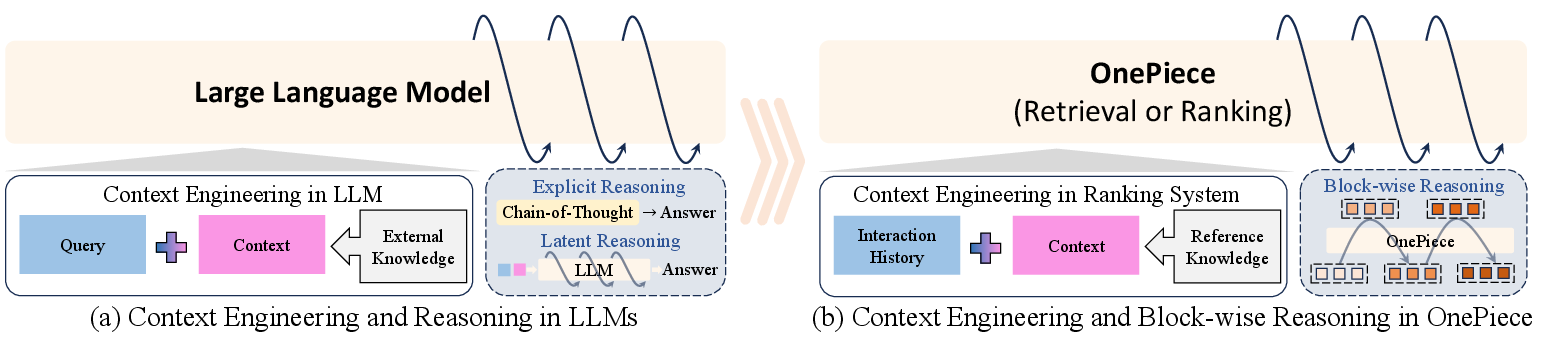
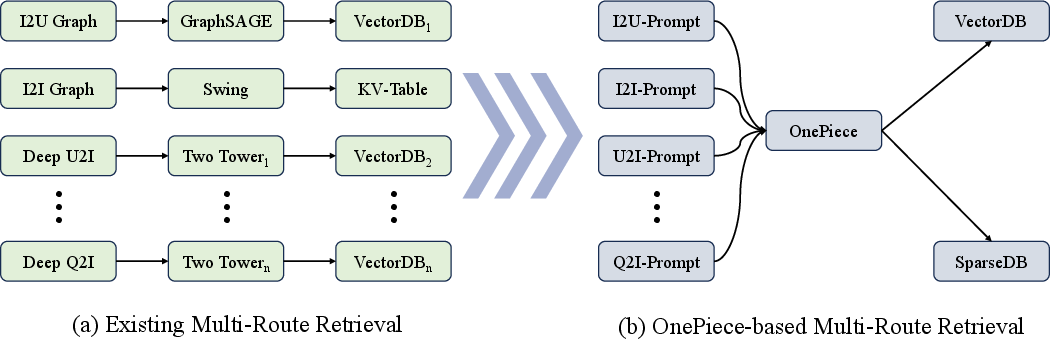
OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System
Abstract: Despite the growing interest in replicating the scaled success of LLMs in industrial search and recommender systems, most existing industrial efforts remain limited to transplanting Transformer architectures, which bring only incremental improvements over strong Deep Learning Recommendation Models (DLRMs). From a first principle perspective, the breakthroughs of LLMs stem not only from their architectures but also from two complementary mechanisms: context engineering, which enriches raw input queries with contextual cues to better elicit model capabilities, and multi-step reasoning, which iteratively refines model outputs through intermediate reasoning paths. However, these two mechanisms and their potential to unlock substantial improvements remain largely underexplored in industrial ranking systems. In this paper, we propose OnePiece, a unified framework that seamlessly integrates LLM-style context engineering and reasoning into both retrieval and ranking models of industrial cascaded pipelines. OnePiece is built on a pure Transformer backbone and further introduces three key innovations: (1) structured context engineering, which augments interaction history with preference and scenario signals and unifies them into a structured tokenized input sequence for both retrieval and ranking; (2) block-wise latent reasoning, which equips the model with multi-step refinement of representations and scales reasoning bandwidth via block size; (3) progressive multi-task training, which leverages user feedback chains to effectively supervise reasoning steps during training. OnePiece has been deployed in the main personalized search scenario of Shopee and achieves consistent online gains across different key business metrics, including over $+2\%$ GMV/UU and a $+2.90\%$ increase in advertising revenue.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OnePiece, a new way to improve how online stores and apps show you items you might like. It brings two ideas from powerful LLMs (like ChatGPT) into search and recommendation systems:
- Context engineering: give the model better “clues” before it makes a decision.
- Multi-step reasoning: let the model think through its decision in steps, instead of jumping straight to an answer.
By combining these ideas, OnePiece helps both parts of a typical shopping system: finding a good set of items (retrieval) and sorting them in the best order (ranking).
What questions did the paper ask?
The paper focuses on two main questions:
- How can we give ranking models richer, more helpful input, beyond just a simple list of things a user clicked?
- How can we train models to “think in steps” using the kinds of feedback that happen naturally in shopping (like clicks, adding to cart, and purchases), even though we don’t have written explanations of why a user chose something?
How did the researchers approach the problem?
A quick tour of how online stores show you items
Imagine a giant library of products. Showing the right items is usually done in two stages:
- Retrieval: quickly find a small set of likely items from millions, a bit like pulling a shortlist from the whole library.
- Ranking: carefully sort that shortlist so the very best items appear at the top.
This “funnel” keeps things fast while still aiming for high quality results.
The OnePiece idea: give better context + think in steps
OnePiece uses a Transformer model (a type of AI that is good at paying attention to useful parts of the input). It adds two key upgrades:
- It builds a richer input “story” for the model, instead of just handing it a plain list of past clicks.
- It lets the model refine its decision through multiple steps, like a student showing their work, making the final choice more accurate.
Building the input “story”
To make smart decisions, models need context—like a detective gathering clues. OnePiece creates a unified sequence of tokens (little pieces of information) the model can read in both retrieval and ranking:
- Interaction history: what items the user interacted with over time, in order.
- Preference anchors: expert-chosen reference items related to the current situation, like top-clicked products under a specific search. This gives strong hints about what’s popular and relevant.
- Situational descriptors: facts about the user and the current query (like age or the search text), so the model knows the setting.
- Candidate item set (ranking only): a small group of items considered together so the model can compare them directly, instead of judging each one in isolation.
Think of this like giving the model a well-organized file: past behavior, helpful examples, the current situation, and the options to pick from.
Thinking in steps (block-wise reasoning)
Rather than making a snap decision, OnePiece lets the model think in stages. It does this by creating “blocks” of hidden states that carry information forward and get refined step by step.
- In retrieval: the block focuses on scenario signals (like the user and query), strengthening both personalization and relevance over steps.
- In ranking: the block covers the whole candidate group (for example, 12 items at a time). The model refines its view of all items together, comparing them fairly.
This “block-wise” design gives the model enough “bandwidth” to keep important details at each step, instead of squeezing everything into a single tiny summary.
Training the model like a school curriculum
You don’t start with calculus on day one. OnePiece trains the model with a progressive curriculum that matches natural shopping behavior:
- Early steps learn from common signals (like clicks).
- Later steps learn from more serious signals (like purchases), which are rarer but more meaningful.
This way, each reasoning step practices a task of the right difficulty, building from easy to hard.
What did they find?
The researchers tested OnePiece on Shopee, a huge e-commerce platform. They saw improvements both offline (in controlled experiments) and online (with real users):
- The richer context (better input clues) improved retrieval and ranking quality.
- The multi-step reasoning added even more gains.
Here are some simple highlights:
- Offline, context engineering boosted how many clicked items are found in the top results and improved ranking accuracy. Adding block-wise reasoning increased these scores further.
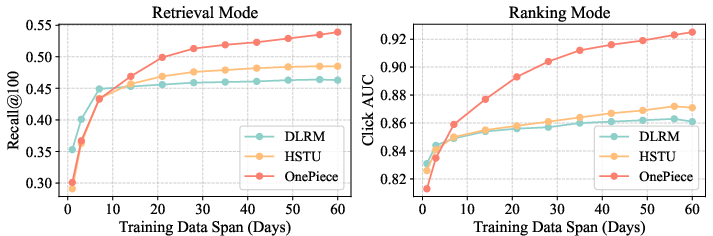
- OnePiece needed less training data to do well and kept improving as more data was added, while traditional models stopped getting better as quickly.
- In real-world A/B tests:
- Retrieval increased money per user (GMV/UU) by about +1.08%.
- Ranking increased GMV/UU by about +1.12% and raised advertising revenue by +2.90%.
- OnePiece covered nearly 70% of impressions found by other methods and contributed twice as much unique value as a strong baseline, showing it both matches existing routes and finds new good items.
Why this matters: it means users are seeing more relevant items, clicking more, and buying more—without making the system slower or less practical to run.
Why does it matter?
OnePiece shows that ideas from LLMs—better input context and step-by-step reasoning—can make real-world shopping systems smarter:
- Better user experience: users see items that fit their tastes and current needs.
- Business impact: more clicks, more purchases, and more ad effectiveness.
- Practical deployment: it fits into existing two-stage pipelines and uses efficient techniques, making it suitable for large platforms.
Big picture: this work is one of the first to successfully bring “prompting” and “reasoning”—core strengths of modern AI—into industrial search and recommendation at scale. It suggests a path forward for many online services to become more helpful and more efficient by teaching models to both read richer context and think through their decisions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- External validity beyond a single e-commerce search scenario: no evaluation on other domains (content feeds, video, news), marketplaces with different dynamics, or purely recommendation settings without queries.
- Cold-start robustness is untested: performance for new users, new items, and new queries with scarce history or anchors is not reported.
- Long-tail impacts and popularity bias: using preference anchors (e.g., top-clicked items) risks amplifying head-item bias; effects on item diversity, seller fairness, and long-tail recall/rank quality are not analyzed.
- Anchor construction design is under-specified: criteria, data sources, refresh cadence, candidate pool size, deduplication, and robustness to noisy/misaligned anchors are not ablated.
- Sensitivity to anchor type and quantity: no study of how many anchors/groups are needed, which anchor families help (clicks vs purchases vs CF neighbors), and how performance degrades with noisy or adversarial anchors.
- Situational descriptors (SD) scope and quality: unclear which features are included, how missing/noisy features are handled, and the contribution of each SD subcomponent via ablation.
- Tokenization/order choices: no analysis on different ordering rules, boundary tokens, or relative vs absolute positional encodings for IH/PA/SD segments.
- Sequence length scaling: limits of IH length, truncation/recency policies, and memory/latency trade-offs are not explored.
- Ranking candidate grouping introduces non-global context: the grouped setwise approach does not compare items across groups; impact on global ranking consistency and transitivity is not quantified.
- Group size (C) sensitivity/latency trade-off: no ablations on varying C, its effect on accuracy/latency/memory, or adaptive grouping strategies.
- Randomized grouping at inference can cause nondeterminism: stability, reproducibility, and user-perceived jitter due to random grouping are not discussed; deterministic serving strategies are not provided.
- Cross-group calibration: how scores remain comparable across independently processed groups is not analyzed or guaranteed.
- Block-wise reasoning design choices: selection of block size M per mode, number of reasoning steps K, diminishing returns, and principled schedules are not studied.
- Early-exit or budget-aware reasoning: no mechanism to adapt K online given latency budgets or confidence; absence of anytime inference.
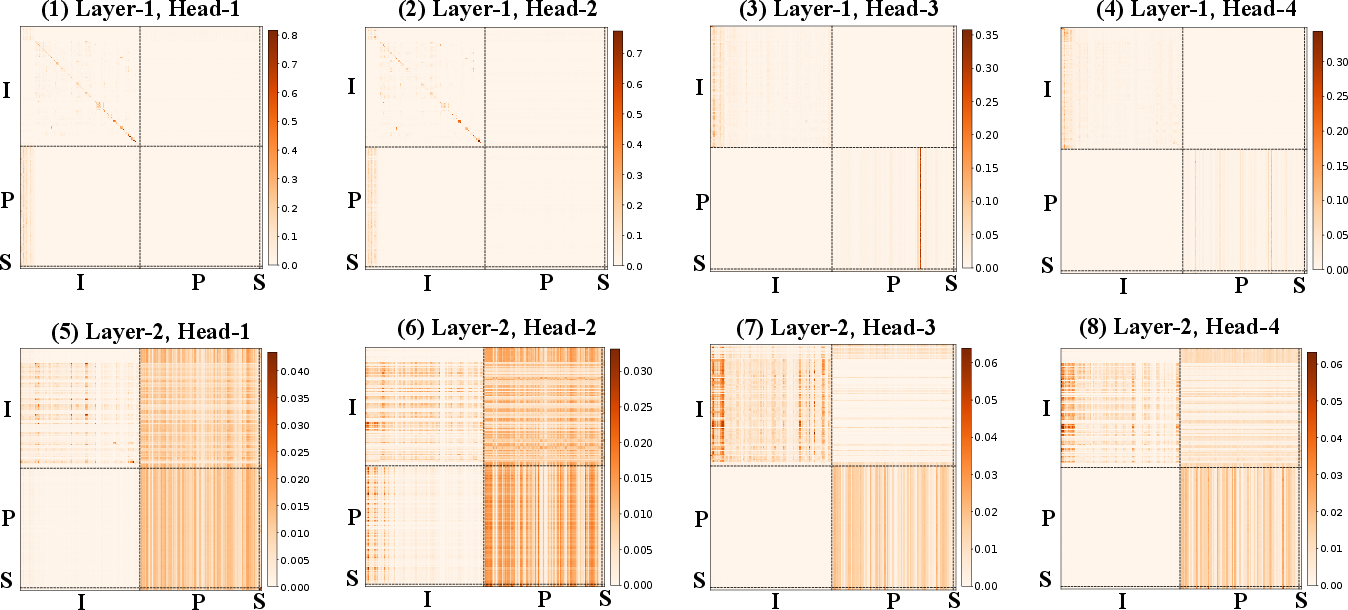
- Reasoning interpretability: the latent multi-step process is opaque; tools to attribute outcomes to IH/PA/SD/CIS or to inspect block-level contributions are missing.
- Curriculum design and task assignment: rationale for task ordering (click→cart→order), handling non-monotonic preferences across tasks, and sensitivity to alternative curricula are not evaluated.
- Multi-task interference and weighting: no analysis of negative transfer across steps, task loss weighting, or mitigation techniques (e.g., gradient surgery).
- Handling missing/implicit labels: approach to biased or missing feedback (e.g., unobserved negatives, exposure bias) in BCE and contrastive losses is not specified.
- Contrastive negative sampling: false-negative risk, negative pool construction, and debiasing strategies (e.g., popularity-aware or hard-negative mining) are not addressed.
- Calibration and uncertainty: probability calibration (ECE/Brier), score reliability under distribution shift, and uncertainty estimates are not reported.
- Distribution shift and seasonality: robustness to query/product drift, promotions, or holiday spikes is not evaluated; no continual learning or drift detection strategy is provided.
- Retrieval serving policy: which step’s user embedding (r_k) is used for ANN queries in production, and whether multi-step representations are ensembled or adapted to different objectives, is unclear.
- ANN index/update compatibility: cadence of item embedding refreshes, index rebuild cost, and alignment between block-wise reasoning and dual-tower retrieval latency constraints are not detailed.
- Memory/latency/throughput in production: while a complexity analysis is given, concrete online latency, memory footprint (KV cache), QPS capacity, and hardware cost compared to baselines are not reported.
- Pre-ranking stage: integration into a full multi-stage cascade beyond retrieval and final ranking (e.g., pre-ranking) is not explored.
- Metric coverage: lack of top-k ranking metrics (e.g., NDCG@k), diversity/novelty, and user-centric long-term metrics; offline–online correlation is not quantified.
- Online A/B testing methodology: experiment duration, confidence intervals, user/segment heterogeneity, regional effects, and potential trade-offs on guardrail metrics are omitted.
- Fairness and exposure control: impact on seller/category/geography fairness and exposure constraints, especially given anchor-driven context, is not assessed.
- Privacy and compliance: how user profiles and histories in context engineering comply with privacy regulations, data minimization, and on-device vs server processing is not discussed.
- Adversarial and spam robustness: vulnerability to manipulation (e.g., gaming anchors via fake clicks) and mitigation mechanisms are unaddressed.
- Cross-modal/text modeling: details on text/image features within φ_item/φ_query and their training (pretraining, multilingual support) are sparse; cross-lingual robustness is not evaluated.
- Reproducibility: public datasets, code, and full hyperparameter/specification details are not provided; replicability on open benchmarks is missing.
- Theoretical grounding: no formal view linking block-wise reasoning to optimization/EM/iterative refinement, or guarantees on convergence/expressivity relative to standard Transformers.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s framework (structured context engineering, block-wise latent reasoning, and progressive multi-task training) to existing retrieval–ranking pipelines.
- E-commerce search and recommendation (Retail/Marketplaces)
- Use case: Lift GMV/UU, CTR, and conversion by enhancing both retrieval and ranking with structured context and multi-step reasoning, mirroring Shopee’s reported +1–2% GMV/UU and +2.90% ad revenue gains.
- OnePiece components: IH+PA+SD tokenization; grouped setwise ranking (CIS); block-wise reasoning; progressive tasks (click → add-to-cart → purchase).
- Tools/products/workflows: “Context Tokenizer” SDK to build IH/PA/SD/CIS tokens; ANN user–item retrieval with bidirectional contrastive learning; KV-cached Transformer serving; randomized candidate grouping; set-contrastive loss for ranking.
- Assumptions/dependencies: Multi-behavior logs (impression/click/cart/order), feature stores for anchors (e.g., top-clicked/purchased by query), GPU/accelerator budget, ANN infrastructure, latency budgets compatible with Transformer+reasoning, privacy compliance (PII governance).
- Sponsored ads ranking and auction quality (Advertising/Marketing tech)
- Use case: Improve ad matching and ordering by aligning earlier reasoning blocks to click-quality and later blocks to revenue/proxy-conversion quality; reduce clickbait by emphasizing deeper outcomes.
- OnePiece components: Progressive multi-task heads per reasoning block; set-wise ranking within candidate ad groups.
- Tools/products/workflows: Multi-objective label orchestrator mapping blocks to click/conversion/fraud filters; online A/B test playbooks; monotonic calibration or constraints layered on top of block outputs.
- Assumptions/dependencies: Accurate attribution, ad policy constraints, guardrails for budget pacing and fairness, compatibility with existing auctions.
- Content feeds and media recommendation (Video/Music/News/Social)
- Use case: Better feed quality by extending context beyond raw sequences (anchors for topicality/diversity) and enabling cross-candidate comparison to avoid redundant items.
- OnePiece components: Preference anchors (e.g., trending items per topic), grouped setwise ranking for de-duplication and intra-group diversity, progressive tasks (view → dwell → completion → follow/subscribe).
- Tools/products/workflows: Diversity-aware anchor generators; session-level block-wise metrics to inspect intermediate reasoning; replay evaluations with progressive metrics.
- Assumptions/dependencies: Well-defined multi-level outcomes, content safety filters, content taxonomies for anchors.
- Enterprise and app-store search (Software/Enterprise)
- Use case: Improve retrieval and ranking of apps/documents by unifying user profile, query semantics, and domain anchors (e.g., most installed apps for similar roles or teams).
- OnePiece components: SD-rich tokenization (role, device, org), anchors derived from peer usage, block-wise refinement over user and query tokens in retrieval.
- Tools/products/workflows: Org-level anchor caches, on-device/edge inference for latency, offline constraint testing (licensing, entitlements).
- Assumptions/dependencies: Access-controlled signals, org privacy boundaries, limited compute at the edge.
- Marketplace matching and supply discovery (Logistics/Gig/Travel)
- Use case: Match users to supply items (drivers, freelancers, listings) by leveraging context and progressive labels (view → inquiry → booking).
- OnePiece components: Structured tokens with scenario descriptors (time, location, price band), block-wise retrieval emphasizing relevance/personalization separately via user/query aggregation tokens.
- Tools/products/workflows: Scenario-specific anchor builders (e.g., top-accepted drivers at this hour), ANN + two-tower migration guides, constraint-aware re-ranking overlay.
- Assumptions/dependencies: Real-time features (geo/ETA), fairness and regulatory constraints, supply/demand anti-gaming controls.
- Data efficiency upgrades for small/medium platforms (SMB Platforms/Startups)
- Use case: Achieve stronger sample efficiency than DLRM baselines by leveraging anchors and progressive supervision, useful when historical logs are short.
- OnePiece components: Lightweight PA construction, BCE + bidirectional contrastive training in retrieval, SCL in ranking.
- Tools/products/workflows: Minimal Anchor Service (global-trending, category-top lists); elastic training on limited GPUs; day-by-day incremental training protocol.
- Assumptions/dependencies: Enough behavioral stratification for progressive tasks; careful regularization to avoid overfitting sparse labels.
- Observability and diagnostics of ranking (MLOps/Trust & Safety)
- Use case: Introduce process-level debugging by probing intermediate reasoning blocks aligned to labeled tasks (e.g., why click prediction was correct but purchase prediction failed).
- OnePiece components: Block-wise outputs with task-specific heads; causal block mask enabling interpretable progression.
- Tools/products/workflows: “Reasoning Block Probes” dashboards; per-block AUC/GAUC/Recall metrics; candidate-group stability tests (robustness to grouping randomness).
- Assumptions/dependencies: Logging of intermediate scores in shadow mode; privacy controls for debug data; cost–benefit tradeoff for extra telemetry.
- Cold-start mitigation via anchors (E-commerce/Content/Ads)
- Use case: Improve new-user/item performance by injecting collaborative anchors (e.g., top items for current query/category) alongside sparse history.
- OnePiece components: PA token groups with BOS/EOS boundaries; shared projection heads for IH and PA.
- Tools/products/workflows: Anchor-generation pipelines per locale/category; fallbacks when IH is short; exploration policy mixing.
- Assumptions/dependencies: High-quality catalogs and taxonomies; cross-lingual embeddings for queries/items when applicable.
- Curriculum-based experimentation and multi-objective control (Product/Optimization)
- Use case: Systematically map product KPIs to reasoning steps (early blocks = engagement; later blocks = conversion/long-term value) and measure trade-offs.
- OnePiece components: Progressive multi-task training; per-block heads and loss weights.
- Tools/products/workflows: KPI-to-task mapping templates; policy knobs to reweight block losses; staged rollout playbooks.
- Assumptions/dependencies: Reliable lag-adjusted labels (e.g., delayed conversions), business alignment on multi-objective targets.
Long-Term Applications
These ideas leverage the paper’s mechanisms but will need further research, domain adaptation, scaling, or validation before production.
- Healthcare information retrieval and triage (Healthcare)
- Use case: Rank guidelines or care pathways using progressive tasks (symptom relevance → test appropriateness → outcome utility), with block-wise refinement to balance personalization and safety.
- OnePiece components: SD for patient context; anchors from vetted clinical pathways; block-wise supervision with clinically validated labels.
- Dependencies: Regulatory approval, expert-curated labels (noisy or scarce), rigorous bias/safety audits, privacy-preserving infrastructure (HIPAA/GDPR).
- Education personalization (EdTech)
- Use case: Recommend learning resources with curriculum-aligned progressive tasks (click → dwell → mastery/assessment), using grouped setwise ranking to encourage diversity and avoid redundancies.
- OnePiece components: Anchors from prerequisite graphs; SD with learner profile; progressive supervision via assessment outcomes.
- Dependencies: Reliable mastery signals, content metadata quality, safeguards against shortcut learning or overfitting to engagement.
- Responsible multi-objective optimization (Policy/Platform Governance)
- Use case: Embed fairness, safety, and well-being as later-stage tasks to temper short-term engagement objectives, yielding policy-compliant ranking.
- OnePiece components: Progressive tasks including fairness/safety heads; per-block constraints; interpretable probes for audits.
- Dependencies: High-quality protected-attribute proxies or fairness definitions, legal compliance frameworks, stakeholder-approved trade-offs.
- Cross-domain unified retrieval–ranking (Finance/Travel/Insurance)
- Use case: Recommend complex bundles (e.g., financial products, itineraries) via block-wise reasoning across heterogeneous signals and progressive outcomes (click → inquiry → approval/booking).
- OnePiece components: Rich SD and PA across domains; block size tuned per scenario; bidirectional contrastive learning for heterogeneous corpora.
- Dependencies: Label scarcity at deep outcomes, strict risk/compliance checks, explanation requirements.
- Enterprise knowledge assistants and RAG hybrids (Software/Enterprise AI)
- Use case: Combine OnePiece retrieval/ranking with LLMs for grounded generation: use block-wise refined candidates as RAG contexts; anchors from curated corpora.
- OnePiece components: Context engineering for retrieval candidates; progressive tasks aligning relevance → trustworthiness → policy compliance; block outputs feeding LLM prompts.
- Dependencies: Tight latency budgets, hallucination controls, document-level safety/factuality scoring.
- On-device/federated personalization with reasoning (Privacy-preserving AI)
- Use case: Deploy compact block-wise models on device with federated updates; anchors derived locally; progressive tasks aligned to user-centric objectives.
- OnePiece components: Model compression/distillation of reasoning blocks; KV-cached local inference; anchor generation on device.
- Dependencies: Model size/energy constraints, privacy budgets, secure aggregation, robustness to non-IID data.
- Auto-anchoring and self-supervised anchors (Foundational Recsys Research)
- Use case: Learn anchors automatically (e.g., via clustering or contrastive pretraining) rather than hand-crafted business rules to improve portability across domains.
- OnePiece components: PA learned from self-supervised objectives; anchor-group BOS/EOS retained for structure.
- Dependencies: Unsupervised quality controls, stability under distribution shift, prevention of degenerate anchors.
- Causal-aware progressive supervision (Methodological advance)
- Use case: Reduce bias from click signals by integrating causal corrections in early blocks and reserving outcome-causal targets (e.g., purchase) for later blocks.
- OnePiece components: Progressive heads with de-biasing (IPS/DR) at early steps; causal constraints across steps.
- Dependencies: Propensity estimation accuracy, stable training with inverse weights, robust offline policy evaluation.
- Reasoning diagnostics for audits and regulation (Policy/Compliance)
- Use case: Provide regulators and auditors with per-block evidence showing how engagement vs. conversion vs. safety signals influence outcomes.
- OnePiece components: Block-wise explanations, mask-ablations demonstrating monotonicity/constraint adherence, per-block fairness reporting.
- Dependencies: Agreed-upon interpretability standards, secure audit interfaces, privacy-preserving telemetry.
- Robotics and operations matching (Robotics/Operations Research)
- Use case: Rank task or skill candidates for robots/operators using context engineering (state, constraints) and progressive tasks (feasibility → efficiency → safety).
- OnePiece components: SD for environment constraints; anchors from successful task libraries; block-wise refinement for multi-criteria decisions.
- Dependencies: High-fidelity simulators, safety-critical validation, real-time latency guarantees.
Notes on feasibility across applications:
- Compute/latency: Block-wise reasoning adds cost; KV caching and small block sizes mitigate but do not eliminate overhead.
- Data requirements: Progressive training depends on stratified multi-level feedback; proxies may be needed in domains lacking deep outcomes.
- Privacy/compliance: Structured context (SD/PA) may include sensitive signals; enforce privacy-by-design and data minimization.
- Robustness/bias: Anchors reflect historical behavior and may encode bias; audits and diversification strategies are required.
- Integration risk: Grouped setwise ranking assumes randomized grouping; production systems need robust grouping services and monitoring for position or correlation leakage.
Glossary
- A/B testing: An online experimental method that compares two or more system variants to measure causal impact on metrics. "Online A/B testing confirms that OnePiece delivers consistent business gains"
- approximate nearest neighbor (ANN) search: A fast retrieval technique that finds items with vectors close to a query without exhaustive search. "Retrieval is then performed via approximate nearest neighbor (ANN) search based on the similarity between user and item representations, typically computed as inner product or cosine similarity."
- Bidirectional Contrastive Learning (BCL): A batch-level contrastive objective aligning users and items in both user-to-item and item-to-user directions. "Bidirectional Contrastive Learning (BCL) operates at the batch level, enabling global contrastive reasoning across the in-batch samples."
- binary cross-entropy (BCE) loss: A pointwise classification loss for calibrated probabilities on binary labels. "Binary Cross-Entropy Loss (BCE) operates at the point-wise level, providing calibrated probability estimates for individual user-item pairs:"
- bi-directional Transformer: A Transformer encoder that allows attention over both past and future positions in the sequence. "We adopt an -layer bi-directional Transformer~\citep{vaswani2017attention} with pre-normalization for the backbone architecture."
- block-wise latent reasoning: Iterative refinement of model representations using blocks of hidden states to increase reasoning bandwidth. "block-wise latent reasoning, which equips the model with multi-step refinement of representations and scales reasoning bandwidth via block size;"
- Candidate Item Set (CIS): A set of candidate item tokens jointly encoded to enable intra-set comparisons for ranking. "Candidate Item Set (CIS, ranking mode only) contains complete feature representations of candidate items to enable fine-grained comparison and scoring."
- cascade ranking: A multi-stage pipeline that filters candidates with lightweight models before applying heavier models to smaller sets. "Cascade ranking has become the dominant paradigm in industrial large-scale ranking systems due to its ability to balance computational efficiency and ranking quality."
- chain-of-thought supervision: Training signals that guide models using explicit intermediate reasoning steps. "ranking models cannot readily exploit prompt-style contexts or chain-of-thought supervision"
- CLIP: A vision-LLM using contrastive learning, used here as inspiration for batch-level contrastive objectives. "Drawing inspiration from CLIP~\citep{radford2021learning}, we propose BCL optimization objective that consists of two symmetric components:"
- curriculum learning: A training strategy that progresses from simpler to more complex tasks to improve learning. "We introduce a progressive multi-task training paradigm that implements curriculum learning~\citep{bengio2009curriculum} through gradually increasing task complexity."
- DCNv2: The second version of Deep & Cross Network for modeling explicit high-order feature crosses. "DCNv2~\citep{wang2021dcn} captures high-order cross features."
- Deep Learning Recommendation Models (DLRMs): A class of recommendation architectures based on deep neural networks and feature interactions. "incremental improvements over strong Deep Learning Recommendation Models (DLRMs)"
- DIN-like: Components inspired by Deep Interest Network that apply attention over user history for target relevance. "it employs a DIN-like~\citep{zhou2018deep} structure and zero-attention~\citep{ai2019zero}."
- dual-tower architecture: Retrieval design with separate encoders for user context and item features, enabling efficient similarity search. "Industrial systems commonly adopt a dual-tower architecture: a user tower transforms user context into a dense representation , while an item tower independently transforms each item into ."
- GAUC: Grouped Area Under the ROC Curve that aggregates AUC over groups (e.g., queries or users). "For each type, we report both AUC and GAUC, denoted as C-AUC/C-GAUC, A-AUC/A-GAUC, and O-AUC/O-GAUC, respectively."
- GMV/UU: Gross Merchandise Value per Unique User, a business metric for monetization efficiency. "including over GMV/UU and a increase in advertising revenue."
- grouped layer normalization (grouped LN): A variant of layer normalization applied over groups of channels for efficiency or stability. "where denotes layer normalization (grouped LN can be used in practice)."
- grouped setwise strategy: Ranking approach that partitions candidates into small groups for joint encoding to balance expressiveness and cost. "To strike a balance between efficiency and expressiveness, we adopt a grouped setwise strategy:"
- KV Caching: Reusing cached key–value pairs in attention to reduce computation across reasoning steps. "For the reasoning phase, we employ the KV Caching technique to reuse historical key–value pairs"
- layer normalization (LN): A normalization technique applied to neural network activations within a layer. "where denotes layer normalization (grouped LN can be used in practice)."
- MHSA (multi-head self-attention): Attention mechanism with multiple heads that captures diverse relational patterns in sequences. "where is multi-head self-attention with bi-directional attention"
- pre-normalization: Applying layer normalization before attention and feed-forward sublayers to improve training stability. "We adopt an -layer bi-directional Transformer~\citep{vaswani2017attention} with pre-normalization for the backbone architecture."
- progressive multi-task training: Supervising successive reasoning blocks with tasks of increasing complexity using multi-level feedback. "progressive multi-task training strategy that leverages naturally available user feedback chains (e.g., click, add-to-cart, order) as staged supervision signals."
- Reasoning Position Embeddings (RPE): Learnable embeddings indicating the reasoning step index to differentiate blocks. "we introduce Reasoning Position Embeddings (RPE)."
- Recall@100: Retrieval metric measuring the proportion of relevant (e.g., clicked) items found within the top 100. "context engineering improves Recall@100 by "
- ResFlow: A residual-flow based backbone architecture used in the baseline ranking model. "The backbone is ResFlow~\citep{fu2024residual}, combined with DIN-like target attention and cross-attention"
- Set Contrastive Learning (SCL): A set-wise contrastive objective that compares each positive candidate against all candidates in the group. "Set Contrastive Learning (SCL) operates at the set-wise level, enabling each positive candidate to distinguish itself from negative candidates within the set:"
- situational descriptors (SD): Tokens encoding static user features and query-specific context for the current task. "Situational Descriptors (SD) represent static user features and query-specific information, providing essential context for the current ranking task."
- Transformer backbone: The core Transformer-based encoder architecture underpinning the model. "OnePiece is built on a pure Transformer backbone"
Collections
Sign up for free to add this paper to one or more collections.

