$δ$-mem: Efficient Online Memory for Large Language Models
Abstract: LLMs increasingly need to accumulate and reuse historical information in long-term assistants and agent systems. Simply expanding the context window is costly and often fails to ensure effective context utilization. We propose $δ$-mem, a lightweight memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory. $δ$-mem compresses past information into a fixed-size state matrix updated by delta-rule learning, and uses its readout to generate low-rank corrections to the backbone's attention computation during generation. With only an $8\times8$ online memory state, $δ$-mem improves the average score to $1.10\times$ that of the frozen backbone and $1.15\times$ that of the strongest non-$δ$-mem memory baseline. It achieves larger gains on memory-heavy benchmarks, reaching $1.31\times$ on MemoryAgentBench and $1.20\times$ on LoCoMo, while largely preserving general capabilities. These results show that effective memory can be realized through a compact online state directly coupled with attention computation, without full fine-tuning, backbone replacement, or explicit context extension.
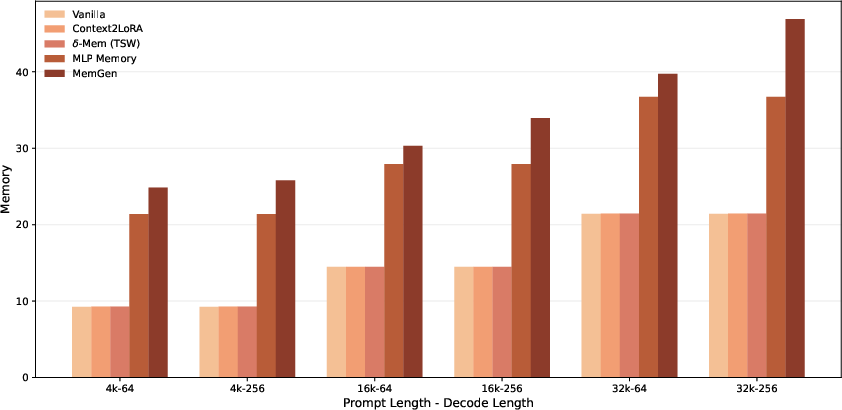
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping LLMs remember important things during long conversations or multi-step tasks without making them much bigger or slower. The authors introduce a small add-on called δ‑Mem (said “delta-mem”). Think of it like giving the model a tiny, smart notepad it can update as it goes. Even though this notepad is very small (just an 8×8 matrix), it helps the model recall useful details later and make better decisions, all while keeping the main model unchanged.
Key Objectives
The paper explores a few simple questions:
- Can a very small, always-updating memory help an LLM handle long, memory-heavy tasks?
- How can this memory plug into the model’s “attention” system (its way of focusing) without retraining the whole model?
- What’s the best way to write information into memory—every token, per message, or in multiple small memory slots?
- Will this work across different models and tasks, and does it keep general skills intact?
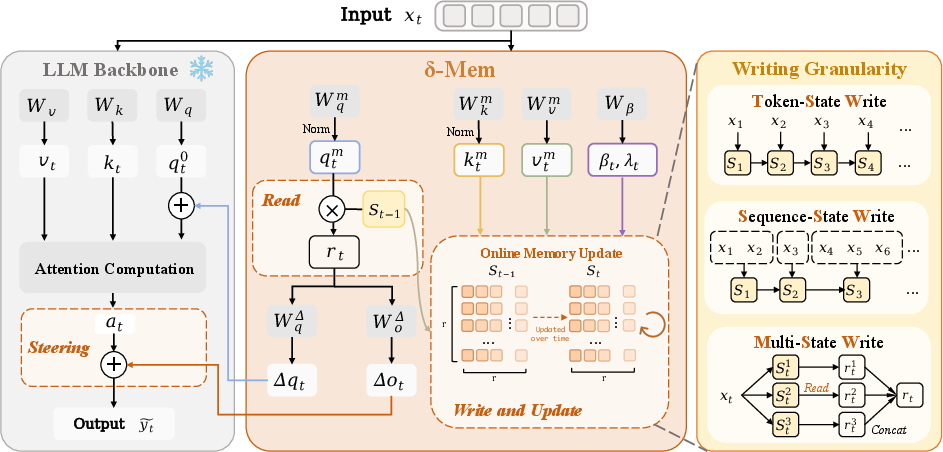
How It Works (Methods)
Here’s the big idea using everyday language:
- The model gets a tiny “online memory” (an 8×8 grid of numbers) that acts like a pocket notepad. It updates this notepad as the conversation continues.
- The memory is “associative,” meaning it tries to learn links like “when I see this kind of clue (key), I should remember that piece of info (value).”
What happens at each step:
- Project to a small memory space:
- The model takes its current internal state (like a thought) and turns it into three small vectors:
- a memory query (to read memory),
- a memory key,
- and a memory value (to write memory).
- The model takes its current internal state (like a thought) and turns it into three small vectors:
- Read from memory:
- The model uses the memory query to ask the notepad, “What do I remember that matches this?” This returns a small “memory signal,” like a hint from past experience.
- Steer attention with small nudges:
- Instead of stuffing more text into the prompt, the memory signal makes tiny adjustments (low-rank “nudges”) to the model’s attention system:
- It slightly adjusts the model’s question (query) about what to focus on.
- It also adds a small correction to the attention output.
- Think of attention as a spotlight. The memory gives a gentle push so the spotlight points at the right places.
- Instead of stuffing more text into the prompt, the memory signal makes tiny adjustments (low-rank “nudges”) to the model’s attention system:
- Write back to memory:
- After using the memory, the model updates the notepad. If the notepad’s guess about a key→value link is off, it corrects itself using a simple rule (the “delta rule”):
- Write more when it’s wrong (a “write” gate).
- Forget a bit when needed (a “forget” gate).
- This keeps the tiny memory stable and useful over time.
- After using the memory, the model updates the notepad. If the notepad’s guess about a key→value link is off, it corrects itself using a simple rule (the “delta rule”):
Writing choices the paper studies:
- Token-State Write (TSW): write at every token (very detailed but can be noisy).
- Sequence-State Write (SSW): write once per message/segment (smoother, less noise).
- Multi-State Write (MSW): keep several tiny notepads in parallel and combine them (reduces interference between different types of info).
Training:
- The main model stays frozen (not changed). Only the small memory-related parts are trained with normal supervised learning.
- During training, context gets “compressed” into the memory state instead of repeated as extra input text.
Main Findings
Here are the main results and why they matter:
- Strong gains on memory-heavy tasks:
- On MemoryAgentBench, performance went up by about 1.31×.
- On LoCoMo, performance went up by about 1.20×.
- A tough subtask (TTL) nearly doubled (from 26.14 to 50.50).
- Overall improvement with a tiny memory:
- With just an 8×8 memory, average scores rose to about 1.10× the frozen model and 1.15× better than the best non-memory baseline.
- Works across different models:
- The method improved small and medium-sized backbones (e.g., Qwen3-4B, Qwen3-8B, SmolLM3-3B). Smaller models especially benefited from using multiple memory states (MSW).
- Memory helps even when context is missing:
- When the original conversation history was removed, the tiny memory still recovered helpful info, noticeably boosting scores on HotpotQA and LoCoMo. This shows the memory truly stores useful signals, not just repeats text.
- Best ways to connect and place memory:
- Adding the memory’s nudges to the attention query and output branches worked best for performance vs. efficiency.
- Applying memory across all layers gave the strongest results; mid-layer insertion alone was the best partial alternative.
- Better than common alternatives:
- Compared to text-based memory (like retrieval or summarization), this avoids context bloat and retrieval noise.
- Compared to parametric add-ons (like LoRA tuned as memory), this online memory adapts on-the-fly instead of being static.
- Compared to outside memory modules, this approach plugs directly into attention, avoiding extra retrieval cost and mismatches.
Why It Matters (Implications)
- Cheaper, faster long-term “remembering”:
- Instead of paying for huge context windows (which are slow and not always effective), a tiny, always-updating memory can guide the model’s focus efficiently.
- Better assistants and agents:
- Long-term helpers (like study buddies, coding aides, or task bots) can remember user preferences and past steps more reliably without constantly reloading old text.
- Simple to deploy:
- The main model stays frozen. You don’t need to retrain or replace the backbone, and you don’t need a complicated retrieval system.
- Scalable design:
- This shows that “small but smart” memory can go a long way. Future work can explore slightly bigger memories, better write strategies, or combining this with other techniques for even stronger, reliable remembering.
In short, δ‑Mem proves that a tiny, well-placed memory that directly nudges attention can meaningfully improve how LLMs handle long, memory-heavy tasks—without making them bulky or slow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list distills what remains missing, uncertain, or unexplored, and frames concrete directions for future research.
- Memory capacity and scaling laws: Quantify how performance scales with the memory state size r (e.g., 8×8 vs larger matrices), number of sub-states N (MSW), and per-layer insertion, including theoretical bounds on what an OSAM of given rank can retain over long horizons.
- Convergence and stability analysis: Provide formal guarantees (or empirical stress tests) for the gated delta-rule updates (λ, β) under long sequences, including conditions that prevent divergence, oscillation, or memory drift/interference.
- Retention curves and longevity: Systematically measure what types of information (facts, preferences, temporal events) the OSAM retains and for how long, across thousands to millions of tokens, with controlled time-lag and interference experiments.
- Extremely long-context robustness: Evaluate delta-Mem in regimes with 100k–1M-token contexts and under context rot/adversarial noise, to test whether compact OSAM mitigates degradation at scale.
- Cross-session persistence: Define and evaluate mechanisms for saving/loading OSAM across sessions (e.g., multi-day assistants), including decay policies and identity-scoped state management (per-user, per-task).
- Privacy, safety, and governance: Analyze risks of storing sensitive user data in OSAM (state leakage, cross-user contamination), and develop eviction, encryption, audit trails, and consent controls tailored to online state memory.
- Hallucination and bias impacts: Measure whether memory steering amplifies or suppresses hallucination, bias, and error propagation, especially when OSAM encodes incorrect or adversarially injected associations.
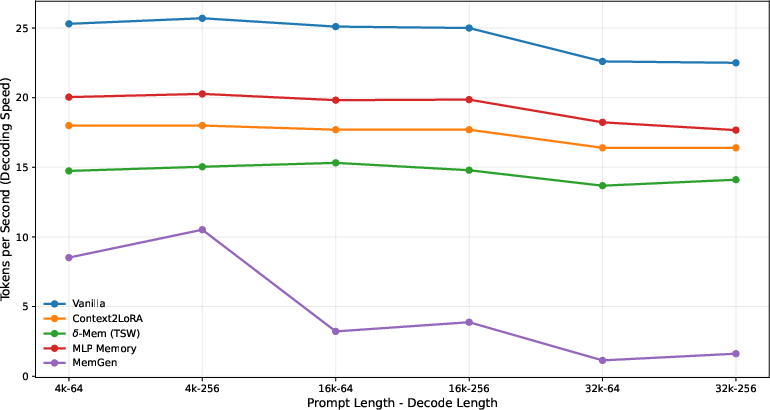
- Runtime and resource overhead: Report latency, throughput, memory footprint, and energy costs of per-token OSAM read/write and attention corrections, compared to strong RAG and adapter baselines under matched hardware.
- Compatibility with KV caching: Clarify how query/output-side corrections interact with KV caches (e.g., cache invalidation or reuse), and whether memory-induced query shifts degrade cache effectiveness.
- Architecture generality: Test on diverse backbones (e.g., Llama, Mistral, Mixtral, MoE, sparse/linear attention) to assess portability, including whether steering points need adaptation for non-standard attention blocks.
- Injection targets beyond attention: Explore memory corrections to additional modules (FFN/MLP layers, residual streams) and assess whether multi-site steering yields better trade-offs than qo-only.
- Hyperparameter sensitivity: Provide ablations for α, r, gate parametrization, projection norms (tanh + L2norm), and learning schedules to identify robust defaults and failure regimes.
- Automatic segmentation and routing: Replace heuristic segment averaging (SSW) and static MSW allocation with learned segmentation and dynamic routing into sub-states; study their benefits and stability.
- Information typing in MSW: Develop mechanisms to automatically disentangle facts, preferences, tasks, and local events into different sub-states, including diagnostics for interference across sub-states.
- Nonlinear state updates/readouts: Compare delta-rule OSAM against alternative associative memory dynamics (e.g., Oja’s rule, Hebbian variants, gated RNN-like cell updates, kernel memories) and nonlinear readouts.
- Training regimes beyond SFT: Evaluate online/continual learning, RLHF, or on-policy distillation to adapt projections and gates to evolving histories, and measure catastrophic forgetting vs adaptation.
- Failure case analysis and interpretability: Provide tools to inspect what OSAM stores (e.g., probing, counterfactual tests, memory audits) and link readout vectors to human-understandable content.
- Combined memory pathways: Study hybrid systems that integrate compact OSAM with textual/vector RAG (inside- and outside-channel) to understand complementarity and optimal orchestration.
- Broader task coverage: Extend evaluation to coding, math, multilingual dialogue, tool-use, and agent benchmarks with adversarial memory (e.g., include LoCoMo adversarial category) to test generalization and robustness.
- Personalization and multi-user isolation: Evaluate per-user OSAM instances, isolation guarantees, and migration strategies (cold-start, warm-start), including metrics for personalization quality and safety.
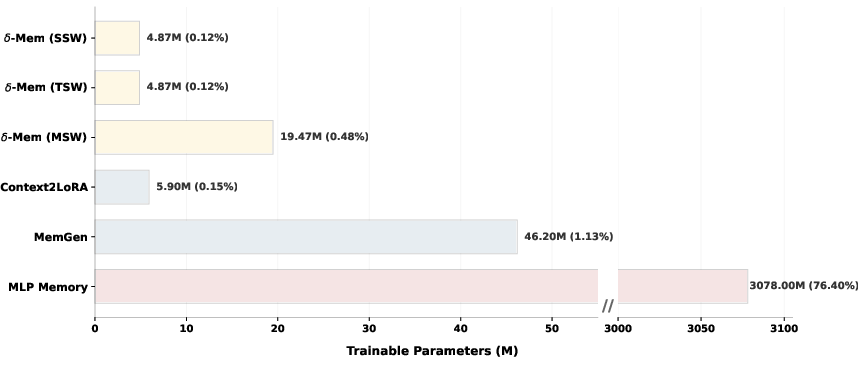
- Parameter budget accounting: Report exact parameter counts and per-layer allocations for qo vs qkvo variants across backbones; quantify the marginal gains vs added parameters to inform deployment decisions.
- Degradation trade-offs: Investigate observed fluctuations on general capabilities (e.g., IFEval) and identify conditions where memory steering harms instruction following or domain-specific performance.
- Layerwise policy learning: Move beyond fixed layer sets (front/middle/back/all) by learning a layer selection policy or per-layer gate strengths that adapt to backbone capacity and task demands.
- Interaction with token noise and formatting: Assess TSW susceptibility to punctuation, boilerplate, and code tokens; develop noise-robust write strategies or token filters.
- Adversarial and poisoning resistance: Stress-test memory poisoning (malicious sequences that shift OSAM) and propose defenses (anomaly detection, gated trust, provenance signals).
- Reproducibility and data transparency: Document training data, segmenting heuristics, seeds, and preprocessing choices to enable strict replication and controlled comparisons with baselines.
- Standardized diagnostics: Introduce benchmarks and metrics that isolate memory-specific capabilities (e.g., controllable interference tests, delayed recall, confounded retrieval) to more precisely attribute gains to OSAM.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging the paper’s delta-rule online memory (δ-Mem) that augments a frozen Transformer with a compact, dynamic associative memory state and low-rank attention corrections.
- Personalized customer support assistants
- Sector: customer service, e-commerce, telecom
- What: Maintain per-customer interaction memory (issues, preferences, resolutions) without long prompt histories; steer attention via δ-Mem rather than prepending past chats.
- Tools/workflows: Per-session memory store for the 8×8 (or r×r) OSAM matrix; SSW at message boundaries to reduce noise; MSW to separate “account,” “product,” and “issue” memories; deploy as middleware around a frozen open-weight LLM (e.g., Qwen3-4B/8B).
- Assumptions/dependencies: Access to model internals for query/output corrections; storage pipeline to persist S across sessions; privacy controls for memory reset.
- Coding copilots that remember project context across long sessions
- Sector: software engineering, DevTools
- What: Persist repository-specific conventions, architectural decisions, and prior errors; reduce token costs versus replaying long diffs/issues.
- Tools/workflows: IDE extension that saves OSAM per repo; SSW at file-save or PR boundaries; MSW to isolate “APIs,” “style,” and “tickets”; Qo default injection for best perf-efficiency.
- Assumptions/dependencies: Open/fine-grained access to inference stack for low-rank corrections; segmented write boundaries derived from editor events.
- On-device or edge assistants with memory under tight compute/memory budgets
- Sector: mobile, IoT, embedded
- What: Use tiny online states (as small as 8×8) to preserve preferences and routines on-device; avoid long contexts and external retrieval.
- Tools/workflows: Lightweight δ-Mem module compiled with the backbone; TSW for fine-grained local tasks; periodic decay via gates (λ) to control drift; encrypted local state.
- Assumptions/dependencies: Compatible open-weight small models (e.g., SmolLM3-3B) and runtime kernels; energy-aware scheduling.
- Long-horizon tool-using agents
- Sector: automation, enterprise AI operations
- What: Agents retain task progress, tool outcomes, and failures across steps and episodes; memory steers planning without ballooning context windows.
- Tools/workflows: MSW with sub-states per tool/skill; SSW per “agent step” to reduce token noise; plug δ-Mem read/write into the agent loop (before attention, after generation).
- Assumptions/dependencies: Agent framework that exposes hidden states and allows per-step state persistence.
- Educational tutors that adapt across sessions
- Sector: education/EdTech
- What: Track student misconceptions, mastery, and preferences; avoid repetitive probing or long replayed transcripts.
- Tools/workflows: SSW per lesson; MSW for “skills,” “content areas,” and “motivation cues”; memory-aware lesson planning prompts; simple dashboard to reset/export memory.
- Assumptions/dependencies: Safeguards for bias and inappropriate carryover; parental/learner controls for deletion and portability.
- Clinical intake and follow-up assistants (pilot/low-risk triage)
- Sector: healthcare front-desk, care navigation
- What: Persist key symptom trends and logistics across interactions without re-exposing full PHI in prompts.
- Tools/workflows: SSW at encounter-level; strict retention gates; memory reset policies; audit logs for read/write events; deploy with a frozen, vetted backbone.
- Assumptions/dependencies: Not for diagnostic autonomy; regulatory review; privacy impact assessment; on-prem or VPC deployment.
- Financial advisory chatbots with consistent preference recall
- Sector: finance, wealth management
- What: Remember risk tolerance, constraints, and time horizons across chats; reduce cost and risk of leaking past details in prompts.
- Tools/workflows: MSW to separate “risk,” “goals,” and “constraints”; periodic “forgetting” via gate schedules; compliance hooks to export/erase memory.
- Assumptions/dependencies: Model governance and suitability checks; auditable state persistence; client consent for retention.
- Cost and latency optimization in LLM serving
- Sector: model serving, MLOps
- What: Replace large prompt histories and retrieval pipelines with compact OSAM; reduce input tokens and retrieval calls.
- Tools/workflows: Memory middleware for HF/Transformers servers; Redis/KeyDB-backed S store keyed by session/user; A/B switch for qo vs qkvo injection; per-route guardrails.
- Assumptions/dependencies: Ability to run a slightly modified forward pass; careful cache/key invalidation and state TTLs.
- Privacy-by-design conversational systems
- Sector: cross-industry
- What: Retain information in latent memory (not raw text), lowering exposure in logs and prompts.
- Tools/workflows: Memory minimization policies; “right-to-be-forgotten” via OSAM reset; “context recovery” tests to probe leakage; encrypted state at rest/in transit.
- Assumptions/dependencies: Latent memory can still encode PII—requires DPIAs, red-team testing, and user controls.
- Research baselines and diagnostics for memory-heavy evaluation
- Sector: academia/industrial research
- What: Use δ-Mem as a simple, reproducible memory augmentation to study long-horizon reasoning, interference (TSW vs SSW vs MSW), and context recovery.
- Tools/workflows: Plug into benchmark harnesses (HotpotQA, LoCoMo, MemoryAgentBench); ablation suites for head injection and layer depth; memory drift visualizers.
- Assumptions/dependencies: Availability of open backbones; reproducible training SFT data and seeds; licensing of benchmark datasets.
Long-Term Applications
These opportunities likely require additional research, integration, standard-setting, or scaling beyond the current paper’s experiments.
- Unified OS-level personal memory across apps and devices
- Sector: consumer platforms, operating systems
- What: A standardized δ-Mem API where apps write segment-level signals; the OS maintains per-user multi-state associative memory to personalize all assistants.
- Potential products/workflows: “Memory daemon” with MSW sub-states per domain (calendar, comms, media); cross-device sync; memory transparency UI.
- Assumptions/dependencies: Interoperability standards, user consent/controls, strong encryption, and revocation; broad developer ecosystem buy-in.
- Privacy-preserving personalization via on-device δ-Mem + federated orchestration
- Sector: mobile, healthcare, finance
- What: Keep memory on-device; optionally learn population-level memory policies centrally without sharing raw states.
- Potential products/workflows: Federated tuning of gates/write-granularity; DP noise for memory metrics; on-device audits.
- Assumptions/dependencies: Efficient on-device training/inference; formal privacy guarantees; regulatory acceptance.
- Continual learning bridges between stateful memory and parametric updates
- Sector: foundation models
- What: Use OSAM to stage information before curated, periodic parametric consolidation (e.g., memory-to-LoRA distillation).
- Potential products/workflows: “Consolidation jobs” that snapshot stable memory sub-states into adapters; rollback/versioning; drift monitors.
- Assumptions/dependencies: Reliable criteria for “stability” and safety of consolidation; prevention of catastrophic bias accumulation.
- Safety and governance standards for stateful AI memory
- Sector: policy, compliance
- What: Define consent, retention limits, portability, and auditability for latent memory states; certification for “ephemeral by default” assistants.
- Potential products/workflows: Memory policy SDKs; standardized “memory manifests” describing sub-states, lifetimes, and purposes.
- Assumptions/dependencies: Regulator and standards-body engagement; harmonization across jurisdictions (e.g., GDPR, HIPAA, GLBA).
- Memory-augmented multi-agent systems at enterprise scale
- Sector: automation, operations, logistics
- What: Teams of agents with MSW per role (planner, executor, reviewer) to reduce interference and improve coordination over weeks/months.
- Potential products/workflows: Memory routers that allocate writes to role-specific sub-states; cross-agent alignment protocols; memory health dashboards.
- Assumptions/dependencies: Robust segmentation signals; failure recovery; provenance tracking across agents.
- Robotics and embodied AI with compact associative memory
- Sector: robotics, manufacturing, warehousing, home automation
- What: Onboard δ-Mem for long-horizon tasks, object/place associations, and routine adaptation; reduced reliance on cloud prompts.
- Potential products/workflows: Hardware-accelerated OSAM updates; event-based SSW at task phase boundaries; MSW for “maps,” “tools,” and “tasks.”
- Assumptions/dependencies: Tight integration with perception/planning stacks; real-time constraints; safety certification.
- Domain-specific clinical decision support with EHR-integrated memory
- Sector: healthcare
- What: Memory-guided attention that fuses structured EHR signals into δ-Mem and steers reasoning on guidelines and longitudinal trends.
- Potential products/workflows: EHR adapters that write curated features into sub-states; clinician-in-the-loop memory editing; post-market surveillance.
- Assumptions/dependencies: Extensive validation, bias audits, and approval pathways; integration with existing clinical IT.
- Hardware and neuromorphic implementations of OSAM updates
- Sector: semiconductors, edge AI
- What: Map the gated delta-rule and low-rank corrections onto analog/digital memory arrays for ultra-low-power stateful LLMs.
- Potential products/workflows: Co-processors for OSAM updates; instruction sets for memory read/write; in-memory compute prototypes.
- Assumptions/dependencies: Co-design with model architectures; manufacturability; software toolchains.
- Cloud “stateful attention steering” as a managed service
- Sector: AI platforms, cloud
- What: Offer per-session δ-Mem with SLAs for latency and cost; API endpoints for write granularity control and memory introspection.
- Potential products/workflows: Serverless-compatible memory store; RBAC for memory operations; billing by state size and read/write ops.
- Assumptions/dependencies: Support from popular inference stacks; tenancy isolation; ecosystem of adapters.
- Evaluation and monitoring suites for memory quality, drift, and leakage
- Sector: MLOps, QA
- What: Continuous tests akin to “context recovery” to quantify how much salient information is retained and whether harmful info persists.
- Potential products/workflows: Benchmarks tailored to business data; red-team harnesses for memory probing; alerting on over-retention or under-performance.
- Assumptions/dependencies: Access to representative real-world tasks; safe synthetic test generation; stakeholder-defined KPIs.
Glossary
- approximate kNN: A fast, approximate search method for retrieving the k nearest neighbors in high-dimensional spaces, often used to fetch similar representations. "retrieve them with approximate kNN"
- associative memory: A memory that stores key→value associations so a query retrieves its linked value by learned association. "an online state of associative memory~(OSAM)"
- associative memory space: A learned low-dimensional space in which keys, queries, and values for memory operations are represented. "low-dimensional associative memory space"
- autoregressive cross-entropy: The standard next-token prediction loss computed over sequences in language modeling. "The loss is the autoregressive cross-entropy over response tokens:"
- BM25 RAG: A retrieval-augmented generation setup that uses BM25 to fetch relevant text and prepend it to the prompt. "we consider BM25 RAG~\citep{lewis2020retrieval}, which retrieves relevant historical text and prepends it to the context;"
- context rot: The degradation of model performance as the context becomes very long, despite more information being present. "context degradation or context rot"
- context window: The maximum number of tokens a model can consider in its attention; increasing it raises cost and may not help utilization. "Simply expanding the context window is costly"
- delta-rule learning: An error-corrective online update rule (akin to SGD) that adjusts memory based on prediction residuals. "updated by delta-rule learning"
- forget gate: A learned gating factor that scales prior memory to control how much past information is retained. "we further introduce a forget gate to control long-range state evolution:"
- frozen full-attention backbone: A pretrained Transformer kept fixed (no fine-tuning) that uses standard full attention as the base model. "a frozen full-attention backbone"
- gated delta update: A delta-rule memory update modulated by gates that control forgetting and writing strength. "This gated delta update forms the basis of the stable online memory dynamics in ."
- GPQA-Diamond: A challenging subset of the GPQA benchmark assessing advanced question answering and reasoning. "GPQA-Diamond~\citep{rein2023gpqa}"
- IFEval: A benchmark focused on instruction-following capabilities of LLMs. "IFEval~\citep{zhou2023instructionfollowingevaluationlargelanguage}"
- LoCoMo: A benchmark evaluating long-context memory and reasoning in LLMs. "LoCoMo~\citep{maharana2024evaluating}"
- long-horizon agent systems: Agent setups requiring extended sequences of actions and interactions where long-term memory matters. "long-horizon agent systems~\citep{yao2022react, openai2026codex, anthropic2026claude_code}"
- LoRA: Low-Rank Adaptation, a method that adds trainable low-rank matrices to a frozen model for efficient adaptation. "LoRA~\citep{hu2022lora}"
- low-rank corrections: Small-rank adjustments injected into attention components (e.g., queries, outputs) to steer computation using memory signals. "low-rank corrections to the attention computation"
- MemoryAgentBench: A benchmark to assess the retention, retrieval, and use of memory across long interactions. "MemoryAgentBench~\citep{hu2025evaluating}"
- multi-hop reasoning: Reasoning that integrates multiple pieces of evidence across steps or documents. "General multi-hop reasoning"
- Multi-State Write (MSW): A writing strategy that maintains multiple parallel memory sub-states and aggregates their readouts to reduce interference. "Multi-State Write~(MSW)."
- online regression loss: A per-step squared-error objective used to update the memory state to better predict values from keys. "can then be regarded as optimizing an online regression loss"
- online state of associative memory (OSAM): The compact, continually updated matrix storing key–value associations for use during generation. "online state of associative memory~(OSAM)"
- output-side correction: A learned adjustment added to the attention output to incorporate memory-derived signals. "an output-side correction"
- Outside-channel memory mechanisms (OMMs): Memory stored in external modules that interface with the backbone via separate retrieval/encoding pathways. "Outside-channel memory mechanisms (OMMs)"
- Parametric memory mechanisms (PMMs): Memory encoded directly into model parameters (e.g., adapters, prefixes), typically static after training. "Parametric memory mechanisms (PMMs)"
- Prefix-Tuning: A method that learns continuous virtual tokens (prefixes) to guide a frozen model’s behavior. "Prefix-Tuning~\citep{li2021prefix}"
- query-side correction: A learned adjustment added to the attention query vector to bias attention based on memory signals. "a query-side correction"
- retrieval-augmented generation: Generation augmented by retrieving external content and conditioning the model on it. "retrieval-augmented generation process"
- retention gate: A learned gate that controls how much of the previous memory state is preserved during updates. "The write gate and retention gate are also determined by the current hidden state:"
- Sequence-State Write (SSW): A writing strategy that updates memory once per message/segment using an averaged representation. "Sequence-State Write~(SSW)."
- SFT: Supervised Fine-Tuning; training a model (or add-on) using labeled data with teacher-forced next-token prediction. "trained with the standard SFT loss."
- sigmoid function: The S-shaped nonlinear function mapping real values to (0,1), commonly used for gating. "σ is the sigmoid function."
- Textual memory mechanisms (TMMs): Memory stored as text (entries/summaries) that is injected back into the input context. "Textual memory mechanisms (TMMs)"
- Token-State Write (TSW): A writing strategy that updates memory at every token position, capturing fine-grained changes. "Token-State Write~(TSW)."
- write gate: A learned per-dimension factor controlling how strongly new residual information is written into memory. "The write gate and retention gate are also determined by the current hidden state:"
- writing granularity: The unit of memory updates (e.g., token, segment), affecting stability and detail of the stored state. "the memory mechanism also depends on the definition of writing granularity."
Collections
Sign up for free to add this paper to one or more collections.