Emergence of Linear Truth Encodings in Language Models
Abstract: Recent probing studies reveal that LLMs exhibit linear subspaces that separate true from false statements, yet the mechanism behind their emergence is unclear. We introduce a transparent, one-layer transformer toy model that reproduces such truth subspaces end-to-end and exposes one concrete route by which they can arise. We study one simple setting in which truth encoding can emerge: a data distribution where factual statements co-occur with other factual statements (and vice-versa), encouraging the model to learn this distinction in order to lower the LM loss on future tokens. We corroborate this pattern with experiments in pretrained LLMs. Finally, in the toy setting we observe a two-phase learning dynamic: networks first memorize individual factual associations in a few steps, then -- over a longer horizon -- learn to linearly separate true from false, which in turn lowers language-modeling loss. Together, these results provide both a mechanistic demonstration and an empirical motivation for how and why linear truth representations can emerge in LLMs.
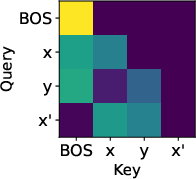
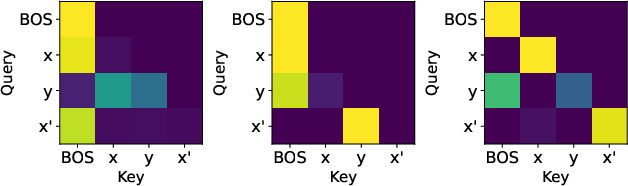
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Emergence of Linear Truth Encodings in LLMs — A simple explainer
What is this paper about?
This paper asks a big question: Inside a LLM (like the ones that write sentences), is there a simple “switch” or direction that tells the model whether a statement is likely true or false? The authors show that such a “truth direction” can appear on its own during training, explain one clear reason why it happens, and demonstrate a simple way it could work.
What questions are the authors trying to answer?
- Why do LLMs form an internal signal that separates true from false statements with a simple straight-line boundary?
- How does the model actually compute this signal when it reads text?
- Under what kinds of training data does this signal show up, and how does it help the model predict the next word better?
How did they study it? (Methods, with plain-language analogies)
The authors combine a data study, a tiny model, and real-model tests:
- A real-world clue (Truth Co-occurrence Hypothesis, TCH): The authors checked a news dataset and found that false statements tend to “cluster” together in the same article more than chance would predict. In everyday terms: if one claim in an article is false, the next claim is more likely to be false too. This gives the model a reason to keep track of a hidden “truthfulness bit,” because it helps it guess what comes next.
- A toy world with a tiny transformer: They built a very simple, one-layer transformer (a super-simplified LLM) and trained it on short, fake sentences like:
- subject → attribute, then another subject → attribute (for example: “France → Paris; Churchill → British”).
- Sometimes the attributes are correct; sometimes they’re replaced with random ones. A knob (called ρ, “rho”) controls how often both attributes are true together. This lets the model notice that “truth goes with truth” and “false goes with false.”
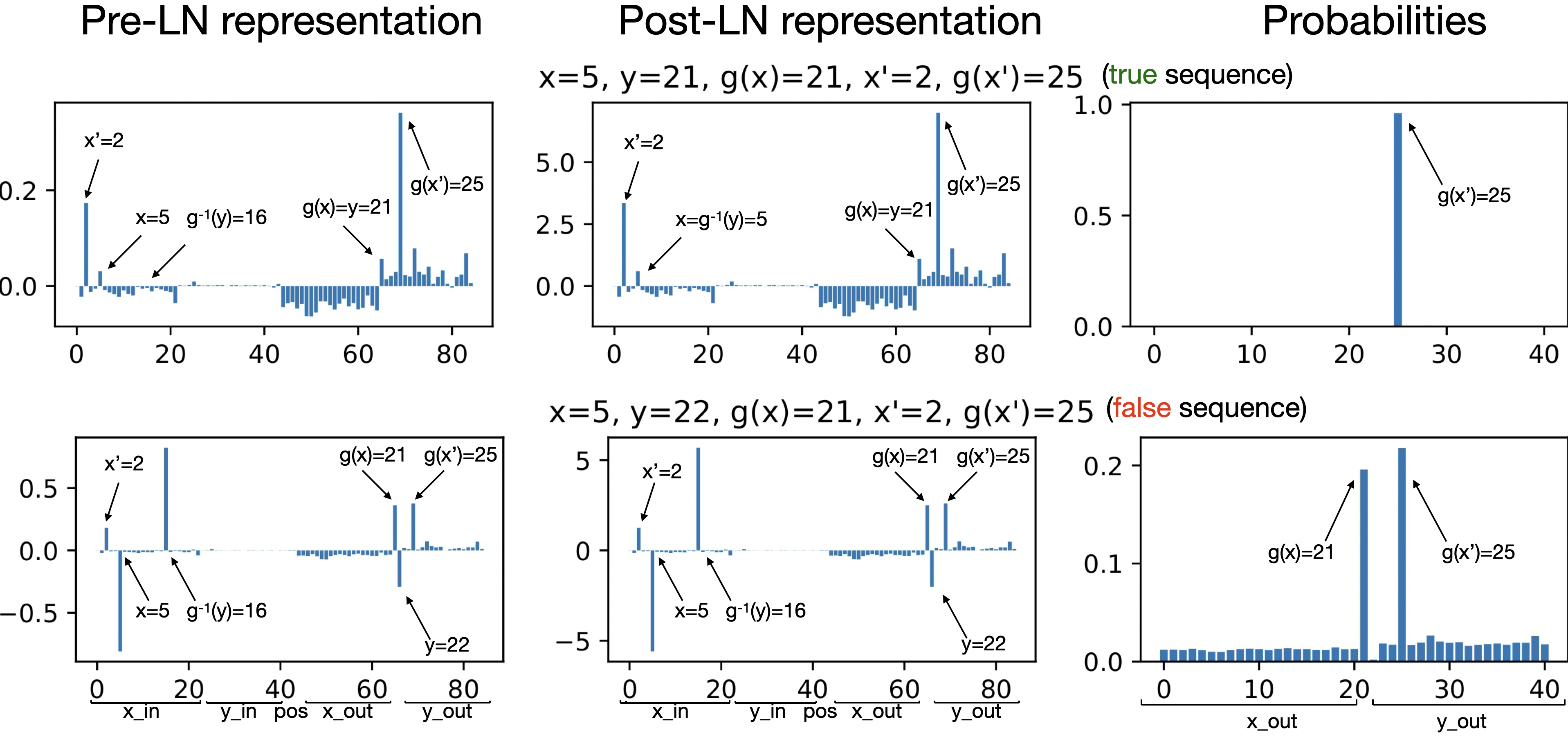
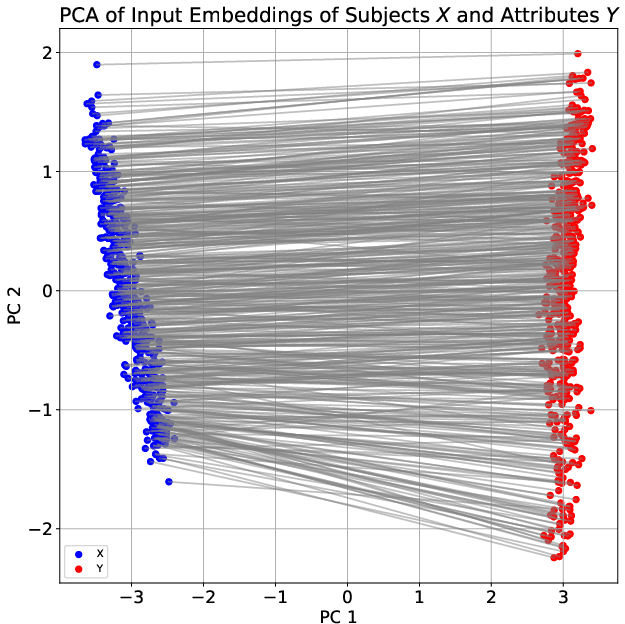
- How the model stores and uses facts (everyday analogy): The model first learns a “fact phonebook” inside itself—when it sees “France → ?” it can look up “Paris.” That’s called associative memory (think: keys and values). Then, it starts comparing what it predicted (Paris) with what it actually saw next. If they match, the context “feels true.” If they don’t, it “feels false.” This comparison creates a consistent internal pattern that can be separated with a straight line—this is the “truth direction.”
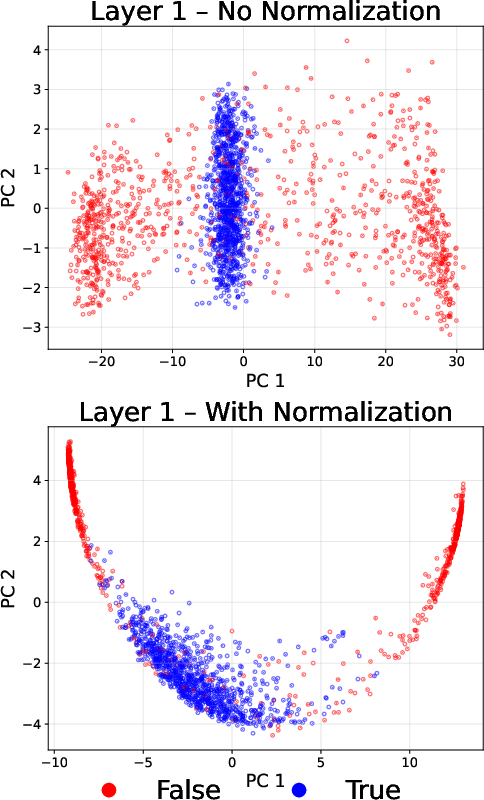
- The role of normalization (rescaling): A layer called “layer norm” rescales the model’s internal notes so their overall size is similar. That makes the “true vs false” difference pop out more cleanly. In practice, this makes the model more confident when the context is true and less confident when it’s false.
- Tests on real models: They repeat the idea using real text (from a dataset of factual claims) and test a real large model (Llama 3–8B). They also try “steering” the model by nudging it along the discovered truth direction to see if it boosts correct answers.
What did they find, and why is it important?
The key results come in a clear story:
- False statements really do cluster: In a news dataset, false claims appeared together more often than random chance (about 2× the chance you’d expect). This supports the idea that tracking a hidden “truthfulness bit” helps prediction.
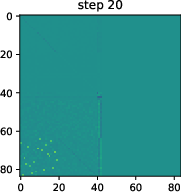
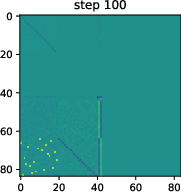
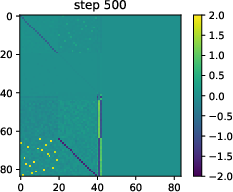
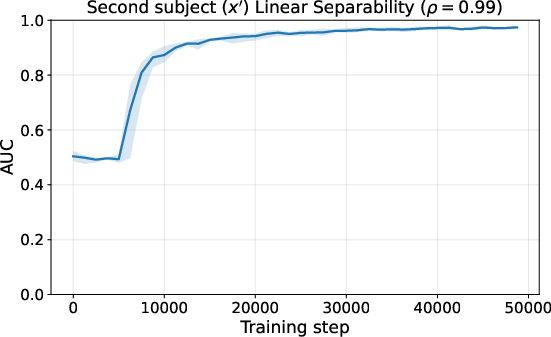
- Two-phase learning appears: 1) Fast memorization: The tiny model quickly learns the fact phonebook (e.g., France → Paris). 2) Slower truth coding: After that, it develops a simple “true vs false” line inside its internal space. This line works across many kinds of facts—like a general-purpose truth meter.
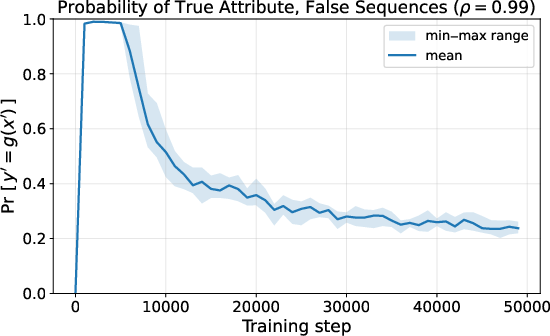
- How the truth signal works: When the model’s prediction matches the attribute it sees, the internal signal looks one way; when it doesn’t, it looks another way. Layer normalization sharpens this difference, which makes the model more confident on truthful contexts and more cautious on false ones.
- The same pattern shows up beyond the toy setup:
- Training small real transformers on factual sentences shows the same two phases: memorize facts first, then develop a truth direction, then use it to lower confidence when the context seems false.
- In a large pretrained model (Llama 3–8B), adding false sentences before a question makes the model less likely to answer correctly—exactly what the “truth clusters” idea predicts.
- Nudging the model along the learned truth direction (“steering”) can raise the probability of the correct answer even after a misleading (false) context.
Why this matters: If we can find and control the “truth direction,” we might reduce hallucinations or help models resist false context. It also gives a concrete explanation for a mysterious behavior people had observed but not fully understood.
What could this change or lead to? (Implications)
- Better tools to reduce hallucinations: If a model has a built-in signal for truthfulness, we can try detecting it or steering it to prefer true continuations, especially after misleading text.
- Clearer interpretability: The paper offers a specific “mechanism” for truth detection—learn facts first, then compare prediction vs observation—rather than just noticing correlations after the fact.
- Smarter training ideas: If training data often places truths with truths (and falsehoods with falsehoods), models will naturally learn to carry a “truthfulness bit” forward in a conversation. Designers could use this to build safer and more reliable systems.
- Limits and next steps: The toy setup has only one kind of relation at a time and ignores many real-world complexities (like logic, multiple relations per subject, and tricky language). Future work can test whether similar mechanisms hold in richer, more realistic training settings.
In short: The paper shows a clear path for how a simple “truth signal” can appear in LLMs and be used to make better next-word predictions. It explains both why this happens (truth tends to cluster) and how the model builds it (compare predicted vs seen attributes, then amplify the difference), and it finds signs of the same behavior in real, large models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and questions the paper leaves unresolved that future work could address.
- Validate the Truth Co-occurrence Hypothesis (TCH) beyond MAVEN-FACT: quantify truth–false co-clustering across diverse domains (Wikipedia, social media, forums), languages, and granularities (sentence, paragraph, document), controlling for topic and source-level confounds.
- Map the quantitative link between observed clustering statistics and the latent correlation parameter used in training: establish how document-level heterogeneity (e.g., 23% extra variance) translates into the co-truth correlation needed for truth-code emergence.
- Test sensitivity to realistic falsehood distributions: replace uniform corruption with structured, plausible counterfactuals (e.g., confusable attributes within type constraints) and measure effects on emergence, linear separability, and behavioral relevance.
- Extend beyond a single relation: train on mixtures of relations (e.g., capitalOf, bornIn, speaksLanguage) and measure whether a single, unified truth subspace emerges and transfers across relations, prompts, and contexts.
- Characterize the minimal correlation threshold for emergence: systematically vary co-truth correlation (not just the true rate ρ) to identify the phase transition at which linear truth encoding appears and how its margin scales.
- Generalize the toy model mechanism to realistic architectures: analyze how multi-head attention, learned key–query–value matrices, MLPs, positional encodings, and deeper stacks affect the emergence, location, and stability of the truth subspace.
- Clarify the role of normalization: compare RMSNorm vs LayerNorm (with learned γ/β), pre-norm vs post-norm, and alternative normalizations; quantify when and why norm differences drive the sharpening and linear separability effects.
- Provide a complete mechanistic account with learned embeddings: move beyond orthogonal one-hot inputs to analyze how cancellation (e.g., empirical e_x ≈ −e_{g(x)} on a principal axis) arises, persists, and interacts with superposition/polysemanticity.
- Formalize and generalize training dynamics: replace the informal sequential-gradient analysis with rigorous proofs under realistic optimizers, step sizes, batch noise, and non-convexities induced by normalization.
- Identify necessary and sufficient architectural/training conditions: systematically chart failure modes (e.g., attention collapsing onto current token when ρ=1) and success regimes as a function of attention temperature, head count, residual weighting, and training curriculum.
- Quantify the rank and geometry of the truth subspace: measure dimensionality, margins, and stability across layers; determine whether the “truth code” is a single direction or a low-rank manifold and how it composes with other concepts.
- Establish stronger causal evidence: go beyond mean-shift steering to targeted interventions (e.g., patching, causal scrubbing, ablations) that demonstrate the truth direction’s necessity and sufficiency for modulating predictions across tasks and contexts.
- Evaluate robustness to negation, logical operators, and compositional claims: test whether the truth subspace flips or shifts under negation, handles multi-hop inferences (transitivity), and respects mutual exclusivity/type constraints.
- Test long-context behavior: measure how truth encoding persists, accumulates, or decays over long sequences with mixed truthful/false prefixes; quantify sensitivity to the number and placement of misleading sentences.
- Control for stylistic/persona confounds: construct matched true/false pairs that minimize lexical and stylistic differences and verify the truth code is lexicon-independent rather than tracking personas or genre.
- Assess generalization across tasks and datasets: determine if a single truth subspace learned on one relation or corpus improves performance on unrelated factual tasks (e.g., TruthfulQA) without special fine-tuning.
- Provide scaling laws: study how model size, depth, head count, and training set size affect the onset time, strength, and layer localization of truth encoding; test for double descent phenomena systematically.
- Measure interaction with frequency and popularity biases: disentangle “majority truth” and frequency effects from factual correctness; test rare facts, long-tail entities, and debiasing techniques.
- Investigate conflicts between latent encoding and outputs: replicate and analyze cases where model predictions disagree with truth representations; diagnose which components (attention/MLP) override or ignore the truth code.
- Explore multi-relation multiplexing and superposition: determine whether truth encoding interferes with or shares subspace with relation-specific features; analyze whether the model uses separate truth codes per relation or a unified code.
- Study post-training modifications (RLHF, instruction tuning): test whether alignment procedures strengthen, weaken, or relocate the truth subspace; measure downstream effects on hallucination mitigation.
- Automate discovery of truth subspaces without labels: develop unsupervised or weakly supervised methods (e.g., contrastive objectives, clustering of contradiction signals) to detect and leverage truth directions in pretrained LMs.
- Quantify practical impact on hallucination reduction: evaluate intervention strategies on standardized benchmarks (e.g., TruthfulQA, HaluEval) and real user queries; report trade-offs in accuracy, calibration, and brittleness.
- Address ethical and epistemic limitations: clarify that “truth” operationalized as majority consistency can encode societal biases; propose methods to align the truth code with verified external knowledge bases or human oversight.
Practical Applications
Below are practical applications that flow from the paper’s findings on linear truth encodings, the Truth Co-occurrence Hypothesis (TCH), and the two‑phase training dynamics (memorization followed by truth encoding). Each item notes the relevant sectors, concrete tools/workflows that could emerge, and feasibility caveats.
Immediate Applications
- Truth-aware hallucination mitigation middleware (software, healthcare, finance, education)
- Build a lightweight probe (e.g., logistic regression) over hidden states to compute a “truth score” at inference time; trigger retrieval, abstention, or rephrasing when the score is low.
- Tools/Workflows: SDK to attach a probe to open-weight models; API endpoint that returns a per-token or per-sentence truth score; guardrail policies keyed off that signal.
- Assumptions/Dependencies: Access to hidden states; truth direction stability across prompts and domains; care with negation and distribution shifts.
- Inference-time steering toward truthful outputs (software, enterprise AI)
- Add a steering vector along the truth subspace (as demonstrated with Llama3 layer 11) to counter misleading context or raise confidence in correct completions.
- Tools/Workflows: “TruthSteer” library to select layers and magnitudes; automated calibration on validation sets.
- Assumptions/Dependencies: Need to identify the right layers and α; potential style/content drift; requires hidden-state intervention.
- Context hygiene in RAG and prompt pipelines (software, knowledge management)
- Detect low-truth prefixes and neutralize their effect by adjusting temperature or steering vectors before generation; re-rank retrieved documents by truth coherence.
- Tools/Workflows: “Context Neutralizer” middleware; retrieval re-weighting based on truth score.
- Assumptions/Dependencies: TCH holds sufficiently for target domains; latency overhead acceptable.
- Truth-aware confidence calibration and abstention (customer support, education, healthcare)
- Use layer-norm norm differences and truth signal to modulate softmax temperature (as in the toy model’s sharpening mechanism) and trigger abstention or “needs verification” banners.
- Tools/Workflows: Temperature scaling tied to truth score; user-facing uncertainty flags.
- Assumptions/Dependencies: Reliable mapping between norm/encoding and correctness; avoid overconfident false negatives.
- Content moderation and fact-checking triage via TCH (media, social platforms, policy)
- Compute a “Truth Coherence Score” for documents or threads; prioritize clusters likely to contain falsehoods for human review.
- Tools/Workflows: Batch scoring pipelines over news/social data; queue prioritization for moderators.
- Assumptions/Dependencies: Availability of labeled seeds; TCH intensity varies by domain and platform.
- Dataset curation to encourage truth encoding (model training, MLOps)
- Introduce paired examples (true/true and false/false) with controlled truth rate ρ (near 0.5 for maximal benefit) to accelerate emergence of truth subspaces.
- Tools/Workflows: Synthetic pair builder for relations; curriculum scheduling (memorize first, then encode truth).
- Assumptions/Dependencies: Impact depends on relation diversity and token frequency; risk of overfitting to proxies.
- Output–internal truth disagreement monitoring (“cognitive dissonance” alerts) (enterprise AI, compliance)
- Flag cases where the decoded truth encoding contradicts the model’s textual output, routing to human review or triggering re-generation.
- Tools/Workflows: Live monitoring dashboards; exception handling in agents.
- Assumptions/Dependencies: Robust probe; clear escalation policies; potential false positives.
- Persona detection and switching to higher-truth styles (customer applications, chat platforms)
- Identify low-truth personas/styles and steer the model’s tone toward high-truth personas (e.g., encyclopedic register).
- Tools/Workflows: Persona classifier + automatic style transfer prompts or steering.
- Assumptions/Dependencies: Lexical persona cues still matter; avoid homogenizing user voice.
- Targeted knowledge editing with truth validation (software, documentation, knowledge bases)
- Use associative memory insights to locate factual slots and apply edits; verify edits raise the truth score rather than just surface-level consistency.
- Tools/Workflows: “EditCheck” pipeline that probes truth encoding pre/post edit.
- Assumptions/Dependencies: Editing stability; concept drift; relation-specific probes.
- Truth-weighted summarization and search ranking (information services)
- Prefer sentences or sources with higher truth scores when summarizing or ranking; annotate low-truth segments.
- Tools/Workflows: Summarizers with truth-aware sentence selection; search ranker feature.
- Assumptions/Dependencies: Domain calibration; bias toward majority or frequent facts.
- Browser/IDE extensions for truth signaling in LLM answers (daily life, software engineering)
- Display inline truth indicators and “verify-on-demand” buttons; optionally steer before finalizing outputs (e.g., in coding or research assistants).
- Tools/Workflows: Client-side probes for open models; server-side scoring for closed models.
- Assumptions/Dependencies: Model access; acceptable latency; privacy considerations.
- Academic tooling for training-dynamics inspection (academia)
- Reproduce two-phase training (memorization → truth encoding) with counterfactual datasets; publish checkpoints and probes to standardize evaluations.
- Tools/Workflows: Benchmark suite (CounterFact/TCH instantiations); visualization of value matrix block structures and attention patterns.
- Assumptions/Dependencies: Reproducibility; compute; diverse relations to avoid proxy shortcuts.
Long-Term Applications
- Auxiliary objectives to explicitly learn a latent truth variable (model training, safety)
- Add a truth-bit prediction loss during training; encourage models to compute and propagate this bit across tokens to reduce LM loss under TCH.
- Tools/Workflows: Multi-task training heads; truth-bit consistency regularizers.
- Assumptions/Dependencies: Requires large-scale labeled/weakly-labeled truth datasets; risk of overfitting to frequency-based “truth.”
- Standardized “truth encoding” APIs and audits (policy, industry standards)
- Require vendors to expose truth-signal metrics for specific tasks; certify models that maintain robust truth encoding across domains and negation.
- Tools/Workflows: Audit suites; cross-domain stress tests; reporting templates.
- Assumptions/Dependencies: Regulator adoption; privacy and IP constraints on hidden-state access.
- Robust cross-relation truth subspaces and negation handling (software, safety-critical domains)
- Develop encodings that generalize across relations and remain stable under negation and stylistic shifts (addressing known fragility).
- Tools/Workflows: Multi-relation training corpora; negation-aware probes and steering.
- Assumptions/Dependencies: Semantic coverage; control of spurious proxies; extensive evaluation.
- Safety certification for truth-aware agents (healthcare, finance, legal)
- Integrate truth signals into agentic planning (chain-of-thought pruning, self-correction loops); mandate abstention and external verification in low-truth states.
- Tools/Workflows: Verification planners; “truth gates” in reasoning chains; human-in-the-loop escalations.
- Assumptions/Dependencies: Reliable detection; model interpretability; liability frameworks.
- Misinformation ecosystem mapping using TCH (media analysis, public policy)
- Apply co-occurrence analytics at scale to detect clusters of false statements; inform intervention strategies and platform policies.
- Tools/Workflows: Document-level truth coherence dashboards; early-warning signals.
- Assumptions/Dependencies: Persistent co-occurrence patterns; robust labeling; ethical use.
- Curriculum and scheduling derived from two-phase dynamics (MLOps, training efficiency)
- Systematically modulate truth rate ρ and relation diversity during training to optimize when truth encoding emerges relative to memorization.
- Tools/Workflows: Auto-curriculum synthesizers; checkpoint diagnostics to detect phase transition.
- Assumptions/Dependencies: Transferability across architectures; interaction with MLP layers and multi-head attention.
- Architectural variants to enhance truth detection (model design)
- Explore normalization schemes and attention/value-matrix designs that strengthen the sharpening mechanism and linear separability (e.g., specialized “confidence neurons”).
- Tools/Workflows: Ablations on layer-norm variants; value-matrix block regularization.
- Assumptions/Dependencies: Avoid narrowing general capabilities; maintain robustness.
- Truth-aware retrieval augmentation and editing pipelines (enterprise content systems)
- Automatically expand retrieval or require corroboration when truth score dips; validate edits against truth encoding across layers and checkpoints.
- Tools/Workflows: “Trust-first RAG” orchestrators; multi-layer consistency checks.
- Assumptions/Dependencies: Latency trade-offs; versioning of knowledge bases; cross-layer consistency.
- Persona governance and platform-level guardrails (platform policy)
- Detect and dampen low-truth personas at scale in user-generated content interfaces; offer high-truth persona defaults.
- Tools/Workflows: Persona classifiers; global guardrail policies; opt-in controls.
- Assumptions/Dependencies: Cultural and stylistic sensitivity; user consent; avoidance of censorship pitfalls.
- Benchmarks and maturity scoring for truth encoding (academia, procurement)
- Establish public benchmarks quantifying emergence, stability, and causal efficacy of truth encoding across model families and training steps.
- Tools/Workflows: Shared checkpoints; inter-model comparators; procurement checklists.
- Assumptions/Dependencies: Community coordination; standardized datasets; openness from vendors.
- Legal and compliance frameworks leveraging truth signals (policy, regulated sectors)
- Set minimum requirements for truth-aware operation in high-stakes domains (e.g., documentation of when models abstained due to low truth signal).
- Tools/Workflows: Compliance logging; audit trails of truth-score decisions.
- Assumptions/Dependencies: Regulatory acceptance; clear definitions of “truthfulness” vs “majority correctness.”
- Cross-modal extension of truth encoding (multimodal AI)
- Investigate linear truth signals in vision–language and speech–LLMs; use them to gate or steer multimodal outputs.
- Tools/Workflows: Probes for multimodal residual streams; multimodal steering vectors.
- Assumptions/Dependencies: Access to hidden states; alignment across modalities; quality of multimodal truth labels.
Notes on key assumptions across applications:
- The TCH (falsehoods cluster with falsehoods) holds to varying degrees by domain and corpus; effectiveness depends on that strength.
- Linear truth encoding may be biased toward majority/frequent facts and can be fragile under negation or stylistic shifts; domain-specific calibration is often needed.
- Many applications require access to hidden states or the ability to intervene; closed models may limit deployment or necessitate surrogate probes.
- The two-phase dynamic suggests curricula and diagnostics but may vary with architecture (e.g., multiple attention heads, MLPs) and training regimes.
Glossary
- Attention head: A single attention mechanism within a transformer layer that computes attention for one set of queries, keys, and values; "a single self-attention layer, one head"
- Attention-only transformer: A transformer architecture composed solely of self-attention (no MLPs), often used to isolate attention mechanisms; "training an attention-only transformer on this data results in linear truth encoding."
- Associative memory: A mechanism by which transformer components store and retrieve key–value patterns learned from data; "we build on the growing understanding of key–value associative memories in transformers."
- Binary entropy: The entropy of a Bernoulli variable, measuring uncertainty in a single bit; "L_{!\neg T}-\mathcal L_{!T}=H_2(\rho), the binary entropy of ."
- Causal interventions: Controlled manipulations of internal representations to test causal effects on model behavior; "causal interventions along those directions can steer LMs toward factual or counter-factual completions"
- Chi-squared test of independence: A statistical test used to assess whether two categorical variables are independent; "A test of independence confirms the association"
- CounterFact dataset: A benchmark of factual assertions designed to study and edit factual associations in LLMs; "We evaluate on the CounterFact dataset \citep{meng2022locating}"
- Cross-entropy: A loss function that penalizes deviations between predicted probability distributions and true labels; "per-token cross-entropy"
- Double descent: A training dynamic where performance improves, deteriorates, and then improves again as training progresses or model capacity increases; "the 1-layer model exhibits epoch-wise double descent"
- Inverse temperature: A scale factor in softmax that controls the sharpness of the output distribution; "softmax operation with inverse temperature~"
- Key–query matrix: The parameter matrix that maps inputs to keys and queries to compute attention weights; "if we also train the key-query matrix with~"
- Key–value lookup circuit: An internal mechanism that matches keys from context to retrieve associated values for prediction; "after the key–value lookup circuit forms"
- Layer-norm: A normalization operation that scales a vector by its norm (often RMS) to stabilize training and control feature magnitudes; "a basic layer-norm operation."
- Latent variable: An unobserved variable inferred by the model that influences predictions, such as truthfulness; "Truth as a latent variable."
- Linear manifold: A low-dimensional linear subspace capturing a concept across representations; "a low-dimensional linear manifold that cleanly separates true from false statements."
- Linear separator: A hyperplane (or direction) that separates classes in representation space; "admits a linear separation for true and false samples."
- Linear truth direction: A specific direction in hidden-state space that encodes truthfulness; "Linear truth direction"
- Logits: The pre-softmax scores produced by a model that are converted into probabilities; "which causes an amplification of the logits"
- Low-rank linear subspace: A small-dimensional subspace capturing a property (e.g., truthfulness) across many inputs; "encode a low-rank linear subspace that distinguishes true from false statements"
- Residual stream: The running hidden representation passed along layers via residual connections in a transformer; "residual stream representation in transformer-based LMs"
- RMS normalization: A form of layer normalization that uses the root-mean-square of activations; "with RMS normalization"
- Softmax: A function that converts logits into a probability distribution over classes; "softmax operation"
- Steering vector: A vector added to internal representations to shift model behavior along a desired direction; "add a steering vector "
- Truth Co-occurrence Hypothesis (TCH): The assumption that true statements co-occur with other true statements and false with false, making truth tracking loss-reducing; "We propose the Truth Co-occurrence Hypothesis (TCH)"
- Truth subspace: A representation subspace that linearly separates true from false statements; "such truth subspaces end-to-end"
- Unembedding: The linear projection from hidden states to output vocabulary logits; "unembedding vectors"
- Unembedding space: The vector space after projecting hidden states into output-logit dimensions; "after projecting to the unembedding space and applying softmax."
- Uniform causal attention: An attention pattern where a token attends uniformly to all previous tokens under causal masking; "a one-layer transformer with uniform causal attention"
- Value matrix: The transformer parameter that maps inputs to value vectors used in attention outputs; "where~ denotes the value matrix"
Collections
Sign up for free to add this paper to one or more collections.