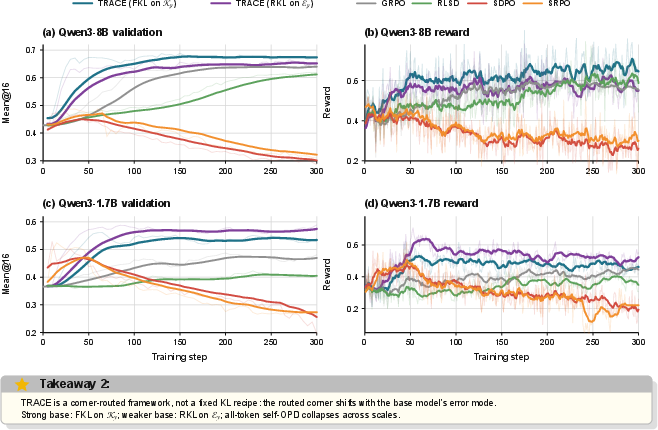
- The paper introduces TRACE, which selectively applies KL divergence to key token spans to mitigate gradient waste and stabilize long-horizon RL.
- TRACE reduces issues like entropy explosion and response truncation by routing supervision based on diagnostic token spans, improving benchmark performance.
- Empirical and theoretical analyses confirm that targeted, span-localized distillation is more effective than all-token methods in reinforcement learning for mathematical reasoning.
Targeted Token-Level Routing for On-Policy Self-Distillation: An Analysis of TRACE
Introduction
The paper "TRACE: Distilling Where It Matters via Token-Routed Self On-Policy Alignment" (2605.10194) addresses a central bottleneck in reinforcement learning with verifiable rewards (RLVR) for reasoning-focused LLMs: achieving stable and effective credit assignment in the presence of sparse, trajectory-level supervision. The core contribution is the TRACE algorithm, which implements a token-routed self on-policy distillation (self-OPD) paradigm that localizes the knowledge distillation signal to critical spans within model-generated trajectories, leveraging privileged annotation to mask out redundant or deleterious supervision. This approach directly responds to empirical instabilities and theoretical failure modes present in established all-token self-OPD methods, notably controlling entropy explosion, premature response truncation, and out-of-distribution (OOD) degradation in long-horizon mathematical reasoning domains.
Failure Modes in All-Token Self-OPD
Unlike classic supervised fine-tuning, RLVR methods such as GRPO provide only trajectory-level advantage signals, motivating the usage of on-policy distillation to densify the training signal via token-level teacher guidance. Early self-OPD methods (e.g., SDPO, SRPO) inherit the configuration where KL divergence is applied to every token in sampled rollouts. The authors provide rigorous empirical analysis and theoretical diagnosis revealing that such "all-token" distillation introduces a uniform "distillation tax": the majority of the KL gradient is wasted on positions already well-aligned between student and teacher, while it also amplifies privileged information leakage due to the teacher's access to additional context. This combination leads to a characteristic three-symptom collapse:
- A precipitous rise in per-token actor entropy (up to 4× baseline),
- Shortening of response lengths by over 50%,
- Abrupt drops in validation accuracy following early training peaks.
These phenomena are visually summarized in the training dynamics shown in Figure 1 and are representative of a deeper granularity mismatch—the correct locus of supervision is not the entire response, but the discriminative spans where the student still deviates from optimal behavior.
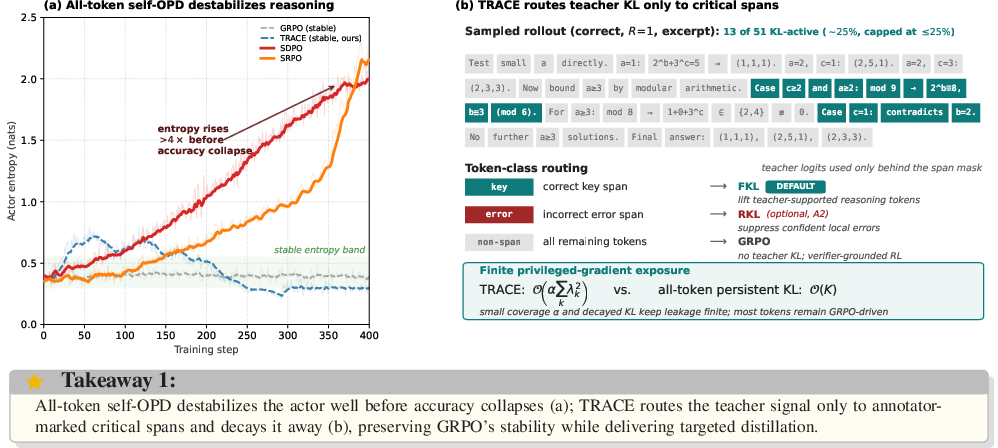
Figure 1: TRACE maintains stable per-token actor entropy relative to baselines (SDPO, SRPO), avoiding collapse symptoms by restricting KL to critical spans.
TRACE Algorithm: Span-Localized, Action-Routed Distillation
TRACE implements a three-way decomposition of tokens in each rollout: key spans (teacher-supported, critical for correct solutions), error spans (high-confidence student mistakes), and non-span (routine, already-aligned tokens). A privileged annotator—either an external LLM (e.g., Qwen3.5+) or the student itself (for online self-annotation)—is tasked with marking these spans and labeling their coarse diagnostic type while withholding exact span content. The teacher is prompted only with the coarse type (not explicit content), ensuring minimal privileged leakage.
Based on span type, TRACE discretely routes the KL divergence action: forward KL (FKL) is applied to key spans, reverse KL (RKL) can be optionally applied to error spans, and non-span tokens proceed under standard GRPO without auxiliary KL. Importantly, the KL channel is decayed to zero after a warm-up phase, bounding the cumulative privileged-gradient exposure.
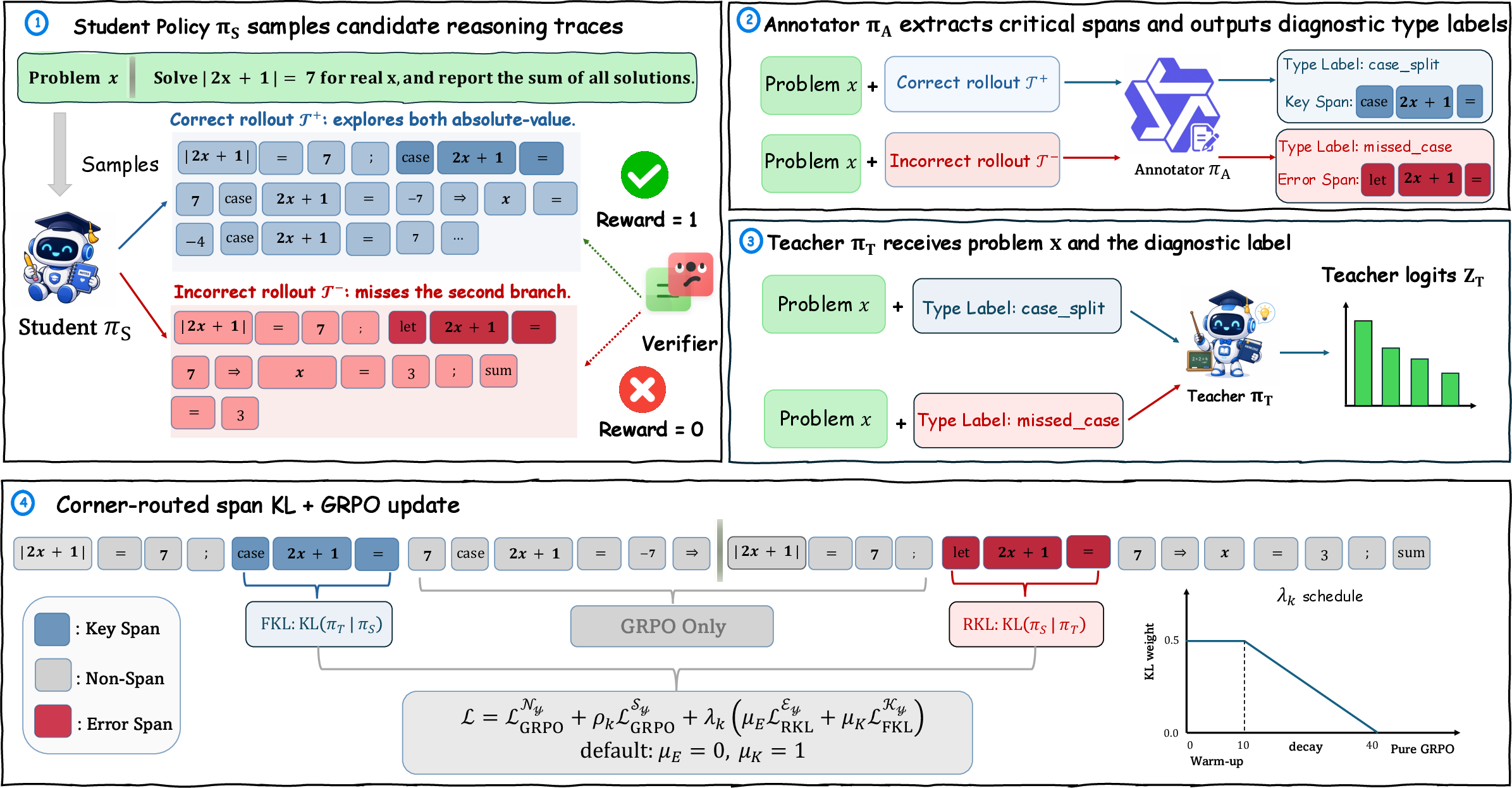
Figure 2: The TRACE pipeline employs annotation-based span masking, type-label diagnostic prefixes, and routed KL actions, with coverage capping and KL decay mechanisms.
This architecture is theoretically justified:
- FKL on key spans provides non-vanishing corrective signal for tokens where the teacher assigns high probability and the student under-allocates.
- RKL on error spans targets overconfident student errors where the teacher assigns low probability.
- Span masking and aggressive KL decay enforce that total privileged-gradient exposure remains finite, preventing training drifts associated with persistent privileged information channels.
Empirical Results: Stability, Transfer, and Annotator Robustness
TRACE is evaluated on RLVR math domains using Qwen3-8B and Qwen3-1.7B, with comparisons to GRPO, all-token SDPO/SRPO, and RLSD. Key findings include:
Ablation studies reinforce that not only span localization but also the diagnostic targeting of spans is critical. All-token or random-sparse KL routings fail to recover TRACE's advantage. Improvements are concentrated on the annotated spans (high credit concentration), which produce a stepwise logit probability lift in the direction predicted by the theoretical analysis.
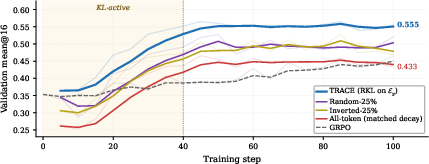

Figure 4: LOCKS ablation showing validation performance under RKL on error spans: token selection, not sparsity alone, is crucial for effective guidance.
Theoretical Foundations and Mechanisms
TRACE’s routed action space is underpinned by:
- Formal identities contrasting the per-token gradients of FKL and RKL, showing FKL is mass-independent in the under-allocation regime (key spans), while RKL is advantageous in the confident-wrong regime (error spans).
- A cumulative privileged-gradient exposure bound: with mask coverage α and KL decay, total exposure is O(αΛ2) and does not scale with training horizon.
- An alignment signal lower bound: if the span annotator exceeds a precision threshold, KL applied to selected spans is provably correlated with the unobservable verifier-gradient direction.
These concepts are captured in the idealized geometry illustrated below.
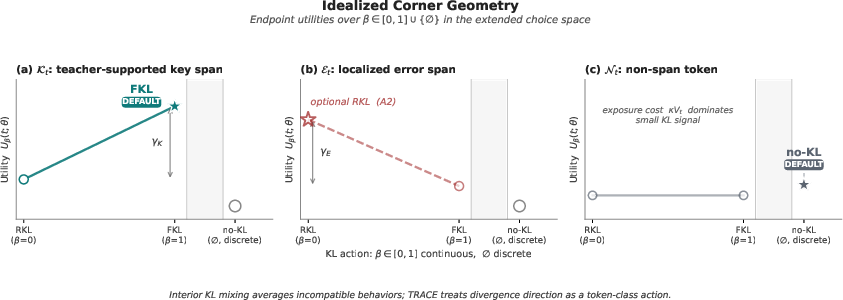
Figure 5: Idealized geometry for the routed KL choice space highlights when FKL, RKL, or null action are optimal, conditioned on span/error classes and risk.
Practical and Theoretical Implications
TRACE provides a coherent principle for self-distillation in the presence of privileged information: supervision should be routed only to tokens where the teacher possesses meaningful corrective signal, using discrete divergence direction per span class, and must be constrained temporally and in coverage. This approach resolves the fragility in long-horizon reasoning tasks and suggests that future advances in RLVR training for LLMs should incorporate fine-grained, targeted intervention rather than uniform, dense teacher forcing.
Further, the result that online self-annotation recovers most of the external-annotator gain signals that continual learning scenarios with no external teacher remain viable. The theoretical machinery (privileged-gradient risk, utility tradeoffs) is general and can be deployed in other domains sensitive to exposure and leakage.
Speculation and Future Directions
Sterile all-token KL paradigms are shown to be fundamentally ill-posed under privileged supervision due to uniform gradient wasting and information leakage. TRACE’s granularity-aware routing opens pathways to:
- More nuanced advantage shaping in RLHF settings, where token-level human feedback could be substituted for automatic privileged annotations.
- Extensions to multi-task scenarios with diverse diagnostic labeling and richer conditional structure, combining trace localization, rationale generation, and multi-agent feedback.
- Direct application in domains where OOD stability is critical, leveraging the established theoretical bounds on privileged-gradient exposure.
Conclusion
TRACE operationalizes a targeted, risk-controlled framework for self on-policy distillation, leveraging explicit annotation and informed KL routing to robustly enhance sequential reasoning capabilities without sacrificing OOD robustness. The work exposes crucial limitations in prior dense-distillation protocols, offering a scalable recipe aligning theoretical, empirical, and practical considerations in advanced LLM training.
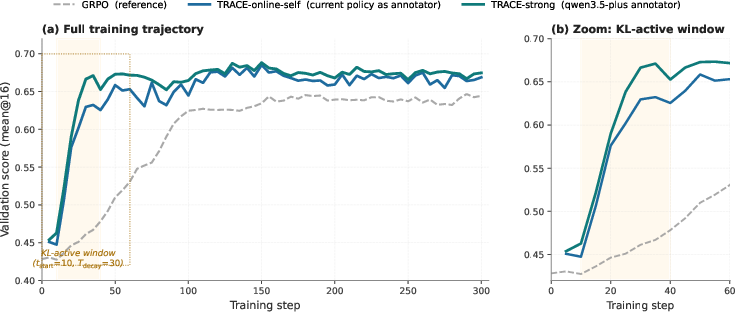
Figure 6: Annotator ablation: validation dynamics for varying annotator strengths show that even online self-annotation (current policy) recovers most of TRACE's benefit, while permanent external annotators yield only marginal extra gain.
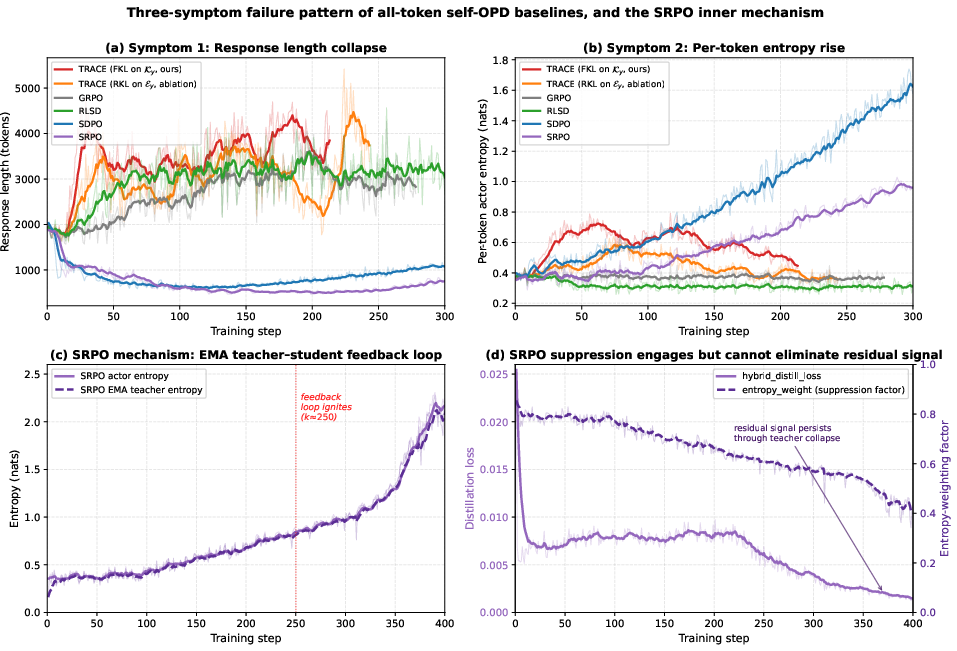
Figure 7: All-token self-OPD baselines exhibit a consistent pattern of response length collapse and entropy explosion; TRACE remains stable across training.