- The paper introduces DASH-KV, a method that reframes attention matching as an ANN search in a learned Hamming space to achieve linear-time LLM inference.
- It employs asymmetric query/key hashing with layer-specific encoders and dynamic mixed-precision filtering to maintain high retrieval recall and efficiency.
- Empirical results show significant latency reductions and competitive accuracy across benchmarks compared to full dot-product attention.
DASH-KV: Asymmetric KV Cache Hashing for Linear-Time Long-Context LLM Inference
Introduction and Motivation
DASH-KV introduces a paradigm shift in accelerating long-context inference for LLMs by reframing the core attention matching procedure as an Approximate Nearest Neighbor (ANN) search within a learned Hamming space. This fundamentally diverges from traditional compression approaches—quantization, selective eviction, and structured sharing—which only mitigate memory requirements but leave computational bottlenecks, particularly the O(N2) floating-point dot-product computation, unresolved. DASH-KV achieves strict O(N) inference complexity, replacing expensive matrix multiplications with bitwise operations, without permanent cache data loss or substantial degradation in downstream generation quality.
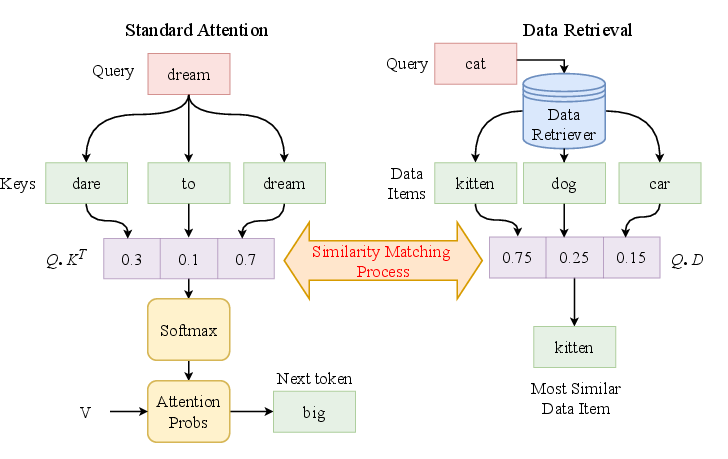
Figure 1: Alignment between standard attention mechanism and large-scale retrieval highlights their computational equivalence.
This attention-retrieval equivalence creates a technical avenue for leveraging advances from deep hashing and ANN search, positioning DASH-KV as a new computational primitive for scalable Transformer inference.
DASH-KV Framework
DASH-KV comprises three distinct stages: asymmetric query/key hashing, Hamming space relevance matching, and a dynamic mixed-precision filtering mechanism.
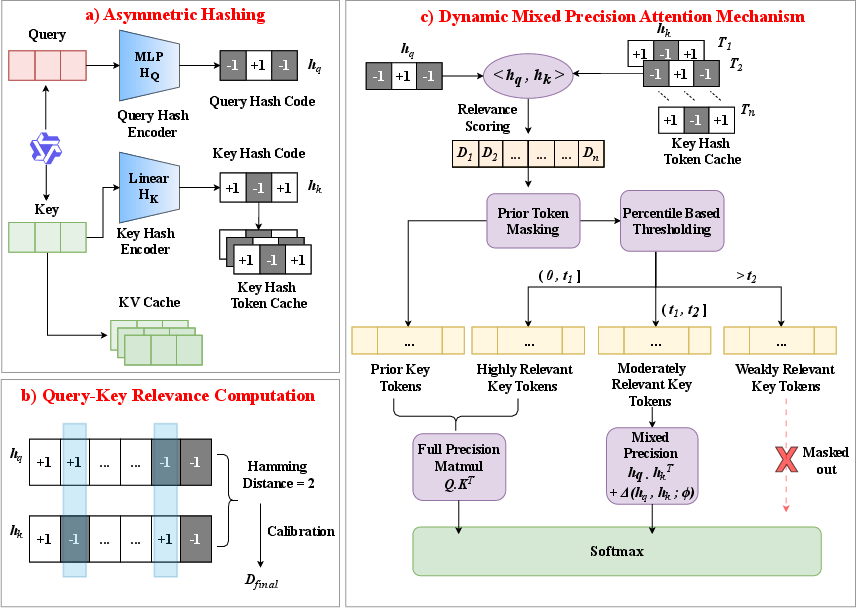
Figure 2: Overview of DASH-KV, detailing the asymmetric hashing, Hamming-based candidate filtering, and dynamic mixed-precision computation pipeline.
Asymmetric Hashing
The architecture employs disparate query and key encoders to satisfy the heterogeneous requirements of dynamic (query) and static (key) token representations. The query-side uses a deep, lightweight MLP to maximize semantic retention while maintaining low latency. The key-side employs a linear projection optimized for one-pass, low-overhead encoding consistent with high reuse in the KV cache. Binarization leverages an annealed tanh for trainability, collapsing to sign-based hashing at inference. This design is motivated by the observed geometric and magnitude mismatch between query and key distributions.
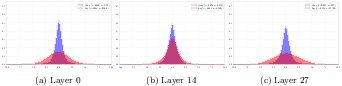
Figure 4: Visualization of distributional characteristics of queries and keys supports asymmetric hash encoding.
Layer-wise Asymmetry
Empirical analysis demonstrates severe distributional drift of both queries and keys across Transformer layers. Layer-specific hash functions are essential for preserving high recall and minimizing quantization error; a symmetric or globally shared hash function exhibits rapid recall degradation between disjoint layers.
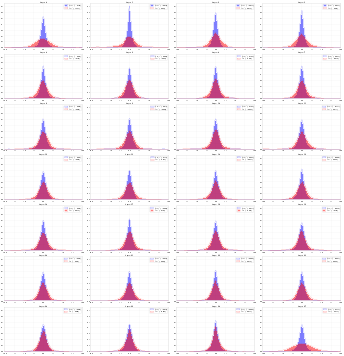
Figure 6: T-SNE projection of query/key activation distributions across layers reveals pronounced geometric manifold shifts.
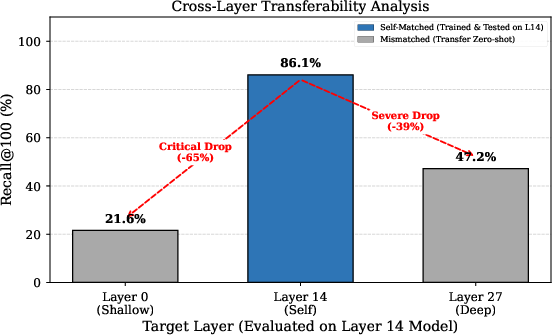
Figure 3: Layer transfer ablation showing that cross-layer hash code transfer severely degrades retrieval recall, justifying layer-wise trained encoders.
Hamming Space Relevance Computation
For each query token, DASH-KV computes Hamming distances to all cached key hashes, exploiting efficient bitwise operations (XOR, POPCNT). Multi-head and cross-layer calibration is incorporated to fuse spatial (head voting) and temporal (layer-momentum) priors, increasing robustness of candidate selection. Final per-key relevance is modulated by these adaptive corrections.
Dynamic Mixed-Precision Attention
DASH-KV applies a percentile-based gating mechanism: top-relevance tokens undergo full-precision attention, mid-tier candidates are attended with a "hash + residual" correction MLP, and low-relevance keys are dynamically masked from computation, not purged from storage. This scheme enacts instance-wise, fine-grained adaptation between computational cost and result fidelity, with critically important tokens (e.g., control, aggregation, named entities) always processed in full float.
Systematic evaluation on the LongBench suite, using Qwen2-7B, Llama-3.1-8B, and Qwen2.5-14B, establishes that DASH-KV:
- Achieves parity with full attention (dense) baselines across question-answering, multi-hop reasoning, and summarization tasks, while linearizing time and space complexity.
- Consistently outperforms SOTA eviction (StreamingLLM, H2O) and retrieval (SnapKV) baselines by large F1 and EM margins, especially in scenarios dependent on long-range context preservation.
- Realizes substantial latency reductions (up to 1.7× per-token speedup and strong Recall@100 improvements) versus naive LSH or symmetric hashing, as demonstrated in component ablations.
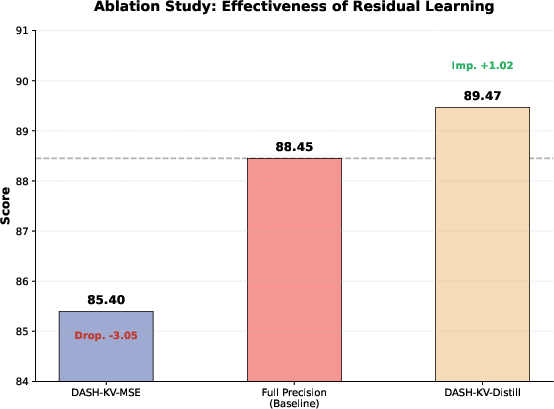
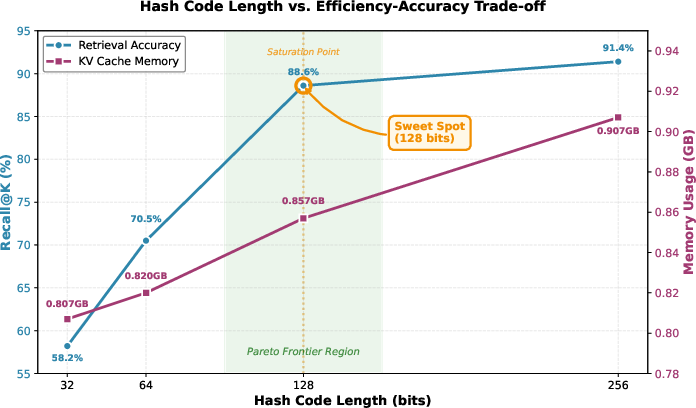
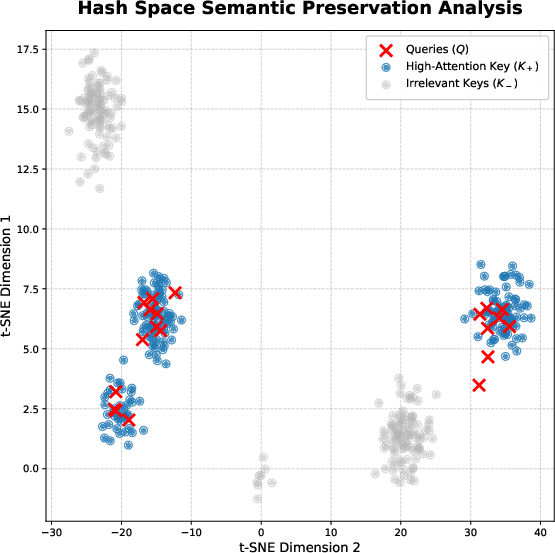
Figure 5: Ablation study on TriviaQA F1 showing that knowledge distillation in the residual module is critical for maintaining performance post-binarization.
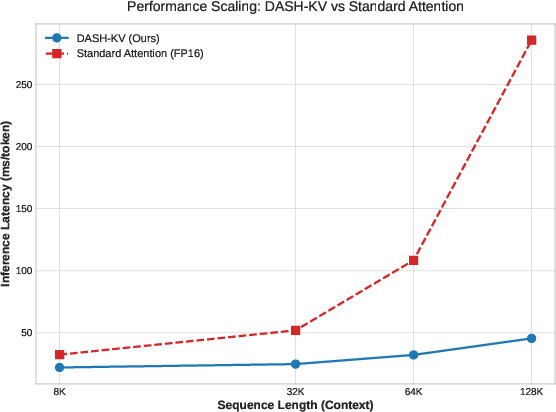
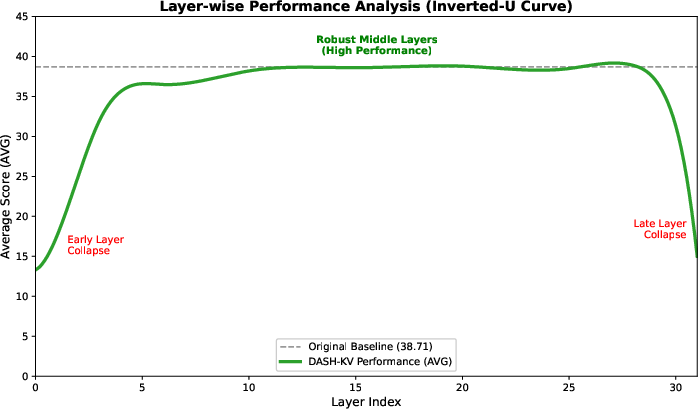
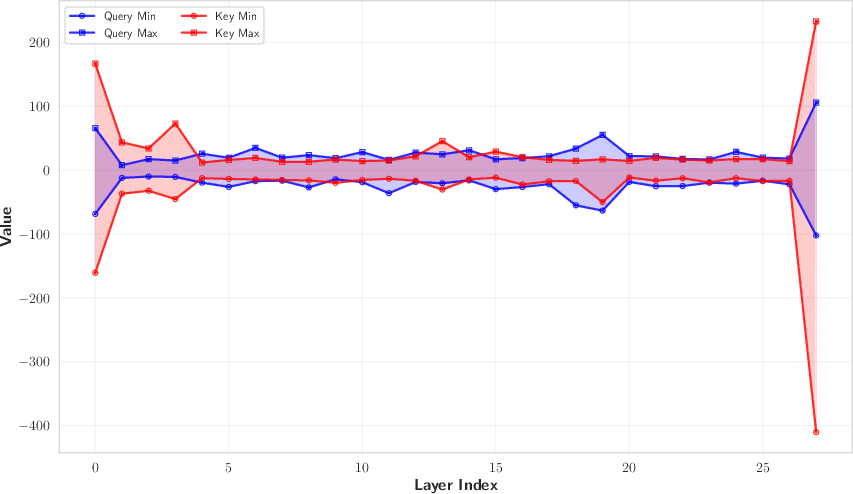
Figure 7: Latency scaling curves confirming DASH-KV’s ability to achieve linear time with context length expansion.
Analysis
Residual Learning for Quantization Correction
Inclusion of a residual MLP to refine similarity scores post-hashing is demonstrated to be mandatory for correcting the “magnitude-blindness” inherent in pure binary encoding—critical in later layers with heavy-tailed value distributions. KL-based distributional distillation, rather than MSE, provides strong generalization across different sequence lengths and enables length extrapolation, as average F1 increases with distillation rather than pointwise regression.
Layer Sensitivity and Deployment
Layerwise sensitivity analysis demonstrates an inverted-U profile. Early and late Transformer layers are intolerant to approximation and replacement with DASH-KV leads to catastrophic performance collapse. Middle layers, however, can be substituted wholesale without significant accuracy loss, justifying a “sandwich” deployment pattern: preserve full attention at extremities, compress in the core.
Hash-Based Retrieval as a New Attention Primitive
Extensive scaling and ablation studies confirm that when end-to-end hash retrieval is deployed, scalable and memory-efficient generation is possible, where efficiency-accuracy tradeoff can be flexibly tuned via the percentile thresholds and residual capacity. The semantic preservation of hash clusters is visually confirmed, supporting theoretical equivalence to full-precision attention for top-k candidates as context windows grow.
Implications and Future Directions
The DASH-KV framework has substantial implications for theoretical modeling of memory-bounded LLMs and for deployment of foundation models in production environments with ultra-long context requirements. It demonstrates that bit-parallel data structures and ANN search, long standard in retrieval, can enable major computational gains in autoregressive modeling without loss of expressive fidelity if properly supervised, asymmetric, and layer-local hash encoders are constructed.
Practically, further efficiency gains are foreseen via custom GPU kernels for native 1-bit bitwise computation, specialized cache layouts, and hardware-aware scheduling, as suggested by the measured equivalence between simulated (FP16) and theoretical (binary) results. Sparser, adaptive, or hybrid attention beyond existing schemes is immediately enabled by this framework’s orthogonality to full or windowed dense attention. The layerwise decoupling and dynamic residual allocation point to more general strategies for mixed-precision and hierarchical routing in future LLM architectures.
Conclusion
DASH-KV proposes and validates a new family of linear-time attention mechanisms via asymmetric, layerwise, deep hash encoding and Hamming space retrieval, with dynamic mixed-precision correction. It conclusively breaks the long-standing efficiency-accuracy bottleneck in long-context LLM inference, outperforming state-of-the-art alternatives on stringent benchmarks, and provides a basis for further theoretical and practical compression advances in Transformer architectures.