Nectar: Neural Estimation of Cached-Token Attention via Regression
Published 10 May 2026 in cs.LG and cs.CL | (2605.09778v1)
Abstract: Evaluating softmax attention over a fixed long context requires reading every cached key-value pair for each new query token. For a given context (a book, a manual, a legal corpus) the attention output is a deterministic function of the query. We propose Nectar, which fits a compact neural network to this function for queries drawn from a task-relevant distribution. Nectar fits two networks per layer and KV-head: a target network that predicts the attention output and a score network that predicts the log-normalizer. The pair plugs into the standard masked self-attention at inference time, replacing the $O(n)$ attention over the cache with a forward pass whose cost does not depend on $n$. Each module carries on the order of $|θ|$ parameters per layer and KV-head, typically much smaller than the $2nd$ KV-cache footprint at the same granularity. We report experiments on models from 1.7B to 8B parameters across five long-context datasets. The approximation error tracks the next-token accuracy gap to full attention, and allocating capacity non-uniformly across layers reduces that gap in our ablation. Beyond this analysis of metrics, we check that the text generations (following a question prompt) of a model equipped with a Nectar module match in semantic content those obtained by giving the same model access to the full cache.
The paper presents Nectar, which approximates full-context attention using neural regression to cut computation and memory costs for long documents.
It introduces two variants, Quadrature and MLP, with MLP showing superior token accuracy and semantic generation quality.
Empirical results demonstrate significantly faster inference and reduced GPU memory usage while maintaining competitive performance.
Neural Estimation of Cached-Token Attention via Regression: Technical Analysis of Nectar
Motivation and Challenges of Long-Context Inference
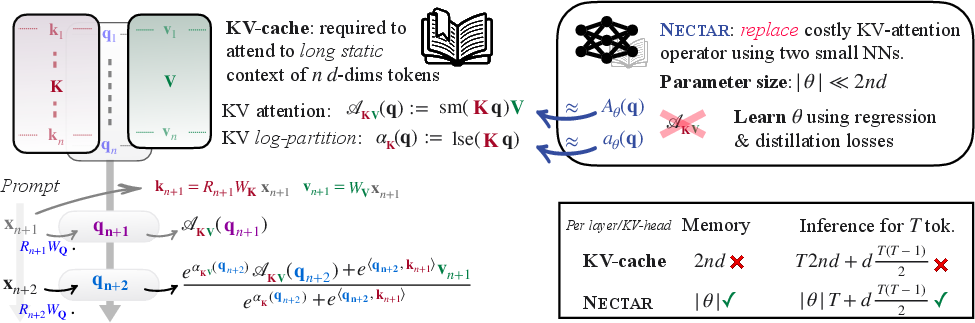
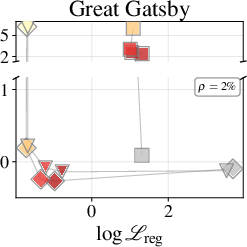
Transformer-based LLMs exhibit strong contextual reasoning, yet their deployment on long documents is bottlenecked by KV-cache memory footprints and O(n) attention costs. Attending over contexts such as full novels, medical records, or legal corpora with standard softmax attention incurs disproportionate resource demands: for Qwen3-4B, storing the KV-cache for The Great Gatsby requires nearly $9$ GB bfloat16, exceeding the model footprint itself, and each new token must attend to all cached pairs.
Existing strategies for context compaction include sparse attention, KV eviction, compression tokens, and retrieval-based distillation. Cartridges and related approaches distill the model's next-token outputs or attention weights into compact representations, optimizing for downstream generation but not explicitly targeting the internal attention operator. There remains an unmet need for per-context, per-layer function approximation of the full attention mapping from queries to attended outputs.
Nectar: Regressing Attention as a Neural Function
The Nectar methodology targets the deterministic mapping from query token to attention output, given a static context. For each layer ℓ and KV head h, the attention operation over the fixed context is decomposed into:
The log-normalizer αℓ,h(q)=logj=1∑nexp(d1q⊤kj)
The normalized attention output Aℓ,h(q)
Nectar fits two neural networks per head: a score network approximating αℓ,h(q), and a target network regressing Aℓ,h(q). This pair replaces the KV-cache-backed attention operator, converting the O(n) attention computation into a forward pass with cost independent of context length.
Figure 1: Nectar replaces the KV-cache attention operators Aℓ,h and $9$0 with compact networks $9$1 and $9$2, reducing both memory and inference cost from $9$3 to $9$4.
During inference, the neural pair is blended into local causal attention via the standard softmax. The scalar log-normalizer adjusts the relative weighting between regressed long-context attention and locally cached tokens, enabling principled integration without kernel modifications.
Architectural Variants: Quadrature and MLP Approximators
Nectar offers two architectural instantiations:
Quadrature: Storing $9$5 learnable pairs $9$6 per head, initialized from the ground-truth KV-cache, yielding analytic forms for score and target networks. This matches the cartridge recipe but is trained via regression rather than end-to-end distillation.
MLP: Score and target heads utilize SiLU-activated input-convex MLPs, optionally sharing a backbone or featuring skip-to-input and residual connections. The score network leverages the convexity of log-sum-exp in $9$7, drawing on amortized-MIPS architectures for efficient approximation of structured convex support functions (Olausson et al., 9 Mar 2026). Parameter allocation between score and target heads is empirically tuned for optimal fidelity.
Experimental Evaluation and Numerical Findings
Nectar was evaluated on Qwen3-1.7B, Qwen3-4B, Qwen2.5-7B-1M, and Qwen3-8B across five long-context datasets (public-domain novels and benchmarks up to 122k tokens). Extensions such as YaRN enabled context lengths beyond the model pretraining window.
Regression Fidelity to Attention Operator:
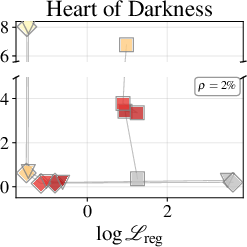
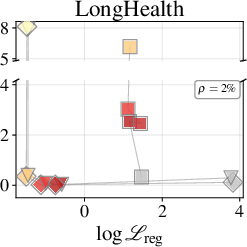
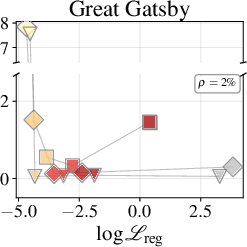
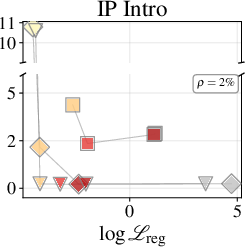
Token-level accuracy gaps (next-token prediction) versus full attention baseline are strongly correlated to regression loss, especially for MLPs at moderate parameter fractions ($9$8) of the original KV-cache. MLP approximators consistently outperform Quadrature, with accurate regression reducing the accuracy gap as model size and depth increase.
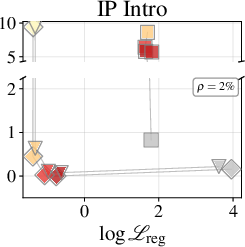
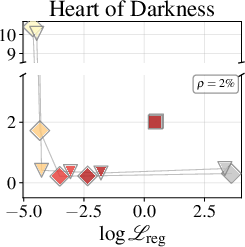
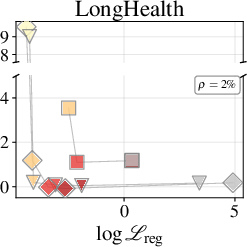
Figure 2: Token-accuracy gap (%) versus $9$9 for Qwen3-1.7B, showing reduced gap with improved regression.
Figure 3: Token-accuracy gap (%) versus ℓ0 for Qwen3-4B, highlighting architecture-dependent fidelity.
Generation Quality: LLM-Based Semantic Evaluation
Beyond token-level metrics, the study emphasizes semantic alignment between generations and document content. Models equipped with Nectar modules were scored across QA, summarization, quoting, and paraphrasing via commercial-grade LLM judges, comparing semantic similarity of outputs to ground-truth responses.
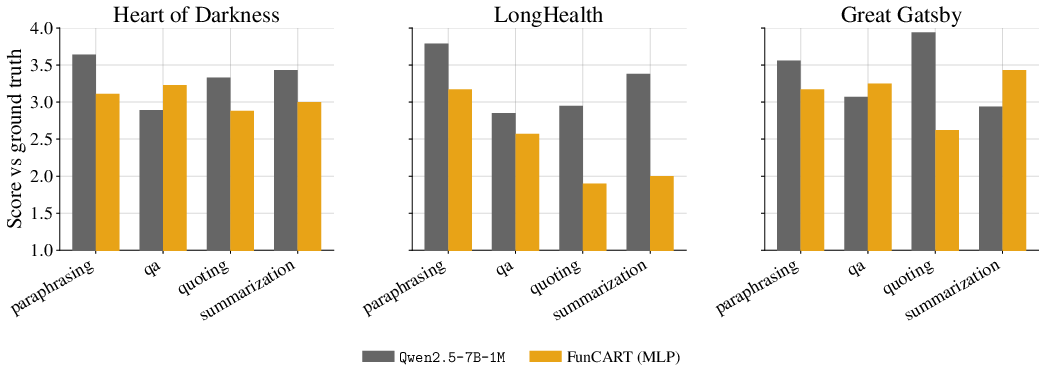
MLP Nectar modules, at increasing parameter fractions, deliver improved generation quality: the similarity score gap ℓ1 to full attention drops from ℓ2 at ℓ3 to ℓ4 at ℓ5 on a 1–5 scale, approaching indistinguishability from full attention. Quadrature modules show little improvement, maintaining ℓ6, regardless of capacity or loss weighting. Task breakdowns reveal quoting and summarization are most demanding; QA tasks are more robust, presumably due to their dominance in training data.
Figure 4: LLM-judge score (1–5, higher is better) per task type for the original model equipped with the full KV-cache and best MLP Nectar across three datasets.
Ablations and Footprint Benchmarks
Ablations indicate that non-uniform per-layer capacity allocation yields lower token-accuracy gap compared to uniform allocation, particularly in models with larger depth. Allocating parameter budget to later layers is empirically beneficial.
Memory and throughput benchmarks confirm Nectar substantially reduces inference time and GPU memory: TTFT shrinks from hundreds of seconds to tens of milliseconds, throughput improves ℓ7–ℓ8, and cache size drops by orders of magnitude. The inference cost and memory become invariant to context length, validating the fixed computational footprint.
Limitations and Prospects
Nectar modules are trained for fixed contexts; quality is evaluated at the training context length and requires ℓ9 ground-truth attention computation during setup. Generation quality is uneven across tasks and degrades for extremely long contexts (IP Intro). Future avenues include cross-context generalization (meta-learning, amortized conditioning), modular fusion (MoE-style gating via score network), and compositional approximators exploiting document structure.
The theoretical formulation of learning the deterministic mapping from queries to attention outputs establishes a new axis in context compression. Practical implications are considerable: Nectar offers a pathway to fixed-cost inference on extremely long documents without sacrificing expressiveness or semantic recall, independent of quadratic bottlenecks, aligning with both token-level and generative metrics.
Conclusion
Nectar systematically regresses the full-context attention operator via per-layer neural networks, offering a practical and theoretically grounded methodology for context compression and inference efficiency. Strong token-level and generation-level empirical results, particularly for MLP-based approximators, underscore the method's superiority over cartridge-style and analytic quadrature alternatives when approximating deep attention operators. The architectural flexibility and blending with local attention mechanisms suggest wide applicability across LLM architectures encountering long-context deployment constraints. Progress in amortized context representation and meta-conditioning will further extend Nectar's utility in future large-scale generative applications (2605.09778).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.