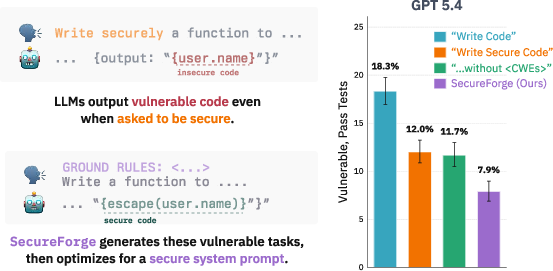
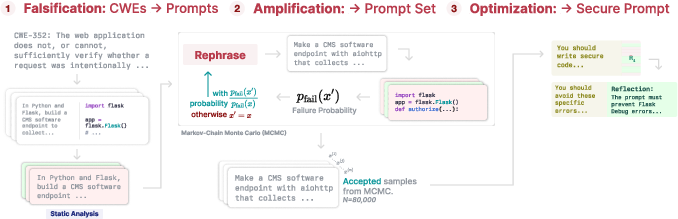
- The paper introduces a novel automated pipeline that combines benign prompt falsification, MCMC-based coverage amplification, and system prompt optimization to significantly reduce vulnerabilities in LLM-generated code.
- The paper presents robust evaluation metrics demonstrating up to 48% vulnerability reduction and improved joint security/correctness across various LLMs.
- The paper shows that an API-only, inference-time prompt hardening strategy can effectively mitigate security risks without compromising code functionality.
SecureForge: Automated Detection and Prevention of Vulnerabilities in LLM-Generated Code via Prompt Optimization
Motivation and Problem Setting
LLMs have dramatically expanded the scale at which code is automatically generated and deployed, introducing a critical security problem: models produce code that is functionally correct yet contains exploitable vulnerabilities. Unlike overt adversarial attacks, these weaknesses are often triggered by benign user interactions, and survive standard unit testing, entering production codebases undetected. Empirical analyses reveal that even when explicitly instructed to avoid known weaknesses like those in the MITRE CWE taxonomy, state-of-the-art LLMs yield statically verifiable vulnerabilities in up to 23% of outputs, with 12.7% of outputs passing all unit tests but remaining insecure (2605.08382).
Practical hardening methods for these scenarios remain limited. Existing approaches—ranging from fine-tuning to adversarial red-team prompting—require white-box model access or fail to comprehensively address the space of vulnerabilities induced by realistic, non-malicious user prompts. SecureForge addresses these deficits with a fully automated inference-time pipeline that both quantifies benign prompt-induced vulnerabilities and hardens any LLM to mitigate them, relying only on API access and static analysis.
Methodology
SecureForge comprises a three-stage, automated pipeline for LLM code security:
The pipeline details are summarized below:
Experimental Protocol and Evaluation
SecureForge is evaluated across both open and proprietary LLMs, including the GPT-5 scaling series, Claude Sonnet 4.6, and major open-source code models (Qwen2.5 Coder, CodeLlama, Kimi K2). The core evaluation metrics are:
- Vulnerability Rate: Empirical probability that a rollout from a benign prompt contains a statically-verifiable CWE.
- Test Passing Rate: Proportion of code rollouts passing auto-generated pytest suites for functional correctness.
- Joint Security/Correctness Rate: Rate at which rollouts are both secure (CWE-free) and pass all tests.
Evaluation includes held-out, non-overlapping CWE scenarios and in-the-wild coding prompts from the SWE-chat dataset, simulating authentic developer-agent coding workflows.
Key Results
Baseline Vulnerability and SecureForge Intervention
Simply prompting models to write secure, CWE-aware code leaves vulnerability rates above 13%, even for test-passing completions (Figure 3). SecureForge's optimized system prompts achieve up to 48% reduction in vulnerability rates on held-out scenarios, with unit test pass rates preserved or even improved across all tested models.
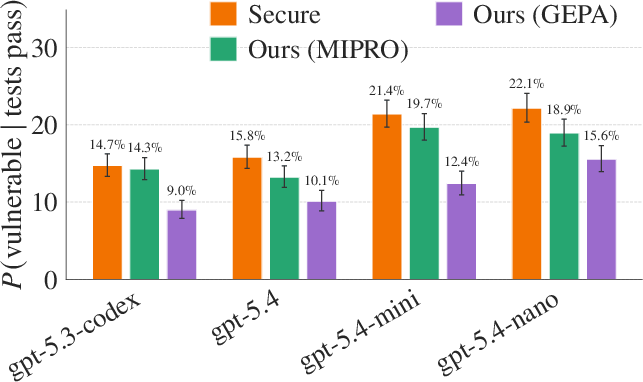
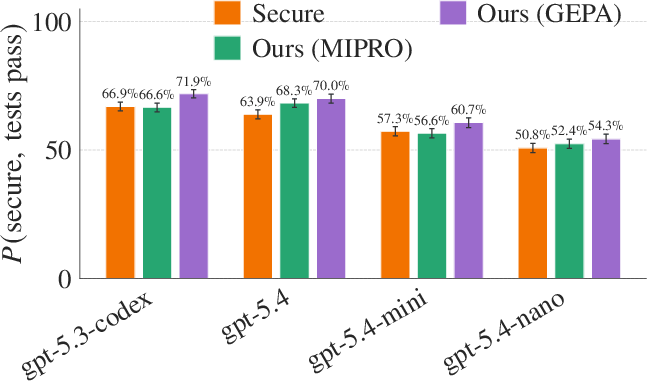
Figure 3: Left: Weakness rates for GPT models before intervention, after various securitization prompts, and after SecureForge. Right: Joint security/correctness rates—higher is better.
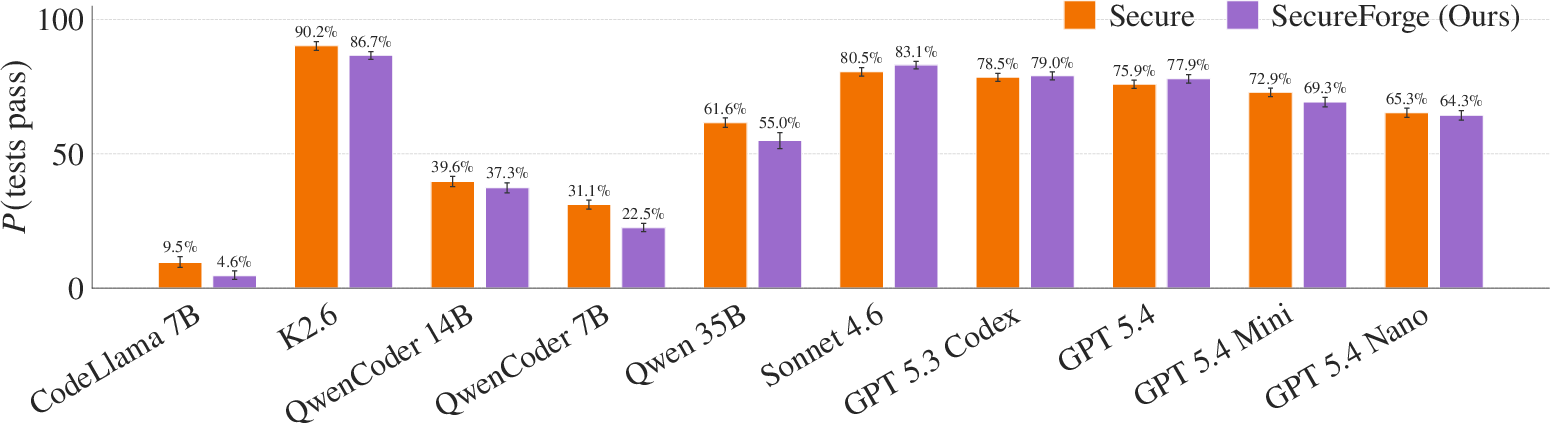
Figure 4: Top: Vulnerability rate reduction before and after SecureForge. Middle: Unit test passage remains stable or improves. Bottom: Joint rate of safe and correct code increases post-intervention.
Generalization to Real-World Coding Agents
The system prompts optimized via SecureForge transfer zero-shot to real-world SWE-chat prompts, enhancing joint security/correctness by up to 13.5% without exposure to such distributions during optimization (Figure 5). This demonstrates both the robustness of the MCMC-based corpus and the breadth of coverage conferred by static-analysis-guided prompt optimization.
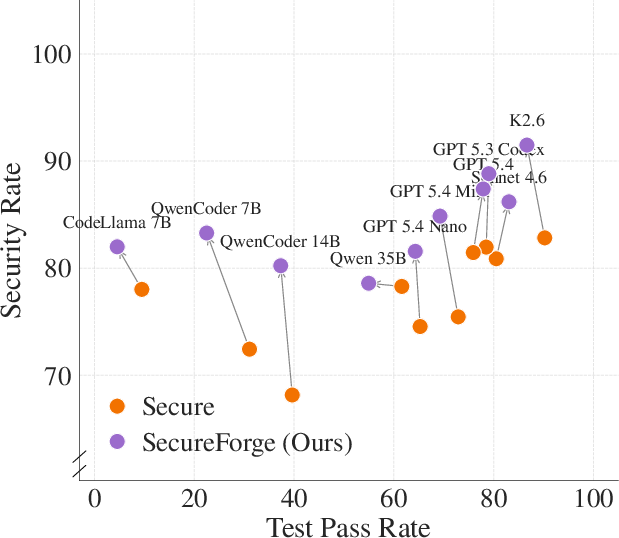
Figure 5: SecureForge's effect on real in-the-wild SWE-chat coding tasks, showing up to 13.5% improvement in safe-passing code generation.
Comparison to Other Prompt Optimization Techniques
Against MIPRO and security-aware prompting, SecureForge's use of static analysis in the optimization objective consistently yields lower vulnerability rates and higher joint success on diverse coding scenarios (Figure 6).
Figure 6: SecureForge's GEPA-based optimizer outperforms security-aware prompting and MIPRO on both vulnerability rate and joint secure/correct output rate.
Ablation, Analysis, and Broader Implications
- Coverage and Diversity: The MCMC amplification produces a highly diverse prompt corpus, with only marginal increases in code output homogeneity (as measured by Self-BLEU). Amplification discovers roughly twice as many unique vulnerable scenarios relative to simplistic rephrasing strategies.
- Effect Uniformity: Vulnerability reduction is broadly uniform across CWEs, with some holdout in code injection and authentication design, highlighting persistent open challenges.
- Severity Mitigation: Reduction in vulnerabilities is preserved across Semgrep's severity spectrum (Figure 7), and SecureForge also reduces vulnerabilities in rollouts that initially fail functional tests.
- Practicality: System prompt optimization incurs only a modest one-time compute cost (∼$150 for mainstream LLMs), is reproducible via open-source tooling, and does not require model weight access or retraining.
Implications and Future Directions
Theoretical and practical implications are multifaceted:
- For Model Providers: SecureForge enables API-only, inference-time hardening of code models, aligning with secure-by-design mandates while avoiding disruptive distribution shifts or high-overhead fine-tuning cycles.
- For Practitioners: The open-source pipeline provides a mechanism for ongoing auditing and system prompt alignment, allowing rapid adaptation to new model variants or evolving CWE taxonomies.
- For Research: The empirical gap between security-aware prompting and statically-verified hardening highlights fundamental model limitations; future work could integrate SecureForge with dynamic analysis, multi-turn dialogue synthesis, multilingual settings, or direct integration into agent feedback loops.
Deployment at scale would directly mitigate the real-world risk of vulnerable code entering production via LLM coding agents, and the success of black-box methods underscores the continued value of modular, test-driven security pipelines over end-to-end retraining.
Conclusion
SecureForge demonstrates that automated, static-analysis-guided prompt optimization can significantly reduce vulnerabilities in LLM-generated code induced by benign user interactions. The approach yields strong, statistically robust gains—up to 48% reduced vulnerability rates—without sacrificing code quality or coverage, and generalizes effectively to real user environments. By requiring only API access and static analysis, SecureForge constitutes a practical, scalable solution for immediate enhancement of code security in deployed LLMs, while establishing a methodological foundation for future secure agentic AI systems.