Geometric Factual Recall in Transformers
Abstract: How do transformer LLMs memorize factual associations? A common view casts internal weight matrices as associative memories over pairs of embeddings, requiring parameter counts that scale linearly with the number of facts. We develop a theoretical and empirical account of an alternative, \emph{geometric} form of memorization in which learned embeddings encode relational structure directly, and the MLP plays a qualitatively different role. In a controlled setting where a single-layer transformer must memorize random bijections from subjects to a shared attribute set, we prove that a logarithmic embedding dimension suffices: subject embeddings encode \emph{linear superpositions} of their associated attribute vectors, and a small MLP acts as a relation-conditioned selector that extracts the relevant attribute via ReLU gating, and not as an associative key-value mapping. We extend these results to the multi-hop setting -- chains of relational queries such as ``Who is the mother of the wife of $x$?'' -- providing constructions with and without chain-of-thought that exhibit a provable capacity-depth tradeoff, complemented by a matching information-theoretic lower bound. Empirically, gradient descent discovers solutions with precisely the predicted structure. Once trained, the MLP transfers zero-shot to entirely new bijections when subject embeddings are appropriately re-initialized, revealing that it has learned a generic selection mechanism rather than memorized any particular set of facts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple-sounding question: how do transformer LLMs remember facts, like “Einstein’s birthplace is Ulm,” and how do they find the right fact when you ask a question?
The authors argue that transformers don’t have to store facts by cramming every pair (question → answer) into a big lookup table. Instead, they can store facts in a geometric way: they place the meanings of things (like people and places) as points in a space of numbers, so that the structure of that space itself helps the model recall the right answers. A small part of the model (an MLP, a tiny neural network) then acts like a smart selector, picking out the relevant piece of information when you name the relation you care about (like “birthplace” or “occupation”).
What questions did the paper ask?
In plain language, the paper explores:
- How can a transformer pack lots of facts efficiently?
- Can it do this by giving each subject (like a person’s name) a smart numeric representation that already “contains” its answers to many relations (birthplace, job, language, etc.)?
- For multi-step questions (like “Who is the mother of the wife of X?”), what is the most efficient way to remember and retrieve answers?
- Does training (gradient descent) actually discover these efficient, geometric solutions in practice?
- Do real, pretrained LLMs show signs of this geometric structure?
How did the researchers study it?
They combined math proofs with controlled computer experiments and light probing of real LLMs.
- Think of N subjects (like N different people) and R relations (like birthplace, occupation, etc.). For each relation r, there is a rule that pairs every subject with exactly one answer from the same shared pool of possible answers. That’s like having R different “perfect match” lists that map each person to one answer, all drawn from the same pile of names.
- The model’s job is: given a subject and a relation (one step), or a chain of relations (many steps), output the correct final answer.
- “Embedding dimension” means how many numbers you use to represent each token (like the length of each word’s ID card). “Logarithmic” growth in N, written , means this number of digits grows very slowly as you add more subjects.
Simple one-step questions (single-hop)
- The authors prove that you can solve all one-step questions using a very small embedding size: about numbers per token.
- Key idea: each subject’s embedding is a “superposition” (a neat stack) of the vectors for its answers to all R relations. Picture a sticker sheet with R colored sections; each section already holds the right answer for that relation.
- The small MLP acts like a selector switch: when you ask “birthplace,” it turns on only the “birthplace” section and reads that value out. This uses a simple “ReLU gate” (a switch that passes positive numbers and blocks negatives).
Harder multi-step questions (multi-hop)
- Without chain-of-thought (CoT): If you try to answer multi-step questions in one shot, you must pay a price. Either:
- make the MLP very wide (a big lookup memory), or
- make the embeddings very large (so they can store huge trees of possibilities).
- With chain-of-thought: If the model is allowed to write down intermediate answers (like doing math step by step), the bottleneck disappears. Then, the same small, efficient single-step mechanism can be repeated several times. This keeps the embedding size small, about , where k is the number of steps.
What did they find?
Here are the main results and why they matter:
- Single-step memory is very efficient with learned embeddings:
- Theory: A transformer can memorize all facts with embedding size and a small MLP. Subjects are encoded as superpositions of their R answers, and the MLP just selects the part you asked for. This is much more compact than storing every (subject, relation) → answer pair separately.
- Why it matters: It shows a path to storing lots of facts without blowing up model size.
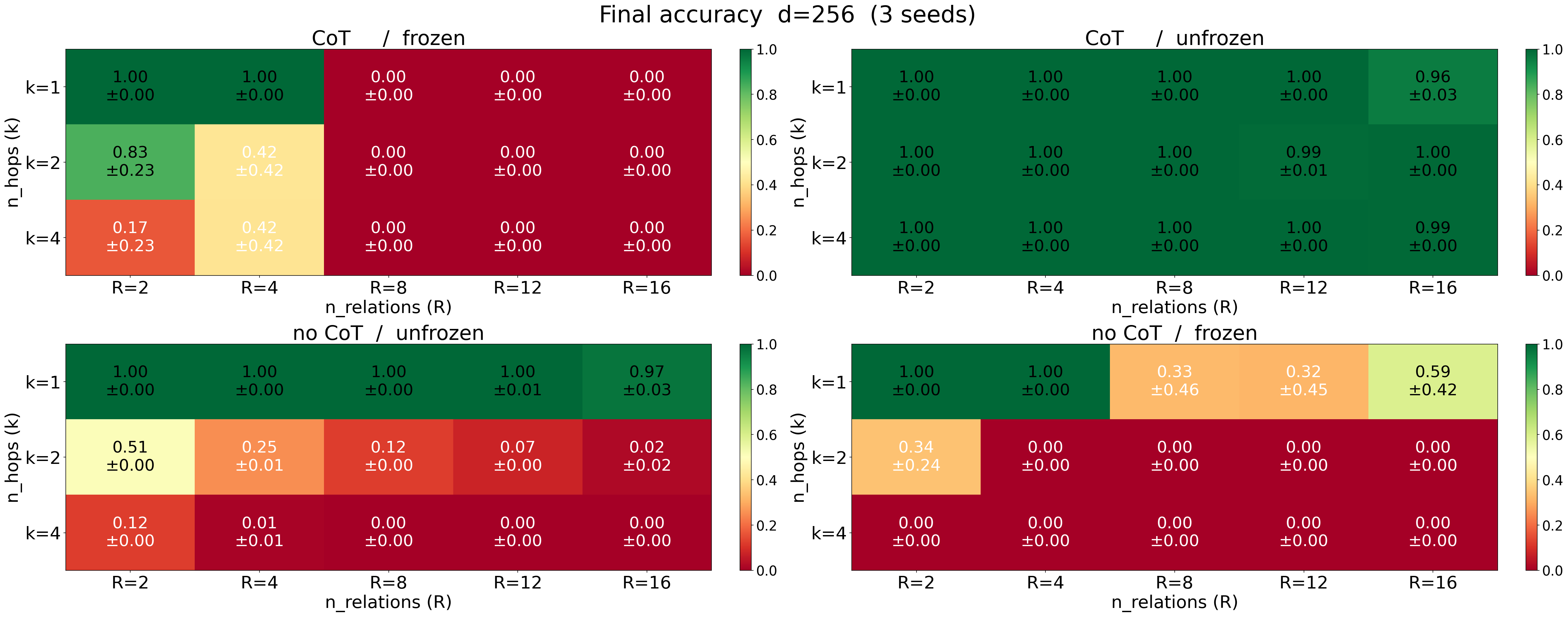
- Multi-step (compositional) questions have a trade-off—unless you use CoT:
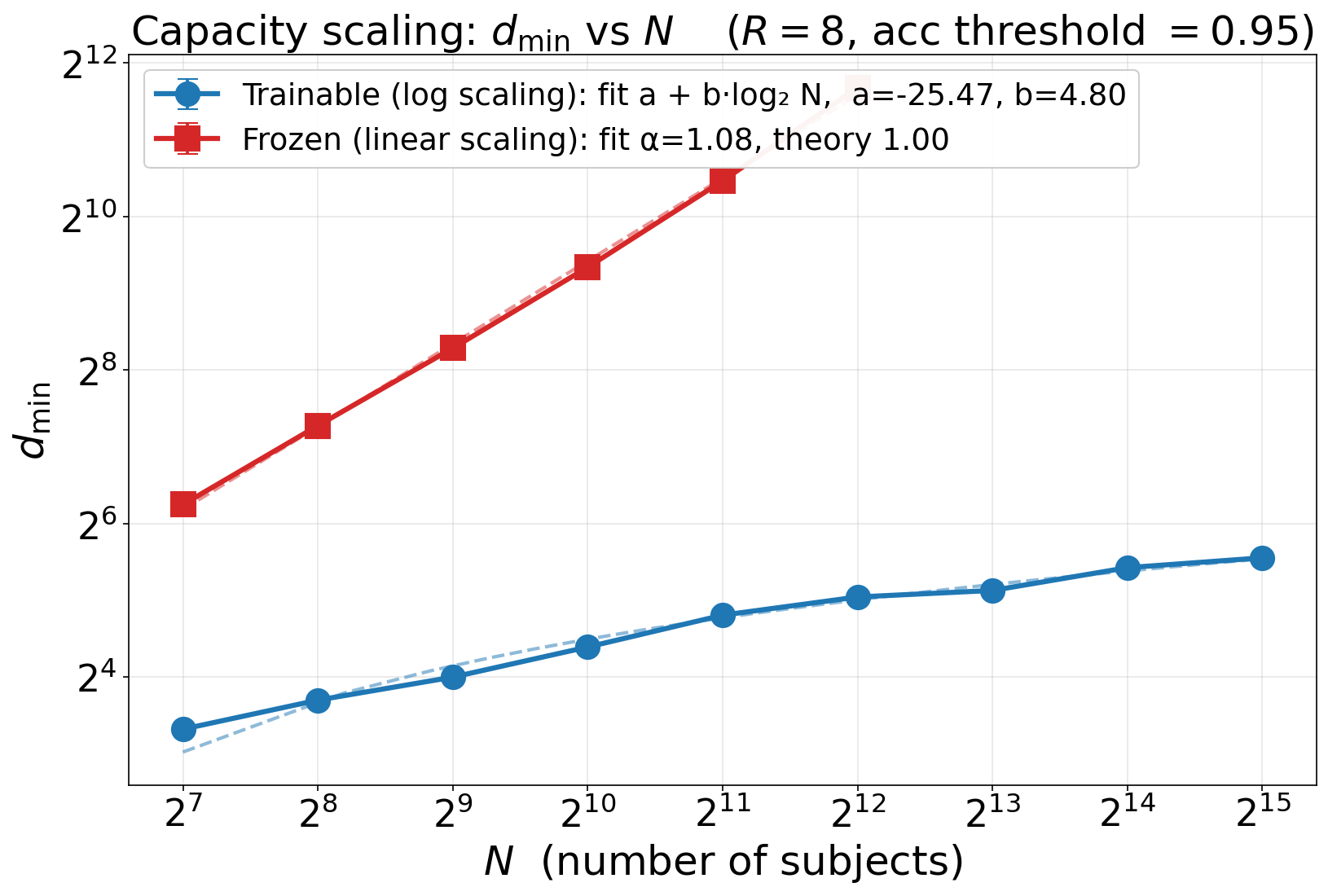
- Without CoT, you must either have a very big MLP (acts like a brute-force memory) or very large embeddings that grow quickly with the number of steps k (roughly like ).
- With CoT, you can keep things small: a one-layer transformer with small embeddings and a small MLP can handle any number of steps by writing out intermediate results.
- Why it matters: It explains why chain-of-thought can genuinely help models reason over multiple steps: it reduces memory pressure by “thinking out loud.”
- Experiments match the theory:
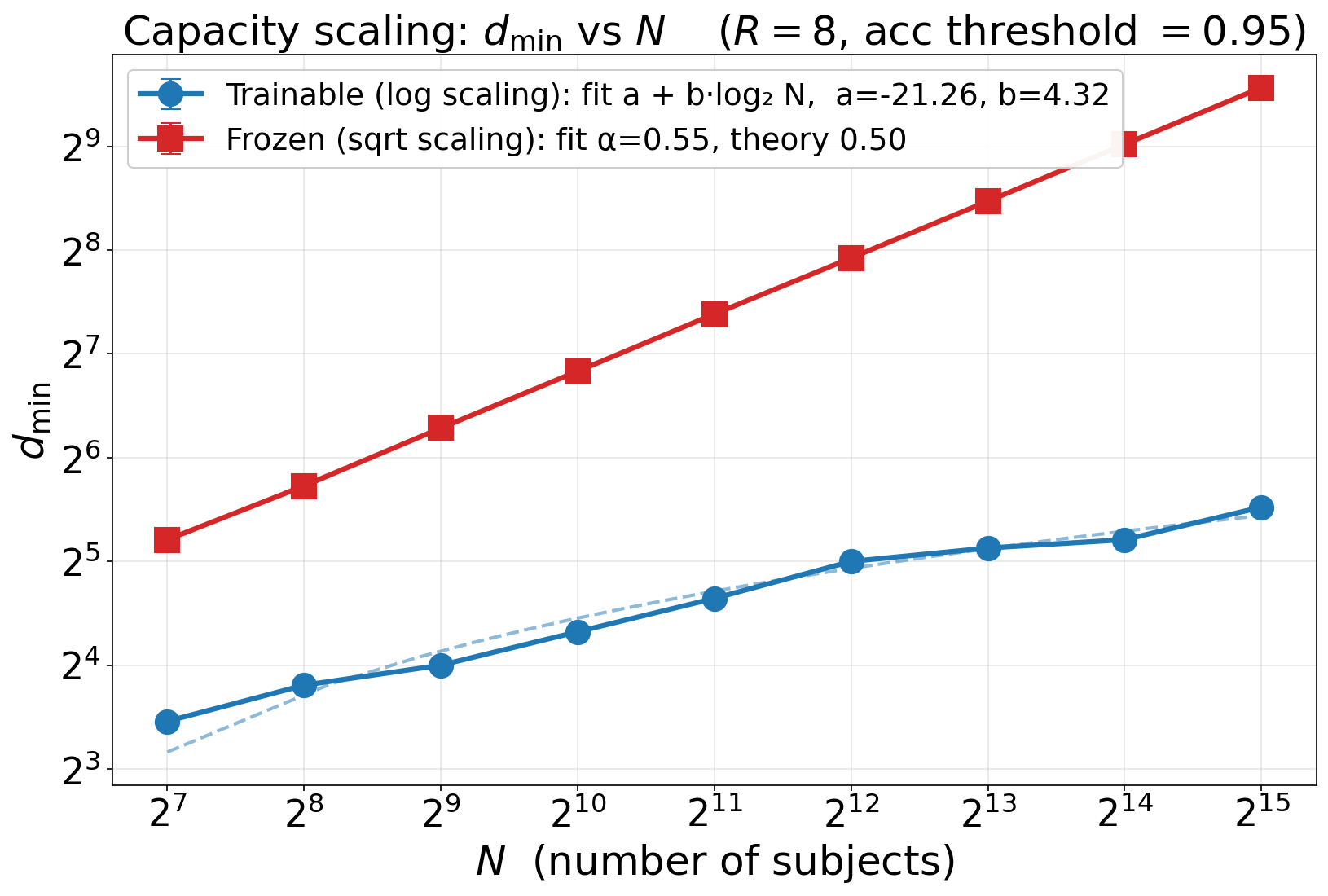
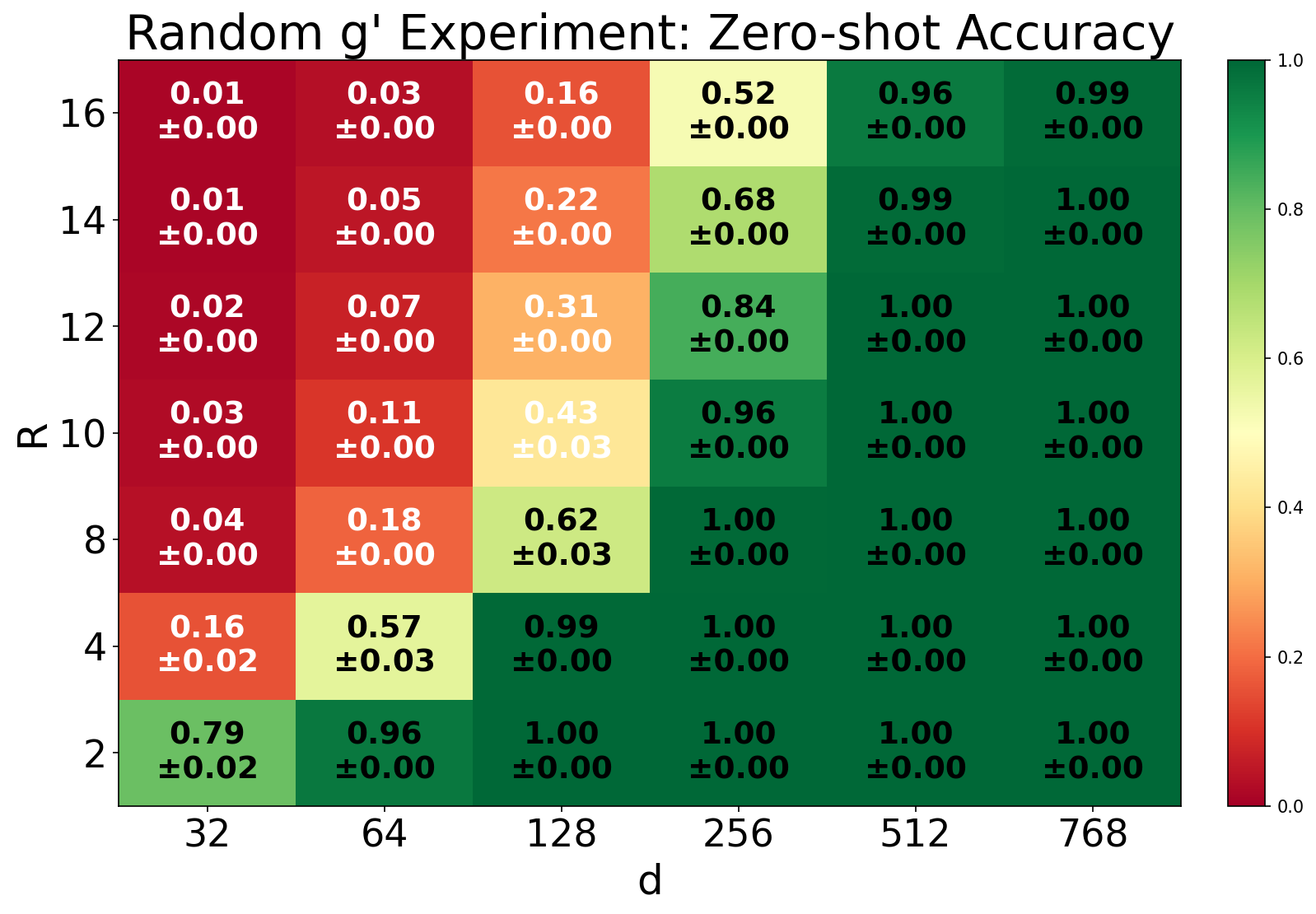
- When embeddings are learnable, the minimum embedding size needed to memorize facts grows like , just as predicted.
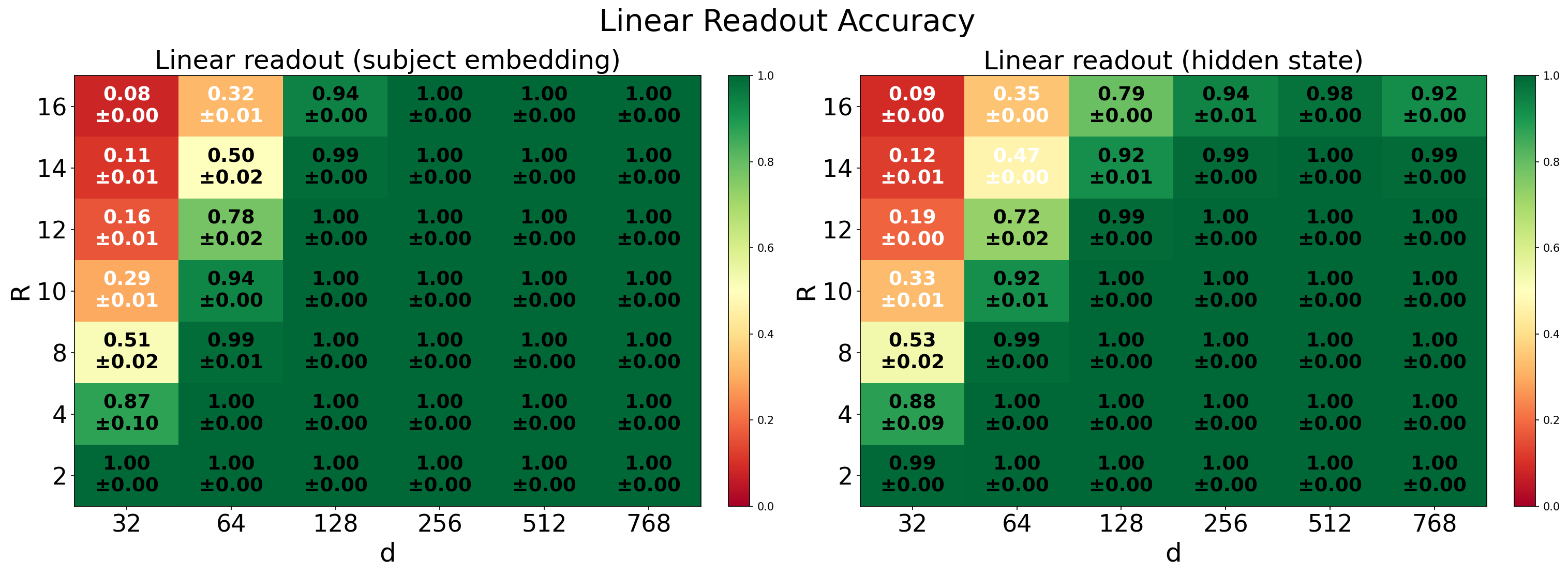
- The subject embeddings really do look like superpositions: a simple per-relation linear decoder can read out each relation’s answer from the embedding.
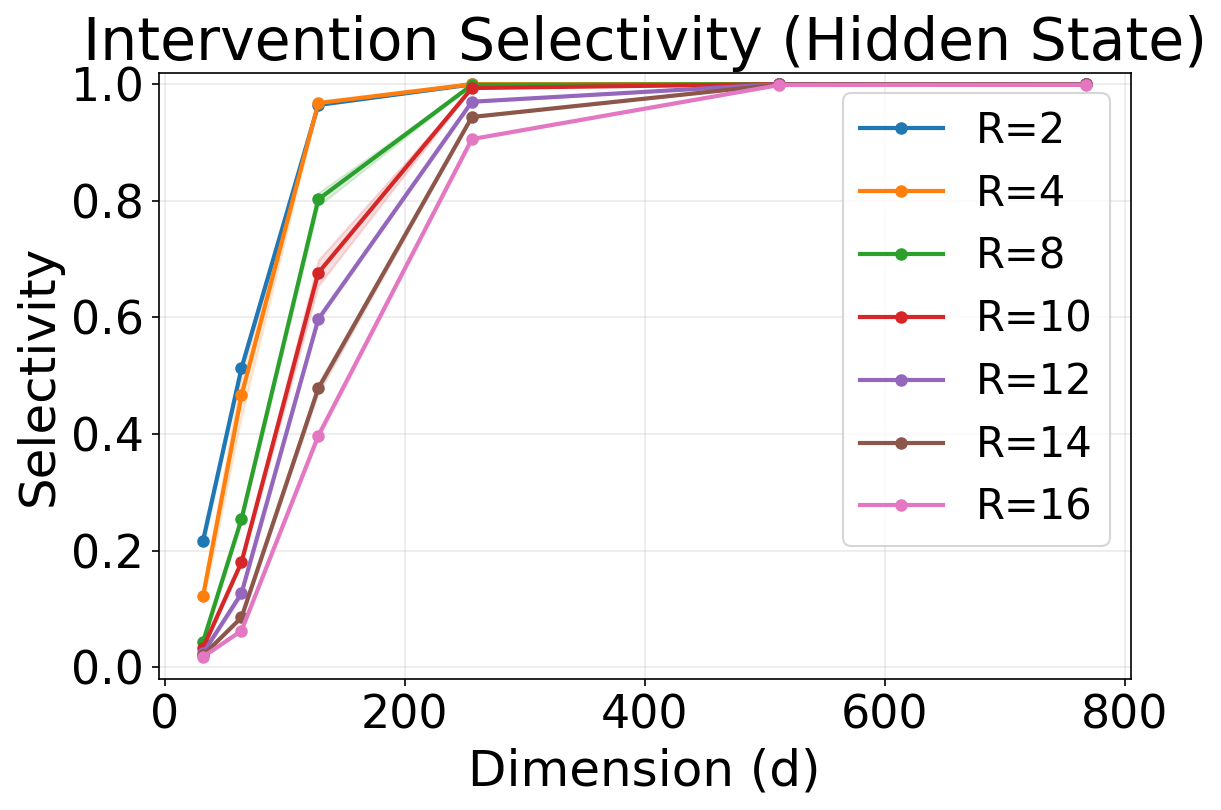
- The MLP behaves like a selector: when you tweak the embedding to say “what if their birthplace were changed,” the MLP follows that change for the asked relation and leaves other relations alone.
- The MLP transfers to new fact sets: freeze the trained MLP, swap in entirely new relations, and reinitialize the subject embeddings accordingly—the model still works. That means the MLP learned a general “selection mechanism,” not a big table of facts.
- Signs in real LLMs:
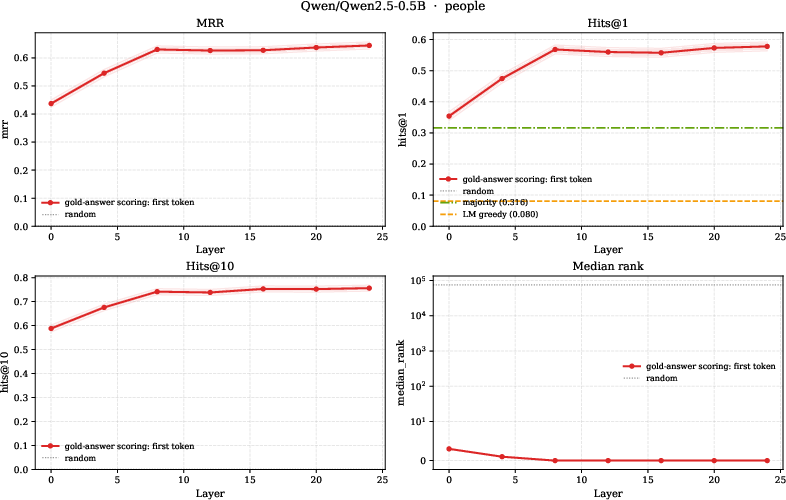
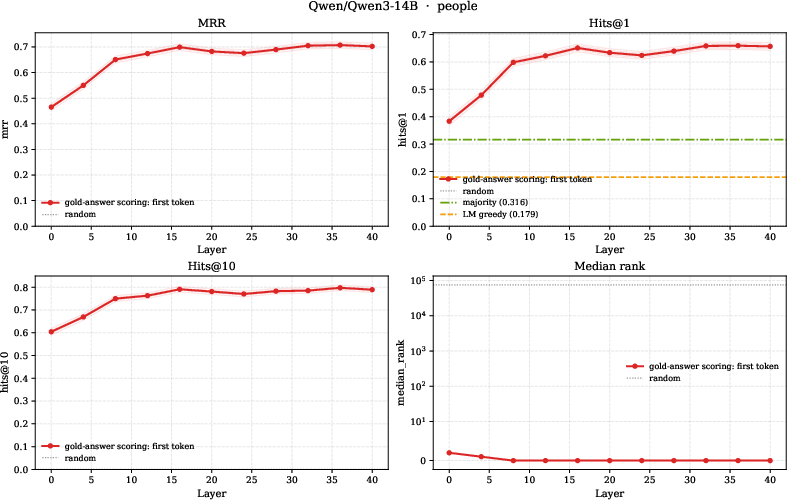
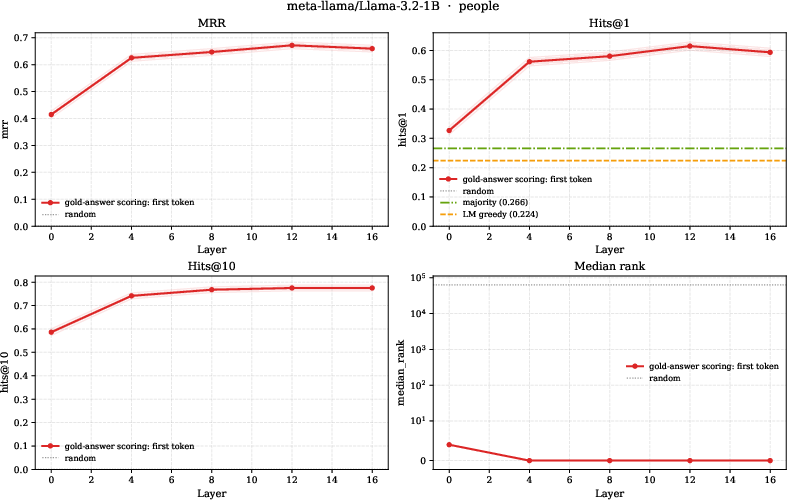
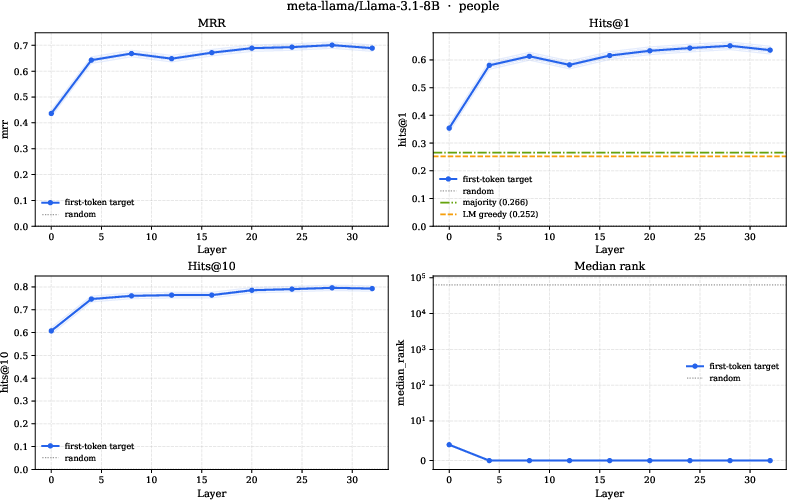
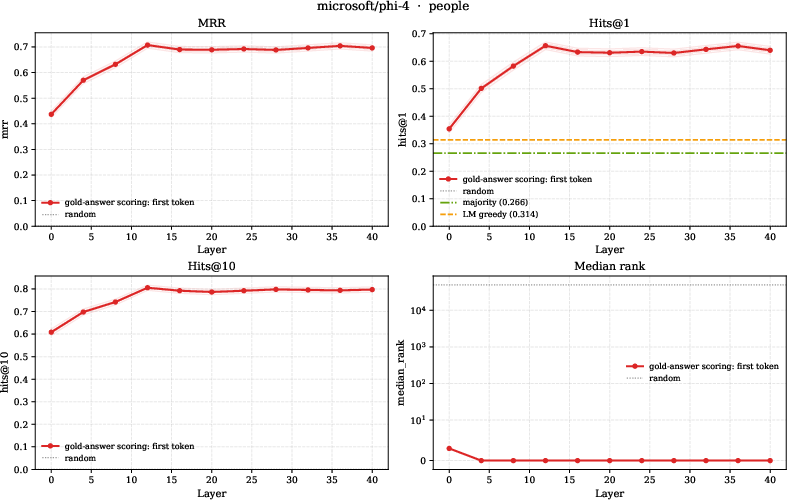
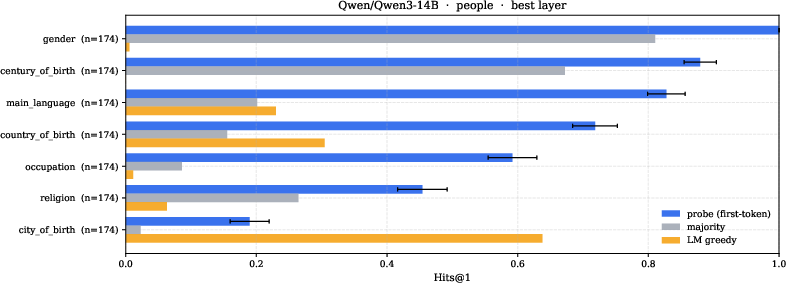
- Probing several pretrained LMs, the authors find that a relation’s answer direction is linearly decodable from a subject’s hidden state at mid-to-late layers. In simple terms, the structure their theory predicts (linearly readable relation answers) also shows up in real models.
Why is this important?
- It gives a clearer picture of how transformers can store and recall facts efficiently: by arranging embeddings to carry structured, layered information and using a small, generic selector to retrieve the part you asked for.
- It explains why chain-of-thought helps multi-step reasoning: it lets the model “reuse” the embedding table at each step, avoiding the need to cram a whole multi-step computation into a single hidden state.
- It suggests practical design ideas:
- Favor learned, structured embeddings that encode multiple relations compactly.
- Use small MLPs as selectors rather than giant memorization blocks.
- Encourage chain-of-thought when tasks involve many steps.
- It also helps interpretability and editing: if subjects store their relation answers in a predictable, linear way, it’s easier to probe, tweak, or transfer knowledge.
In short, the paper argues and demonstrates that transformers can remember facts “geometrically,” packing many relations into compact embeddings and using a simple selector to pull out the right answer—especially powerful when combined with step-by-step (chain-of-thought) reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues and open directions that future work could address.
- Tightness of single-hop capacity: establish matching lower bounds for the learned-embedding single-hop setting to confirm whether is necessary (not just sufficient), including constants and dependence on activation/nonlinearity.
- Intermediate-regime lower bound: close the gap noted for with in the multi-hop lower bound by deriving a smooth trade-off (e.g., showing scales like rather than ), or proving impossibility results for such tightening.
- Non-bijective and noisy relations: generalize constructions and lower bounds beyond bijections to partial functions, many-to-one/one-to-many mappings, multi-valued attributes, and data with label noise or ambiguity; quantify how these affect capacity and selection mechanisms.
- Correlated relations and typed attributes: develop geometric representations that exploit relational correlation, type constraints, and hierarchical ontologies (e.g., birth place vs. nationality), rather than encoding each relation independently.
- Sample complexity and data coverage: quantify how many subject–relation pairs (and which sampling schemes) are required for gradient descent to reliably discover the geometric solution; analyze performance under partial coverage and long-tailed frequency distributions.
- Optimization guarantees: provide theoretical guarantees (or conditions) under which gradient descent converges to the superposition-plus-selector solution, including effects of initialization, learning rate, regularization, and width.
- Role of activations and normalization: examine how the selection mechanism depends on activation choice (ReLU vs. GELU, etc.) and normalization layers (LayerNorm, RMSNorm); extend proofs to architectures with realistic normalization and residual scaling.
- Attention dynamics: move beyond uniform attention in theory and experiments to characterize how learned attention contributes to transporting subjects/relations and whether attention heads can implement or augment the selector; determine minimal head count and head dimension needed.
- Depth and multi-layer implementations: generalize single-layer constructions to deep transformers, mapping where (and how) superposition and selection emerge across layers; test whether geometric structure concentrates at specific depths or disperses across the network.
- Computational efficiency claims: empirically validate the suggested compute/memory benefits of embedding-based storage versus large associative MLPs (e.g., latency, FLOPs, cache behavior), and analyze trade-offs under practical constraints.
- Robustness to perturbations: assess how the geometric solution degrades under adversarial or random perturbations to embeddings or MLP weights, and whether selector gating exhibits brittleness or graceful degradation.
- Editing and continual learning: develop and evaluate methods that edit or add facts by modifying embeddings (rather than MLP weights), measuring interference across relations and scalability to large knowledge bases.
- Generalization across N and R: test larger regimes of subjects and relations (beyond N up to 215 and R up to 16) to identify potential phase transitions or failure modes; characterize constants in empirically across architectures.
- Multi-token entities and outputs: extend theory and experiments to multi-token entities and attributes (not just first-token decoding), including compositional encodings across subword tokens and their interaction with positional encodings.
- Causal validation in real LMs: complement linear probes with causal interventions in pretrained LMs (e.g., counterfactual swaps via rank-constrained edits) to test whether the model actually uses linear relational directions for decoding, not just encodes them.
- Chain-of-thought in practice: evaluate CoT constructions on real multi-hop QA benchmarks, measuring sensitivity to decoding strategies (temperature, sampling), exposure bias, and prompting; compare implicit multi-hop computation without explicit CoT versus explicit step-wise generation.
- Selector transfer scope: expand MLP-freeze transfer experiments to new relations, different N/R, and heterogeneous attribute distributions; test whether a single selector generalizes across relation sets of different cardinalities and semantics.
- Embedding tying choices: study the impact of tying vs. untying input/output embeddings (and tying across layers) on the emergence of linear relational encoding and selection behavior.
- Uniqueness and degeneracy of solutions: analyze whether the geometric solution is unique up to symmetries or whether multiple qualitatively different minima exist; characterize the basin of attraction and identifiability of relation-specific subspaces.
- Interaction with regularization: examine how weight decay, dropout, or orthogonality constraints affect superposition quality, selector sharpness, and capacity thresholds; identify regimes that encourage cleaner relational subspaces.
- Head and width efficiency: determine the minimal number of attention heads and MLP width required for reliable selection, and whether sparse or low-rank parameterizations suffice without sacrificing accuracy.
- Formal link to mechanistic circuits: relate the ReLU-gating selector to known transformer-circuit motifs (e.g., feature splits, sign-gating, monosemantic features), and test dictionary-learning approaches to recover monosemantic relational features.
- Domain transfer and semantics: evaluate geometric recall on semantically rich, non-synthetic corpora with real entity graphs, measuring whether embeddings reflect topology (community structure, centrality) and whether selectors align with typed relations.
- Training-time scaling laws: derive and validate scaling laws for time-to-memorization and gradient flow in the geometric regime versus associative-memory regimes, controlling for dataset size and architecture parameters.
- Limits of CoT bypass: identify tasks and graph structures where CoT does not collapse capacity requirements (e.g., stochastic transitions, latent variables), and formalize conditions under which output-unembedding “memory fetch” is insufficient.
- Safety and interference: explore whether embedding-based fact storage increases risk of unintended leakage or cross-fact interference during generation and editing, and propose safeguards or auditing methods.
Practical Applications
Overview
Based on “Geometric Factual Recall in Transformers,” the paper’s core innovations are: (1) a geometric mechanism for factual memory where learned subject embeddings linearly superpose per‑relation attribute vectors and a small MLP acts as a relation‑conditioned selector via ReLU gating; (2) an embedding capacity result showing suffices in a shared‑attribute regime; (3) a capacity–depth tradeoff for multi‑hop queries and a formal result that chain‑of‑thought (CoT) breaks the bottleneck, enabling small ; and (4) empirical signatures and diagnostics (linear readouts, causal interventions, freeze‑and‑swap transfer) that confirm the mechanism and suggest reusability of the selector.
Below are practical applications derived from these findings, organized by deployment timeline.
Immediate Applications
The following use cases can be prototyped with today’s models and tooling, often by constraining scope (closed schemas, entity IDs) or using adapters/LoRA.
- Geometric CoT prompting for multi‑hop factual tasks
- Sectors: customer support, healthcare triage, legal/finance research, education
- What: Prefer chain‑of‑thought prompting for multi‑hop lookups to reduce required model capacity and increase reliability on compositions (e.g., “subsidiary of the parent of X”).
- Tools/workflows: Prompt templates that elicit step‑by‑step relational traversal; evaluation that measures intermediate step correctness; toggles to use CoT selectively for multi‑hop queries.
- Dependencies/assumptions: Willingness to show or use latent CoT; latency budget for multi‑step decoding; tasks exhibit multi‑relation compositions; privacy constraints on intermediate outputs.
- Embedding‑level knowledge adapters for enterprise KBs
- Sectors: enterprise software, CRM, helpdesk, internal search
- What: Freeze a small, generic “selector” MLP and train only entity/subject embeddings so the model encodes per‑relation answers via superposition; quick onboarding of new org‑specific facts.
- Tools/workflows: Lightweight fine‑tuning that maps a company KG (relations are known) to subject embeddings; per‑tenant embedding tables; A/B tests against weight‑editing baselines.
- Dependencies/assumptions: Entities can be mapped to stable IDs/tokens; relations are relatively clean and few (); supervision for each (subject, relation) exists.
- Faster knowledge updates via embedding edits instead of weight edits
- Sectors: news/chatbots, compliance updates, e‑commerce catalogs
- What: Update or swap subject embeddings to revise facts without editing the core model weights (contrast to MEMIT‑style surgery).
- Tools/workflows: “Freeze‑and‑swap” pipelines that regenerate embeddings when facts change; rollback/versioning at the embedding‑table level.
- Dependencies/assumptions: Subject tokens/IDs exist and can be associated with embeddings; relation schema is stable; guardrails for consistency across cached copies.
- Auditing and interpretability with linear relational probes
- Sectors: model governance, safety, regulated industries
- What: Use low‑rank linear probes from subject hidden states to LM‑head rows to check which relations/attributes are linearly decodable (signals of memorized or sensitive facts).
- Tools/workflows: Probe training/validation per relation; layer‑wise scans to locate best‑decoding layers; dashboards for probe Hits@1/MRR and drift over time.
- Dependencies/assumptions: Sufficient labeled (subject, relation, attribute) examples; tolerance for probe noise; interpretability teams.
- Causal intervention tests for safe knowledge editing
- Sectors: safety, QA, MLE tooling
- What: Apply minimal‑norm counterfactual perturbations aligned to per‑relation readouts to test whether edits change only the targeted relation (high selectivity).
- Tools/workflows: Automated “edit‑then‑verify” tests in CI; per‑relation selectivity metrics; regression tests across model versions.
- Dependencies/assumptions: Stable readout directions; access to internal activations; tolerance for small activation perturbations in production tests.
- Compact, closed‑world assistants with logarithmic memory scaling
- Sectors: SMEs, on‑device assistants, embedded/IoT
- What: Build small, domain‑specific assistants (FAQs, catalogs) where suffices; the MLP acts as a reusable selector across clients/tasks.
- Tools/workflows: Data schema with bijective or near‑bijective relations (e.g., SKU→price, SKU→category); small one‑layer transformers or adapters.
- Dependencies/assumptions: Closed schemas; bounded relations; limited scope and vocabulary; tolerance for synthetic pre‑processing.
- RAG pipelines with relation‑aware entity embeddings
- Sectors: enterprise search, developer docs, customer support
- What: Re‑encode entities (e.g., APIs, products) so multiple attributes are recoverable via relation‑specific linear maps; the LLM then “selects” the right field via a small MLP.
- Tools/workflows: Precompute per‑relation readouts; retrieval retrieves entity IDs; generation conditions on relation cues to select fields.
- Dependencies/assumptions: Clear relation signaling in prompts; retriever returns canonical entity IDs; controlled vocabularies.
- Benchmarking and diagnostics for multi‑hop factual recall
- Sectors: academia, model evaluation, procurement
- What: Include shared‑attribute multi‑relation benchmarks; report performance with/without CoT, and capacity vs. .
- Tools/workflows: Synthetic generators mirroring the paper’s tasks; per‑relation accuracy and selectivity; capacity threshold measurements.
- Dependencies/assumptions: Agreement on standardized schemas; public release of generators and metrics.
- Rapid multi‑tenant model instancing
- Sectors: SaaS platforms, contact centers
- What: Deploy one shared “selector‑MLP” service and client‑specific embedding tables; swap embeddings to switch tenants quickly without retraining the core selector.
- Tools/workflows: Tenant isolation at embedding‑table level; secure hot‑swaps; monitoring of leakage/cross‑tenant interference.
- Dependencies/assumptions: Strong isolation guarantees; consistent relation schemas across tenants.
Long‑Term Applications
These require further research, architectural changes, or broader ecosystem support (e.g., data pipelines, standards).
- Architectures with per‑layer embedding stores as knowledge caches
- Sectors: foundation models, hardware acceleration
- What: Design transformers where learned embedding caches at intermediate layers hold superposed relational facts; small MLP gates perform selection.
- Tools/products: New layer types, cache management, quantization for embedding stores; compiler/runtime support.
- Dependencies/assumptions: Stable training that encourages superposition; efficient memory hierarchies; compatibility with multi‑token entities.
- Model compression via geometric memorization objectives
- Sectors: edge AI, sustainability
- What: Pretraining/fine‑tuning objectives that encourage linear superposition of relation answers, reducing parameters needed for factual stores.
- Tools/products: Regularizers for superposition; curriculum that learns relation‑conditioned selectors; distillation that preserves decodability.
- Dependencies/assumptions: Retains task performance; handles noise, polysemy, and non‑bijective relations.
- General‑purpose “selector‑MLP” modules as reusable services
- Sectors: cloud AI platforms, MLOps
- What: Ship a hardened, audited selector MLP; customers upload embedding tables to encode their facts; the selector generalizes across domains.
- Tools/products: APIs for embedding ingestion; validation/probe suites; service‑level objectives for selectivity and drift.
- Dependencies/assumptions: Cross‑domain transfer holds; standardized relation schemas or mappings.
- KG‑to‑LM compilers for superposed entity representations
- Sectors: healthcare, finance, logistics
- What: Compile knowledge graphs into entity embeddings that pack multi‑relation attributes; LMs use CoT to traverse multi‑hop chains.
- Tools/products: Graph compilers; schema alignment; consistency checkers; incremental updates for streaming KGs.
- Dependencies/assumptions: Noisy/missing edges handled; identifiers aligned across systems; governance for sensitive attributes.
- Continual and federated learning via embedding updates
- Sectors: mobile, IoT, privacy‑sensitive domains
- What: Add or update facts by modifying user/device‑local embeddings; central selector remains unchanged, reducing catastrophic forgetting.
- Tools/products: Federated optimization for embedding tables; privacy accounting; on‑device fine‑tuning libraries.
- Dependencies/assumptions: Reliable per‑user IDs; robust to data heterogeneity; privacy and compliance frameworks.
- On‑device multi‑step reasoning with CoT for low‑power platforms
- Sectors: robotics, AR/VR, automotive
- What: Use CoT to trade compute for memory, enabling multi‑hop reasoning with small and narrow MLPs on constrained hardware.
- Tools/products: Runtime schedulers for stepwise decoding; caching intermediate tokens; energy‑aware CoT policies.
- Dependencies/assumptions: Real‑time constraints can accommodate multi‑step decoding; safety around intermediate states.
- Safety and policy: standards for factual recall audits
- Sectors: regulators, governance
- What: Require reporting linear decodability of sensitive relations, selectivity of edits, and CoT dependence for multi‑hop answers.
- Tools/products: Certification checklists; public metrics/benchmarks; audit logs of editing events and probe results.
- Dependencies/assumptions: Industry alignment on tests and thresholds; access to internal activations for audits.
- Training pipelines for robust multi‑token entity handling
- Sectors: foundation model pretraining, NER/NEL systems
- What: Ensure multi‑token entity spans converge to linearly decodable subject states in mid‑late layers, enabling geometric recall.
- Tools/products: Span pooling objectives; auxiliary losses for relation decodability; dataset curation for entity coverage.
- Dependencies/assumptions: High‑quality entity annotations; stability across tokenizers and languages.
- Hardware/software co‑design for embedding‑centric memory
- Sectors: accelerators, systems
- What: Optimize memory bandwidth and compute for large embedding reads plus small MLP gating; cache hierarchies tuned for selector access patterns.
- Tools/products: New kernels; memory‑aware schedulers; sparse/low‑rank MLP primitives.
- Dependencies/assumptions: Stable usage patterns; sufficient market pull to justify silicon changes.
- Cross‑lingual and multi‑modal relational selectors
- Sectors: global enterprises, multimodal assistants
- What: Extend geometric memorization to cross‑lingual entities and vision/audio attributes; selector MLP generalizes across modalities.
- Tools/products: Shared entity ID spaces across languages/modalities; alignment losses.
- Dependencies/assumptions: Reliable cross‑modal alignment; unified schemas for relations.
Key Assumptions and Dependencies (cross‑cutting)
- The strongest theoretical results are proved in controlled settings: single‑layer transformers, synthetic bijections, shared attribute pools, and . Real data includes noise, non‑bijective/typed relations, multi‑token entities, and long‑tailed frequencies.
- CoT benefits depend on allowing intermediate steps (visible or latent) and incurring extra decoding time; some applications disallow visible CoT for privacy or UX reasons.
- Success of embedding‑only updates presumes stable subject identifiers and good coverage of (subject, relation) examples.
- Linear decodability signatures vary by layer; production systems may need layer‑wise probes and training adjustments to induce the geometry.
- Transferability of a “generic selector” depends on schema similarity across domains and on preserving superposition structure during fine‑tuning.
These applications translate the paper’s geometric memorization mechanism and capacity results into concrete product patterns, evaluation practices, and system designs that can reduce parameter counts, accelerate updates, and improve multi‑hop reliability—especially when combined with judicious use of chain‑of‑thought.
Glossary
- Affine probe: A learned linear-plus-bias mapping used to decode a target from hidden states, sometimes constrained to low rank. "we fit a low-rank affine probe from the layer- subject hidden state to the LM-head row of the gold answer's first token"
- Autoregressive LLM: A model that predicts the next token conditioned only on previously seen tokens in the sequence. "we train an autoregressive LLM over the vocabulary "
- Bijection: A one-to-one and onto mapping between two sets. "a random bijection "
- BPE (Byte Pair Encoding): A subword tokenization scheme that represents words as sequences of frequent symbol pairs. "entities span multiple BPE tokens"
- Capacity–depth tradeoff: A relationship showing that achieving a task may require more parameters (capacity) if depth is limited, or more depth if capacity is limited. "a provable capacity--depth tradeoff"
- Causal interventions: Experimental manipulations that alter internal representations to test causal effects on model outputs. "as confirmed by causal intervention experiments"
- Causal language modeling objective: The training loss for next-token prediction using only past context. "trained with the standard causal language modeling objective"
- Chain-of-Thought (CoT): Generating intermediate reasoning steps to solve multi-step tasks more efficiently. "we naturally introduce Chain-of-Thought (CoT) generation into our setting."
- Directed edge-colored graph: A graph whose edges are directed and assigned colors (labels), often used to encode different relation types. "the space of -regular directed edge-colored graphs on vertices"
- Disjoint-attribute setting: A setup where each relation maps into a distinct, non-overlapping attribute set. "a learned-embedding construction for the disjoint-attribute setting"
- Edge-colored graph: A graph where each edge is assigned a color representing a type or category. "A counting argument over -regular edge-colored graphs"
- Embedding dimension: The number of components in the vector representation of tokens. "embedding dimension "
- GELU: The Gaussian Error Linear Unit activation function used in neural networks. "a two-layer GELU MLP with Pre-RMSNorm"
- Hits@1: An accuracy metric indicating whether the top-ranked prediction is correct. "Hits@1 ranks against every row of ."
- Information-theoretic bottleneck: A fundamental limit on what can be encoded or processed given representational capacity. "exposes a fundamental information-theoretic bottleneck"
- Information-theoretic lower bound: A provable minimum amount of information (or parameters/bits) required to perform a task. "a matching information-theoretic lower bound"
- Key-Value Memory: An interpretation or module in which feed-forward layers store associations as key–value pairs. "Key-Value Memory: Embedding dimension and MLP width ."
- LM-head: The final linear projection from hidden states to vocabulary logits in a LLM. "to the LM-head row of the gold answer's first token"
- Mean Reciprocal Rank (MRR): A ranking metric averaging the reciprocal of the rank of the correct answer. "best-layer MRR (averaged over models) reaching $0.69$ on people"
- Multi-hop: Involving compositions of multiple relational steps to reach an answer. "multi-hop relational queries"
- Outer product: A matrix formed by multiplying a column vector with a row vector, used to store pairwise associations. "transformer weights are outer products over near-orthogonal embedding pairs"
- Pigeonhole Principle: A combinatorial principle used to argue about unavoidable collisions when mapping many items into fewer containers. "we apply the Pigeonhole Principle"
- Pre-RMSNorm: Applying Root Mean Square Layer Normalization before a sublayer in a transformer. "a two-layer GELU MLP with Pre-RMSNorm"
- Pseudoinverse: The Moore–Penrose inverse of a matrix, used for least-squares or minimum-norm solutions. "the full pseudoinverse introduces noise"
- ReLU gating: Using ReLU activations to selectively pass components of a representation, effectively acting as a gate. "via ReLU gating"
- Residual connection: A skip connection that adds the input of a layer to its output to aid optimization and signal flow. "This is followed by a residual connection"
- Ridge regression: Linear regression with L2 regularization, used for stable linear decoding. "we fit a linear map via ridge regression"
- R-ary tree: A rooted tree where each node has exactly R children. "a complete -ary tree of depth "
- R-regular graph: A graph where every vertex has exactly R incident edges. "A counting argument over -regular edge-colored graphs"
- Self-attention: A mechanism where each token attends to all tokens in the sequence to compute contextualized representations. "a multi-head self-attention mechanism"
- Softmax: A function that converts a vector of scores into a probability distribution. "A{(h, \ell)} = \text{softmax}\left( (W_K{(h, \ell)} X{(\ell-1)})\top (W_Q{(h, \ell)} X{(\ell-1)}) \right)"
- Superposition (linear): Combining multiple signals or features additively within the same representation. "linear superpositions of their associated attribute vectors"
- Uniform attention: An attention pattern that does not learn token-specific weights and treats inputs uniformly. "We use uniform attention in the single-hop experiments"
- Unembedding: The final projection from hidden states back to vocabulary space via the output embedding matrix. "the output unembedding operation"
- Zero-shot: Performing well on new tasks or mappings without additional training. "the MLP transfers zero-shot to entirely new bijections"
Collections
Sign up for free to add this paper to one or more collections.

