dataset queries."
- MTEB: The Massive Text Embedding Benchmark, which evaluates embedding models across many downstream tasks. "benchmarks such as MTEB \cite{muennighoff-etal-2023-mteb}, which measure embedding quality across a range of target tasks."
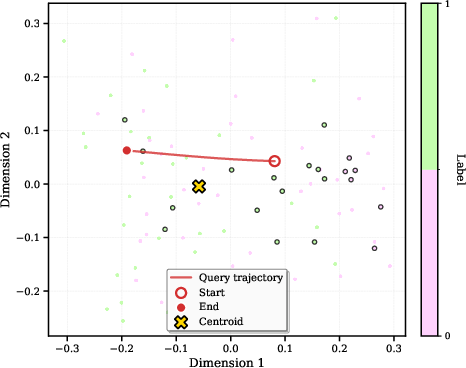
- PCA (Principal Component Analysis): A dimensionality reduction technique that projects high-dimensional data onto principal components. "Figure \ref{fig:pca_example} depicts a PCA 2D projection of the embedding space"
- Pointwise relevance scoring: A method that scores each query–document pair independently rather than in pairs or lists. "by replacing pointwise relevance scoring with list-wise or set-wise scoring strategies"
- Precision–recall curve: A plot showing the trade-off between precision and recall at different thresholds to assess ranking/classification performance. "Precision-recall curve for an individual intent query from CLINC150"
- Pseudo-relevance feedback (PRF): A technique that uses top-ranked documents from an initial retrieval as feedback (assumed relevant) to refine the query or model. "often termed as a form of ``pseudo-relevance feedback'' (PRF)."
- Query refinement (LLM-guided): Adjusting a query or its embedding using feedback from an LLM at inference time to better align rankings with task needs. "LLM-guided query refinement yields consistent gains across all models and datasets"
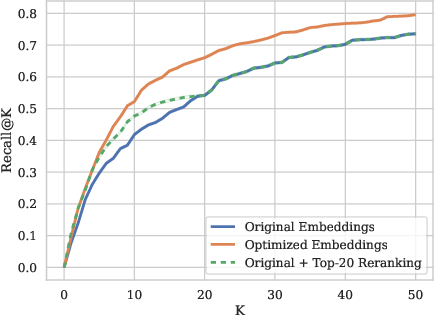
- Recall@K: The fraction of relevant documents retrieved within the top K results. "(b) Recall@K (aggregated across queries) for E5-Mistral-7B on RealScholarQuery."
- Retrieval-Augmented Generation (RAG): A paradigm that retrieves documents to provide context for a generative model, improving knowledge-intensive tasks. "Retrieval-Augmented Generation (RAG; \citealp{lewis2020rag,gao2024ragsurvey})"
- Reranker: A model that reorders an initial set of retrieved documents to improve ranking accuracy. "leverages feedback from an encoder or reranker to optimize representations"
- Softmax: A function that converts a vector of scores into a probability distribution. "where and are the softmax over and ."
- Teacher model: A stronger model that provides supervisory signals (e.g., scores) to guide or refine another model at test time. "these feedback scores are given by a teacher model , which is a generative LLM."
- Test-time optimization: Adapting inputs or intermediate representations during inference to improve performance on a specific instance. "We apply test-time optimization that uses a feedback signal from to modify the query representation"
- Threshold tuning: Selecting a score cutoff to convert ranked results or scores into binary decisions. "or a threshold-tuning approach (see e.g., \citealp{chausson2025insight, vannooten2025sizedoesfitall})."
- TREC relevance narratives: Detailed, human-written relevance descriptions from TREC used to specify nuanced retrieval criteria. "a benchmark derived from rigorous TREC relevance narratives."
- Zero-shot classification: Assigning labels without task-specific training data, relying on generalization from pretrained models. "zero-shot classification with a general-purpose embedding model, in response to an ad-hoc user input, remains a major challenge."
Collections
Sign up for free to add this paper to one or more collections.