- The paper demonstrates that synthetic noisy data induces training loss divergence, particularly when using small, restricted vocabularies for noise injection.
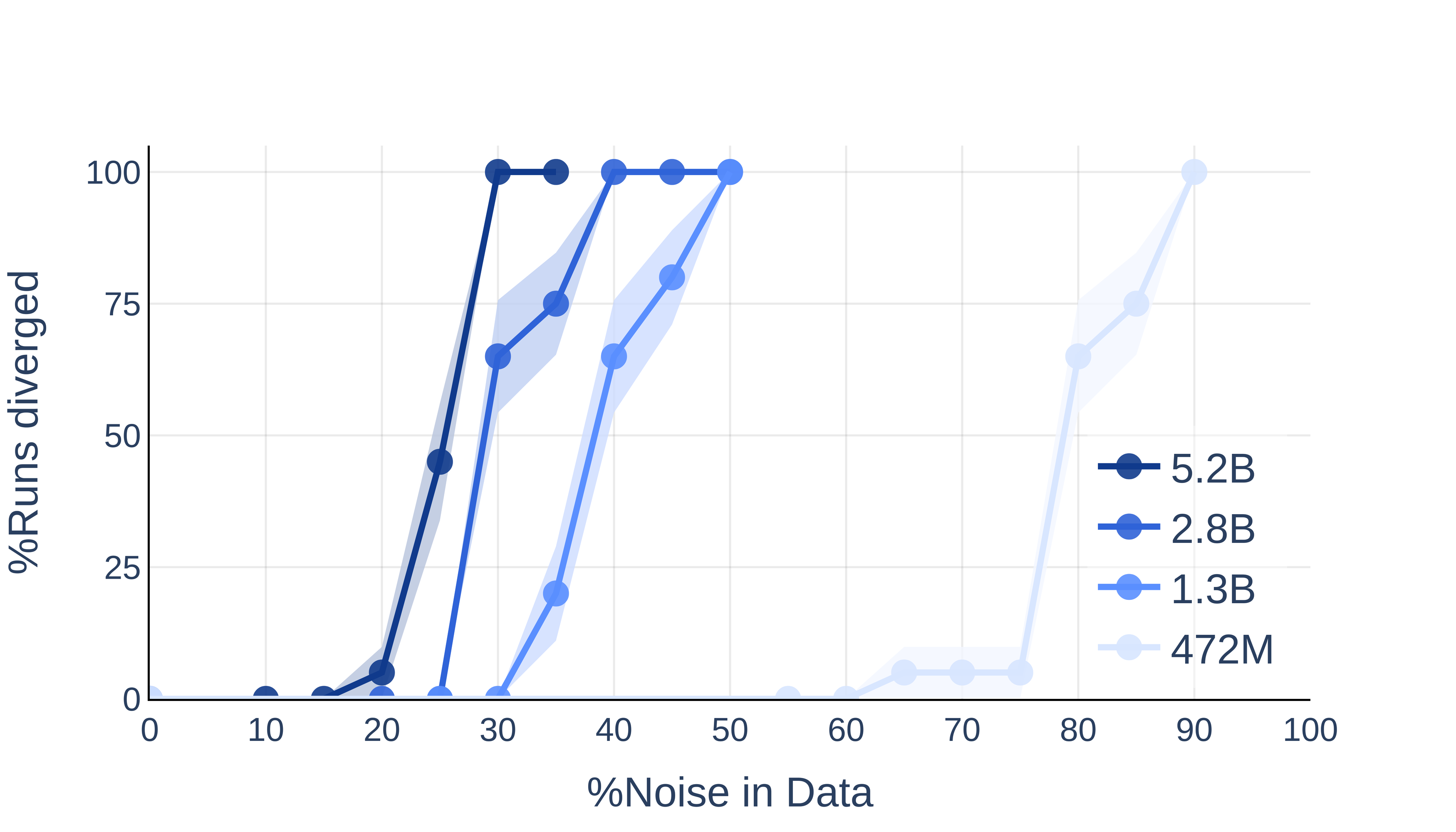
- The study reveals that deeper architectures are significantly more sensitive to noise than wider ones, with token insertion methods proving more destabilizing than overwriting.
- The authors propose robust interventions such as data cleaning and QK-layernorm to mitigate instability, with comparable divergence behavior observed between dense and MoE models.
Empirical Analysis of Noisy Data and Training Loss Divergence in LLM Pretraining
Introduction and Motivation
The pretraining of LLMs leverages massive, uncurated web-scale datasets, which unavoidably introduce substantial data noise from a variety of sources, including random sequences, unregulated content, and artifacts of tokenization. Despite regular practitioner speculation implicating noisy data as a possible cause of instabilities and loss divergence in large-batch, large-model training, a rigorous understanding of these dynamics under controlled experimentation has been lacking. This paper conducts a systematic empirical investigation to quantify the impact of synthetic uniform random noise on LLM pretraining stability across model and data scales (2602.02400).
Experimental Setup and Methodology
The study utilizes controlled synthetic noise injection into subsets of Llama 4 pretraining corpora, injecting noise tokens sampled uniformly from restricted or unrestricted tokenizer vocabularies, with configurable ratios and insertion schemes. Both dense (standard Transformer-based) and Mixture-of-Experts (MoE) architectures are considered, spanning a parameter range from 480M to 5.2B. Multiple random seeds are employed to measure the stochastic nature of divergence, and identification of divergent runs is based on persistent, unrecoverable increases in training loss exceeding a calibrated threshold.
The factors varied include:
- Noise Vocabulary Size and Content: The cardinality and token selection of Vn are varied, assessing whether rare/common/semantic content affects divergence.
- Noise Injection Method: Both “insertion” (injecting noise tokens between existing tokens) and “overwrite” (replacing clean tokens probabilistically) are tested.
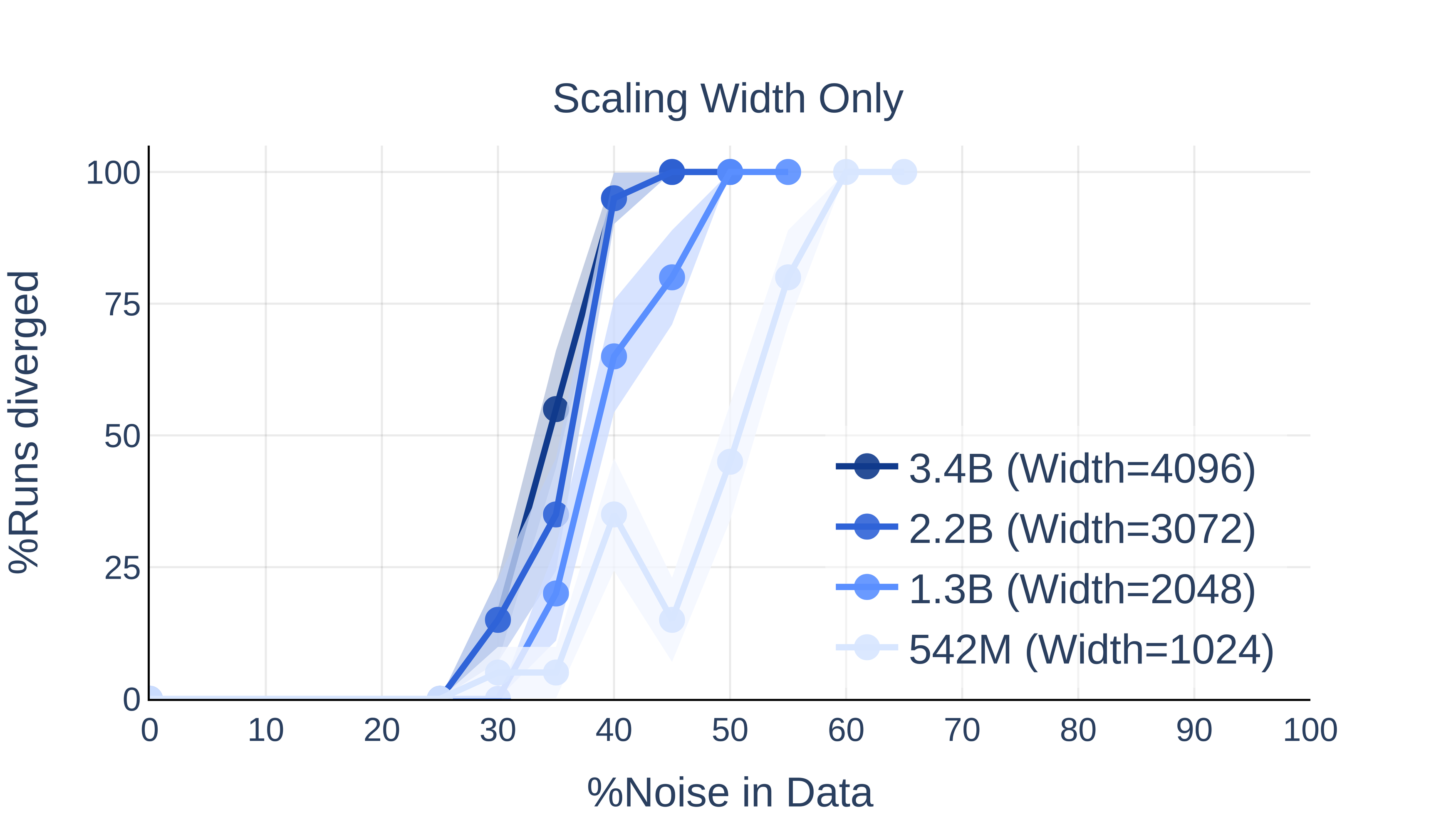
- Scaling Axes: Model depth and width are independently and jointly scaled to characterize architectural sensitivity.
- Comparison of Dense vs. MoE: Both architectures are tested under parameter-matched configurations.
- Activation Diagnostics: Detailed examination of attention logits, parameter norms, and activation statistics is conducted to differentiate mechanics of divergence caused by noisy data versus high learning rates.
Key Empirical Findings
Noisy Data Induces Loss Divergence; Noise Type is Crucial
Systematic introduction of uniform random noise into pretraining corpora revealed that noisy data can indeed cause catastrophic training loss divergence. Notably, the probability of such divergence is highly sensitive to the specifics of the noise:
- Vocabulary Size Effect: Restricting the noise to a small subset of the tokenizer vocabulary dramatically increases the likelihood of divergence for a fixed noise ratio.
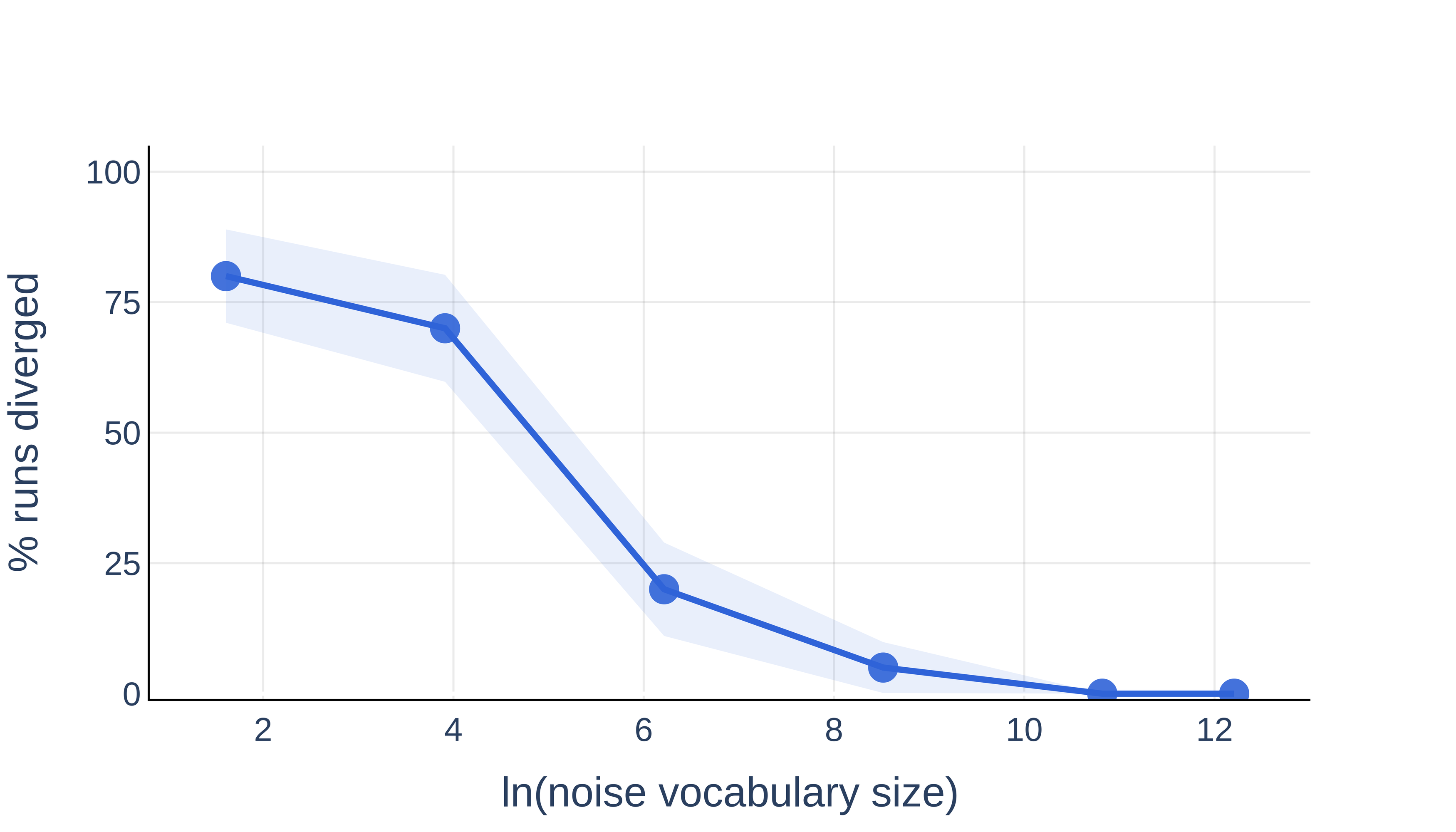
Figure 2: Reduced noise vocabulary size significantly increases the probability of divergence in 540M models at fixed noise ratio.
- Vocabulary Content: The empirical data show that the semantic or frequency content of the noise tokens—whether rare or common—exerts negligible effect on divergence probability for a fixed vocabulary size.
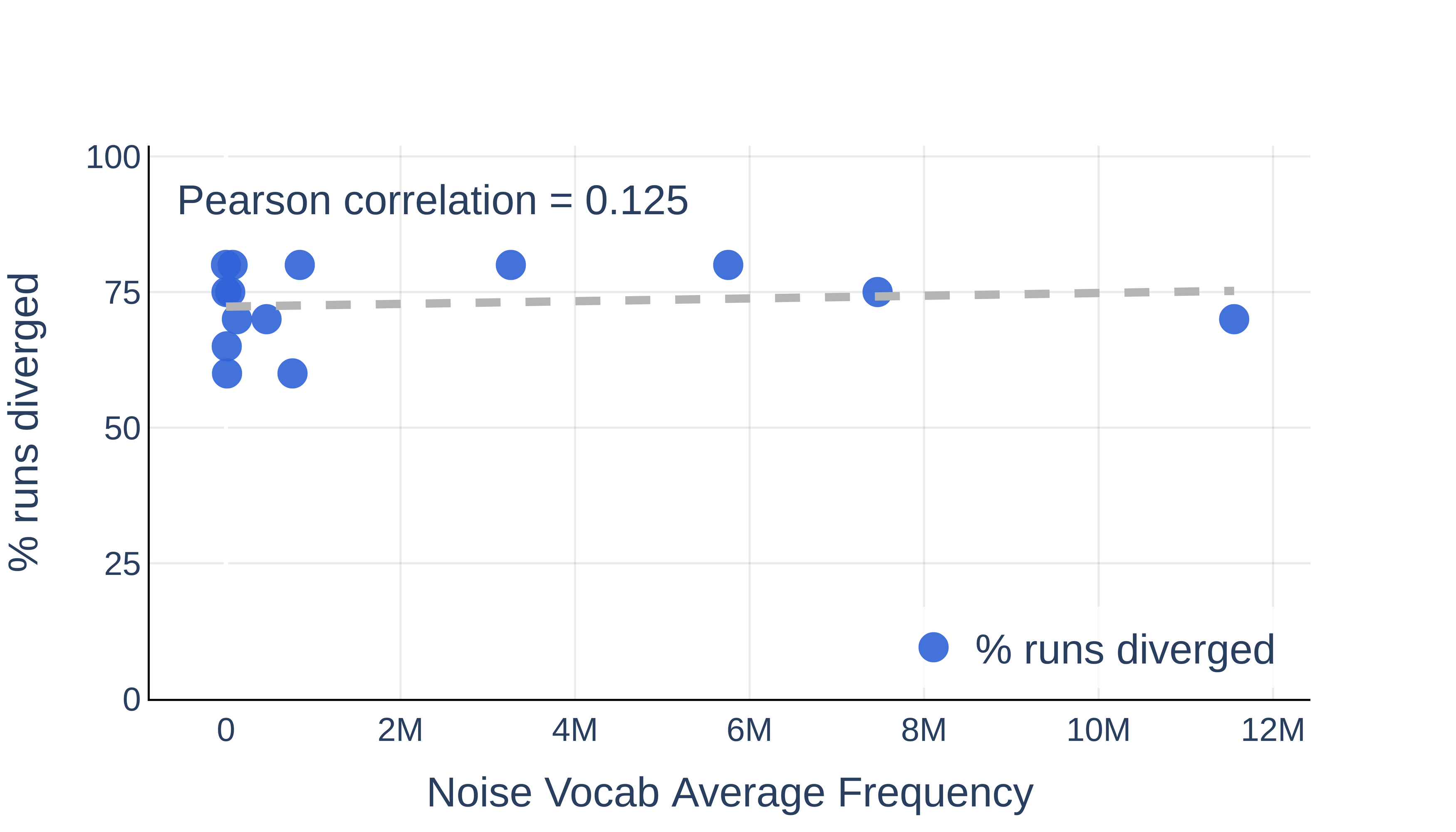
Figure 1: The content (frequency) of noise tokens does not significantly affect divergence; size is the dominant factor.
- Insertion vs. Overwrite: Inserting noisy tokens is considerably more destabilizing than overwriting, at matched noise ratios and vocabulary sizes.
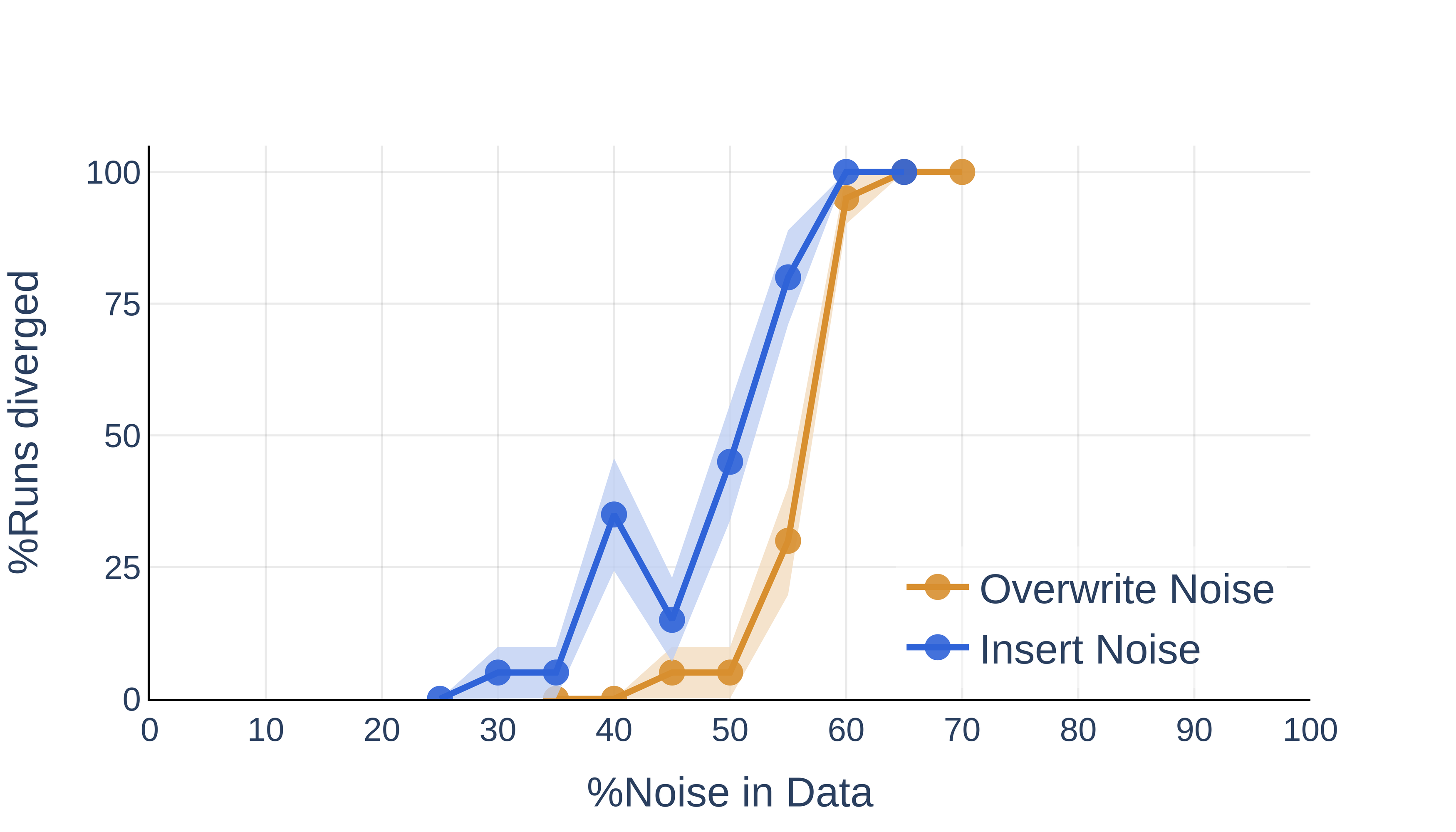
Figure 3: Inserting noise tokens leads to higher divergence probability compared to overwriting.
Scaling Trends: Depth Sensitizes, Width Less So
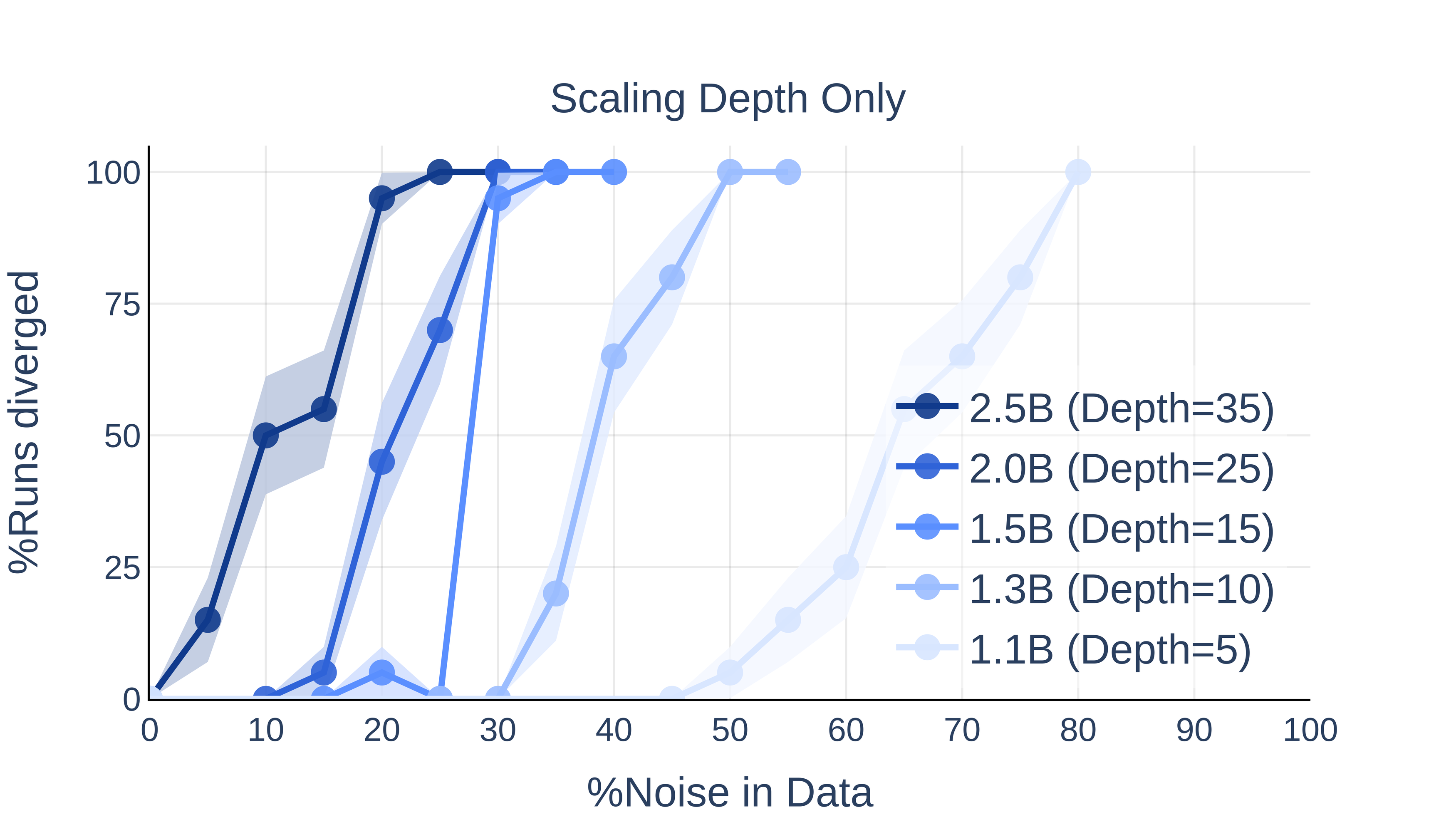
Figure 5: Depth scaling (right) has a much stronger effect on divergence than width scaling (left).
Divergence Mechanisms: Distinguishing Noise from High LR
Through careful activation diagnostics, the authors show that:
- Maximum Attention Logits: Divergence due to noisy data occurs at a lower and distinct attention logit threshold (∼1800) compared to high learning rate (LR) divergence (∼4000); the latter has been previously studied.
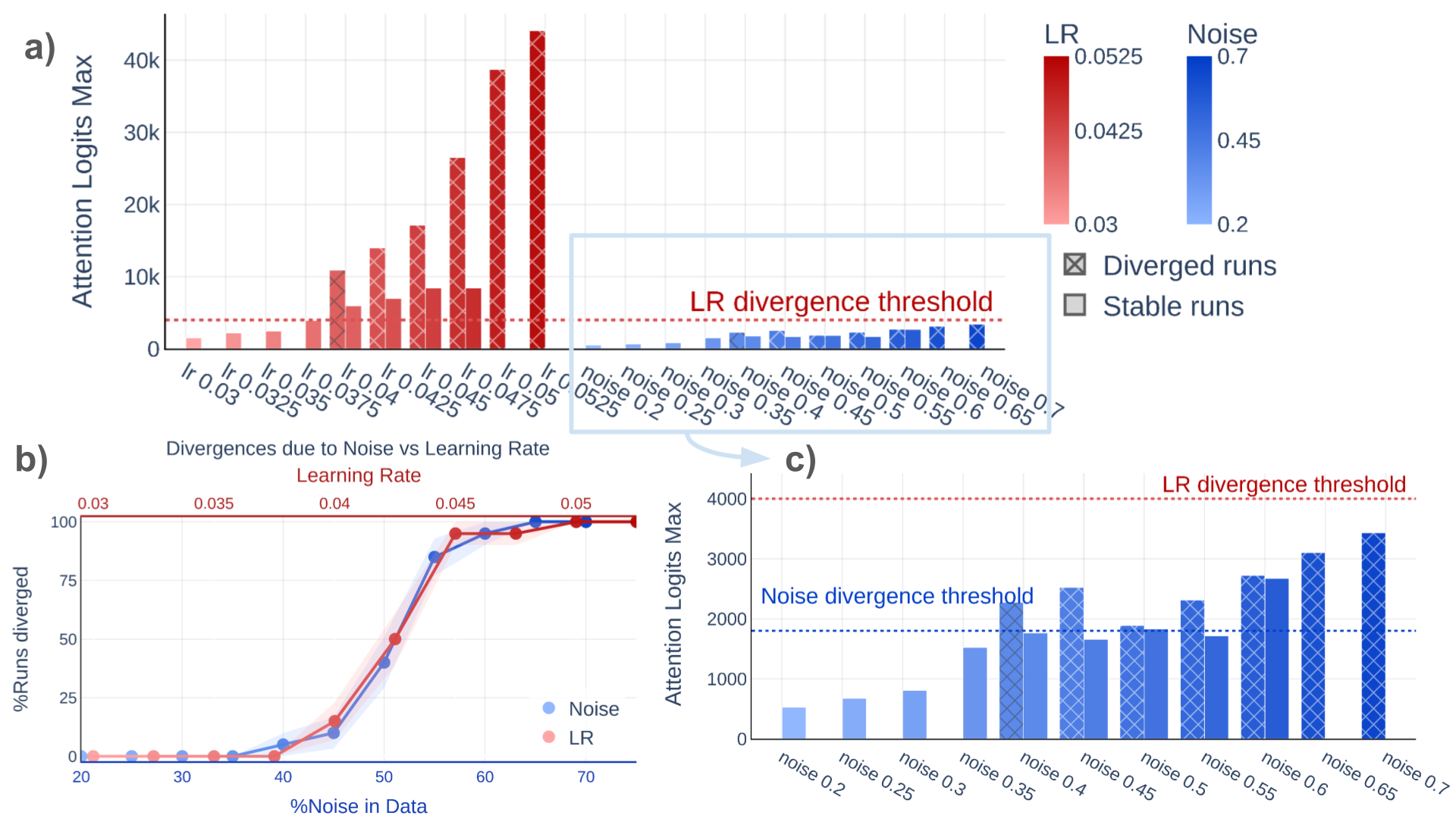
Figure 6: Noisy data- and LR-induced divergences present distinct attention logit statistics; blue bars: noise, red bars: LR.
- Parameter Norms & Activation Patterns: Parameter RMS norms and activation magnitude increase dramatically under high LR divergence but are only moderately affected by noise-induced divergence.
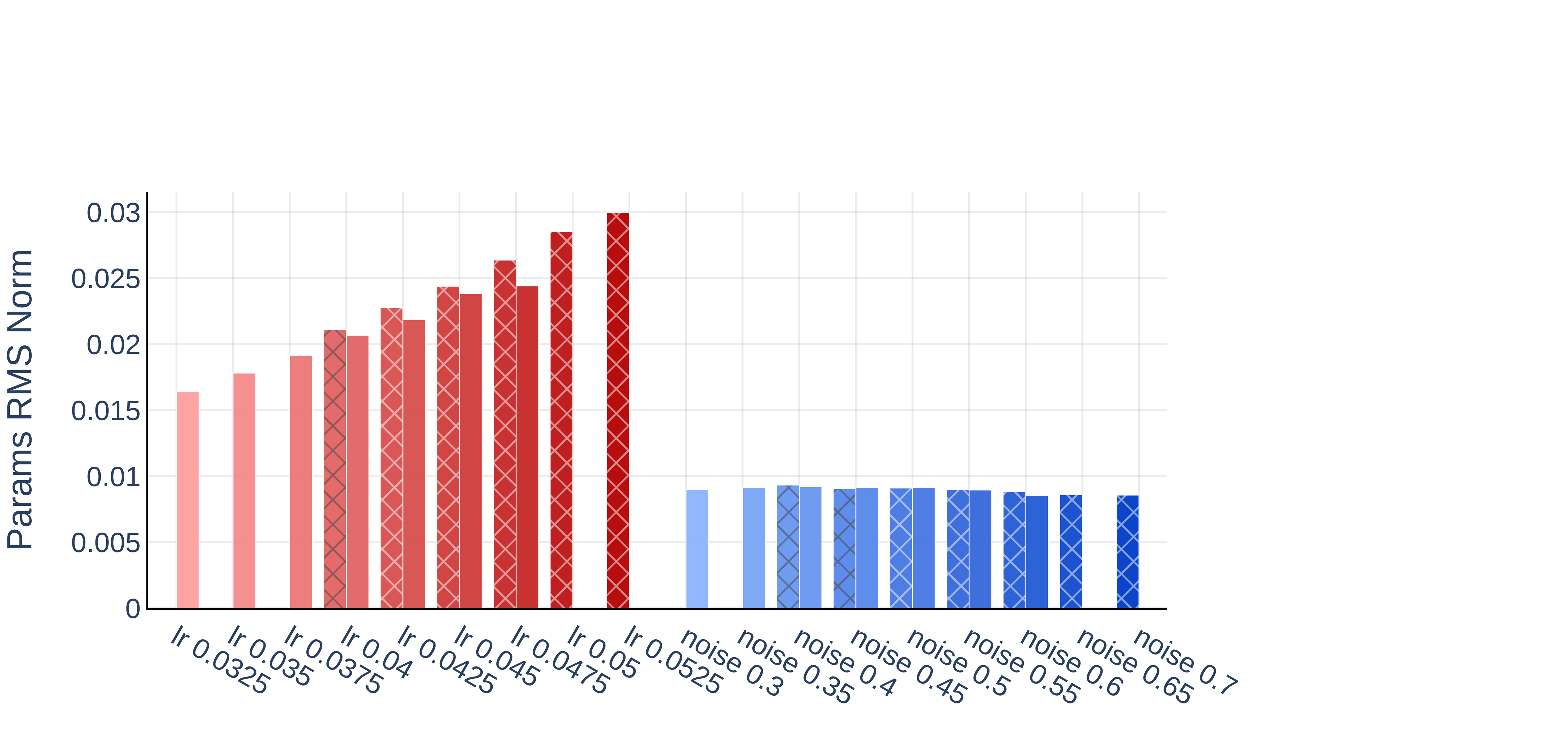
Figure 7: Divergence episodes from LR and noise show different trends in parameter RMS norms and activations.
This disambiguation enables practical diagnostics for the underlying mechanism of a divergence event.
Interventions: Data Cleaning and QK-layernorm
Empirically, the most robust prevention is data cleaning; reducing the noise ratio yields consistently lower loss on clean tokens and eliminates divergence events. When cleaning is impractical, application of QK-layernorm—in which attention queries and keys are normalized—completely suppresses divergence across all tested high-noise regimes.
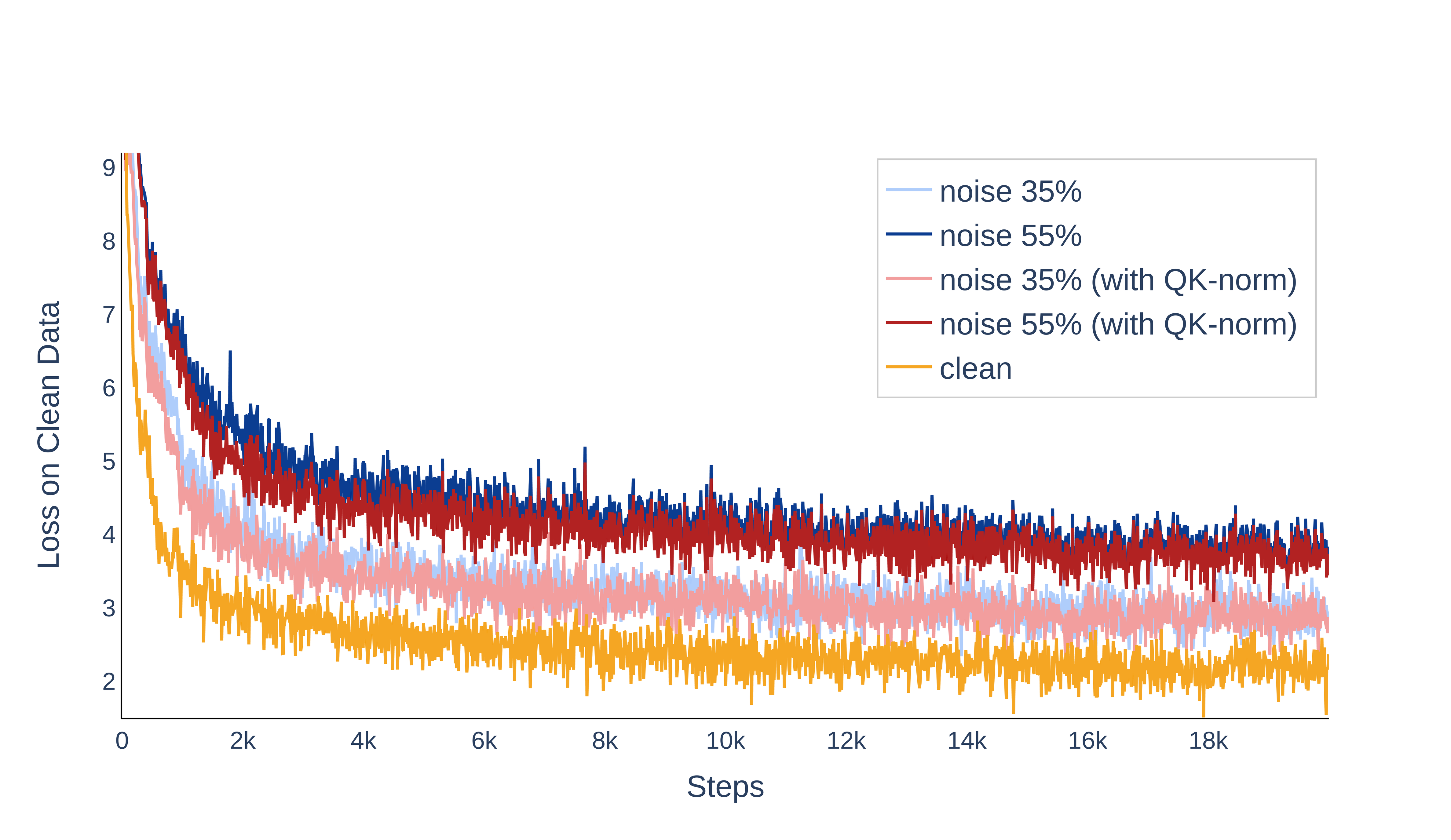
Figure 8: Persistent noisy data degrades final loss even in stable runs; QK-layernorm and data cleaning are both effective.
MoE Architectures: Comparable Sensitivity to Dense Counterparts
Despite architectural differences and the expectation of increased sensitivity due to routing, MoE models—when parameter-matched to dense equivalents—exhibit indistinguishable divergence probabilities under noisy data across all tested parameter scales.
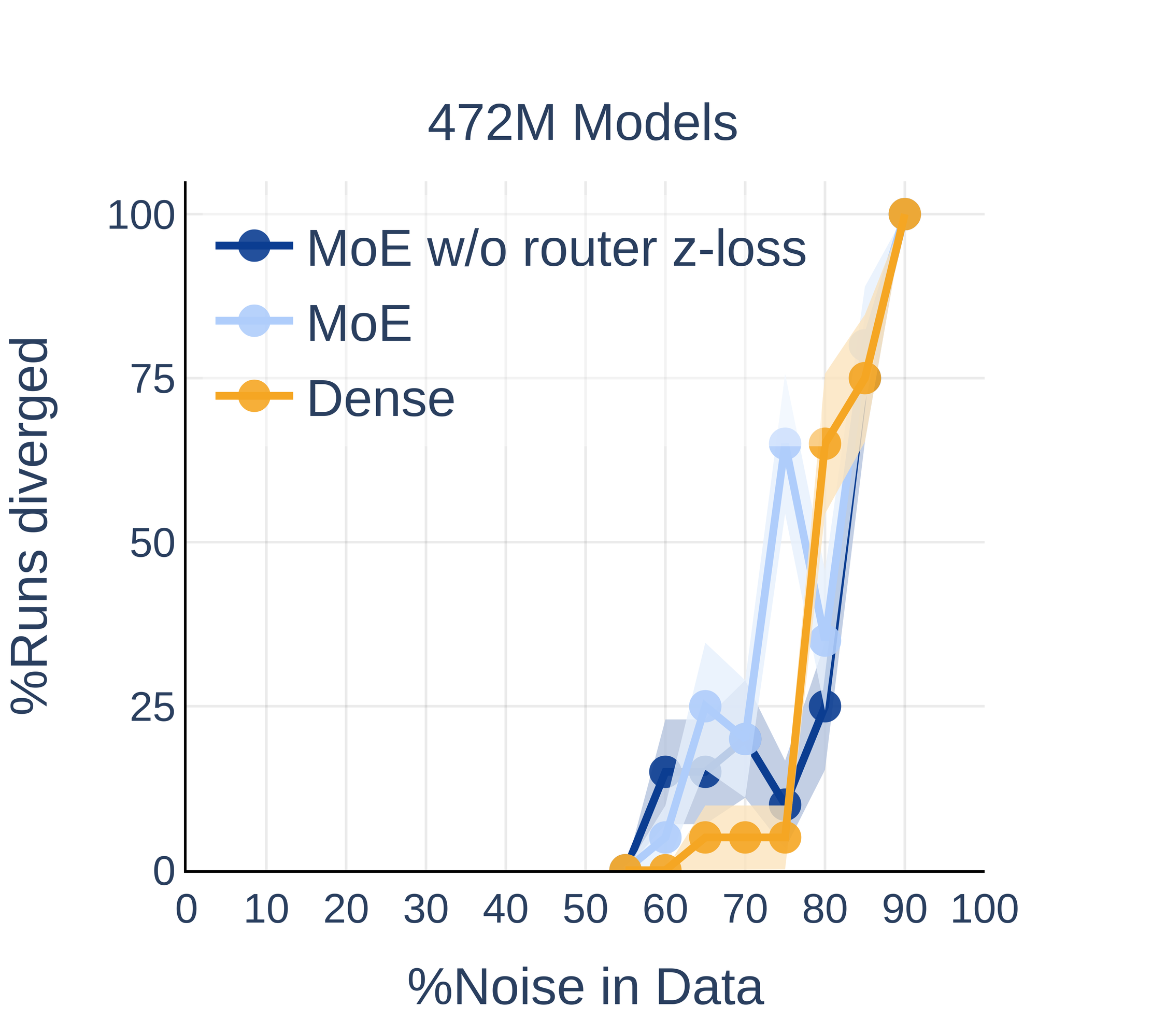
Figure 9: Dense and active-parameter-matched MoE models show comparable divergence rates under noise, regardless of router regularization.
Analysis of noisy token routing within MoEs reveals no significant correlation between the fraction of noisy tokens routed to an expert and the magnitude of activation, indicating that noise does not cause pathological specialization within the routing mechanism.
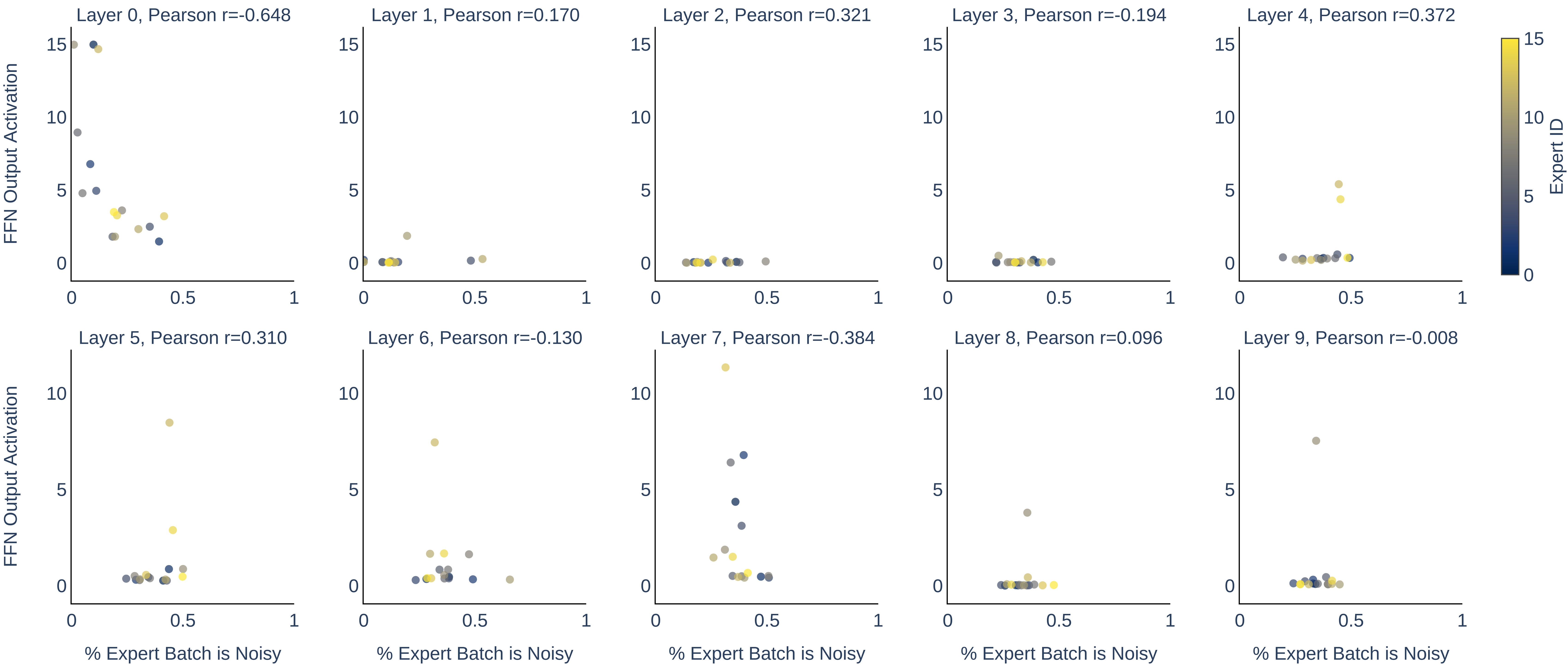
Figure 10: The fraction of noisy tokens routed to each expert in MoE shows negligible correlation with expert FFN activation magnitude.
Theoretical and Practical Implications
This study systematically establishes that noisy data is a direct cause of training instability and loss divergence in LLM pretraining, particularly in larger and deeper architectures. The primary destabilizing factor is the structure of the noise (specifically, restricted small vocabularies), rather than its frequency characteristics or semantic content. The results suggest that as LLMs continue scaling along depth and parameter count, data curation and fidelity become increasingly critical, and robust training setups must integrate not just learning rate and architectural stabilization heuristics, but also noise-aware dataset construction and monitoring tools.
The diagnostic separability of noise-induced versus LR-induced divergence has implications for automated training monitoring pipelines, enabling specific remedial action (e.g., data audit/cleaning vs. learning rate annealing).
For practitioners deploying MoE architectures, the empirical results justify expectation of parity in noise robustness with dense models, assuming proper parameter-matching and load balancing.
Looking forward, systematic studies on other real-world noise modalities (beyond uniform random noise) and further exploration of scaling laws in even larger regimes are pertinent open areas. Additionally, the efficacy and potential side effects of architectural normalization techniques (like QK-layernorm) in mitigating non-uniform, structured noise remain to be more fully understood.
Conclusion
This work provides a comprehensive empirical framework for analyzing and diagnosing the role of noisy data in LLM pretraining divergence. Key recommendations include prioritizing data cleaning, leveraging practical diagnostics based on activation statistics, and, when unavoidable, deploying normalization-based architectural interventions. The results highlight an increasing imperative for rigorous data quality practices as model scales continue to grow, and an ongoing need for theoretically grounded analysis of the limits of training stability under imperfect data conditions.