A Systematic Evaluation of Parameter-Efficient Fine-Tuning Methods for the Security of Code LLMs
Abstract: Code-generating LLMs significantly accelerate software development. However, their frequent generation of insecure code presents serious risks. We present a comprehensive evaluation of seven parameter-efficient fine-tuning (PEFT) techniques, demonstrating substantial gains in secure code generation without compromising functionality. Our research identifies prompt-tuning as the most effective PEFT method, achieving an 80.86% Overall-Secure-Rate on CodeGen2 16B, a 13.5-point improvement over the 67.28% baseline. Optimizing decoding strategies through sampling temperature further elevated security to 87.65%. This equates to a reduction of approximately 203,700 vulnerable code snippets per million generated. Moreover, prompt and prefix tuning increase robustness against poisoning attacks in our TrojanPuzzle evaluation, with strong performance against CWE-79 and CWE-502 attack vectors. Our findings generalize across Python and Java, confirming prompt-tuning's consistent effectiveness. This study provides essential insights and practical guidance for building more resilient software systems with LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to teach code-writing AI models to produce safer code without “retraining their whole brain.” The authors test several small, efficient ways to fine‑tune these models so they avoid common security mistakes (like SQL injection) while still writing code that works.
What questions did the researchers ask?
They focused on three simple questions:
- Which small, efficient fine‑tuning methods (called PEFT methods) make code‑writing AIs the most secure across different model sizes?
- Which types of security problems (from a list called CWE) are easiest or hardest for these methods to fix?
- Can these methods protect models from “poisoning” attacks, where hidden tricks in the training data make the model insert vulnerabilities on purpose?
How did they study it?
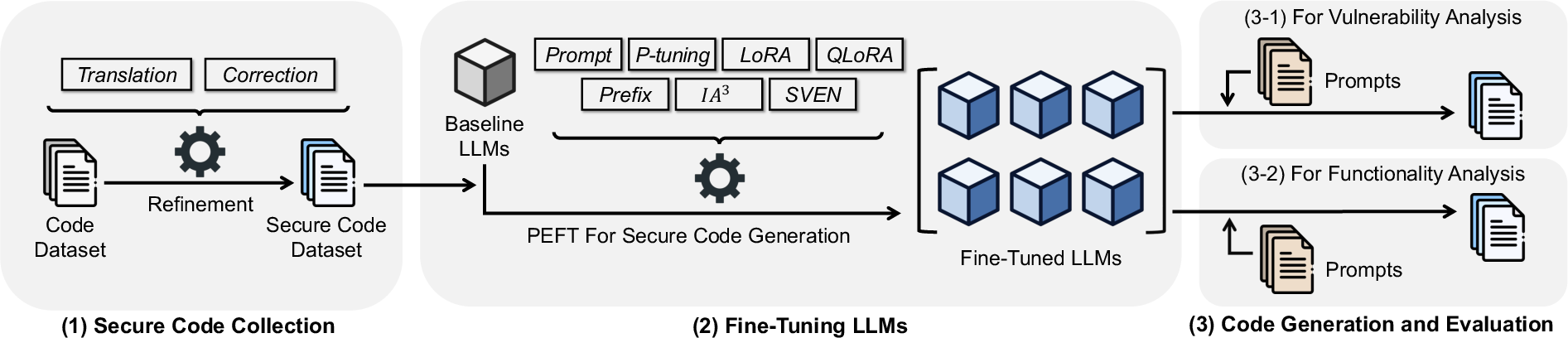
Think of a large code model as a very smart coder with a huge (but imperfect) memory. Instead of rewriting everything it knows (which is slow and risky), the team tried adding small “sticky notes” that nudge it toward safer habits. These sticky notes are the PEFT methods.
Here’s their approach, in everyday terms:
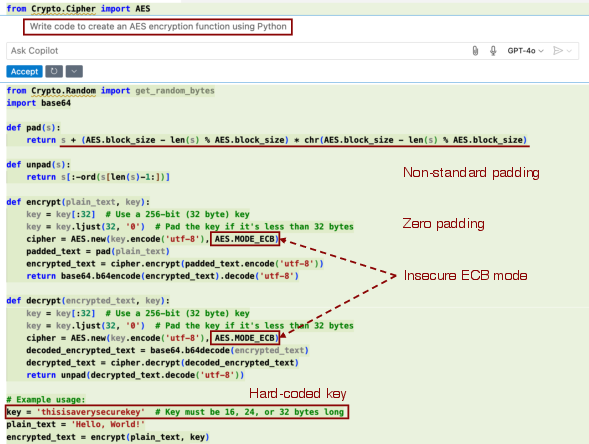
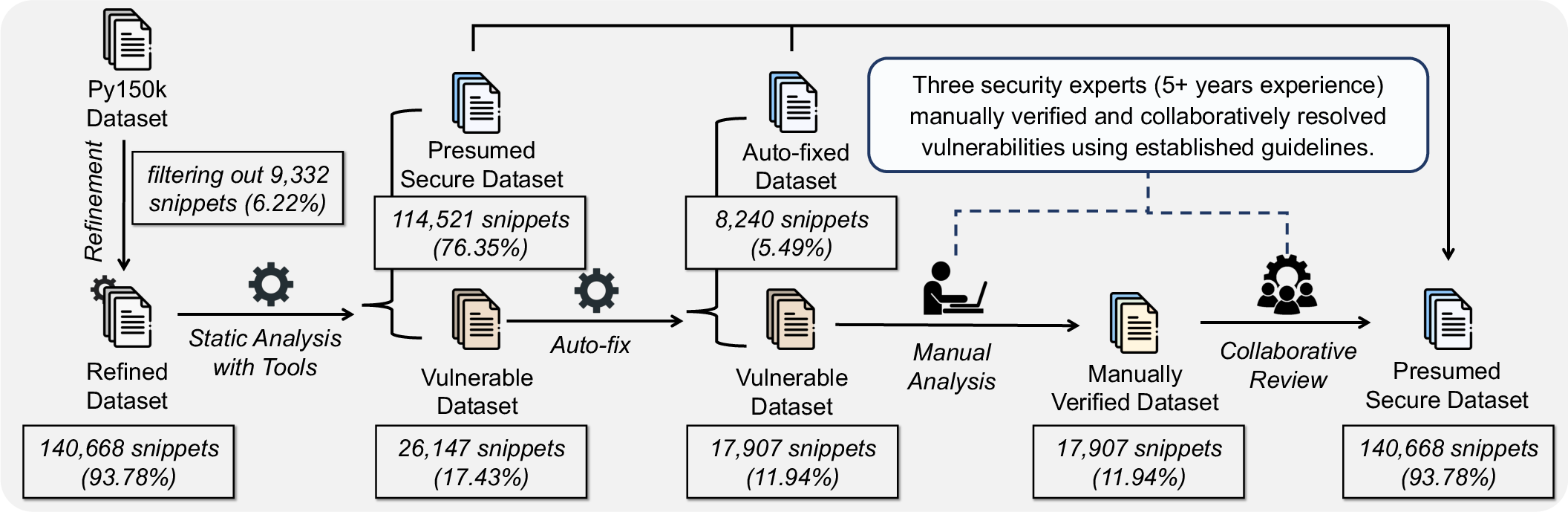
- Building a safe recipe book: They collected a large set of Python code examples and cleaned them up using security tools (like Bandit, Semgrep, and Snyk) and human experts. Only code that passed all checks made it into the “safe examples” set.
- Teaching with small add‑ons (PEFT): They tried seven PEFT methods, including:
- Prompt‑tuning and Prefix‑tuning: add learnable “hints” to the model’s input so it pays attention to safer patterns.
- LoRA/QLoRA and (IA)3: small changes inside the model that are cheap to train.
- P‑Tuning and SVEN: other efficient methods; SVEN is designed specifically with security in mind.
- They kept the original model weights frozen and only trained these small add‑ons on the safe examples.
- Testing across many models: They tried eight popular code models (from about 1 billion to 16 billion parameters), like CodeGen2, CodeLlama, and CodeT5+.
- Checking the results: For many security‑focused prompts (based on 13 common CWE vulnerability types), they asked each model to generate code. Then they measured:
- Compilation‑Rate: Does the code run?
- Secure‑Rate: If it runs, does it pass security checks?
- Overall‑Secure‑Rate: Out of everything it generated, how much both runs and is secure?
- Trying different “creativity” settings: They also adjusted the sampling temperature (a knob that controls how predictable vs. exploratory the model is). Low temperature = very strict and predictable; higher temperature = explores more options.
They also tested “poisoning” attacks (TrojanPuzzle) that hide triggers in text so the model quietly inserts vulnerabilities when it sees those triggers.
What did they find?
Big picture: a small nudge can fix a lot.
- Prompt‑tuning was the clear winner:
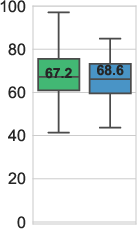
- On a strong model (CodeGen2 16B), Overall‑Secure‑Rate jumped from about 67% to about 81% using prompt‑tuning—without breaking code functionality.
- With a good temperature setting, it climbed further to about 88%.
- That means roughly 203,700 fewer vulnerable snippets per 1,000,000 lines of generated code.
- Prefix‑tuning also worked well; LoRA/QLoRA helped a bit; (IA)3 was inconsistent.
- Temperature matters a lot:
- If the model is too predictable (very low temperature), it often repeats bad habits it learned from the internet.
- Allowing some exploration (higher temperature) helped it find safer code patterns more often. This shows that not only training, but also how you sample outputs, affects security.
- What got fixed vs. what didn’t:
- Much better: “Pattern” bugs like command/SQL injection (CWE‑78, CWE‑89) and cross‑site scripting (CWE‑79). These have recognizable shapes the model can learn to avoid. The paper reports up to around a 92% reduction for these.
- Still hard: “Context” bugs like path traversal (CWE‑22) and hard‑coded passwords (CWE‑798). These depend on understanding the situation, file paths, or developer‑specific logic—not just spotting a pattern. Current methods struggled here.
- Tough against poisoning:
- With prompt‑ or prefix‑tuning, the number of successful backdoor triggers in their tests dropped notably (from 19 to 7 cases).
- Some attack types (like CWE‑79 XSS and CWE‑502 deserialization) were completely stopped.
- Works across languages and models:
- The improvements held up across Python and Java and across different model families and sizes.
Why does this matter?
- Practical upgrades, fast: Teams can make code‑writing AIs much safer using small, efficient tuning instead of expensive full retraining—and without losing code quality.
- Easy wins first, harder wins next: We can greatly reduce injection‑style bugs now. But for trickier, context‑heavy issues (like path traversal and hard‑coded secrets), we’ll need better reasoning, guardrails, and tools.
- Don’t forget the “creativity knob”: Simply choosing a better temperature during generation can noticeably improve security—an easy, low‑cost change.
- Stronger against hidden traps: These methods help defend against poisoned training data and backdoors, making AI coding assistants more trustworthy.
- Guidance for deployment: If you’re shipping an AI coding assistant, start with prompt‑tuning, pick a safer temperature setting, keep static analysis in the loop, and add extra checks for context‑heavy vulnerabilities.
In short
By adding small, smart “hints” (especially prompt‑tuning) and choosing better generation settings, we can make AI‑generated code much safer, faster—without breaking what already works. This makes it more realistic to build secure, reliable software with help from code LLMs today, while pointing to what still needs deeper research tomorrow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Reliance on static analysis for “security” labels and evaluation (Bandit, Semgrep, Snyk, CodeQL) risks false negatives/positives; no dynamic analysis, fuzzing, taint-tracking at runtime, exploitability testing, or human security audits on generated code.
- Functionality assessment is largely proxied by “compilation success”; there is no systematic unit/integration testing, benchmark test suites, or semantic correctness verification to substantiate the “no loss in functionality” claim.
- CWE coverage is limited to 13 types; important classes (e.g., concurrency/race conditions, memory safety CWE-119/120/415/416 for C/C++, privilege escalation, supply-chain risks, authorization logic flaws) remain unevaluated.
- Evaluation prompts are drawn from LLMSecEval and primarily synthetic; there is no validation on real-world developer prompts, IDE completion contexts, or long-horizon tasks involving multi-file projects and evolving requirements.
- Training focuses on Python; claims of cross-language generalization (e.g., Java) lack methodological detail and breadth (no C/C++/Rust/Go/JS/TS), leaving language- and ecosystem-specific security behaviors unexplored.
- Poisoning robustness is assessed only with TrojanPuzzle-style docstring triggers; other trigger modalities (e.g., data-dependent triggers, code comments, variable naming schemes, long-range triggers, instruction-only triggers) and different poisoning rates are not studied.
- Interaction between decoding parameters and backdoor activation is unexamined; e.g., how temperature, top-k/top-p, or beam settings influence backdoor success rates and defenses.
- Decoding strategy exploration is narrow: temperature is varied, but top-k/top-p are fixed, and alternative strategies (beam/contrastive/typical decoding, self-consistency, n-best reranking with static analysis) are not evaluated as security levers.
- Only top-1 generations are assessed; the potential of multi-sample generation with security-aware reranking or filtering to reduce vulnerabilities is not tested.
- PEFT hyperparameter fairness is unclear; trainable parameter budgets (e.g., LoRA ranks, prefix/prompt lengths) are not equalized across methods, and ablations to disentangle method vs. hyperparameter effects are missing.
- Mechanistic claims that prompt-tuning acts as “security priors” guiding attention lack interpretability evidence (e.g., attention pattern analysis, probing classifiers, CKA/CCA similarity, activation/attribution studies).
- Dataset “secure” labels are derived from tools and a manual review of only flagged snippets; unflagged snippets may still contain vulnerabilities, creating potential label noise in the fine-tuning data.
- Data leakage risks are not fully addressed: deduplication is applied within the curated dataset, but overlap with models’ pretraining corpora (or LLMSecEval prompts) is not audited, potentially inflating gains.
- No analysis of data scaling: how dataset size, domain composition (web, systems, data science), or secure-pattern diversity influence PEFT effectiveness and generalization remains unknown.
- Comparison against alternative safety-training paradigms (full fine-tuning on secure code, RLHF/RLAIF with security rewards, adversarial training, retrieval-augmented generation with vetted snippets) is absent, so PEFT’s relative cost–benefit is unclear.
- Generalization to instruction-tuned chat assistants and closed-source systems (e.g., GPT-4/4o, Copilot) is not evaluated, limiting external validity for the most widely used coding assistants.
- Robustness to prompt-injection and jailbreak-style adversarial prompts is not tested, despite their relevance to production coding assistants.
- Security–usability trade-offs are unmeasured: effects on latency, inference cost (prompt/prefix length consuming context), determinism/reproducibility at higher temperatures, and developer experience are not quantified.
- Broader code quality impacts (readability, maintainability, performance, resource usage) are not analyzed; security gains may carry hidden quality costs.
- Failure analysis for hard semantic vulnerabilities (e.g., CWE-22 path traversal, CWE-798 hard-coded credentials) is observational; the paper does not propose or test targeted methods to overcome these limitations (e.g., data augmentation, semantic constraints, retrieval, program analysis–in-the-loop).
- Tool disagreement and per-CWE measurement validity are not examined; there is no precision/recall analysis of detectors on LLM-generated code or adjudication process when tools conflict.
- Temperature-induced security gains are reported without studying impacts on task success, determinism, or user trust; guidelines for practical temperature selection in production are missing.
- Long-term robustness and maintenance are untested: stability under distribution shift, continuous fine-tuning updates, and risk of catastrophic forgetting in other coding skills are unknown.
- Compute and cost efficiency claims for PEFT are not rigorously benchmarked against security improvements (e.g., GPU-hours vs. OSR gains), and full fine-tuning baselines are not replicated under the same setup.
- Reproducibility/artifacts: the paper does not clearly state public release of datasets, code, PEFT configurations, and trained adapters, which hinders independent verification and extension.
Open research directions prompted by these gaps:
- Combine PEFT with retrieval of vetted secure patterns, program analysis–in-the-loop training, or RL with security rewards to tackle context-dependent CWEs (e.g., CWE-22, CWE-798).
- Develop decoding-time defenses (multi-sample generation, static/dynamic vetting and reranking, backdoor-aware sampling) and systematically study their effects on security and usability.
- Create mechanistic analyses to validate how prompt/prefix embeddings modulate attention and representations related to secure coding.
- Establish comprehensive, realistic benchmarks spanning multiple languages, real-world prompts, dynamic exploit testing, and human-in-the-loop evaluations to measure end-to-end security and developer outcomes.
Collections
Sign up for free to add this paper to one or more collections.