PriorVLA: Prior-Preserving Adaptation for Vision-Language-Action Models
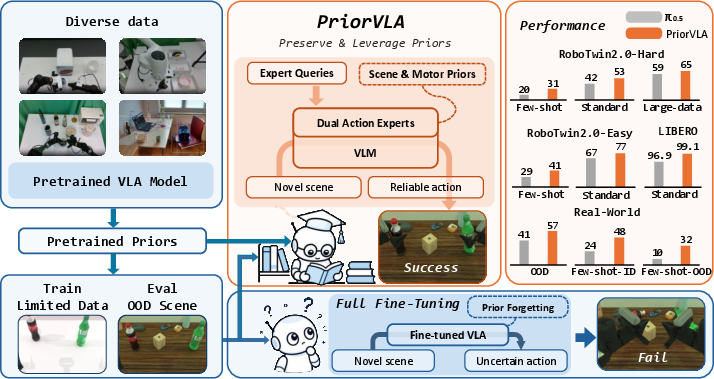
Abstract: Large-scale pretraining has made Vision-Language-Action (VLA) models promising foundations for generalist robot manipulation, yet adapting them to downstream tasks remains necessary. However, the common practice of full fine-tuning treats pretraining as initialization and can shift broad priors toward narrow training-distribution patterns. We propose PriorVLA, a novel framework that preserves pretrained priors and learns to leverage them for effective adaptation. PriorVLA keeps a frozen Prior Expert as a read-only prior source and trains an Adaptation Expert for downstream specialization. Expert Queries capture scene priors from the pretrained VLM and motor priors from the Prior Expert, integrating both into the Adaptation Expert to guide adaptation. Together, PriorVLA updates only 25% of the parameters updated by full fine-tuning. Across RoboTwin 2.0, LIBERO, and real-world tasks, PriorVLA achieves stronger overall performance than full fine-tuning and state-of-the-art VLA baselines, with the largest gains under out-of-distribution (OOD) and few-shot settings. PriorVLA improves over pi0.5 by 11 points on RoboTwin 2.0-Hard and achieves 99.1% average success on LIBERO. Across eight real-world tasks and two embodiments, PriorVLA reaches 81% in-distribution (ID) and 57% OOD success with standard data. With only 10 demonstrations per task, PriorVLA reaches 48% ID and 32% OOD success, surpassing pi0.5 by 24 and 22 points, respectively.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to use what they already know—without forgetting it—when learning new tasks. The authors build on “Vision-Language-Action” (VLA) models, which are AI systems that look at the world (vision), understand instructions (language), and then decide what to do next (action). Their new method, called PriorVLA, helps robots adapt to new tasks while keeping their earlier, broad knowledge intact.
What questions are the researchers asking?
- How can we adapt a big, pretrained robot brain to new tasks without making it forget what it already learned?
- Can we get better results in tricky situations that are different from training (out-of-distribution, or OOD), and when we have only a few examples (few-shot)?
- Is there a way to use the robot’s “old experience” directly during learning, instead of rewriting everything?
How did they do it?
Think of a robot’s brain like a student who has studied a lot. When you teach the student a new topic, you don’t want them to forget the basics. PriorVLA keeps a copy of the student’s old notes and teaches the new topic using those notes as a reference.
Here’s the idea in simple pieces:
Big idea: Keep the old knowledge and use it
- “Pretraining” gives the robot general knowledge about many tasks—like broad experience.
- “Fine-tuning” (the usual method) updates all parts of the brain for a new task, which can cause forgetting and overfitting to the small training set.
- PriorVLA preserves that general knowledge (the “prior”) and teaches the robot to use it while learning the new task.
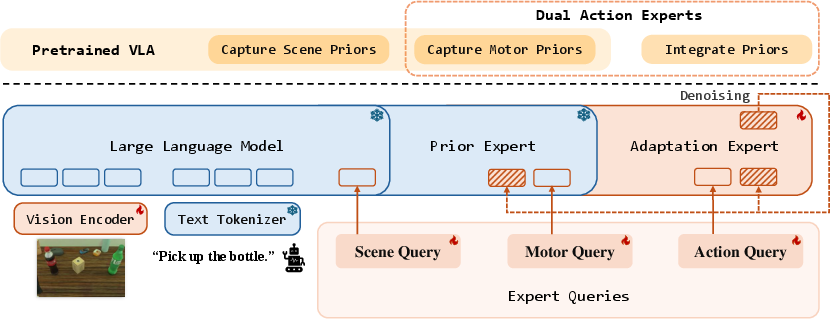
Dual Action Experts: a frozen “teacher” and a trainable “student”
- The model is split into two versions of its action-making part (the part that decides how to move the robot):
- Prior Expert (teacher): a frozen copy that never changes. It holds the robot’s broad, pretrained “motor habits” (how to move in many situations).
- Adaptation Expert (student): a trainable copy that learns the new task.
- The teacher doesn’t directly tell the robot what to do. Instead, it provides helpful hints (internal signals) about good movement patterns learned from lots of past data.
- The student uses those hints to produce the final actions for the new task.
Analogy: Imagine a coach (teacher) standing by with years of experience, and a player (student) practicing new plays. The coach doesn’t play, but shares insights during practice so the player learns the new play without losing fundamentals.
Expert Queries: ask the right questions at the right time
- The model adds special “query tokens”—think of them as smart post-it notes or questions—that pull useful information from different parts of the brain:
- Scene Queries: ask the vision-language part for what’s important to see in the scene (e.g., “Where is the cup?”).
- Motor Queries: ask the frozen teacher for movement know-how (e.g., “How do I usually grasp objects?”).
- Action Queries: combine scene and movement hints inside the student to produce better actions.
- These queries are learned end-to-end, so the model figures out which questions are most useful.
Training in everyday terms
- The robot plans its moves step-by-step, gradually improving from a rough guess to a good action sequence (you can think of this like un-blurring a photo until it’s sharp).
- Only the student’s output is trained and used. The teacher’s output is never used directly—only its internal “hints” are read.
- PriorVLA updates only about 25% as many “knobs” (parameters) as standard full fine-tuning, which helps keep old knowledge stable and reduces the chance of forgetting.
What did they find?
Across simulation and real-world tests, PriorVLA worked better than standard methods, especially when facing new situations or with very little training data:
- RoboTwin 2.0 (simulation, bimanual tasks)
- Out-of-distribution (Hard) setting: improved by 11 percentage points over a strong baseline ().
- In-distribution (Easy) setting: improved by 10 points.
- Works well even with few examples, and keeps advantages as data scales.
- LIBERO (simulation, single-arm tasks)
- Average success: 99.1% across four suites—better than other top VLA models.
- Real-world robots (8 tasks, 2 robot types)
- With standard data: 81% success on seen conditions (ID) and 57% on new conditions (OOD).
- With only 10 demos per task (few-shot): 48% ID and 32% OOD.
- In few-shot, PriorVLA beat the strong baseline by 24 points (ID) and 22 points (OOD).
They also ran careful tests (ablations) showing:
- Keeping the frozen teacher matters. If you remove it, performance drops.
- The query tokens matter. Without them, the student can’t use the teacher’s or scene’s hints effectively.
Why is this important?
- Better generalization: Robots are more reliable in new or changing environments—like different lighting, backgrounds, or object positions.
- Data efficiency: Good performance with very few demonstrations makes training cheaper and faster.
- Stability: Updating fewer parts of the model helps avoid “forgetting” and keeps useful broad skills.
- Practical impact: This can help real robots learn new tasks quickly while staying robust in real homes, labs, or factories.
Limitations and what’s next
- Extra compute: Running both the teacher and the student adds some time during action planning.
- Benchmark coverage: Some simulation results used a subset of tasks; more testing would be helpful.
- OOD factors: Real-world tests changed multiple things at once; future work could separate them to see which matter most.
- Deeper understanding: The paper shows that “priors” help, but there’s more to learn about exactly how these scene and motor hints interact inside the model.
Overall, PriorVLA shows a simple, powerful idea: keep the robot’s broad experience intact and teach it to use that experience when learning something new. This leads to smarter, steadier robots that need less data and handle surprises better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that are missing, uncertain, or left unexplored in the paper, aimed at guiding future research:
- Multi-task scalability: The study trains a separate model per task; it does not evaluate PriorVLA as a single multi-task policy across many tasks (e.g., the full 50-task RoboTwin 2.0 benchmark), leaving open questions about interference, capacity sharing, and stability.
- Continual/online adaptation: The framework is not tested under continual learning or task sequences without resetting, so it is unclear how well preserved priors resist catastrophic forgetting when adapting to many tasks over time.
- When priors hurt: There is no analysis of negative transfer cases where frozen priors conflict with new tasks or affordances; mechanisms to detect and mitigate misleading priors are not explored.
- OOD factor disentanglement: Real-world OOD evaluation perturbs multiple factors jointly; the impact of each factor (lighting, background, object pose, table height) is not isolated or quantified.
- Priors interpretability: The paper lacks probes that quantify what “scene” and “motor” priors contain at different layers/denoising steps and how they influence action tokens (e.g., saliency, mutual information, probing classifiers).
- Sensitivity to query design: The number, placement, dimensionality, and attention masks of Scene/Motor/Action Queries are not systematically ablated; design rules for robust performance are unclear.
- Frozen vs trainable component choices: Only the vision encoder is fine-tuned in the VLM; the consequences of fine-tuning other VLM parts (e.g., text encoder, cross-attention) or different freeze patterns are not evaluated.
- Alternative prior-leveraging strategies: The approach is not compared to other ways of using pretrained priors (e.g., KL regularization to pretrained features, guidance terms during denoising, distillation from the Prior Expert, EMA/teacher-student schemes).
- Compute and latency: Dual experts increase inference cost, but overhead is not quantified (FLOPs, latency per control cycle, memory footprint); it’s unclear if it meets tight real-time constraints or how caching reduces cost.
- Robustness to demo quality: The method’s sensitivity to noisy, sparse, or inconsistent demonstrations is unstudied; robustness to label noise and suboptimal demos remains unclear.
- Action horizon and chunking: Effects of action-chunk length H and denoising schedule on performance/latency/generalization are not explored.
- Cross-embodiment breadth: Real-world tests cover two embodiments; generality across more diverse robot morphologies, end-effectors, and kinematics (e.g., mobile manipulators, dexterous hands) is not assessed.
- Modality coverage: The framework only uses vision, language, and proprioception; integration and benefits of tactile/force feedback or 3D (depth/point clouds) priors are not evaluated.
- Long-horizon and hierarchical tasks: While LIBERO includes “Long” tasks, broader evaluation on complex, multi-stage, or hierarchical plans (with subgoal sequencing and failure recovery) is limited.
- Extreme distribution shifts: OOD tests are moderate; performance under severe shifts (novel objects/categories, camera calibration changes, heavy occlusions, dynamic distractors) is not examined.
- Language robustness: The impact of diverse, ambiguous, or out-of-domain natural language instructions (e.g., paraphrases, multi-step linguistic descriptions) is not studied.
- Partial observability: Robustness under occlusions, limited viewpoints, or missing sensory modalities is not analyzed.
- Training budget parity: Baselines and PriorVLA use fixed training steps (e.g., 30k), but compute/budget parity and the performance–compute trade-off are not thoroughly controlled or reported.
- Parameter-efficiency comparisons: Although updating ~25% of parameters, the method is not compared head-to-head with established parameter-efficient fine-tuning (e.g., LoRA/adapter variants inside AEs and VLMs) under matched budgets.
- Prior Expert variants: Only fully frozen or fully trainable Prior Experts are explored; intermediate variants (e.g., LoRA on select layers, layer-wise freezing, or EMA snapshots) are not studied.
- Cross-pretraining dependence: Sensitivity to the quality/domain of pretraining (e.g., weaker/different pretraining corpora, different VLA families beyond π0.5) is not evaluated.
- Failure analysis: The paper lacks fine-grained error taxonomies (perception vs action vs language grounding failures) to guide targeted improvements.
- Safety and constraint handling: The approach does not consider safety constraints, failure detection, or constraint-satisfying action generation during adaptation and deployment.
- Theoretical grounding: There is no formal characterization of “prior preservation” (e.g., bounds/criteria on representation drift, alignment between Prior and Adaptation Experts), leaving open how to measure and guarantee it.
- Query–prior alignment: How well query features align with task-relevant priors across layers is unknown; learning objectives that explicitly align or gate prior usage are not investigated.
- Online/test-time adaptation: The framework is not assessed for test-time adaptation or rapid on-robot updates, where preserving priors while adapting quickly could be most valuable.
- Fairness of benchmarks: LIBERO is highly saturated; evaluation on newer, harder benchmarks and real-world suites with standardized OOD protocols would better stress-test generalization claims.
Practical Applications
Immediate Applications
The paper introduces PriorVLA, a prior-preserving adaptation framework that improves few-shot and out-of-distribution (OOD) generalization for robot manipulation while updating only ~25% as many parameters as full fine-tuning. Based on the reported real-world results (81% ID and 57% OOD success with standard data; 48% ID and 32% OOD with only 10 demos), the following applications are deployable now:
- Rapid adaptation of factory and warehouse manipulators (Robotics, Manufacturing, Logistics)
- What: Few-shot fine-tuning of generalist robot arms for new SKUs, bins, kitting, palletizing, dual-arm assembly, or packaging changes; robust to lighting/background/layout shifts.
- Tools/Products/Workflows: “PriorVLA Adapter” pipelines that keep a frozen prior expert and train only the adaptation expert + query tokens; SKU onboarding workflows using 10–100 demonstrations per task; rollback-friendly parameter-efficient updates.
- Assumptions/Dependencies: Access to a strong pretrained VLA backbone (e.g., π0.5); flow-matching/chunked-control support; sufficient on-robot or edge compute to run both Prior and Adaptation Experts; high-quality demonstrations.
- Field and facility service tasks (Robotics, Field Service, Energy/Utilities)
- What: Adapting robots for door/valve operation, panel toggling, routine inspections, and simple maintenance under varying lighting and background clutter.
- Tools/Products/Workflows: On-site few-shot adaptation sessions; OOD robustness checks using PriorVLA; priors caching for low-latency inference in the field.
- Assumptions/Dependencies: Safe-force limits and compliance; demonstration data reflecting site-specific tolerances; latency managed via caching or hardware acceleration.
- Retail backroom and micro-fulfillment automation (Robotics, Retail)
- What: Rapidly adapting generalist manipulation to new product packaging, shelf configurations, and seasonal layouts with minimal data collection.
- Tools/Products/Workflows: Data-collection stations that capture 10–50 demos; PriorVLA fine-tune jobs integrated with WMS; A/B testing of Adaptation Expert updates.
- Assumptions/Dependencies: Pretrained priors covering typical retail objects; clear demonstration protocols; compute budget for dual-expert inference.
- Home and office assistance robots (Robotics, Consumer, Facilities)
- What: User-guided few-shot teaching for tidying, placing objects, organizing desks, or kitchen tasks with robust performance under household variability.
- Tools/Products/Workflows: “Teach-by-demonstration” apps that record short demo clips; on-device parameter-efficient updates; safety gates using prior-preserved behavior.
- Assumptions/Dependencies: Non-safety-critical applications; device security for on-device learning; fallback to prior behavior if adaptation fails.
- Hospital logistics and non-critical support (Robotics, Healthcare Operations)
- What: Adapting to new carts, trays, storage placements, and ward layouts without extensive data recollection; robust to shift changes (lighting, clutter).
- Tools/Products/Workflows: Centralized Prior Expert maintained by hospital IT; ward-level adaptation modules; change-management workflows with audit trails.
- Assumptions/Dependencies: Excludes surgical or high-risk tasks; compliance with hospital safety policies; privacy-compliant demo capture.
- Simulation-to-real transfer with minimal real demonstrations (Robotics R&D, Integration)
- What: Use simulation (e.g., RoboTwin 2.0) with strong domain randomization, then apply PriorVLA to bridge to real robots with 10–50 real demos per task.
- Tools/Products/Workflows: Sim pipelines that produce robust priors; quick on-site adaptation; standardized OOD checks (light/background/position/table height).
- Assumptions/Dependencies: Sim assets that reasonably match deployment hardware; careful selection of demo conditions; monitoring for sim-to-real gaps.
- Robotics MLOps for parameter-efficient updates (Software/DevOps for Robotics)
- What: Safer deployment via updates to only ~25% of parameters; easier rollback and versioning; separation of priors from specialization for debugging.
- Tools/Products/Workflows: Weight management systems that store frozen Prior Experts and track Adaptation Expert/Query token deltas; CI pipelines with OOD metrics.
- Assumptions/Dependencies: Robust telemetry; dataset/version governance; reproducible training on π0.5 or similar models.
- Integrator services and customization (Professional Services, Systems Integration)
- What: Offer rapid customization of generalist VLA policies for client sites using PriorVLA, reducing onsite data collection and time-to-value.
- Tools/Products/Workflows: Fixed-price packages for 10–100 demos per task; standard safety checklist; per-task model delivery with documentation of OOD performance.
- Assumptions/Dependencies: Access to pretrained priors relevant to client domain; clear task definitions; uptime SLAs aligned with compute overheads.
- Academic teaching and benchmarking (Academia, Education)
- What: Use PriorVLA to teach concepts of knowledge retention, catastrophic forgetting, and OOD generalization; reproduce ablations on Query designs.
- Tools/Products/Workflows: Course labs using LIBERO/RoboTwin tasks; assignments on prior-preserving design and parameter-efficient fine-tuning.
- Assumptions/Dependencies: Availability of open datasets/backbones; GPU time for dual-expert forward passes.
- Public-sector pilots with minimal data requirements (Policy, Public Services)
- What: Pilot robots in municipal facilities (e.g., libraries, offices) where data collection is constrained; minimize new data via prior-preserving methods.
- Tools/Products/Workflows: Procurement language that prefers parameter-efficient, prior-preserving adaptation; OOD robustness as an evaluation criterion.
- Assumptions/Dependencies: Non-critical tasks; clear acceptance testing on OOD conditions; privacy-aware demo collection guidelines.
Long-Term Applications
These concepts build on the paper’s mechanisms (Dual Action Experts + Expert Queries) but require further research, scaling, or engineering to reach reliable deployment:
- Cross-embodiment, multi-robot generalist manipulation platforms (Robotics, Cloud Robotics)
- What: Fleet-wide shared Prior Experts with per-site Adaptation Experts; cross-robot reuse of priors to cut data and training costs.
- Tools/Products/Workflows: “Prior servers” hosted in the cloud; device-level adaptation modules synchronized over the air; fleet-wide OOD dashboards.
- Assumptions/Dependencies: Robust cross-embodiment priors; secure update channels; scheduling/caching to meet latency budgets.
- Continual learning with minimal forgetting (Robotics, ML Research)
- What: Lifelong accumulation of tasks by adding/refreshing query tokens and adaptation modules while keeping priors intact.
- Tools/Products/Workflows: Task-conditional query banks; automated capability regression tests; selective freezing/unfreezing policies.
- Assumptions/Dependencies: Methods to prevent interference across many tasks; scalable query management; memory constraints.
- Safety-critical manipulation with certifiable behavior (Healthcare, Advanced Manufacturing)
- What: Extend prior-preserving adaptation with formally verified safety envelopes and fail-safes for high-stakes tasks (e.g., assistive manipulation, sterile workflows).
- Tools/Products/Workflows: Verified controllers wrapped around PriorVLA policies; runtime monitors; formal hazard analyses integrated with adaptation logs.
- Assumptions/Dependencies: Regulatory approvals; formal verification methods compatible with learned policies; extensive validation datasets.
- Standardized “Expert Query Interface” across vendors (Interoperability Standards, Policy)
- What: An industry standard for scene/motor/action query tokens and attention masks to make priors portable between models and tools.
- Tools/Products/Workflows: Open API specs; compliance test suites; reference implementations.
- Assumptions/Dependencies: Multi-stakeholder consensus; IP/licensing alignment for pretrained priors.
- Hardware acceleration for dual-expert inference (Semiconductors, Robotics Hardware)
- What: Onboard accelerators that cache frozen prior key/value states and efficiently route query attention to reduce latency and energy.
- Tools/Products/Workflows: KV-cache controllers; compilers that fuse prior and adaptation paths; mixed-precision scheduling.
- Assumptions/Dependencies: Stable model architectures; hardware–software co-design; real-time OS support.
- Integration with synthetic data and auto-demo pipelines (Simulation, Data Engineering)
- What: Combine large-scale synthetic data (e.g., RoboTwin/MimicGen) for priors with minimal real demos via PriorVLA for rapid deployment in new domains (agriculture, energy).
- Tools/Products/Workflows: Domain randomization recipes targeted at prior formation; active selection of 10–20 high-value real demos for adaptation.
- Assumptions/Dependencies: Realistic simulators and assets; robust sim-to-real calibration; automated data QA.
- Extension beyond physical robotics to digital agents (Software Automation, Enterprise Productivity)
- What: Apply the prior-preserving principle to vision-language-action agents operating GUIs/web apps, preserving broad priors while specializing to enterprise workflows.
- Tools/Products/Workflows: Frozen Prior Experts trained on generic GUI knowledge; per-customer adaptation modules; query tokens for app-specific affordances.
- Assumptions/Dependencies: Suitable pretrained VLM-action backbones for digital domains; safety/IT policies for in-product learning.
- Model marketplaces for sector-specific priors (Ecosystem, Commercialization)
- What: Vendors publish high-quality Prior Experts for domains (retail, manufacturing, healthcare logistics); customers buy lightweight Adaptation Expert packages.
- Tools/Products/Workflows: Licensing frameworks; secure distribution; telemetry for performance warranties.
- Assumptions/Dependencies: Clear IP boundaries around priors; standard evaluation contracts; privacy-preserving adaptation.
- Advanced policy and governance frameworks (Policy, Compliance)
- What: Guidelines emphasizing OOD testing, minimal-data adaptation, and prior preservation to reduce data collection burdens and safety risks.
- Tools/Products/Workflows: Audit trails for adaptation steps; mandated OOD benchmarks; red-team protocols for priors misuse.
- Assumptions/Dependencies: Regulatory bodies adopt technical metrics; sector-specific risk profiles; harmonization across jurisdictions.
Cross-cutting Assumptions/Dependencies
- Strong pretrained VLA backbones are available and relevant to the target domain; benefits shrink if priors are weak or mismatched.
- The current method is tied to flow-matching action experts and chunked-control denoising; other action models may need adaptation.
- Dual-expert inference adds compute/latency; caching or hardware acceleration may be required for tight real-time loops.
- Reported gains are demonstrated on specific tasks and two embodiments; performance in new domains depends on demo quality and domain similarity.
- The paper’s current scope trains one model per task; multi-task packaging and routing remain open engineering work for large deployments.
Glossary
- Action chunk: A contiguous sequence of future control actions predicted by the policy for execution. "predicts a future action chunk for robot manipulation."
- Action Expert (AE): The action-generation module of a VLA policy, often instantiated with flow matching. "a flow-matching-based action expert (AE)"
- Action horizon: The length of the predicted action chunk, often denoted by H. "where denotes the action horizon."
- Action Queries: Learnable tokens inside the Adaptation Expert that integrate scene and motor priors to guide action generation. "Action Queries integrate these priors inside the Adaptation Expert to guide action generation."
- Adaptation Expert: The trainable action expert specialized to downstream tasks while leveraging preserved priors. "trains an Adaptation Expert for downstream specialization."
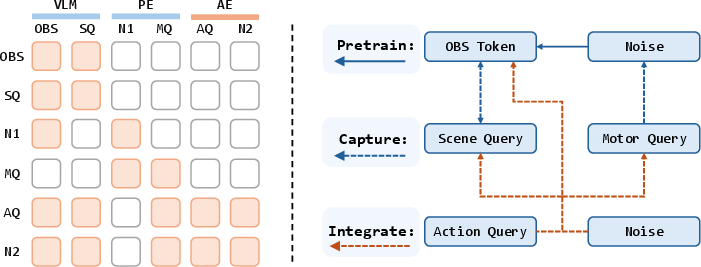
- Attention mask: A structured mask that controls which token groups can attend to which others in attention layers. "Attention mask over token groups in the VLM, Prior Expert (PE), and Adaptation Expert (AE)."
- Bimanual manipulation: Robotic manipulation involving two arms or manipulators. "RoboTwin 2.0 evaluates bimanual manipulation under Easy (ID) and Hard (OOD) modes;"
- Bridge attention: An interface technique that connects vision-language representations to action policies via attention pathways. "query-style tokens or bridge attention"
- Chunked-control: A control paradigm where actions are generated and executed in chunks rather than single-step commands. "this overhead is manageable in our chunked-control setting,"
- Continual-learning regularization and replay: Techniques to preserve previously learned capabilities while adapting to new tasks. "continual-learning regularization and replay"
- Denoising: The iterative process (in flow/diffusion-style models) of refining noisy actions into clean action predictions. "During denoising, both experts are executed along the same noisy action trajectory."
- Denoising dynamics: The internal transformation behavior of the action expert throughout the denoising process, encoding motor regularities. "A pretrained AE contains reusable motor priors encoded in its denoising dynamics,"
- Denoising step: A single iteration within the denoising process. "At denoising step , they receive the same noisy action chunk"
- Downstream adaptation: The process of adapting a pretrained model to specific target tasks or datasets. "In practice, downstream adaptation is commonly performed via full fine-tuning,"
- Dual Action Experts (DAE): The architectural design with a frozen Prior Expert and a trainable Adaptation Expert to separate prior preservation from specialization. "Dual Action Experts (DAE) and Expert Queries (EQ)."
- Embodied reasoning: Reasoning that integrates perception, language, and action within a physical or simulated embodiment. "embodied reasoning"
- Embodiments: Different robot bodies or platforms on which a policy is deployed. "generating actions across tasks and embodiments"
- Expert Queries (EQ): Learnable token interfaces (Scene, Motor, Action) that capture and transmit priors between preserved and adapting components. "Dual Action Experts (DAE) and Expert Queries (EQ)."
- Few-shot: A training regime with very limited demonstrations per task. "few-shot training uses only 10 demonstrations per task."
- Flow matching: A generative modeling technique used to learn a mapping from noise to data, here for action generation. "flow-matching-based action expert (AE)"
- Flow-matching update: The specific update step applied to the noisy action using the flow model’s prediction. " denotes the flow-matching update."
- Forward pass: The computation through network layers during inference/training; here, where priors emerge and can be preserved. "emerge in the pretrained model's forward pass."
- Full fine-tuning: Updating all model parameters on downstream data, often risking over-specialization. "full fine-tuning treats the pretrained model mainly as an initialization"
- In-distribution (ID): Evaluation conditions matching the training distribution. "in-distribution (ID) performance"
- Key-value caches: Stored attention key-value states across layers that facilitate efficient cross-module information access. "layer-wise key-value caches"
- Low-rank updates: Parameter-efficient fine-tuning technique that restricts updates to low-rank subspaces. "reducing trainable parameters with low-rank updates"
- Masked attention: Attention computed under a masking scheme that restricts token-to-token information flow. "We implement these interfaces through masked attention over token groups."
- Mean-squared error (MSE): A standard regression loss used here as the flow-matching training objective. "flow-matching mean-squared error (MSE) objective"
- Motor priors: Pretrained regularities in action generation dynamics that help produce reliable motor commands. "Motor Queries capture motor priors from the Prior Expert"
- Noisy action chunk: A noise-corrupted version of the action chunk used as input during denoising. "conditions on a noisy action chunk"
- Out-of-distribution (OOD): Evaluation conditions that differ from the training distribution. "out-of-distribution (OOD) generalization"
- Prior Expert: The frozen copy of the pretrained action expert whose internal representations provide preserved motor priors. "keeps a frozen Prior Expert as a read-only prior source"
- Prior-preserving adaptation: An adaptation principle that retains and leverages pretrained priors rather than overwriting them. "a prior-preserving adaptation framework"
- Proprioceptive state: Internal robot state measurements (e.g., joint positions/velocities) used as model inputs. "and proprioceptive state "
- Query-style tokens: Learnable tokens used as interfaces to query and integrate information via attention. "query-style tokens"
- Scene priors: Pretrained knowledge about visual structure and task-relevant cues in the environment. "Scene Queries capture task-relevant scene priors from the VLM"
- Scene Queries: Learnable tokens attached to the VLM that extract scene priors for use by the action policy. "Scene Queries capture task-relevant scene priors from the VLM"
- Self-attention: The attention mechanism where tokens attend to one another within the same sequence. "They participate in VLM self-attention"
- Vision-LLM (VLM): The module that processes visual observations and language instructions to produce multimodal features. "a vision-LLM (VLM)"
- Vision-Language-Action (VLA) models: Models that map visual observations and language instructions to robot actions. "Vision-Language-Action (VLA) models have emerged as promising foundations for generalist robot manipulation"
Collections
Sign up for free to add this paper to one or more collections.

