Attention Is All You Need for KV Cache in Diffusion LLMs
Abstract: This work studies how to adaptively recompute key-value (KV) caches for diffusion LLMs (DLMs) to maximize prediction accuracy while minimizing decoding latency. Prior methods' decoders recompute QKV for all tokens at every denoising step and layer, despite KV states changing little across most steps, especially in shallow layers, leading to substantial redundancy. We make three observations: (1) distant ${\bf MASK}$ tokens primarily act as a length-bias and can be cached block-wise beyond the active prediction window; (2) KV dynamics increase with depth, suggesting that selective refresh starting from deeper layers is sufficient; and (3) the most-attended token exhibits the smallest KV drift, providing a conservative lower bound on cache change for other tokens. Building on these, we propose ${\bf Elastic-Cache}$, a training-free, architecture-agnostic strategy that jointly decides ${when}$ to refresh (via an attention-aware drift test on the most-attended token) and ${where}$ to refresh (via a depth-aware schedule that recomputes from a chosen layer onward while reusing shallow-layer caches and off-window MASK caches). Unlike fixed-period schemes, Elastic-Cache performs adaptive, layer-aware cache updates for diffusion LLMs, reducing redundant computation and accelerating decoding with negligible loss in generation quality. Experiments on LLaDA-Instruct, LLaDA-1.5, and LLaDA-V across mathematical reasoning and code generation tasks demonstrate consistent speedups: $8.7\times$ on GSM8K (256 tokens), $45.1\times$ on longer sequences, and $4.8\times$ on HumanEval, while consistently maintaining higher accuracy than the baseline. Our method achieves significantly higher throughput ($6.8\times$ on GSM8K) than existing confidence-based approaches while preserving generation quality, enabling practical deployment of diffusion LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making a new kind of LLM (called a diffusion LLM, or DLM) much faster without hurting its accuracy. The authors introduce a method called Elastic-Cache that decides smartly when and where to reuse past computations and when to redo them. The goal is to keep answers high-quality while cutting waiting time during generation.
What questions does the paper ask?
- Can we avoid recomputing the same stuff over and over when a diffusion LLM writes text?
- If we must recompute, can we do it only in the parts of the model that actually changed?
- Can we use the model’s own attention (what it “looks at”) to tell us when something really changed?
How does the method work? (Explained simply)
First, a few ideas in everyday language:
- Attention: Imagine the model as a student writing an essay. At each step, the student looks back at notes (previous words) to decide what to write next. “Attention” is which notes the student looks at the most.
- KV cache (Key-Value cache): Think of the model’s notes as sticky notes with labels (keys) and summaries (values) for each word. Storing these notes saves time because you don’t rewrite them from scratch each step.
- Diffusion LLMs: Unlike regular models that write one word at a time, diffusion models start with a blank sentence (MASKs) and fill it in gradually over several “cleanup” rounds. Because all words can influence each other in each round, the sticky notes can go stale and may need updates.
The problem: Standard diffusion decoders recompute every sticky note for every word and every layer, at every round. That’s slow and often unnecessary because many notes barely change between rounds.
The key insights behind Elastic-Cache:
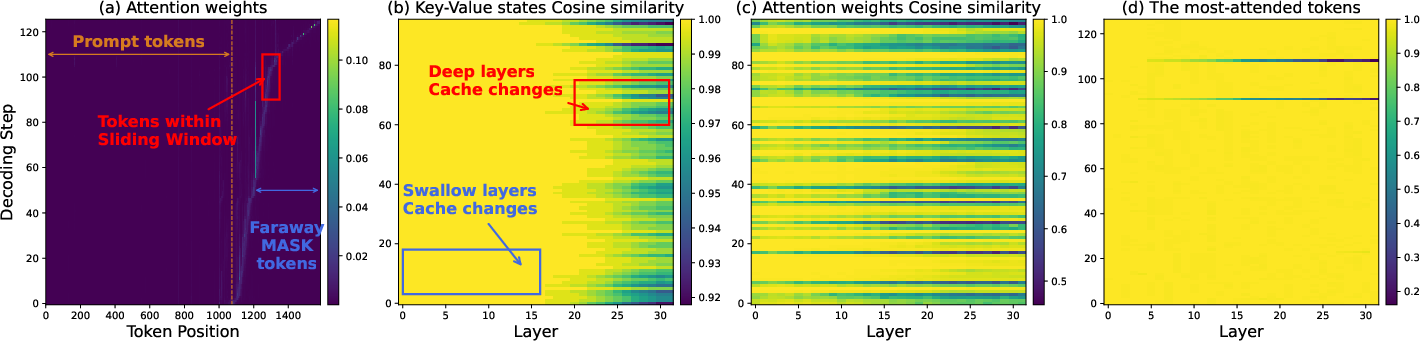
- Far-away MASKs don’t matter much right now: MASK tokens that are far from the current focus mostly act like a “length hint” rather than changing the actual words. So their sticky notes can be safely reused (cached) without constant updates.
- Shallow vs. deep layers: Early (shallow) layers settle down quickly (they capture basic patterns), while deeper layers keep changing more (they capture meaning). So it’s wasteful to refresh everything—focus updates on deeper layers first.
- Follow the most-looked-at token: The token that gets the most attention tends to change the least. If even that “most-watched” token starts to change, it’s a strong signal that others have changed too. So track its change as a lightweight alarm.
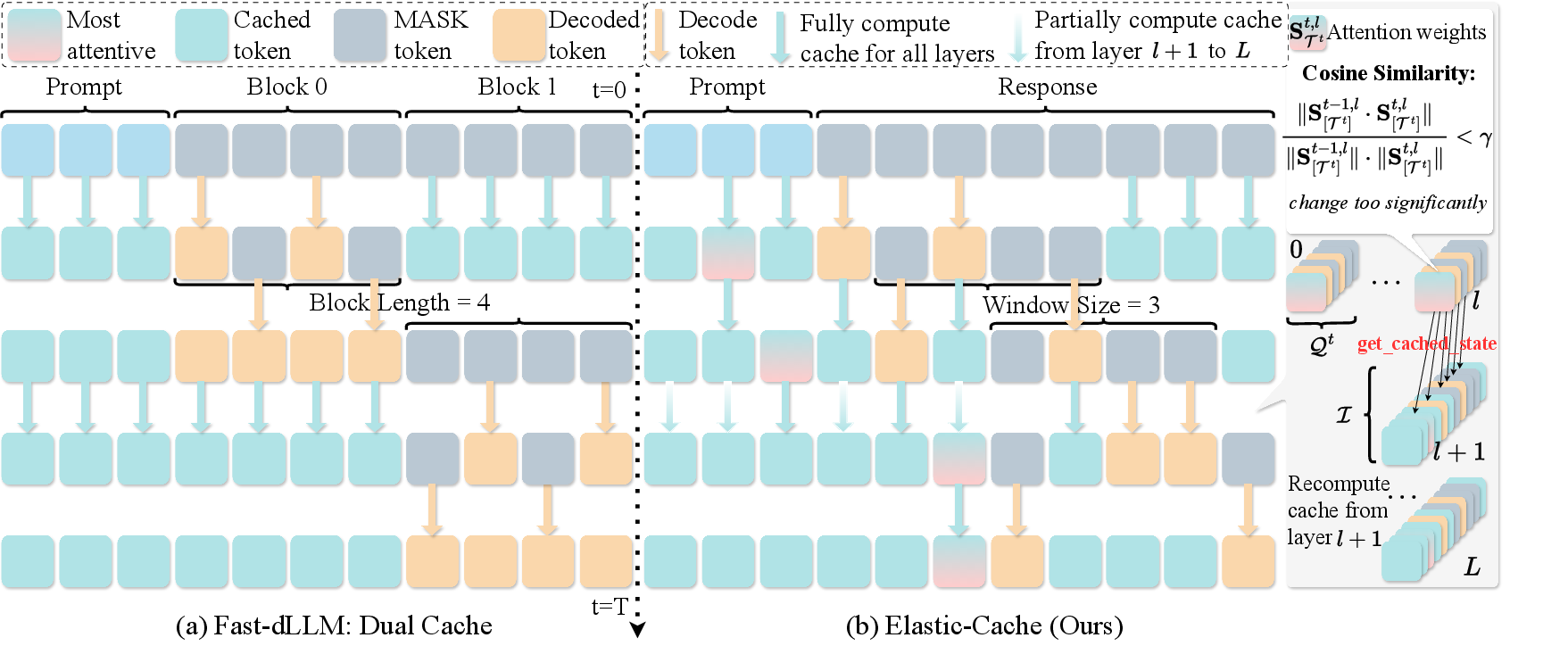
What Elastic-Cache does, step by step:
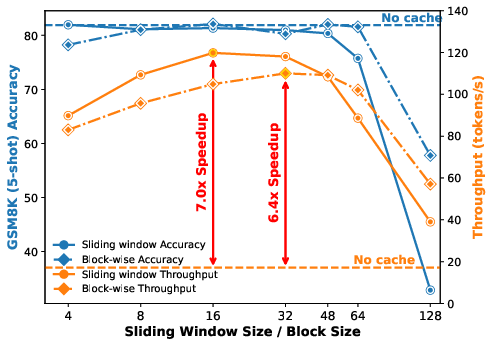
- Sliding window: Instead of looking at all MASKs at once, the model concentrates on a small window of nearby MASKs (like focusing on a paragraph rather than the whole book). Tokens outside the window keep their cached notes.
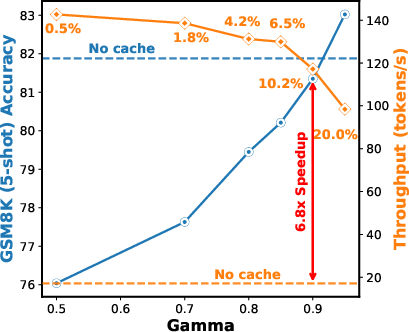
- Attention-aware trigger: At each round, Elastic-Cache checks how much the attention patterns for the “most-attended token” have changed compared to the last round. It uses a similarity score (cosine similarity)—think of it as a number that says “how similar are these two attention snapshots?” If similarity drops below a threshold, it’s time to refresh.
- Layer-aware refresh: When a refresh is needed, the method starts recomputing from a specific deeper layer onward, while reusing the shallower layers’ cached notes that likely didn’t change much.
- Training-free and model-agnostic: This is a plug-in strategy—you don’t retrain the model or change its architecture.
In short, instead of refreshing everything every time, Elastic-Cache refreshes only when attention signals say “things really changed,” and only in the deeper layers where it matters most.
What did they find?
Across math and coding benchmarks, Elastic-Cache made decoding much faster while keeping accuracy the same—or sometimes better:
- Big speedups: up to about 45× faster on longer text, around 9× on GSM8K (math word problems) with moderate length, and about 4.8× on HumanEval (coding).
- Strong accuracy: It matched or beat the baseline model’s accuracy in many cases (for example, it maintained accuracy on GSM8K at longer lengths while being up to 45× faster).
- Better throughput than previous accelerations: Compared to confidence-based methods (like Fast-dLLM), it achieved notably higher tokens-per-second while preserving quality.
Why this matters: Faster decoding means less waiting for users and lower compute cost. It also brings diffusion LLMs—known for flexible, parallel generation—closer to being practical in real apps.
Why is this important?
- Practicality: Diffusion LLMs are promising but can be slow. Elastic-Cache makes them much faster without retraining, so they’re easier to deploy.
- Efficiency: Less unnecessary recomputation saves time, energy, and money.
- General idea: Using attention as a guide to decide “when to update” and using depth to decide “where to update” is a smart strategy that could inspire similar speedups in other models.
- Scalability: The method works across text and multimodal tasks (e.g., math with images), and it scales well to longer generations due to the sliding window and selective refresh.
Takeaway
Elastic-Cache turns KV caching into an attention-guided control problem: attention tells you which tokens matter, a similarity test tells you when things have changed enough to refresh, and a depth-aware plan tells you where to refresh. This cuts a lot of wasted work, giving big speed boosts with little to no loss in quality—making diffusion LLMs far more practical for real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains uncertain, missing, or unexplored in the paper. Each point is framed so that future researchers can act on it.
- Lack of theoretical guarantees: no formal proof or bounds linking attention-weight cosine similarity to actual KV drift (per layer/head), nor a proof that the “most-attended token” provides a conservative lower bound on KV changes across the context.
- Head-wise variability is unaddressed: the method operates per layer but ignores multi-head heterogeneity; it remains unclear whether a single “most-attended token” per layer reliably captures drift across all heads.
- Failure modes when attention is miscalibrated: no analysis of cases where attention is noisy, diffuse, or misaligned (e.g., adversarial prompts, long-range dependencies), potentially triggering false positives/negatives in cache refresh decisions.
- Generality across diffusion architectures: despite claiming architecture-agnostic behavior, evaluation is limited to LLaDA variants; applicability to other DLM families (e.g., RADD, Dream-7B), different attention implementations, or encoder–decoder diffusion remains untested.
- Multimodal specifics: Elastic-Cache is applied to LLaDA-V without detailing how cross-attention between modalities is cached/refreshed; impact on image-token KV drift, cross-attention patterns, and multimodal window selection is not analyzed.
- Sliding-window policy design: window selection is fixed to the leftmost masked positions; it is unknown whether adaptive window positioning/size (β) based on attention or uncertainty would outperform static policies across tasks and sequence structures.
- MASK token length-bias assumption: the claim that distant MASK tokens mainly act as length prior lacks task- and dataset-level validation on long-range reasoning (e.g., algorithms, global constraints in code), multilingual texts, or discourse-heavy generation.
- Automatic thresholding: γ (attention-change threshold) is tuned via ablation, but no method exists to adapt γ per instance, per layer, or over time (e.g., using calibration, bandits, or RL) to optimize a joint accuracy–latency objective.
- Refresh boundary learning: the paper references a “boundary layer” ℓ⋆ but does not actually learn it; an open question is whether a learned or predictive schedule (e.g., lightweight meta-controller) can choose the start layer and refresh depth more effectively.
- Overhead accounting: the “lightweight” cost of drift testing (computing and storing attention matrices S, tracking most-attended tokens per layer, and maintaining extra hidden states H) is not quantified in FLOPs, memory bandwidth, or latency.
- Memory footprint and scalability: Elastic-Cache stores KV and certain hidden states for selective refresh; the memory trade-offs and limits on smaller GPUs (e.g., 24–48 GB), longer contexts (≥4k tokens), or multi-batch throughput are not reported.
- Hardware generalization: all results are on a single A100 80GB; performance and efficiency across diverse hardware (consumer GPUs, TPUs, multi-GPU/CPU setups) and with different BLAS/attention kernels remain unknown.
- Comparisons to dynamic KV baselines: the evaluation focuses on Fast-dLLM; direct head-to-head comparisons with other diffusion KV strategies (e.g., dKV-Cache) under matched settings are missing.
- Robustness across domains and languages: tasks are math/code-heavy; behavior on open-ended, multi-sentence generation, dialogue, multilingual corpora, and safety-critical outputs has not been studied.
- Long-context behavior: testing tops out at 1024 tokens; how speed/accuracy trade-offs evolve for 2k–8k+ contexts (where distant tokens may matter more) is not characterized.
- EOS/termination effects: the paper notes LLaDA’s tendency to emit EOS early affecting β choices; a systematic control or mitigation (e.g., EOS-aware refresh policy) is not provided.
- Interaction with decoding strategies: Elastic-Cache is combined with confidence-aware decoding (ε), but joint optimization of ε and γ, or integration with other parallel decoding/infill policies, is not explored beyond small ablations.
- Alternative drift signals: only attention cosine similarity is used; evaluation of other signals (e.g., Q/K/V norm changes, KL divergence of attention distributions, hidden-state deltas, per-head entropy) and their false positive/negative rates is missing.
- Quality beyond pass@1: accuracy metrics are primarily pass@1; analysis of robustness, diversity, error types, and pass@k (especially for code) under different γ/β schedules is absent.
- Practical deployment metrics: energy consumption, memory bandwidth savings, and end-to-end latency in real applications (interactive infilling, streaming, server batching) are not measured, despite claims of reduced memory traffic.
Practical Applications
Summary
The paper introduces Elastic-Cache, a training-free, architecture-agnostic inference strategy for diffusion LLMs (DLMs) that adaptively refreshes key–value (KV) caches. It uses three ideas: (1) block-caching distant MASK tokens outside an active sliding window, (2) depth-aware recomputation starting from layers with higher KV drift, and (3) an attention-aware drift trigger based on the most-attended token to decide when to refresh. Across LLaDA, LLaDA-1.5, and LLaDA-V, Elastic-Cache delivers large speedups (up to 45×) with minimal or no accuracy degradation on math and code benchmarks.
Below are practical applications grounded in the paper’s findings, organized by immediacy and sector, with assumptions and dependencies noted.
Immediate Applications
These can be deployed now with modest engineering effort in inference stacks for DLMs.
- Cloud inference acceleration for DLM-backed services
- Sectors: software, education, finance, customer support.
- What: Integrate Elastic-Cache into serving stacks for DLM-based chat, tutoring, and coding services to reduce latency and increase throughput (tokens/sec), especially for longer outputs.
- Tools/workflows: PyTorch/Triton kernels implementing sliding-window KV reuse; plugins for inference servers (e.g., vLLM-like or TGI-like engines) that expose a “drift-aware cache policy”; MLOps dashboards for per-request drift/refresh stats.
- Assumptions/dependencies: Underlying models are DLMs with bidirectional attention; access to attention matrices and KV states at inference; tuning of
gamma(drift threshold) andbeta(window size) per domain/hardware.
- Cost and energy reduction in production inference
- Sectors: cloud platforms, enterprise IT.
- What: Lower GPU-hours per request and improve SLA adherence by skipping redundant recomputation during stable denoising phases.
- Tools/workflows: Capacity planning models that incorporate adaptive refresh rates; autoscaling policies keyed to observed drift update frequency.
- Assumptions/dependencies: Savings depend on output length distribution; measured on A100 80GB—benefits vary with hardware, batch sizes, and kernel optimizations.
- Faster code assistants and IDE integrations using DLMs
- Sectors: software engineering.
- What: Speed up code completion, infill, and patch generation in IDEs when using DLMs (e.g., LLaDA variants), improving developer responsiveness for long edits.
- Tools/workflows: IDE plugins (VS Code, JetBrains) backed by Elastic-Cache-enabled DLM servers or high-end workstations.
- Assumptions/dependencies: Stable accuracy on code-generation tasks as shown (HumanEval, MBPP); careful threshold tuning to avoid subtle regressions on edge cases.
- Multimodal STEM tutors and math solvers
- Sectors: education, EdTech.
- What: Enhance throughput for LLaDA-V-like multimodal math reasoning (MathVista/MathVerse), enabling more concurrent sessions or faster interactive feedback.
- Tools/workflows: Classroom or homework-helper apps with on-demand reasoning bursts; queueing systems that leverage increased tokens/sec.
- Assumptions/dependencies: DLMs used in the application (not AR LLMs); image-text pipelines expose attention for drift computation.
- Long-form writing and document infilling
- Sectors: productivity tools, publishing, legal/finance documentation.
- What: Use sliding-window cache reuse for localized masked spans to accelerate iterative infill, redaction, or style-transfer workflows in DLMs.
- Tools/workflows: Document editors with “smart infill” that iteratively unmasks sections; batch infill pipelines for templates/contracts.
- Assumptions/dependencies: Tasks compatible with masked diffusion decoding; careful
betaselection to balance locality and compute.
- Research acceleration and evaluation pipelines
- Sectors: academia, industrial research.
- What: Cut wall-clock time for benchmarks (GSM8K, MATH, HumanEval) and ablations by 5–45×, enabling broader sweeps and faster iteration.
- Tools/workflows: lm-eval-harness integrations; experiment tracking for drift-trigger rates vs. accuracy; ablation tooling to scan
gamma/beta. - Assumptions/dependencies: Comparable results outside the paper’s models; standardized attention export in research codebases.
- Privacy-friendly on-prem and workstation deployments
- Sectors: healthcare, legal, finance, public sector.
- What: Make small/medium DLMs more practical on single high-memory GPUs for sensitive data by reducing inference compute and memory traffic.
- Tools/workflows: On-prem inference services with Elastic-Cache; audit logs of cache updates in regulated environments.
- Assumptions/dependencies: Accuracy validated on domain-specific corpora; governance requires robust evaluation before production.
- Observability and adaptive decoding control
- Sectors: MLOps/DevOps for ML.
- What: Use the most-attended-token drift statistic as a lightweight signal to adapt decoding policies (e.g., increase confidence threshold, trigger verification).
- Tools/workflows: Drift dashboards; hooks to increase compute when
sigmafalls belowgamma; alerts for anomalous drift spikes. - Assumptions/dependencies: Access to per-layer attention; minimal overhead to compute cosine similarities at runtime.
Long-Term Applications
These require further research, ecosystem integration, or hardware/runtime co-design.
- Standardization of adaptive KV management for iterative decoders
- Sectors: ML frameworks, inference platforms.
- What: Establish new APIs in major inference libraries (e.g., TensorRT-LLM, vLLM) for adaptive, layer-aware cache refresh, including attention-exposed kernels and partial recompute plans.
- Dependencies: Community convergence on DLM interfaces; portable kernel implementations; robust CI to guard accuracy.
- Hardware and compiler co-design for drift-aware decoding
- Sectors: semiconductors, systems software.
- What: Accelerators and compilers that natively support partial KV refresh, on-chip attention drift computation, and depth-selective recompute to reduce memory bandwidth demands.
- Dependencies: Vendor support (NVIDIA/AMD/Apple/Qualcomm NPUs); ISA extensions or specialized kernels; profiling-guided scheduling.
- Auto-tuning and RL-based policies for cache updates
- Sectors: AutoML, platform optimization.
- What: Learn per-domain policies to set
gamma,beta, and layer boundariesl*, optimizing the accuracy/latency frontier dynamically per prompt/session. - Dependencies: Online telemetry, safe exploration, and guardrails; reward design tying latency, energy, and task-specific metrics.
- Safety- and uncertainty-aware decoding using drift signals
- Sectors: healthcare, legal, finance, content moderation.
- What: Use attention-drift spikes as a proxy for semantic revision/instability to trigger fallback strategies (e.g., slower full-refresh, external verification, human-in-the-loop).
- Dependencies: Validation that drift correlates with error/uncertainty across domains; policy design to avoid spurious triggers.
- Expansion to other iterative refinement models beyond DLMs
- Sectors: translation/editing, code repair, retrieval-editing.
- What: Apply attention-aware, depth-selective cache updates to non-diffusion iterative models (e.g., editor models, masked LM infilling, verifier-refiner loops).
- Dependencies: Access to attention maps; empirical study of KV drift patterns in alternative architectures.
- Edge and mobile integration for real-time assistants
- Sectors: consumer devices, automotive, robotics.
- What: With further optimizations and quantization, deploy small DLMs on NPUs for on-device assistants that perform local infill/reasoning loops with lower battery cost.
- Dependencies: Efficient kernels on NPUs; memory-constrained cache management; integration with multimodal sensors.
- Green AI policy and sustainability accounting
- Sectors: policy, ESG, data center operations.
- What: Use adaptive caching to reduce energy per token and inform procurement and reporting standards for iterative decoding models.
- Dependencies: Independent energy audits; standardized benchmarks capturing long-output behavior.
- Compositional decoding with other accelerations
- Sectors: platform engineering.
- What: Combine Elastic-Cache with confidence-aware decoding, speculative decoding for DLMs, or mixture-of-experts gating to push the Pareto frontier.
- Dependencies: Interference effects between methods; scheduler design across techniques; stability verification.
Cross-Cutting Assumptions and Dependencies
- Model scope: Benefits apply to diffusion LLMs (bidirectional attention with iterative denoising). Autoregressive LLMs already have invariant KV caches and do not need this mechanism.
- Implementation: Requires access to attention weights, hidden states, and KV caches at inference and the ability to modify kernels to support partial refreshes and sliding windows.
- Hyperparameters: Performance depends on tuning
gamma(attention-drift threshold) andbeta(sliding-window size); defaults (e.g.,gamma≈0.9) worked well in reported tasks but may need domain/hardware-specific tuning. - Hardware variability: Reported speedups are on NVIDIA A100 80GB; actual gains will vary with GPU/TPU/NPU capabilities, memory bandwidth, batching, and kernel quality.
- Accuracy guarantees: While accuracy was preserved or improved on tested benchmarks, safety-critical domains require additional validation and possibly more conservative thresholds.
- Ecosystem readiness: Broad deployment benefits from integration into mainstream inference libraries and serving frameworks, plus observability for drift metrics.
Glossary
- Absorbing-state discrete diffusion: A diffusion process over discrete tokens that transitions into a special absorbing MASK state during the forward noising process. "Masked Diffusion Models (MDMs), absorbing-state discrete diffusion, build on D3PM"
- Architecture-agnostic: A method that does not depend on specific model architectures and can be applied broadly. "a training-free, architecture-agnostic strategy that jointly decides"
- Attention-aware KV Cache Update: A mechanism that uses attention statistics to decide when to refresh cached key–value states. "couples Attention-Aware KV Cache Update with Layer-Aware KV Cache Update"
- Autoregressive Transformers: Models that generate sequences token-by-token, conditioning each token on previously generated ones. "have recently emerged as a compelling alternative to autoregressive Transformers"
- Bidirectional attention: An attention mechanism where all positions can attend to each other, not restricted by causal masks. "diffusion models employ bidirectional attention where all positions can attend to each other"
- Bidirectional dependencies: Mutual token dependencies across the sequence that cause representations to change when any token changes. "The bidirectional dependencies cause previously computed key-value pairs to become stale"
- Block-wise decoding: A strategy that processes tokens in fixed blocks, updating caches after each block. "block-wise decoding method caches the Key-Value of all tokens outside the current block"
- Block-wise MASK caching: Caching MASK token states in blocks outside the active prediction region to avoid redundant recomputation. "We develop block-wise MASK caching to eliminate needless updates outside the prediction window."
- Causal attention: An attention pattern restricting tokens to attend only to earlier positions, enabling invariant KV caching. "In causal attention, each layer projects the current hidden state"
- Confidence-aware decoding: A decoding scheme that only unmasks tokens whose confidence exceeds a threshold to enable more parallel prediction. "We employ confidence-aware decoding strategies from Fast-dLLM"
- Cosine similarity: A metric measuring directional similarity between vectors, used here to detect attention drift. "using cosine similarity."
- D3PM: A framework for discrete diffusion probabilistic models underlying the masked diffusion formulation. "build on D3PM"
- Diffusion LLMs (DLMs): LLMs that generate sequences via iterative denoising steps rather than autoregressive sampling. "Diffusion LLMs (DLMs) have recently emerged as a compelling alternative"
- dKV-Cache: A prior caching approach for diffusion models that recognizes evolving token representations under bidirectional attention. "As noted by dKV-Cache, token representations in diffusion models evolve dynamically"
- Elastic-Cache: The proposed adaptive KV caching policy that refreshes caches based on attention drift and layer depth. "we propose Elastic-Cache, a training-free, architecture-agnostic strategy"
- Fast-dLLM: A block-based acceleration method for diffusion LLMs leveraging confidence-aware parallel decoding. "The fast-dLLM block-wise decoding method caches the Key-Value of all tokens outside the current block at each step."
- Key–Value (KV) cache: Stored key and value projections reused across decoding steps to avoid recomputation. "Key-Value (KV) caching"
- KV drift: The step-to-step change in cached key and value representations used to trigger updates. "We introduce KV drift as a principled signal for adaptive cache management."
- Layer-aware KV Cache Update: A policy that refreshes caches selectively from a boundary layer onward, focusing on deeper layers. "Layer-Aware KV Cache Update"
- Length-bias prior: An effect where distant MASK tokens mainly influence the model’s notion of sequence length rather than current content. "behave primarily as a length-bias prior"
- LLaDA-1.5: A variant in the LLaDA family of diffusion LLMs used for evaluation. "We evaluate Elastic-Cache on LLaDA-Instruct, LLaDA-1.5, and multimodal LLaDA-V"
- lm-eval-harness: A standardized evaluation toolkit for benchmarking LLMs. "We use lm-eval-harness"
- Masked Diffusion Models (MDMs): Diffusion models that replace tokens with MASK during the forward process and learn to reverse it. "Masked Diffusion Models (MDMs), absorbing-state discrete diffusion, build on D3PM"
- Parallel decoding: Generating multiple tokens simultaneously during diffusion steps. "enabling parallel decoding and flexible infilling."
- Prefill: The initial prompt content used before generation, whose length affects throughput. "Prefill and Generation Length."
- Reweighted cross-entropy: A training objective that weights masked positions to approximate the diffusion reverse process. "simplifies training from a variational bound to a reweighted cross-entropy over masked positions"
- Sliding window decoding: A scheme that focuses computation on a window of nearest masked tokens while reusing caches for distant ones. "sliding window decoding and KV cache"
- Throughput: The rate of token processing during decoding, typically measured in tokens per second. "Throughput is tokens/sec averaged until emitting, matching Fast-dLLM's protocol"
- Variational bound: A probabilistic training objective used in diffusion modeling, replaced here by a cross-entropy surrogate. "simplifies training from a variational bound to a reweighted cross-entropy"
Collections
Sign up for free to add this paper to one or more collections.

