Synthetic Pre-Pre-Training Improves Language Model Robustness to Noisy Pre-Training Data
Abstract: LLMs rely on web-scale corpora for pre-training. The noise inherent in these datasets tends to obscure meaningful patterns and ultimately degrade model performance. Data curation mitigates but cannot eliminate such noise, so pre-training corpora remain noisy in practice. We therefore study whether a lightweight pre-pre-training (PPT) stage based on synthetic data with learnable temporal structure helps resist noisy data during the pre-training (PT) stage. Across various corruption settings, our method consistently improves robustness to noise during PT, with larger relative gains at higher noise levels. For a 1B-parameter model, a synthetic PPT stage with only 65M tokens achieves the same final loss as the baseline while using up to 49\% fewer natural-text PT tokens across different noise levels. Mechanistic analyses suggest PPT does not immediately suppress attention to noisy tokens. Rather, PPT-initialized models gradually downweight attention between corrupted tokens during noisy PT. This indicates that synthetic PPT inhibits noise self-modeling and shapes the subsequent optimization trajectory. Code is available at https://github.com/guox18/formal-language-prepretraining.
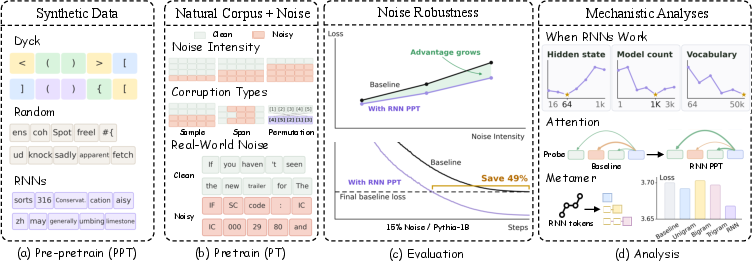
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Synthetic Pre-Pre-Training Improves LLM Robustness to Noisy Pre-Training Data”
1) What is this paper about?
This paper looks at a common problem when training LLMs: the text they learn from is often messy. Real web data contains lots of “noise” like boilerplate, repeated text, random symbols, or poorly formatted pages. That noise makes training less effective.
The authors suggest a simple warm-up step, done before the usual training, that teaches the model to notice general patterns in sequences. This short warm-up uses made-up (synthetic) data with structure, not real text. They show this helps the model handle noisy data better later on.
2) What questions are the researchers asking?
In simple terms, they ask:
- Can a quick warm-up on synthetic, pattern-rich sequences make a LLM tougher against noise in its real training data?
- Which kind of warm-up data works best?
- How and when does this warm-up actually help during training?
3) How did they do it? (Methods in everyday language)
Think of training an LLM like teaching someone to read by giving them billions of sentences from the internet. Some of those sentences are excellent; many are junk. The paper tries a two-step approach:
- Step 1: A short practice stage (they call it “pre-pre-training” or PPT). Instead of using real text, the model reads sequences created by many tiny generators that produce patterns over time. You can think of each generator like a simple “music box” that plays a repeating but learnable tune using the full set of tokens (words/subwords). These generators are small recurrent neural networks (RNNs) with random settings. Even though their outputs look like nonsense words, they contain consistent, learnable timing and ordering patterns.
- Step 2: The usual big training on real text (called pre-training or PT), but with different amounts and types of added noise so they can test robustness. They use common datasets (C4 and FineWeb).
To make the idea clear:
- “Synthetic” means the sequences are made by a program, not written by people.
- “RNN” here is just a simple pattern-maker that remembers what came before and produces the next token in a structured way.
- “Noise” means unhelpful or scrambled text. The authors test several kinds:
- Replacing whole training examples with random tokens.
- Shuffling tokens inside a sentence.
- Corrupting spans (chunks) of text.
- They measure how good the model gets with a score that goes down when the model predicts the next word better (lower is better).
They compare three warm-up choices:
- No warm-up (baseline).
- Random tokens (no structure at all).
- A formal bracket pattern (called “Dyck,” a classic balanced-brackets sequence).
- Their method: many small random RNN generators (patterned but broad and varied).
They test at a smaller model size (160 million parameters) and a larger one (1 billion parameters).
4) What did they find, and why is it important?
Main takeaways:
- The RNN warm-up consistently made models more resistant to noisy data. As the training data got noisier, the advantage got bigger.
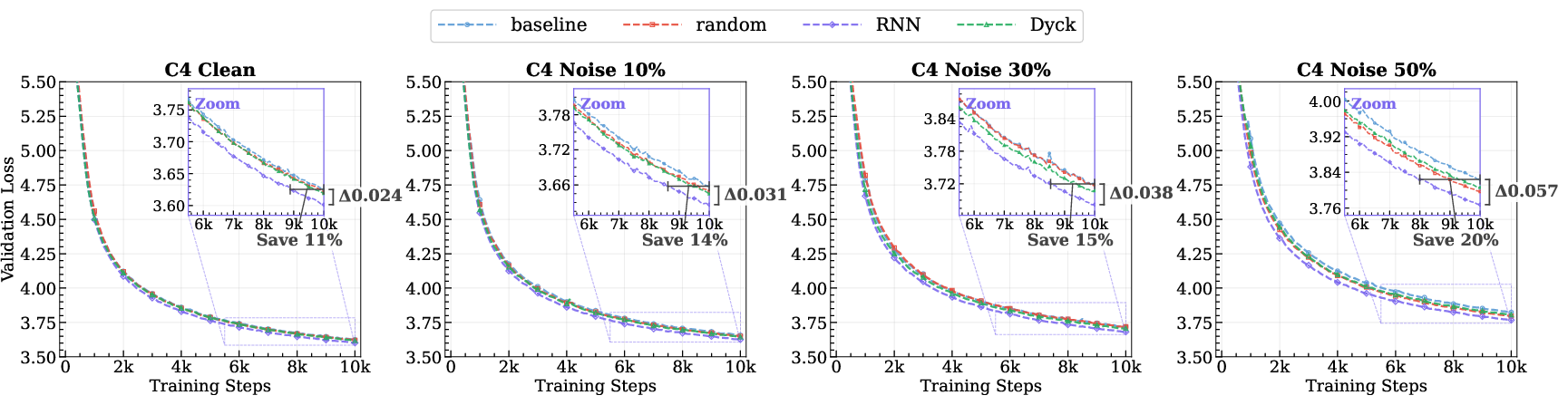
- With a 1B-parameter model, a very short warm-up (about 65 million tokens) let the model reach the same performance while needing up to about 49% fewer real-text training tokens afterward. That’s a big savings in time and cost.
- The bracket-pattern warm-up helped a bit, but not as much. A random-token warm-up didn’t help, showing that structure matters.
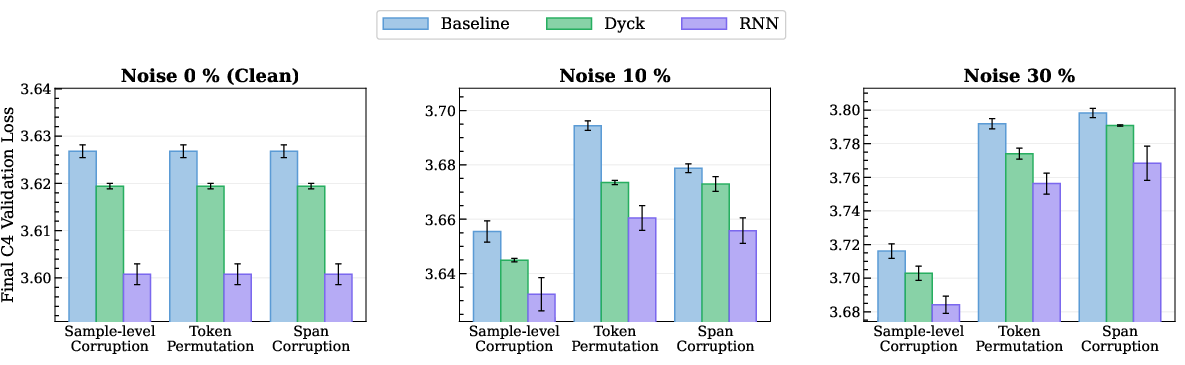
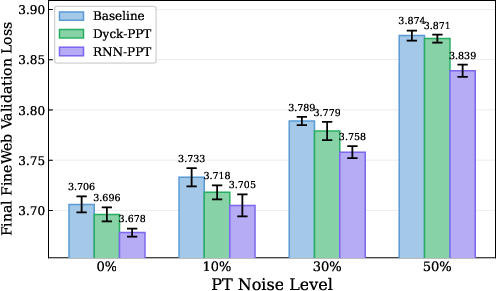
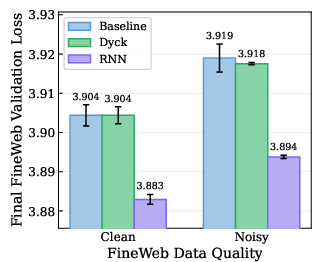
- This worked across different kinds of noise (entire examples replaced, token shuffles, span corruption) and on a second dataset (FineWeb), including naturally messy web text. The gains were strongest on the noisier parts of the data.
- Design details matter. The warm-up works best when:
- The RNN generators are not too complex, so the model can actually learn their patterns.
- There are many different generators (so the warm-up isn’t biased toward one narrow pattern).
- They use a broad vocabulary (not a tiny set of tokens).
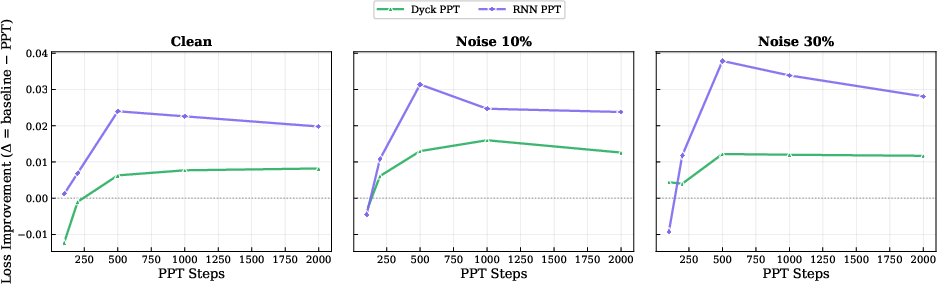
- Why does it help? The authors dug into the model’s “attention” (how it focuses on earlier words). Models trained from scratch tended to start “modeling the noise,” meaning they learned to use junk tokens to predict other junk. After the RNN warm-up, models were guided during training to stop linking noisy parts together. Interestingly, this benefit doesn’t appear instantly; it shows up during the main training stage as the model learns, step by step, to ignore the junk connections.
5) Why does this matter? (Implications)
- Training LLMs is expensive, and cleaning huge web datasets perfectly is impossible. This warm-up offers a cheap, practical way to make models more stable and efficient even when the data is messy.
- It complements data cleaning: you can still clean your data, but this method makes the model itself more tolerant to whatever noise remains.
- It can reduce the amount of “good” data you need to reach a target quality, saving time and compute.
- The idea is simple and flexible: short, structured synthetic practice before the “real game” of large-scale training. Future work could explore other pattern generators (like different sequence models), bigger model scales, and quick tests to predict which synthetic sources will work best.
In short: a small dose of structured, synthetic practice helps LLMs learn to ignore junk later, making training faster, cheaper, and more reliable on real-world web text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scaling to larger models and longer training: Robustness is only shown up to 1B parameters and 25K PT steps; it is unknown how gains behave for larger LLMs (e.g., 7B–70B), longer PT budgets, and different optimizer schedules at scale.
- Downstream generalization breadth: Aside from validation loss and a brief LAMBADA check, the impact on broader downstream suites (e.g., MMLU, BIG-bench, reasoning, QA, code, dialogue, tool use) remains untested.
- Persistence through later stages: Whether PPT-induced robustness persists or interacts with post-PT stages (SFT, DPO/RLHF, preference tuning) is not evaluated.
- Domain and language coverage: Results are limited to English web corpora (C4, FineWeb); performance on multilingual data, code, scientific/biomedical text, and mixed-domain pretraining remains unknown.
- Interaction with curation and deduplication: The method’s synergy or redundancy with standard data-quality interventions (dedup, perplexity filtering, NSFW/toxicity filters, URL/domain filtering) is not measured.
- Robustness to real-world noise types: Controlled corruptions (uniform replacement, permutation, span corruption) and a perplexity-based “noisy” split cover only a subset of web noise; effects on boilerplate/templated pages, duplicated content, HTML/markup artifacts, encoding/OCR errors, fragmented snippets, and topic drift are not studied.
- Noise labeling and evaluation bias: The “noisy” FineWeb split is defined with an external reference model; robustness to the choice of reference model, thresholds, and alternative noisy/clean definitions (e.g., human-labeled noise) is not explored.
- Negative-transfer regimes: Conditions where RNN-PPT harms performance (e.g., very clean data, domain mismatch, very small/no PPT budgets) are only briefly observed; a systematic map of when PPT helps vs. hurts is missing.
- Tokenizer and vocabulary dependence: RNN-PPT uses the full 50,304-token BPE vocabulary; the effect’s sensitivity to tokenizer type (Unigram/BPE/byte-level), special/rare tokens, or multilingual vocabularies is unknown.
- Context-length effects: Whether robustness gains hold for long-context pretraining (e.g., 8k–128k tokens) and long-range dependencies in natural text is not tested.
- Architectural generality (LM): Experiments use Pythia-like Transformers; generalization to different LM architectures (e.g., MoE, GQA/MHA variants, rotary vs. ALiBi, linear-attention, SSM-based LMs) is untested.
- Architectural generality (generator): RNNs are the only synthetic generators studied; whether LSTMs, GRUs, state-space models, cellular automata, or other recurrent/structured generators yield better or worse robustness is unknown.
- Generator hyperparameters and regimes: The impact of generator temperature, nonlinearity, spectral radius/eigenvalue spectra, chaotic vs. periodic regimes, sequence length distributions, and sampling curricula is not characterized.
- PPT budget scaling law: PPT effectiveness plateaus near 500 steps at 160M, but how the optimal PPT budget scales with model size, PT budget, and noise level is not established; adaptive PPT schedules remain unexplored.
- Automated source selection: Selecting a synthetic source currently requires full PPT-to-PT training; the field lacks predictive metrics or proxy evaluations to rank candidate sources cheaply.
- Mechanistic causality: The attention-based “noise self-modeling” metric is correlational; causal tests (e.g., targeted head ablation/patching, representation interventions, gradient-based causal mediation) are needed to establish mechanism.
- Beyond attention probes: Analyses focus on attention weights; the role of MLPs, layer norms, residual pathways, and representational structure in mediating robustness is not examined.
- Early-training dynamics: RNN-PPT models initially show higher noise-to-noise attention at PT start yet end up more robust; the cause of this transient behavior and its dependence on optimization hyperparameters is unclear.
- Compute/energy ROI: Results report PT-token savings but not wall-clock/energy costs; the practical cost-benefit of adding PPT (e.g., 65M synthetic tokens) versus stronger curation remains unquantified.
- Safety, bias, and calibration: Effects on toxicity, demographic bias, calibration/uncertainty, and factuality/hallucination are not evaluated; whether PPT shifts these properties is unknown.
- Memorization and privacy: It is unclear whether RNN-PPT affects memorization propensity or data extraction risks under standard privacy audits.
- Real-crawl training: Robustness was not demonstrated when training directly on minimally curated raw crawls; the benefits under “in-the-wild” pipelines remain to be tested.
- Interaction with robust-training methods: Synergies/conflicts with sample reweighting, noise-aware objectives, curriculum learning, and contrastive/noise-correction methods are not assessed.
- Alternative synthetic baselines: Comparisons are limited to Random and Dyck; other structured sources (e.g., PCFGs, algorithmic tasks, music/code corpora, higher-order Markov processes) and higher-order metamers (4-gram+) are not evaluated.
- Fairness of C4-PPT control: Only a single budget-matched C4-PPT control at 1B is shown; a broader comparison across budgets/scales is needed to isolate “structure” vs. “more clean tokens” effects.
Practical Applications
Immediate Applications
The paper’s core finding—that a short synthetic pre-pre-training (PPT) stage on sequences generated by ensembles of randomly initialized RNNs can make LLMs more robust to noisy pre-training (PT) data—enables several deployable uses. Below are actionable use cases, mapped to sectors, with concrete workflows and caveats.
- Noise-robust warm‑start in LLM training pipelines (Software/AI, Cloud)
- What: Insert a 200–500 step synthetic PPT stage before PT using an ensemble of random RNN generators (e.g., 1000 generators, hidden size 64, full tokenizer vocabulary).
- Why: Achieves lower validation loss under noisy PT; at 1B scale, 65M-token PPT matched baseline final loss with up to 49% fewer PT tokens across noise levels.
- How (workflow):
- Add a “PPT module” in the training runner that emits
checkpoint_ppt.ptafter ~500 synthetic steps. - Use the provided codebase to generate synthetic batches online or pre-generate a 65M-token buffer.
- Proceed with unchanged PT recipe and dataset.
- Assumptions/dependencies:
- Access to pretraining stack and weights (not applicable to closed APIs).
- Tokenizer with a large vocabulary; narrow vocab reduces gains.
- Similar model/dataset regimes as evaluated (160M–1B, C4/FineWeb-like noise).
- Token-efficiency and energy/cost reduction for noisy corpora (Energy, Finance, Software/AI)
- What: Leverage PPT-induced sample efficiency to reduce PT tokens or training runs required to hit target loss.
- Why: Up to 49% fewer PT tokens at 1B to achieve baseline loss in noisy settings; reduces compute spend and carbon footprint.
- How (workflow):
- Set target validation loss; run PPT; shorten PT schedule to target.
- Integrate a scheduler that stops PT when the baseline’s target loss is matched.
- Assumptions/dependencies:
- Gains are strongest when PT data contains residual noise; benefits may be smaller with heavily curated corpora.
- Relaxed data curation thresholds without catastrophic degradation (Data vendors, Data engineering, Policy/Procurement)
- What: Dial back some aggressive filters (e.g., on perplexity, duplication) to preserve tail knowledge while maintaining robustness via PPT.
- Why: PPT intervenes on the model to tolerate noise; can complement incomplete curation.
- How (workflow):
- Keep current curation; create a “lightly relaxed” variant (e.g., higher perplexity caps).
- Compare validation loss with/without PPT to quantify trade-off.
- Assumptions/dependencies:
- Must validate that downstream tasks still meet quality thresholds; the paper’s main metric is validation loss.
- Robust continual pretraining on heterogeneous web streams (Software/AI, MLOps)
- What: Use PPT as a preparatory step before each new noisy data tranche in continual PT schedules.
- Why: The mechanism (reducing “noise self-modeling” during PT) provides a better optimization trajectory when new, uneven-quality data arrives.
- How (workflow):
- For each continual PT phase, repeat a short synthetic PPT (e.g., 200–300 steps) from the prior checkpoint, then resume PT on the new corpus.
- Assumptions/dependencies:
- Empirically validated for initial PT; continual PT extension is practical but should be monitored.
- Domain LMs trained on messy text (Healthcare, Finance, Legal, Education)
- What: Pretrain or continue-pretrain smaller domain LMs on messy or OCR-prone corpora (e.g., EHR notes, filings, scanned PDFs, forum Q&A) with PPT to mitigate noise effects.
- Why: Paper shows robustness across multiple noise types (sample replacement, token permutation, span corruption) and on naturally noisy FineWeb subsets.
- How (workflow):
- Apply PPT before domain PT on collected corpora; keep PT recipe fixed.
- Monitor validation loss on clean in-domain validation sets.
- Assumptions/dependencies:
- Must ensure privacy compliance in domain data; PPT does not replace redaction/anonymization.
- Open-source model training for small labs/startups (Academia, SMEs)
- What: Adopt PPT to stabilize training on budget and with less aggressive data cleaning.
- Why: Low PPT budget (hundreds of steps; tens of millions of tokens) yields measurable robustness improvements.
- How (workflow):
- Integrate the open-source PPT code; use default configuration:
generators=1000,hidden_size=64,vocab=full,steps=500. - Assumptions/dependencies:
- Compute constraints should accommodate a short synthetic stage.
- Training monitors for “noise self‑modeling” (Software/AI Tooling)
- What: Add probes that track the paper’s attention-based metric r_noise to flag drift toward noise-to-noise attention patterns during PT.
- Why: Paper links improvements to reduced noise self-modeling, especially in late-layer heads during noisy PT.
- How (workflow):
- Periodically evaluate attention heads on a held-out corrupted-validation slice; alert if r_noise grows relative to PPT-initialized baseline.
- Assumptions/dependencies:
- Requires access to attention weights and evaluation infra; metric complements, not replaces, standard loss metrics.
- Rapid PPT A/B testing harness (MLOps)
- What: Instantiate a harness to compare: No PPT vs Random vs Dyck vs RNN-PPT across a small grid of PPT steps and generator counts.
- Why: The paper’s ablations identify sweet spots (e.g., generator hidden size 16–64; ≥100 generators; full vocabulary).
- How (workflow):
- Use a scripted sweep to select the best PPT config on a small PT pilot before committing full budgets.
- Assumptions/dependencies:
- Requires a small budget for pilot PT; results transfer best when PT data/noise resembles production.
- Educational demos on structure learning (Education/Research)
- What: Classroom labs demonstrating how synthetic structured pretraining changes optimization trajectories under noise.
- Why: Clear, replicable experiment showing sequential inductive bias vs low-order statistics (unigram/bigram/trigram metamers).
- How (workflow):
- Provide students with the code repo, small models (≤160M), and noise-injection toggles to observe effects.
- Assumptions/dependencies:
- Modest compute (single or few GPUs) and access to the provided code.
- Procurement guidance for dataset providers (Policy/Standards)
- What: Update RFPs/SOWs to allow calibrated levels of residual noise if model-side robustness (PPT) is applied and validated.
- Why: Balances tail-knowledge retention with practical cleaning costs.
- How (workflow):
- Include a requirement to report loss under a “noisy split” and a “clean split,” with and without PPT warm-up.
- Assumptions/dependencies:
- Requires shared evaluation protocols and transparency into training runs.
Long-Term Applications
The paper suggests promising directions that need further research, scaling, or engineering before wide deployment.
- Scaling PPT to frontier models and multi-epoch PT (Software/AI, Cloud)
- What: Validate and tune PPT for ≥7B–70B models and longer PT schedules.
- Potential products/workflows:
- “PPT-as-a-service” checkpoints for frontier-scale training.
- Adaptive PPT length auto-tuning based on early r_noise and loss curves.
- Assumptions/dependencies:
- Unknown scaling laws beyond 1B; may require adjusting generator complexity and step counts.
- Generalized synthetic sources beyond RNNs (Research, Software/AI)
- What: Explore LSTMs, state-space models, and other sequence architectures as generators to broaden inductive biases.
- Potential tools:
- A modular synthetic-source library with pluggable generators and auto-selection heuristics.
- Assumptions/dependencies:
- The paper shows benefit is tied to learnable, low-bias sequential structure; new sources must meet these criteria.
- Dynamic, curriculum-aware PPT/PT schedulers (Software/AI, MLOps)
- What: Real-time adjustment of PPT length and generator parameters based on online signals (e.g., r_noise, validation loss slope).
- Potential products:
- “Noise-aware trainer” that inserts micro-PPT refreshers when noise self-modeling rises.
- Assumptions/dependencies:
- Requires reliable, low-overhead probes and validated intervention policies.
- Robust training for multilingual and low-resource web data (Global development, Education)
- What: Apply PPT to pretrain models on noisier, under-resourced languages where curation tools are limited.
- Potential workflows:
- Language-specific PPT parameter sweeps, coupled with lighter curation.
- Assumptions/dependencies:
- Tokenizer coverage and vocabulary breadth must be adequate; benefits may vary with script and tokenization quality.
- Federated or on-device pretraining with non-IID, noisy streams (Edge AI, Privacy-preserving AI)
- What: Use PPT to stabilize server-side base models before federated aggregation across noisy clients.
- Potential workflows:
- Server initializes with PPT, then aggregates client updates from messy local corpora.
- Assumptions/dependencies:
- Requires federated PT setups; security/privacy constraints remain orthogonal.
- Sector-specific robustness for OCR and ASR pipelines (Healthcare, Legal, Finance, Public Sector)
- What: Couple PPT with pretraining on OCR/ASR outputs (which introduce character-level and span-level noise).
- Potential tools:
- Synthetic corruption suites paired with PPT to emulate channel noise before domain PT.
- Assumptions/dependencies:
- Must verify improvements on downstream tasks (e.g., coding extraction, contract parsing), not just validation loss.
- Standards and benchmarks for noise-robust PT (Policy, Academia, Industry consortia)
- What: Establish shared protocols for measuring robustness (e.g., controlled sample/token/span corruption; r_noise reporting).
- Potential outcomes:
- A “Noise-Robust PT Scorecard” required in model cards.
- Assumptions/dependencies:
- Community agreement and datasets for comparative evaluation.
- Theory-guided source selection and diagnostics (Academia)
- What: Predictive metrics to select effective synthetic sources without full PPT-to-PT runs.
- Potential tools:
- Cheap proxy metrics capturing long-range dependencies absent in unigram/bigram/trigram metamers.
- Assumptions/dependencies:
- Requires correlational studies across sources and PT outcomes.
- Environmental impact optimization (Energy, Sustainability)
- What: Co-design PPT with token-efficiency targets to minimize energy per performance point.
- Potential workflows:
- Optimize PPT parameters for maximal PT-token savings across noise bands; integrate into sustainability reporting.
- Assumptions/dependencies:
- Accurate energy metering and standardized loss/performance targets.
- Robustness-aware data marketplace practices (Policy, Data economy)
- What: Pricing and SLAs that reflect acceptable noise levels when model-side robustness is in place.
- Potential outcomes:
- Tiered data products (e.g., “standard clean,” “lightly cleaned + PPT-ready”) with documented loss trade-offs.
- Assumptions/dependencies:
- Transparency into training practices and shared evaluation criteria.
Notes on feasibility and dependencies common across applications:
- The benefits are demonstrated on validation loss (and some LAMBADA evidence); task-specific gains should be verified per deployment.
- PPT gains depend on generator “learnability” and low bias: moderate hidden sizes (≈16–64), large ensembles (≥100, often ~1000), and broad token vocabularies.
- Very large or very small generators, too few generators, or restricted vocabularies can attenuate benefits.
- The approach complements, not replaces, data curation; legal/ethical filtering and safety removal remain necessary.
Glossary
- Ablation: A controlled experimental comparison where specific components or choices are removed or varied to assess their impact. "Through controlled ablations, we identify three conditions under which RNN-PPT yields gains: generators should remain learnable, the ensemble should be large enough to avoid idiosyncratic bias, and the vocabulary should be broad."
- Attention head: A sub-component of a multi-head attention layer that learns distinct patterns of dependencies. "An attention probe shows that RNN-PPT models progressively learn to downweight attention between corrupted tokens---an effect concentrated in late-layer heads."
- Attention probe: An analysis technique that inspects attention patterns to diagnose model behavior. "An attention probe shows that RNN-PPT models progressively learn to downweight attention between corrupted tokens---an effect concentrated in late-layer heads."
- Attention weight: The normalized coefficient indicating how much a query position attends to a key position. "let denote the attention weight from query position to key position ."
- Bigram: A two-token sequence model capturing adjacent token dependencies. "These controls match the unigram, bigram, or trigram statistics of RNN-generated tokens."
- C4: A large, cleaned web text dataset commonly used for LLM pre-training. "Our primary pre-training corpus is C4~\citep{raffel2020exploring}."
- Causal prefix: The set of prior positions permitted for attention in a strictly left-to-right (causal) model. "For a given , let $K_{\text{valid}(q)$ be all valid key positions in its causal prefix"
- Categorical distribution: A discrete probability distribution over a finite set used for sampling tokens. ""
- Chomsky hierarchy: A classification of formal languages by generative capacity used to analyze structural complexity. "and explain the effect through the Chomsky hierarchy~\citep{delétang2023neuralnetworkschomskyhierarchy}."
- Dyck language: A formal language of balanced brackets used to instill hierarchical structure. "Dyck PPT uses -Shuffle Dyck, the strongest formal-language source from prior work~\citep{hu2025prepretraining}, which interleaves independent, balanced 1-Dyck bracket-matching strings."
- Ensemble: A collection of multiple models or generators used together to produce diverse training signals. "an ensemble of randomly initialized recurrent neural networks (RNNs)."
- FineWeb: A large-scale web text dataset curated for pre-training. "we also use FineWeb~\citep{penedo2024fineweb} as a natural language dataset."
- Formal language: A mathematically defined set of strings (e.g., Dyck) used to probe or impart structural priors. "an unstructured Random i.i.d.\ token source and a formal-language Dyck source."
- Hidden size: The dimensionality of a model’s hidden state vector. "hidden size "
- i.i.d.: Independent and identically distributed; data points sampled independently from the same distribution. "Random i.i.d.\ token source"
- LAMBADA-OpenAI: A dataset requiring broad discourse understanding to predict a passage’s final word. "we also evaluate on LAMBADA-OpenAI~\citep{paperno2016lambada}"
- Logits: The unnormalized scores before applying softmax to obtain probabilities. "with logits "
- Mechanistic analyses: Explanatory evaluations that probe internal model mechanisms to understand observed behaviors. "Mechanistic analyses suggest PPT does not immediately suppress attention to noisy tokens."
- Metamer: A synthetic stimulus constructed to match certain statistics (e.g., n-grams) of another source while altering other properties. "Unigram, bigram, and trigram metamer controls recover almost none of the benefit, indicating that longer-range sequential structure is what drives the effect."
- Noise self-modeling: A phenomenon where a model learns to treat noise as predictive, reinforcing attention among corrupted tokens. "We refer to this behavior as noise self-modeling."
- One-hot encoding: A vector representation with a single 1 indicating a specific token and 0s elsewhere. "is the one-hot encoding of the previous token."
- Packing: A training technique that concatenates multiple shorter sequences to fully utilize the model’s context window. "For token-efficiency comparisons, all experiments use packing, so equal steps correspond to equal training tokens."
- Perplexity: An exponentiated average negative log-likelihood metric for LLMs; lower is better. "RNN-PPT also tends to improve LAMBADA~\citep{paperno2016lambada} perplexity"
- Pre-pre-training (PPT): An initial, lightweight synthetic training phase before standard pre-training to impart structural priors. "We therefore study whether a lightweight pre-pre-training (PPT) stage based on synthetic data with learnable temporal structure helps resist noisy data during the pre-training (PT) stage."
- Pre-training (PT): Large-scale training on unlabeled text to learn general language modeling capabilities. "helps resist noisy data during the pre-training (PT) stage."
- Pythia: A family of open LLM architectures used for controlled training and analysis. "we pre-train a 160M-parameter Pythia model~\citep{biderman2023pythia}"
- Recurrent neural network (RNN): A neural architecture with recurrent connections for modeling sequences and temporal dependencies. "Our proposed source samples sequences from an ensemble of randomly initialized RNN models."
- Sampling temperature: A parameter controlling randomness when sampling from a probability distribution; higher values yield more diverse samples. "where is the sampling temperature."
- Sample-level corruption: A noise process that replaces entire training sequences with random tokens during PT. "Our primary setting introduces sample-level corruption during PT"
- Span corruption: A noise process that perturbs contiguous segments of tokens within sequences. "token permutation and span corruption"
- Token permutation: A noise process that shuffles or permutes tokens within a sequence. "token permutation and span corruption"
- Tokenizer vocabulary: The set of discrete symbols produced by a tokenizer that the model operates over. "where is the tokenizer vocabulary size."
- Unigram: A single-token frequency model ignoring dependencies among tokens. "Unigram, bigram, and trigram metamer controls recover almost none of the benefit"
- Validation loss: The average loss on a held-out dataset used to monitor generalization during training. "Our main metric is held-out validation loss on the clean PT corpus"
- Web-scale corpora: Extremely large text datasets collected from the web for training LLMs. "LLMs rely on web-scale corpora for pre-training."
Collections
Sign up for free to add this paper to one or more collections.