- The paper introduces NER Retriever, which uses mid-layer type-aware embeddings to achieve zero-shot named entity retrieval without prior fine-tuning.
- The approach employs a two-layer MLP with contrastive loss to project embeddings into a compact and discriminative space, significantly boosting R-Precision.
- Experimental results demonstrate superior performance over lexical and dense baselines on benchmarks like Few-NERD and MultiCoNER 2, validating its practical utility.
NER Retriever: Zero-Shot Named Entity Retrieval with Type-Aware Embeddings
Introduction and Motivation
The paper presents NER Retriever, a zero-shot framework for ad-hoc Named Entity Retrieval (NER) that leverages type-aware embeddings derived from LLMs. Unlike traditional NER systems constrained by fixed schemas and extensive labeled data, NER Retriever enables retrieval of entities belonging to user-defined, open-ended types without prior exposure or fine-tuning for those types. This approach is particularly relevant for real-world scenarios where entity categories are diverse, domain-specific, and often defined on-the-fly.
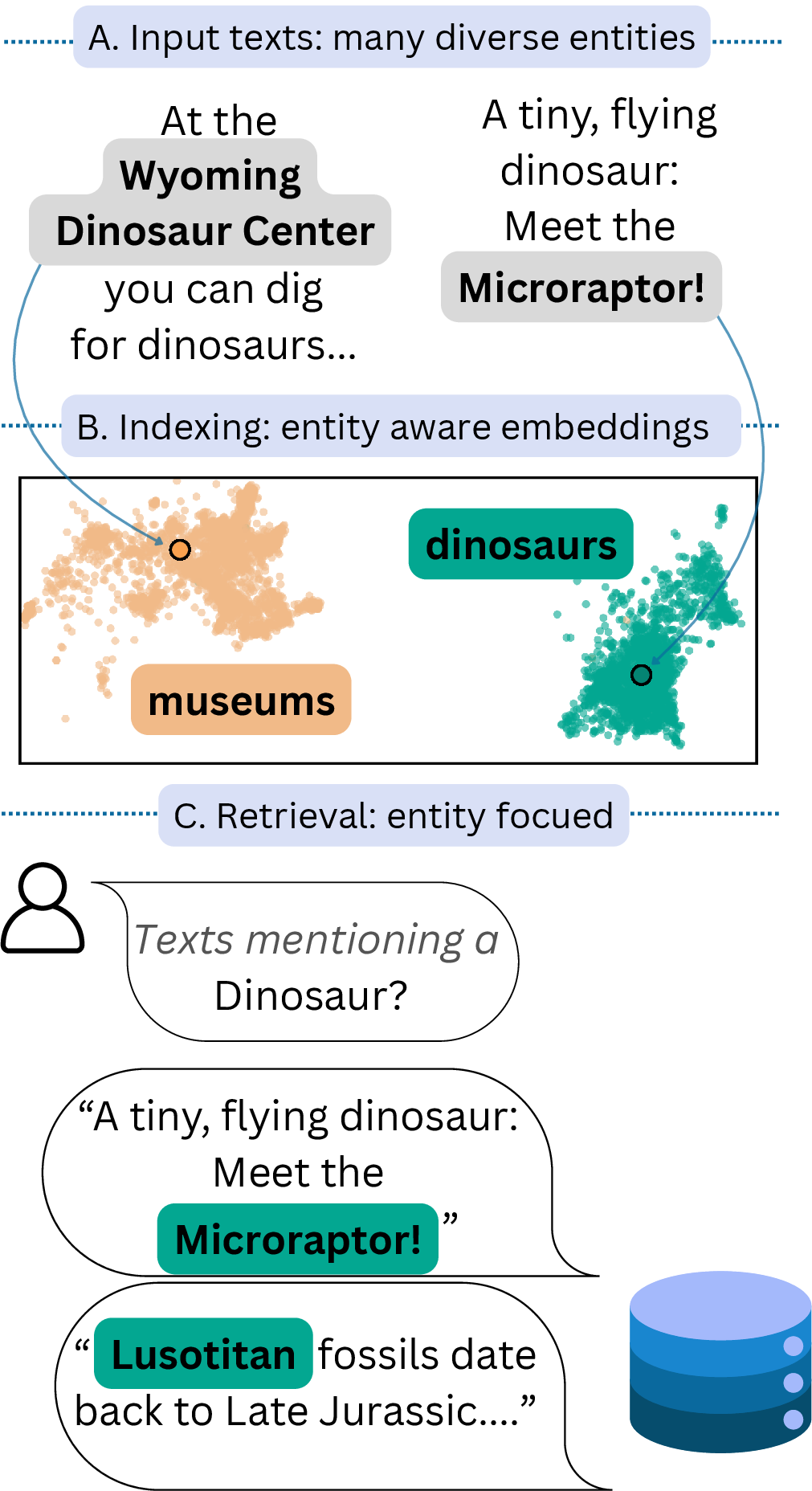
Figure 1: Example use case for ad-hoc Named Entity Retrieval given a query type (“dinosaur”).
System Architecture and Methodology
NER Retriever operates in three main phases: entity detection, indexing, and retrieval. During indexing, entity spans are detected in the corpus and embedded using contextual representations from a mid-layer (specifically, the value (V) vectors from block 17) of LLaMA 3.1 8B. These embeddings are then projected into a compact, type-aware space via a lightweight two-layer MLP trained with a contrastive objective. At query time, user-specified type descriptions are embedded using the same pipeline and matched to relevant entities via nearest-neighbor search.
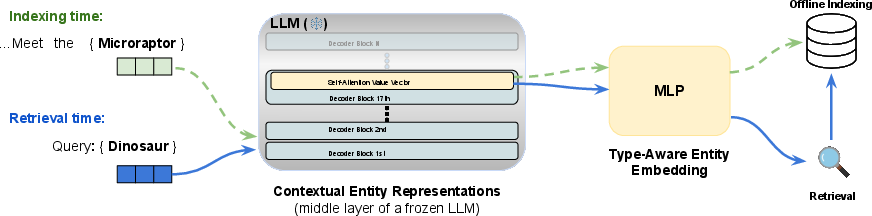
Figure 2: NER Retriever high-level architecture, illustrating the indexing and query-time retrieval pipelines.
A key innovation is the selection of mid-layer LLM representations, which the authors demonstrate encode fine-grained type information more effectively than top-layer outputs. The contrastive projection network further refines these representations, aligning entities of the same type and separating unrelated types.
Analysis of LLM Representations
The authors conduct a comprehensive analysis of LLM internal representations to identify the most type-sensitive embeddings. Using the Few-NERD dataset, they evaluate the type discrimination power of various layers and subcomponents across multiple LLMs. The value (V) vectors from block 17 of LLaMA 3.1 8B achieve the highest AUC (0.78), outperforming both earlier and final layers, as well as other architectures.
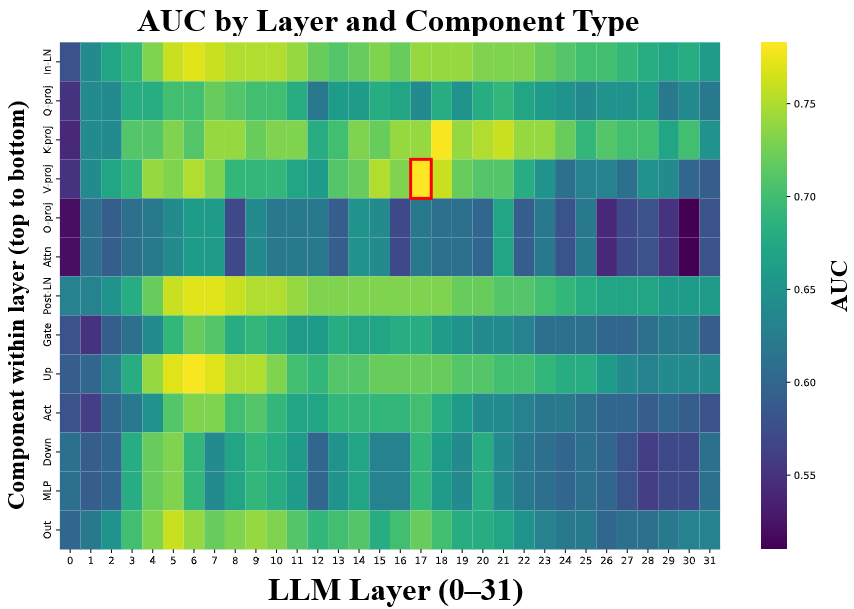
Figure 3: Entity-type discrimination AUC scores for 13 subcomponents across all 32 transformer blocks of LLaMA 3.1 8B.
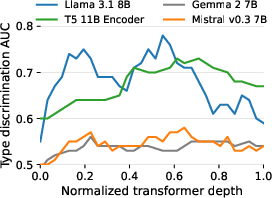
Figure 4: Type discrimination AUC for self-attention value (V) vectors across normalized transformer depth.
This empirical finding underscores the importance of careful representation selection for entity-centric tasks and provides practical guidance for embedding-based retrieval systems.
Type-Aware Entity Embeddings
To optimize for similarity-based retrieval, the high-dimensional LLM embeddings are distilled into a lower-dimensional, type-aware space using a two-layer MLP trained with triplet contrastive loss. The anchor is a type description, positives are entity mentions of that type, and negatives are mentions from other types, including hard negatives selected via BM25 similarity. This training regime encourages the model to tightly cluster same-type entities while maintaining separation from distractors.

Figure 5: 2D UMAP projection of type-aware entity embeddings for the top 25 Few-NERD types, showing tight clustering by type and clear separation between types.
The resulting embeddings are compact (500 dimensions), discriminative, and well-suited for efficient nearest-neighbor search.
Experimental Results
NER Retriever is evaluated on three benchmarks: Few-NERD, MultiCoNER 2, and NERetrieve. The system is compared against strong lexical (BM25) and dense retrieval baselines (E5-Mistral, NV-Embed v2), all in zero-shot settings.
- On Few-NERD, NER Retriever achieves an R-Precision of 0.34, outperforming NV-Embed v2 (0.04) and E5-Mistral (0.08).
- On MultiCoNER 2, NER Retriever attains an R-Precision of 0.32, more than three times higher than E5-Mistral (0.09) and four times higher than BM25 (0.08).
- On NERetrieve, NER Retriever matches NV-Embed v2 (0.29 vs. 0.28) and BM25 (0.28), with no statistically significant difference.
Precision@50 and Precision@200 metrics further confirm the system's effectiveness in top-k retrieval scenarios. The use of an entity span oracle (gold annotations) boosts performance by ~11%, highlighting the impact of accurate entity detection.
Ablation Studies
Ablation experiments isolate the contributions of key design choices:
- Layer Selection: Using block 17 V-projection improves R-Precision from 0.09 (final layer) to 0.19.
- Token Representation: Span-based representations outperform EOS-based ones (0.19 vs. 0.03 R-Precision).
- MLP Projection: The learned MLP significantly enhances retrieval performance over raw LLM embeddings.
Efficiency analysis shows that, despite storing one embedding per entity instance, NER Retriever's compact vectors (500 dimensions) result in lower storage requirements compared to sentence-level models (e.g., NV-Embed v2 at 4096 dimensions).
Practical and Theoretical Implications
NER Retriever demonstrates that mid-layer LLM representations, when refined with contrastive learning, enable robust zero-shot retrieval of fine-grained entity types. This approach is scalable, schema-free, and adaptable to diverse domains, making it suitable for information retrieval, question answering, and knowledge base construction. The findings challenge the prevailing reliance on top-layer LLM outputs and highlight the latent type-sensitive knowledge encoded in transformer architectures.
The system's reliance on parametric LLM knowledge may limit effectiveness in highly specialized domains. Future work could explore domain-adapted LLMs, improved entity detection, and integration with RAG-based agents for broad-query search.
Conclusion
NER Retriever offers a principled solution for zero-shot named entity retrieval, leveraging mid-layer LLM representations and contrastive projection to achieve state-of-the-art performance on fine-grained, open-ended entity types. The work provides empirical evidence for representation selection within LLMs and opens new avenues for embedding-based NER and retrieval systems.