- The paper introduces ARR, an evaluation framework that employs explicit, prompt-conditioned rubrics to replace scalar reward models, significantly improving preference accuracy and reducing bias.
- It utilizes a generate-verify-refine pipeline to synthesize hierarchical rubrics, ensuring interpretable and robust reward signals for text-to-image generation and image editing.
- Empirical results demonstrate state-of-the-art performance with up to a 0.80 GenEval score and marked reductions in positional bias across multiple benchmarks.
Structured Multimodal Alignment via Auto-Rubric as Reward (ARR) and Rubric Policy Optimization (RPO)
Motivation and Problem Setting
The paper "Auto-Rubric as Reward: From Implicit Preferences to Explicit Multimodal Generative Criteria" (2605.08354) addresses the central challenge of aligning multimodal generative models, particularly for text-to-image and image editing tasks, with multi-dimensional human preferences. Prevailing RLHF and reward modeling approaches reduce fine-grained judgments into scalar or pairwise labels, entangling nuanced evaluation axes and exposing the learning process to reward hacking and positional bias. The authors argue that the bottleneck in multimodal alignment is not a lack of preference knowledge but the absence of a stable, factorized interface to apply it. By externalizing preference structure as explicit, prompt-conditioned rubrics, the ARR framework enables interpretable, bias-resistant evaluation and generative optimization.
ARR Framework and Rubric Synthesis
ARR operates training-free and synthesizes prompt-specific rubrics by prompting a frozen VLM to convert holistic intent into independently verifiable evaluation criteria. This generate-verify-refine pipeline induces compact, discriminative rubrics that span relevant quality dimensions such as semantic fidelity, compositional structure, spatial consistency, and edit faithfulness. Instance-conditioned rubrics are verified and refined to suppress self-amplified biases, and subsequently aggregated into a hierarchical, semantically organized structure for consistent evaluation. Importantly, ARR requires only minimal supervision for rubric generation and achieves high data-efficiency.
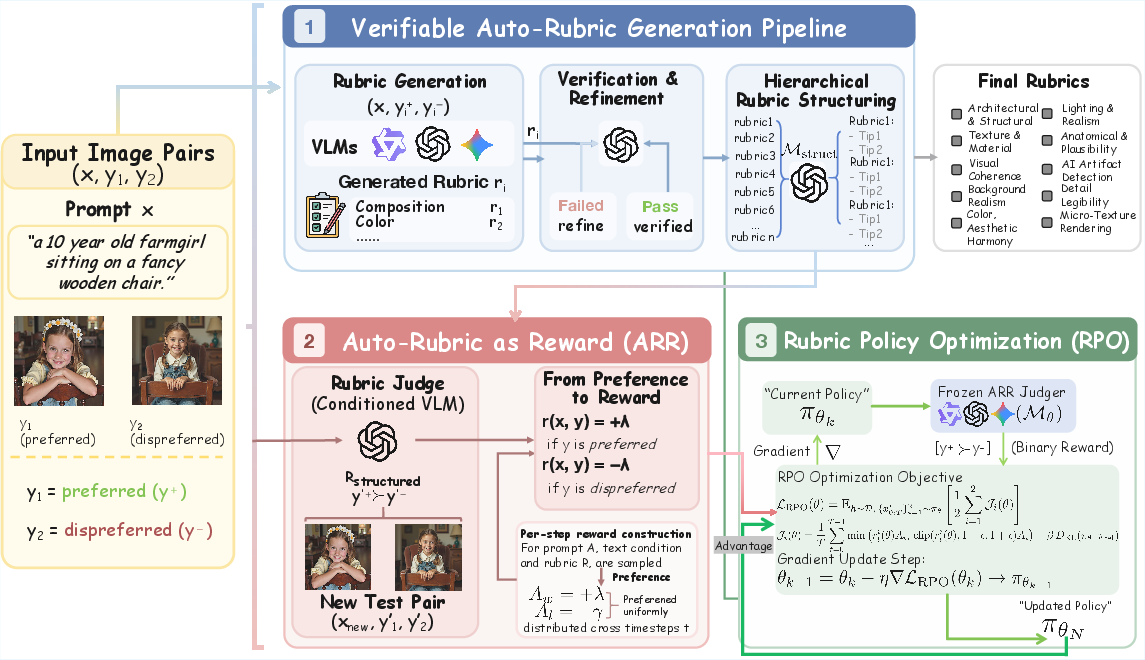
Figure 1: Overview of the ARR-RPO framework, detailing rubric synthesis, verification, structuring, and integration into reward modeling and policy optimization.
Explicit Reward Modeling and Policy Optimization
Rubrics produced by ARR are employed in both evaluation and optimization. During evaluation, the VLM judge is conditioned on these explicit rubrics, reframing pairwise comparison from latent preference matching to criterion-aligned verification. For generative training, Rubric Policy Optimization (RPO) utilizes rubric-conditioned binary decisions as reward signals, aligning policy gradients directly with interpretable axes of quality. RPO distributes advantage uniformly across generation steps and applies PPO-style clipping and KL regularization to enhance training stability and mitigate reward hacking. The reward interface thus becomes compositional, interpretable, and robust without scalar regression or separate reward modeling.
The ARR-RPO framework is evaluated across standard benchmarks for preference evaluation (HPDv3, MM-RewardBench2, EditReward-Bench) and generative quality (GenEval, DPG-Bench, TIIF, UniGenBench++, GEdit-Bench, ImgEdit). ARR conditioning consistently surpasses pairwise reward models and direct VLM judges, improving preference accuracy by 1.7–6.3 percentage points and significantly reducing positional bias (Δ drops by up to 25 points) even in zero-shot scenarios. ARR achieves state-of-the-art accuracy in both evaluation and generative tasks, with robust generalization across model families.
For generative alignment, ARR-RPO lifts FLUX.1-dev and Qwen-Image-Edit-2509 performance over specialist baselines. In text-to-image tasks, ARR-RPO achieves up to GenEval 0.80 (vs. 0.66 baseline), DPG-Bench 85.76 (vs. 83.84), and TIIF 76.85 (vs. 71.09). For image editing, GEdit-Bench and ImgEdit scores improve by 0.3 and 0.08 points, respectively. These gains are achieved without reward model fine-tuning or large-scale annotation.
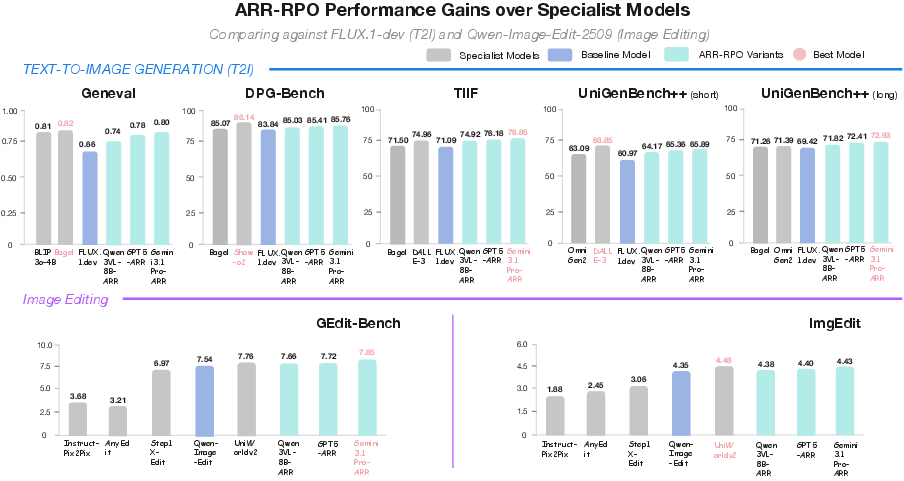
Figure 2: Performance comparison of ARR-RPO variants against specialist models in text-to-image generation (top) and image editing (bottom) tasks.
Qualitative inspection shows enhanced compositionality, architectural fidelity, and edit faithfulness, demonstrating that rubric factorization directly translates to improved generative output.

Figure 3: Example outputs for text-to-image and image editing generated by ARR-RPO Gemini 3.1 Pro, highlighting improvements in prompt adherence and edit realism.
Ablations and Analysis
Ablation analyses reveal that the gains stem from rubric structure rather than model scale or judge-generator co-adaptation: cross-model transfer maintains accuracy gains, and increasing rubric cardinality monotonically improves evaluation robustness. The paper demonstrates substantial residual positional bias in all base VLMs, but explicit rubrics from ARR—especially those augmented with human guidance—dramatically reduce this instability. ARR's generate-verify-refine pipeline yields highly consistent rubrics which are directly transferable across domains and model families.
Rubric Operationalization and Prompt Engineering
Hierarchical structuring combines rubric axes into a coherent evaluation protocol (Figure 4), while system prompts (Figure 5, Figure 6) ensure standardized and order-agnostic comparison. Structured rubrics span semantic, compositional, and local fidelity dimensions in both text-to-image and editing contexts (Figure 7).
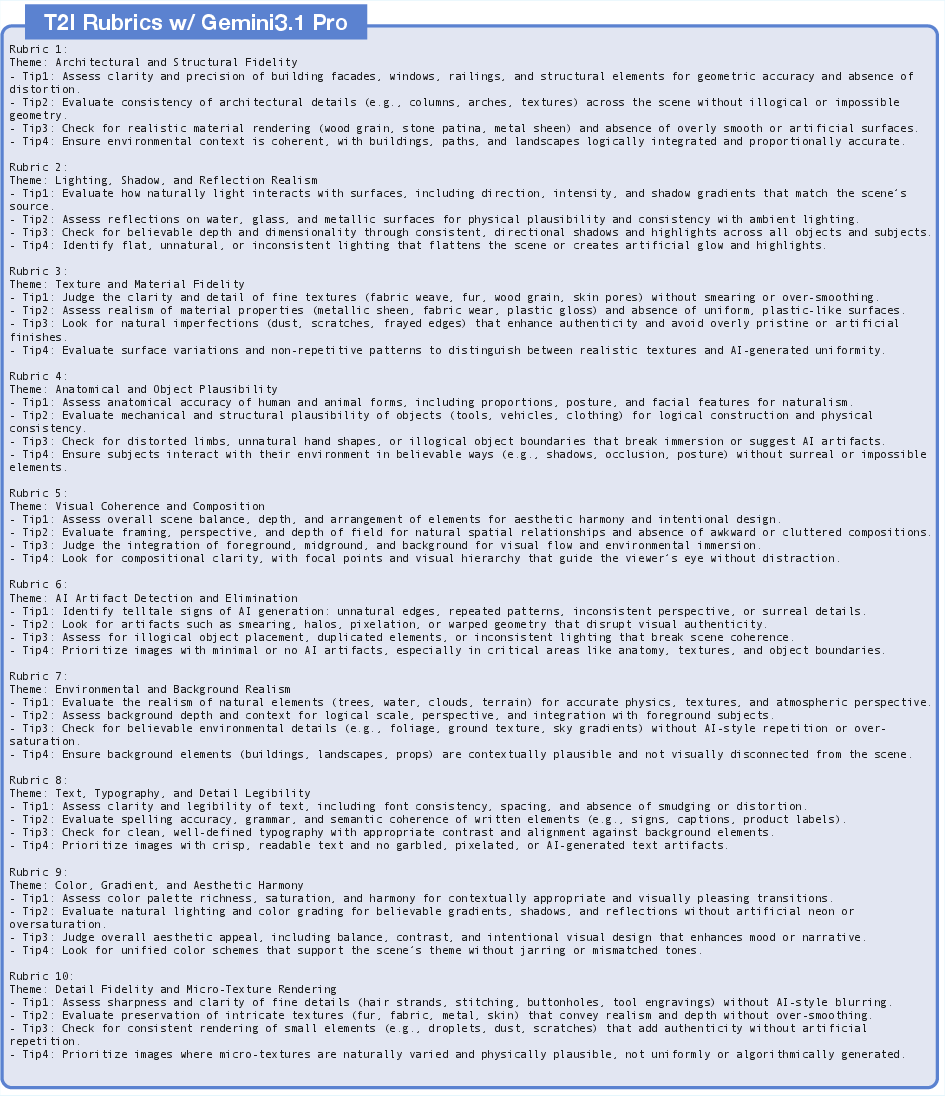
Figure 4: Auto-generated T2I rubrics illustrating how ARR distills architectural fidelity, lighting consistency, texture realism, and artifact detection into explicit evaluation axes.

Figure 7: Auto-generated image editing rubrics encompassing dimensions for fidelity preservation, material integrity, lighting consistency, and artifact elimination.
Implications and Future Directions
ARR-RPO demonstrates that explicitly externalizing implicit preference structure enables principled, scalable, and compositional alignment in multimodal generation. The paradigm shift from scalar reward models to rubric-based discrimination reduces reward hacking, amplifies interpretability, and enables robust, zero-shot deployment. Theoretical implications include the feasibility of decoupling evaluation logic from model parameters and operationalizing multidimensional intent via natural language scaffoldings. Practically, ARR-RPO invites extension toward task-specific rubric refinement, human-in-the-loop guidance, and scaling to more complex multimodal domains, including video synthesis and reasoning. Integration with self-improving VLMs and adaptive rubric synthesis remains a compelling avenue for future research.
Conclusion
The authors show that the critical bottleneck in multimodal generative alignment lies in the interface for preference application, not in model capacity or preference data. The Auto-Rubric as Reward framework, together with Rubric Policy Optimization, externalizes preference structure as explicit, interpretable rubrics, directly supporting robust evaluation and optimization. This structured, data-efficient, and bias-resistant approach consistently outperforms state-of-the-art reward models and judge paradigms, providing a principled foundation for compositional multimodal alignment and scalable generative quality improvement.

