- The paper introduces DFMs that recast flow maps to respect the probability simplex, enabling non-autoregressive text generation.
- It employs simplex-aligned mean denoiser, cross-entropy, and KL losses to train models for rapid, block-parallel decoding.
- Empirical results show substantial speedups and improved generative perplexity on LM1B and OpenWebText benchmarks.
Discrete Flow Maps: Geometrically Consistent Non-Autoregressive Generation for Language Modeling
Motivation and Problem Statement
Discrete Flow Maps (DFMs) target a fundamental constraint in contemporary language modeling: the sequential bottleneck imposed by next-token autoregressive (AR) prediction. While AR models retain impressive scaling properties, generation remains necessarily sequential, incurring linear computational costs for synthesizing long-form text and making real-time applications computationally expensive. Existing acceleration methods such as speculative decoding and multi-token prediction, though effective, are strictly bound by the underlying autoregressive structure.
In contrast, continuous generative models—including diffusion models and flow matching—enable parallel, non-autoregressive generation in continuous domains by transforming noise into data via neural ODEs. Recent advances such as consistency models and flow maps further compress generative trajectories into single or few-step mappings, offering massive speedups. However, these architectures traditionally employ Euclidean objectives (L2 regression), which are ill-suited for discrete data, e.g. language, whose geometry is that of the probability simplex. Cross-entropy and KL divergence are more appropriate, yet conventional flow map parameterizations are not simplex-respecting.
Theoretical Framework
To resolve this geometric mismatch, the paper introduces a systematic recasting of flow map models for discrete data. Rather than parameterizing in terms of unconstrained average velocities, DFMs employ the mean denoiser ψs,t, which resides on the simplex, allowing the entire training objective and operator to be defined through cross-entropy and KL divergence losses. The framework rigorously anchors all flow map identities (semigroup, Lagrangian, and Eulerian) within the simplex geometry, yielding direct mappings from noise to data distributions via neural networks operating exclusively on probability distributions.
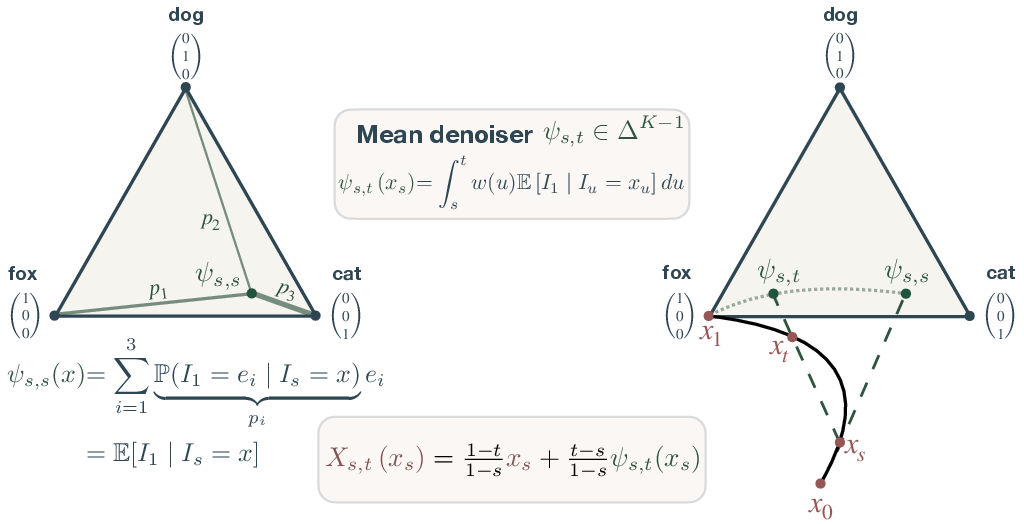
Figure 1: Overview of the geometry of the discrete flow map, showing that both the instantaneous denoiser ψs,s(xs) and the mean denoiser ψs,t(xs) are projections onto the simplex, enabling geometrically consistent flow map parameterization.
Parameterization of the flow map is achieved as a convex combination:
Xs,t(x)=1−s1−tx+1−st−sψs,t(x)
where ψs,t(x) is always in the simplex. The consistency identities governing valid generative trajectories are also reformulated in terms of simplex-valued mappings. Crucially, the diagonal component recovers the standard denoiser, and off-diagonal components enforce trajectory validity via KL distillation with simplex-valued targets.
Algorithmic Contributions
DFMs are instantiated via the following:
Empirical Results
DFMs are extensively evaluated on LM1B and OpenWebText with sequence lengths up to 1024 tokens. Experimental results show:
- Substantial Speedups: DFMs achieve high-quality text generation in one or a few steps, with only minor performance degradation relative to AR decoding.
- Superior Generative Perplexity: Across the few-step regime, DFMs outperform all prior accelerated discrete diffusion, flow map, and distillation baselines on generative perplexity and output diversity.
- Robust Guidance and Block Generation: CFG experiments demonstrate effective fidelity/diversity trade-offs, with guided scales achieving lower perplexity and entropy, analogous to trends observed in image continuous diffusion.
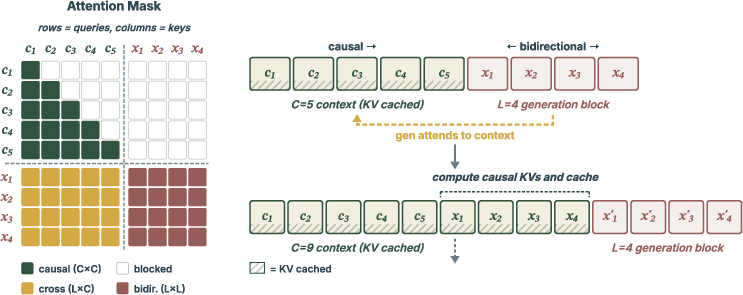
Generations produced by block-wise parallel decoding, supported by KV caching and mixed masking, illustrate qualitatively coherent outputs even at minimal function evaluations.
Practical and Theoretical Implications
DFMs present a formal advance in non-autoregressive discrete sequence generation by aligning model geometry with discrete data through the probability simplex. The approach enables parallel text generation in a rigorously controlled manner, preserving both fidelity (via cross-entropy) and diversity (via entropy maximization). Practically, DFMs unlock scalable synthesis for real-time applications and long-form reasoning, alleviating the inherent disadvantages of AR models.
Theoretically, this simplex-centric reparameterization introduces a principled paradigm for discrete data modeling, extending flow map and diffusion frameworks well beyond their continuous roots. The approach generalizes to arbitrary convex sets, with simplex serving as the canonical example in language. The consistency identities in simplex parameterization could influence a broad class of generative modeling tasks, including conditional generation, controllable synthesis, and combinatorial domains.
Future Directions
Current results suggest that further scaling of DFMs—both in model and data size—could yield competitive or superior performance to the best AR sequence models. Potential developments include:
- Extension to Multimodal and Multilingual Data: Adapting simplex-based flow maps to domains beyond language, e.g., multimodal vision-language synthesis.
- Improved Distillation Schemes: Exploiting the geometric structure of the simplex for more expressive and efficient consistency training.
- Hybrid Autoregressive/Non-Autoregressive Schemes: Combining block-wise DFM decoding with autoregressive prefix extension for adaptive generation.
- Integration with Reinforcement Learning and Control: Using the simplex parameterization to enable precise control mechanisms, test-time steering, and reward-driven guidance.
Conclusion
Discrete Flow Maps systematically resolve the geometric mismatch between continuous flow-based generative models and discrete data, establishing a fully consistent simplex-based framework for non-autoregressive language modeling. The empirical and theoretical contributions position DFMs as a foundational step toward efficient, controlled, and scalable text synthesis. The application of rigorously simplex-aligned training objectives and block-parallel generation mechanisms demonstrates clear superiority in both speed and quality for discrete generative tasks (2604.09784).