ELF: Embedded Language Flows
Abstract: Diffusion and flow-based models have become the de facto approaches for generating continuous data, e.g., in domains such as images and videos. Their success has attracted growing interest in applying them to language modeling. Unlike their image-domain counterparts, today's leading diffusion LLMs (DLMs) primarily operate over discrete tokens. In this paper, we show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. We propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network. This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG). Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.



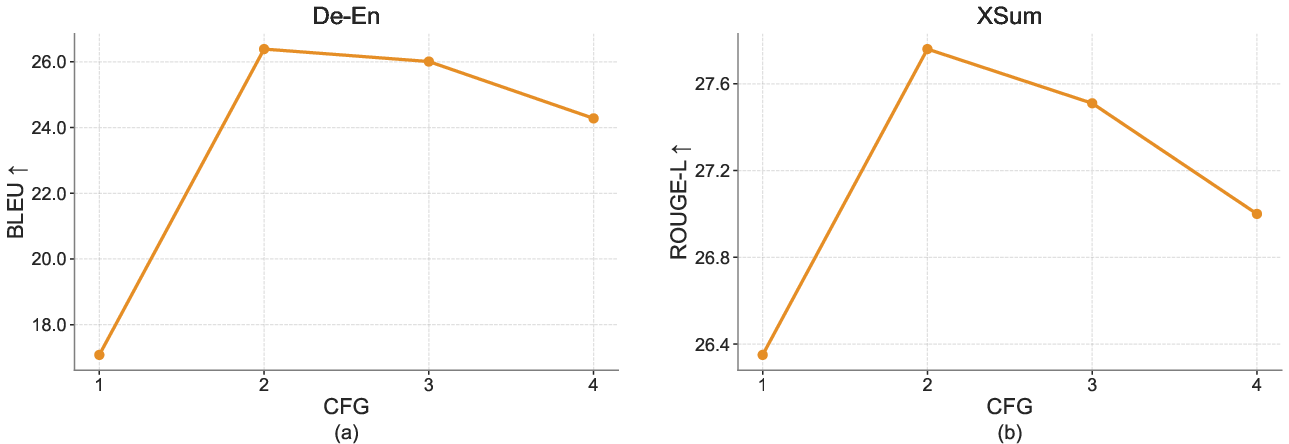
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
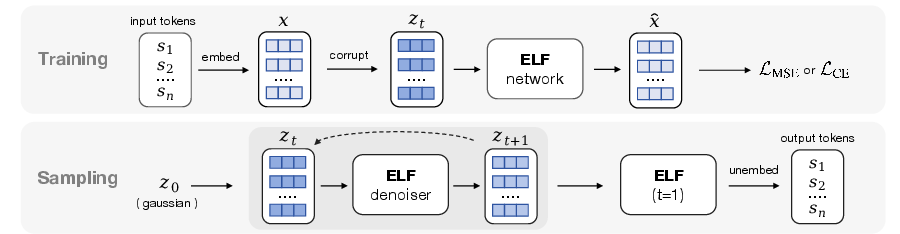
This paper introduces a new way for computers to write text called ELF (Embedded Language Flows). It takes a technique that’s been very successful for making images (diffusion/flow models) and adapts it to language. The big idea: instead of working directly with words, ELF works with smooth, continuous “word coordinates” (called embeddings), cleans them up step by step, and only turns them back into actual words at the very end. This makes it faster and often better than earlier methods that worked directly with words at every step.
Key Questions the Paper Tries to Answer
- Can a LLM generate better text by staying in a smooth, continuous space (embeddings) almost the entire time and only switching back to actual words at the end?
- Can this approach reuse powerful tricks from image diffusion models (like “guidance” to steer outputs) to improve text quality and efficiency?
- Will this method be faster, need fewer steps, and require less training data than competing diffusion-based LLMs?
How ELF Works (In Simple Terms)
Turning words into numbers: embeddings
Think of each word (or sub-word token) as being placed at a point in a huge coordinate system—like giving every word a GPS location in a very high-dimensional space. These coordinates are called embeddings. ELF uses an encoder to map text into these continuous embeddings. Working in this smooth space lets the model make tiny adjustments easily, instead of jumping between whole words.
From noise to clean text: Flow Matching
Imagine starting with TV static and gradually revealing a clear picture. ELF does something similar: it starts with random noise embeddings and “flows” toward clean, meaningful embeddings that represent a sentence. The method guiding this cleanup is called Flow Matching. You can picture it as drawing a path from noisy points to clean points and learning the “velocity” (direction and speed) at each moment to get there smoothly.
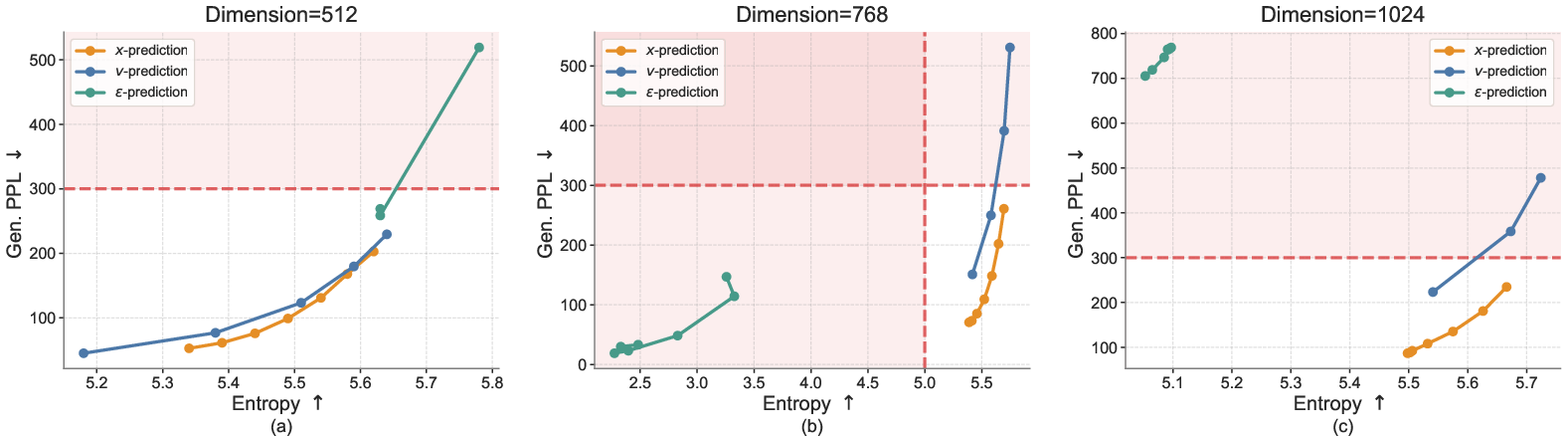
A practical detail: ELF predicts the clean embeddings directly (the “x-prediction”) rather than predicting the velocity first. This makes training stable and matches nicely with turning embeddings back into tokens at the final step.
Training in two modes with one network
ELF uses one shared neural network for two jobs:
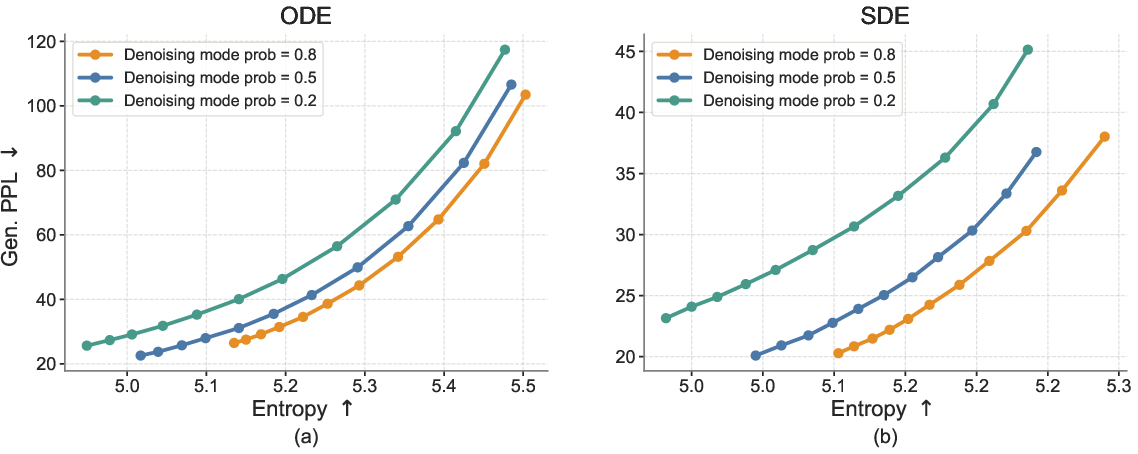
- Denoising mode (most steps): The network gets a partly noisy embedding and learns to predict the clean version. It’s trained with a simple “how close are we?” score (mean squared error).
- Decoding mode (final step): The network turns the final clean embeddings into actual words. This last step uses a standard “pick the right word” loss (cross-entropy). Because the same network does both jobs, there’s no extra decoder to run at test time.
Generating text (inference)
To write a sentence:
- Start with random noise embeddings.
- Take a small step along the learned flow to make them a bit cleaner.
- Repeat for a fixed number of steps (like 32 or 64).
- At the last step, switch to decoding mode and turn the final embeddings into words.
ELF supports two ways to step forward:
- ODE (deterministic): like calmly following a path.
- SDE-like (adds a little randomness each step): sometimes helps avoid mistakes and get better results in fewer steps.
Steering the model: guidance
ELF borrows “classifier-free guidance” (CFG) from image models. Guidance is like a steering wheel: turning it more can make outputs higher quality but a bit less diverse; turning it less gives more variety but sometimes lower quality. ELF uses a simple trick called self-conditioning (using its own previous guess as a hint) to make this guidance work well without extra cost at test time.
Main Findings and Why They Matter
Here are the key results the authors report:
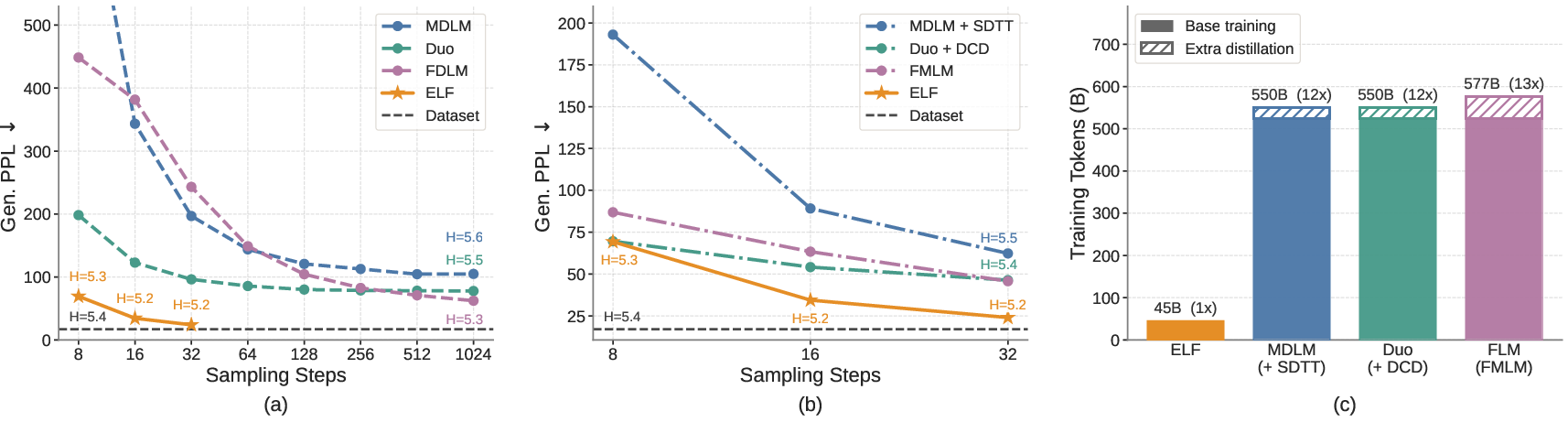
- Better text quality with fewer steps:
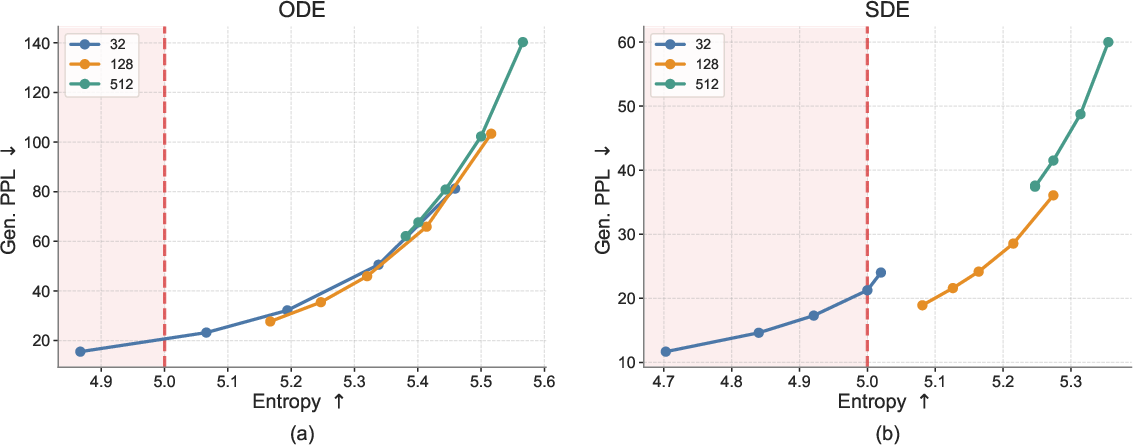
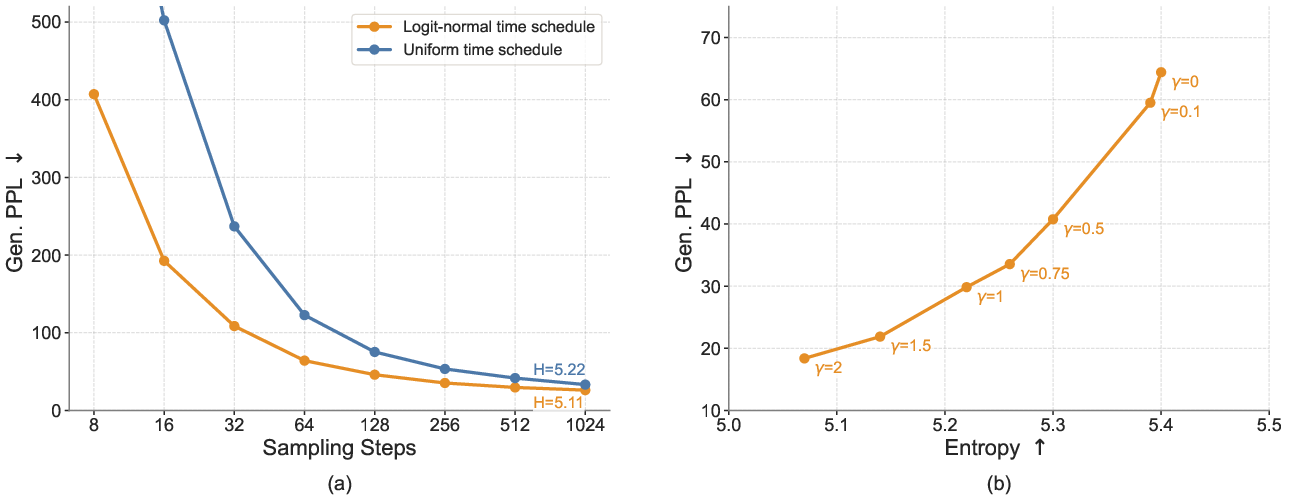
- ELF beats top diffusion LLMs (both those that operate on words directly and those in continuous space) on a common benchmark. For example, it achieves strong “generative perplexity” with as few as about 32 steps. Perplexity here is a measure of how “surprising” the text is to a separate LLM—the lower, the better.
- No special distillation needed:
- Some competing methods need an extra training phase (distillation) to run fast with few steps. ELF doesn’t—it’s already fast and strong without that extra work.
- Much less training data:
- ELF reportedly uses about 10× fewer training tokens than many diffusion LLMs and still performs better. This makes it more practical and cheaper to train.
- Works for translation and summarization:
- ELF gets higher scores than similar-sized models on German-to-English translation (BLEU) and summarization (ROUGE). In simple terms, it translates more accurately and summarizes more effectively.
- Helpful design details:
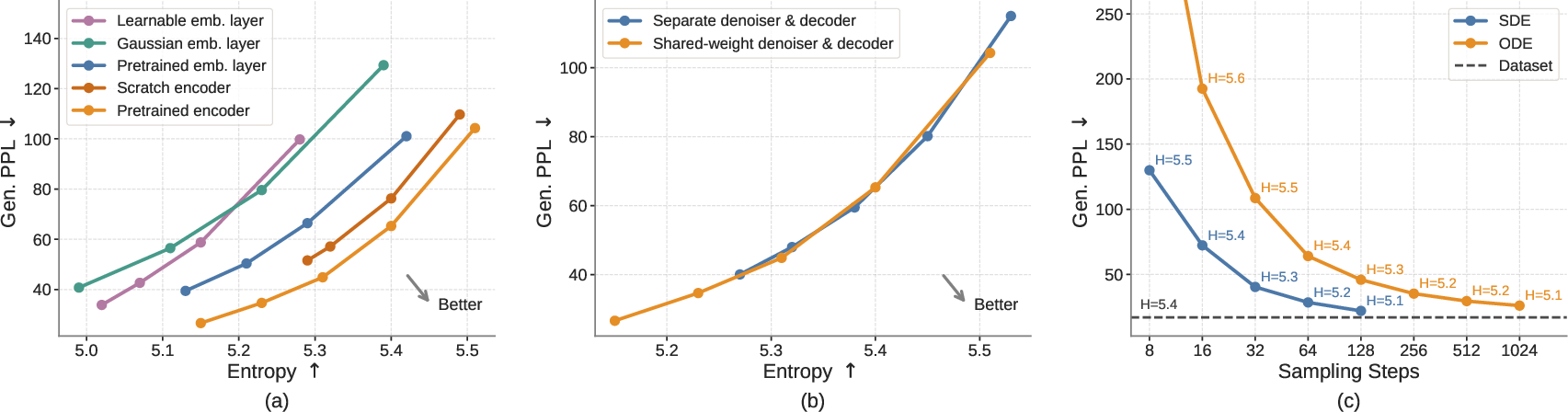
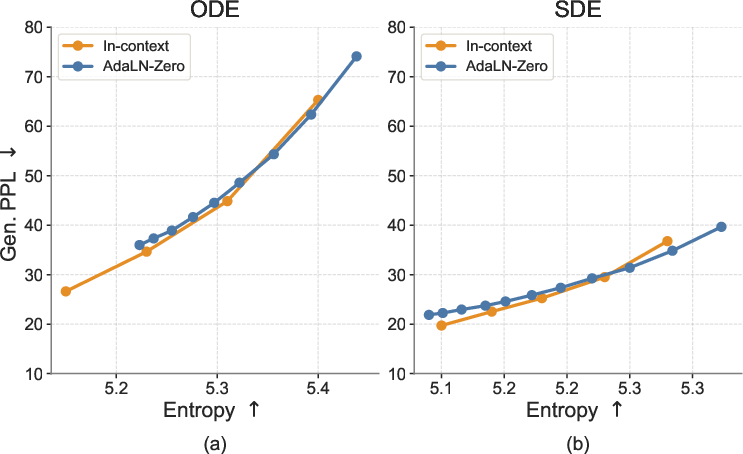
- Using pretrained contextual embeddings (from a model like T5) gives better results than simple, non-contextual embeddings.
- The shared denoiser–decoder setup is effective and simpler than training a separate decoder.
- Adding a little randomness during sampling (the SDE-like way) often improves quality when you only have a few steps.
- Larger ELF models keep improving quality and diversity, showing good scaling behavior.
What This Could Mean Going Forward
- A simpler, stronger path for diffusion-based text models: By doing almost everything in continuous embedding space and only converting to words at the end, ELF keeps training and sampling straightforward and fast.
- Easy reuse of image-generation advances: Because ELF is continuous (like image diffusion models), powerful tricks from images—like guidance—transfer cleanly to text.
- More efficient training: Getting strong results with far fewer training tokens makes diffusion LLMs more accessible and eco-friendlier.
- Broad usefulness: Strong results on translation and summarization suggest this approach could help many text tasks. With further scaling and refinement, ELF-like models could become a core alternative to standard autoregressive LLMs for certain applications.
In short, ELF shows that staying “continuous” almost all the way, then discretizing at the end, can make diffusion-based language generation both high-quality and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and missing analyses that future work could address to strengthen and extend ELF.
- Data efficiency accounting: the paper’s “10× fewer training tokens” claim excludes tokens used to pretrain the frozen T5 encoder; quantify and report total effective pretraining tokens to fairly compare with baselines.
- Variable-length generation: ELF fixes sequence length and decodes via a single final argmax step; investigate modeling and sampling of variable-length outputs (e.g., EOS prediction, dynamic length modeling, length priors, insertion/deletion flows).
- Final-step-only discretization: assess whether deferring discretization to the last step harms syntactic consistency or long-range structure; run targeted tests (agreement, coherence, discourse markers) and compare with per-step token supervision variants.
- CE–MSE mixing sensitivity: the training uses an 80% MSE vs. 20% CE mixture without sensitivity analysis; ablate the mixing ratio, schedules (e.g., ramp-up/down), and mode-conditioning design to understand stability, convergence, and decoding accuracy.
- Encoder dependence: performance relies on a specific pretrained T5 encoder; evaluate across encoder types (contextual vs. non-contextual, multilingual encoders, different tokenizers), frozen vs. finetuned encoders, and quantify how encoder quality affects ELF’s frontier.
- Embedding-space design: only a 128-d bottleneck on 512-d contextual embeddings is tried; systematically ablate embedding dimensionality, bottleneck magnitude, normalization schemes, and positional encoding to map quality–efficiency trade-offs.
- Tokenization effects: study robustness across tokenizers (SentencePiece, BPE, WordPiece, byte-level) and vocabulary sizes; measure OOV handling, rare-token fidelity, and subword fragmentation impacts on final decoding via the unembedding matrix.
- Unembedding calibration: the learnable unembedding matrix W is only trained with CE at t=1; analyze calibration, confidence, and logit scaling (e.g., temperature, label smoothing), and test alternatives (weight tying, shared embedding matrices) to reduce miscalibration.
- Corruption at t≈1: the decoding branch introduces an ad hoc token-level corruption to avoid trivial inputs; detail the corruption process and ablate corruption type/intensity to measure its impact on decoding robustness and error rates.
- v-prediction vs. x-prediction: the paper reports poor performance for v-pred with shared weights but offers no explanation; perform controlled experiments and theoretical analysis (conditioning leakage, loss geometry, gradient alignment) to understand failure modes.
- Flow path choice: ELF uses rectified (linear) flows; evaluate alternative interpolants (e.g., curved/geodesic paths, stochastic interpolants with different drift/diffusion terms) and schedules to test whether different paths improve quality or few-step sampling.
- Sampler theory and stability: the SDE-inspired sampler injects noise with a heuristic time shift; provide a principled derivation, stability analysis, and hyperparameter guidelines (noise scale, time-shift schedule), and compare against higher-order ODE integrators (RK, Heun).
- Few-step regime limits: quantify the minimum steps at which ELF remains stable and high-quality; compare ODE vs. SDE samplers under extreme compression (e.g., 4–16 steps) and explore distillation or fast-forward training tailored to ELF.
- CFG scheduling: only scalar CFG scales are swept; study step-dependent schedules, conditional-vs-self-conditioning separation, and training-time vs. inference-time CFG hybrids to better manage the quality–diversity trade-off.
- Conditional guidance sources: in conditional generation, CFG mixes self-conditioning and input prefixes; measure how each source contributes (ablate each), and explore alternative conditioning (retrieval context, classifiers, constraints) for controllable text generation.
- Likelihood and evaluation: ELF avoids likelihood-based metrics; investigate tractable or approximate likelihood estimators for flows and evaluate bits-per-token to enable apples-to-apples comparisons with AR and discrete DLMs.
- Human and fine-grained evaluation: add human judgments of fluency, coherence, faithfulness, and toxicity; include targeted metrics (factuality, entity consistency, lexical diversity, repetition) beyond GPT-2 generative perplexity and unigram entropy.
- Long-context and document-level tests: measure performance on tasks requiring >1024 tokens (summarization, story generation, long QA), test memory and coherence over long sequences, and assess scaling of context windows for ELF.
- Multilingual and cross-domain generalization: extend to non-English, morphologically rich languages, code, tables, and multimodal text; examine whether continuous embeddings and final-step discretization handle non-Latin scripts and specialized domains.
- Robustness to OOD inputs: stress-test rare words, noisy text, adversarial prompts, and domain shifts; quantify robustness, failure cases (degenerate repetitions, semantic drift), and recovery strategies (stochastic sampling, guidance tweaks).
- Fair comparison protocol: harmonize training budgets, parameter counts, and data sources across baselines; include wall-clock, energy, and memory metrics for training and inference to substantiate efficiency claims.
- Scaling laws: only three model sizes are shown; derive ELF scaling laws (loss vs. compute/data/params), test larger scales, and analyze diminishing returns and the role of sampler/guidance at scale.
- Decoding alternatives: explore final-step sampling strategies (top-k, nucleus, temperature), beam search over W·xθ(z1), or iterative refinement post t=1 to balance diversity and faithfulness.
- Error attribution along the flow: develop diagnostics (e.g., intermediate decoding probes) to localize where errors arise (early noise regime vs. late refinement) and guide training corrections (curriculum schedules, targeted regularization).
- Safety and bias: assess demographic bias, toxicity, and unsafe outputs; integrate constraints or guided classifiers into training-time CFG to mitigate harmful generations.
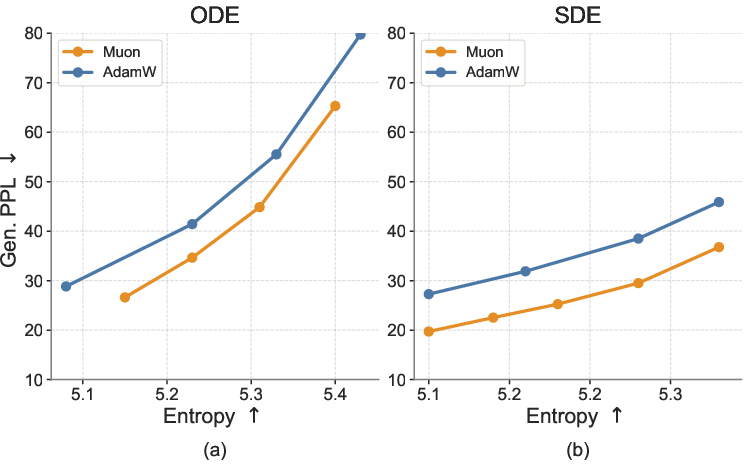
- Training stability and optimization: ablate optimizer choice (Muon vs. Adam variants), learning-rate schedules, gradient clipping, and mode-conditional batching/masking strategies for the two branches to improve convergence and reduce interference.
- EOS and structure modeling: analyze how structural tokens (EOS, PAD) are handled when discretization occurs only at t=1; add structure-aware losses or auxiliary heads if needed to better control termination and formatting.
- Theoretical guarantees for discrete recovery: provide analysis of when continuous embedding denoising plus a single unembedding step constitutes a consistent estimator of discrete token distributions, and what conditions on encoder/unembedding ensure recoverability.
Practical Applications
Immediate Applications
The following applications can be deployed with modest engineering effort using the paper’s released code and findings on efficient sampling, shared-weight decoding, and classifier-free guidance (CFG). Each item notes relevant sectors, potential tools/workflows, and key dependencies.
- Low-latency, controllable text generation for drafting and chat
- Sectors: software, media, customer support, education
- What: Few-step SDE sampling plus a “creativity–precision” CFG knob enables fast generation with a tunable quality–diversity trade-off for chatbots, writing assistants, and copy ideation.
- Tools/workflows: An inference SDK exposing CFG scale and sampler choice; multi-draft generation via CFG sweeps.
- Dependencies/assumptions: Requires CFG tuning per task; safety filters still needed; reported quality measured by Gen PPL/ROUGE/BLEU, not human eval.
- Data-efficient domain adaptation for specialized text models
- Sectors: healthcare, legal, finance, scientific publishing
- What: ELF’s 10× lower training-token usage and shared-weight decoding reduce cost to build domain-specific generators (e.g., discharge-summary writers, contract clause suggestions).
- Tools/workflows: Fine-tuning pipelines using pretrained contextual encoders during training; iterative CFG tuning per domain.
- Dependencies/assumptions: Access to compliant domain corpora; clinical/legal deployment needs thorough human review and governance.
- Machine translation and summarization services
- Sectors: media, enterprise knowledge management, education, government
- What: Validated gains on WMT14 De–En and XSum indicate deployable MT/summarization with step-efficient sampling for near-real-time use.
- Tools/workflows: Sequence-to-sequence setup with clean prefix conditioning and inference-time CFG for quality control.
- Dependencies/assumptions: Generalization beyond tested datasets/languages requires retraining; streaming use cases need latency optimization.
- Batch paraphrasing and data augmentation
- Sectors: ML practitioners (industry/academia), education platforms
- What: Generate diverse paraphrases by sweeping CFG and using the SDE sampler to augment training sets for classifiers, retrieval, and QA systems.
- Tools/workflows: Batch generators producing multiple variants per input; entropy–quality curves for selection.
- Dependencies/assumptions: Label preservation must be validated; human-in-the-loop recommended for high-stakes domains.
- On-prem/offline text generation for privacy-sensitive environments
- Sectors: healthcare, finance, public sector
- What: 105M–650M parameter models, no separate inference-time decoder, and fewer sampling steps enable on-prem deployments for private document processing.
- Tools/workflows: Quantized inference builds; policy-compliant logging and guardrails; server-side SDE sampler for low-latency.
- Dependencies/assumptions: Still non-trivial compute; mobile-class deployment may require aggressive compression; security and safety layers required.
- Research prototyping for continuous-time text generation
- Sectors: academia, R&D labs
- What: Apply mature image-diffusion techniques (training-time CFG, flow solvers) to language via ELF’s continuous embedding formulation.
- Tools/workflows: Modular research code supporting ODE/SDE sampling, self-conditioning, and x-prediction; ablation-ready pipelines.
- Dependencies/assumptions: Familiarity with flow matching; careful evaluation beyond likelihood proxies.
- Interactive multi-draft writing assistants
- Sectors: productivity apps, marketing
- What: Generate several diverse drafts quickly (few-step SDE, varying CFG) and converge to a final version via user selection.
- Tools/workflows: UI sliders for CFG and step count; automatic entropy filtering to diversify suggestions.
- Dependencies/assumptions: UX integration and content safety controls; human preference alignment not addressed in paper.
- Infrastructure cost reductions for diffusion LMs
- Sectors: platform providers, MLOps
- What: Without distillation and with fewer steps, a single shared-weight denoiser/decoder reduces inference memory and simplifies serving.
- Tools/workflows: Unified transformer that switches denoise/decode modes; autoscaling by step budget vs throughput.
- Dependencies/assumptions: Autoregressive baselines may still be cheaper in some settings; requires empirical TCO benchmarking.
Long-Term Applications
These concepts require further research, scaling, or engineering—e.g., compression to on-device sizes, broader multilingual support, or extensions beyond the paper’s scope.
- On-device keyboards and personal assistants
- Sectors: consumer mobile, accessibility
- What: Compact ELF with 8–16 SDE steps for offline suggestions, summarization, and quick replies; CFG as a user-facing creativity control.
- Tools/workflows: Quantization/pruning; distillation-free few-step optimization; energy-aware schedulers.
- Dependencies/assumptions: Strong compression and latency budgets; robust safety; limited memory/compute constraints.
- Low-resource language and underserved-domain models
- Sectors: public policy, education, non-profits
- What: Data-efficient training can lower barriers for localized NLP (translation, summarization) in low-resource languages or domains.
- Tools/workflows: Government/NGO-supported community corpora; multilingual encoders during training.
- Dependencies/assumptions: High-quality datasets needed; fairness and bias audits; availability of pretrained encoders per language.
- Multimodal generative systems via unified flows
- Sectors: media, robotics, creative tools
- What: Leverage flow matching’s cross-domain traction to co-train text with image/video flows for consistent text–vision generation and editing.
- Tools/workflows: Shared continuous latent spaces; training-time CFG conditioned on multimodal inputs.
- Dependencies/assumptions: Large multimodal datasets; architecture and alignment extensions.
- Real-time, controllable live captioning and speech-to-text translation
- Sectors: media, accessibility, conferencing
- What: Streamed generation with CFG to stabilize outputs under latency constraints; partial-sequence conditioning.
- Tools/workflows: Incremental flow solvers; adaptive step schedules tied to latency budgets.
- Dependencies/assumptions: New training for streaming; careful latency–quality trade-offs.
- Regulated-content generation with final-step constraints
- Sectors: policy, compliance-heavy industries
- What: Insert safety/compliance constraints at ELF’s final discretization step (logit constraints, rule-based vetoes) while preserving continuous denoising.
- Tools/workflows: Plug-in safety heads; auditable decoding-time constraint logs.
- Dependencies/assumptions: Robust safety classifiers; minimal quality degradation; accepted standards for auditability.
- Program synthesis and code editing
- Sectors: software engineering, DevOps
- What: Apply continuous flows to code tokens for few-step iterative refinement and multi-draft edits with adjustable CFG.
- Tools/workflows: Syntax/semantics-aware conditioning; unit-test-guided training-time guidance modules.
- Dependencies/assumptions: Training on large code corpora; evaluation for correctness/security; extension beyond text tasks.
- Structured document generation under hard constraints
- Sectors: enterprise reporting, legal, finance
- What: Combine flow-based coherence with constrained decoding at the final step to meet schema, length, or terminology constraints.
- Tools/workflows: Constraint-aware unembedding/decoding; templated conditioning.
- Dependencies/assumptions: Methods to mesh single-step discretization with hard constraints; potential need for hybrid decoders.
- Training-time guidance ecosystems for controllable attributes
- Sectors: research tools, platform providers
- What: Generalize training-time CFG to encode attributes (toxicity, style, length) as guidance signals learned into the flow for single-pass inference.
- Tools/workflows: Attribute-labeled datasets; modular guidance heads; evaluation suites for multi-objective control.
- Dependencies/assumptions: Stability with multiple guidance signals; robustness across domains; clear metrics for control quality.
Glossary
- Absorbing state: A special token/state in discrete diffusion where once entered, it remains unchanged and helps structure the denoising process. Example: "use a special [MASK] absorbing state"
- BLEU: An automatic evaluation metric for machine translation that measures n-gram overlap between generated and reference translations. Example: "evaluate using BLEU"
- Bottleneck design: An architectural choice that projects representations to a lower-dimensional space and then back, often to improve efficiency. Example: "We use a bottleneck design that linearly projects embeddings"
- CFG scale: A scalar that controls the strength of classifier-free guidance, trading off quality and diversity. Example: "across CFG scales"
- Classifier-free guidance (CFG): A guidance method that combines conditional and unconditional model predictions to steer generation without an external classifier. Example: "classifier-free guidance (CFG)"
- Continuous-time Flow Matching: A generative modeling framework that learns a velocity field over continuous time to transform noise into data. Example: "based on continuous-time Flow Matching."
- Cross-entropy (CE) loss: A standard token-level classification loss; here used only at the final discretization step. Example: "token-wise cross-entropy loss"
- D3PMs: Discrete Denoising Diffusion Probabilistic Models; define diffusion over discrete variables via categorical transitions. Example: "D3PMs~\citep{austin2021structured} define general discrete corruption processes"
- DDPM-style formulations: Generative diffusion setups that define forward/backward transitions between states, often with Gaussian noise schedules. Example: "In DDPM-style formulations, generation is defined by transitions between successive states"
- Diffusion LLMs (DLMs): Diffusion-based generative models tailored for text, operating in discrete or continuous spaces. Example: "diffusion LLMs (DLMs)"
- Euler solver: A simple numerical integrator for ODEs used to step the generative flow forward in time. Example: "numerical (e.g., Euler) solver."
- Flow Matching: A technique that learns the velocity field along a path from noise to data for fast, continuous-time generation. Example: "Flow Matching defines a continuous flow path from noise to data in this space."
- Gaussian noise: Standard normal noise used as the starting distribution for diffusion/flow processes. Example: "from Gaussian noise to clean embeddings."
- Generative perplexity: The perplexity of generated text measured under a reference LLM, used to assess generation quality. Example: "lower generative perplexity with fewer sampling steps"
- Guidance scale: The weight in CFG that balances conditional and unconditional predictions to control generation. Example: "and is the guidance scale."
- Latent Diffusion Models (LDM): Diffusion models that operate in a learned latent space rather than pixel/token space. Example: "Following Latent Diffusion Models (LDM)"
- Masked diffusion models: Discrete diffusion setups that use a mask token to iteratively reveal tokens during generation. Example: "Masked diffusion models, such as MDLMs"
- Mean squared error (MSE): A regression loss used here to match predicted clean embeddings or velocities during denoising. Example: "mean squared error (MSE)"
- Ordinary differential equation (ODE): A deterministic continuous-time formulation for the generative trajectory. Example: "We show ODE for simplicity."
- Rectified-flow interpolant: A linear interpolation path used in Flow Matching that simplifies training and sampling. Example: "linear (rectified-flow) interpolant"
- ROUGE: A set of summarization metrics based on n-gram overlap and longest common subsequence. Example: "report ROUGE-1 (R1), ROUGE-2 (R2), and ROUGE-L (R-L)"
- Self-attention: The Transformer mechanism enabling each token to attend to others, used here for conditioning on prefixes. Example: "through self-attention."
- Self-conditioning: Feeding the model’s previous prediction as an additional input condition to stabilize and improve generation. Example: "we employ self-conditioning"
- SDE (stochastic differential equation): A stochastic continuous-time formulation that injects noise at each step during sampling. Example: "SDE sampler is also applicable."
- SDE-inspired sampler: A practical sampler that approximates SDE behavior by injecting small noise per step with time adjustments. Example: "an SDE-inspired sampler."
- Simplex-based representations: Continuous token relaxations that lie on the probability simplex, used to model discrete text. Example: "simplex-based representations"
- Stochasticity (during sampling): The deliberate injection of randomness in the sampler to reduce error accumulation and improve quality. Example: "introducing stochasticity during sampling"
- Time schedule: The sequence of time points used by the sampler to advance from noise to data. Example: "sampling time schedule, from 0 to 1"
- Unembedding: The projection from continuous embeddings back to vocabulary logits for token prediction. Example: "unembedding layer"
- Uniform categorical distribution: A corruption target over tokens where all categories are equally likely. Example: "toward a uniform categorical distribution"
- Unmasking: The iterative process of replacing mask tokens with predicted tokens during discrete diffusion generation. Example: "generate samples through iterative unmasking"
- v-prediction: A parameterization that predicts the flow velocity directly instead of the clean data. Example: "whereas the standard -prediction in Flow Matching does not."
- Velocity field: The vector field defining how latent variables move over time from noise to data. Example: "learn the velocity field along a continuous path"
- x-prediction: A parameterization that predicts the clean data (embeddings) directly, which can be converted to velocity. Example: "The -prediction parameterization is important for ELF."
Collections
Sign up for free to add this paper to one or more collections.