Rethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Abstract: Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to create and use “rubrics” (clear checklists or rules) to help AI models judge quality in open-ended tasks, like writing, planning, or answering complex questions. The method is called Recursive Rubric Decomposition (RRD). It makes rubrics more detailed, fair, and non-repetitive so AI judges can score better, and those scores can be used to train other AI models more effectively.
Key Questions the paper asks
- How can we build rubrics that cover all the important parts of a good answer, instead of leaving gaps?
- How can we avoid rubrics that are confusing, overlap too much, or point in the wrong direction?
- How can we combine many rubric scores fairly, without double-counting similar items?
- Do better rubrics help both judging and training AI models on open-ended tasks?
Methods: How does RRD work?
Think of grading a school project. A good rubric breaks the grade into clear parts (like accuracy, clarity, creativity), and each part should help tell good work from bad without repeating the same thing.
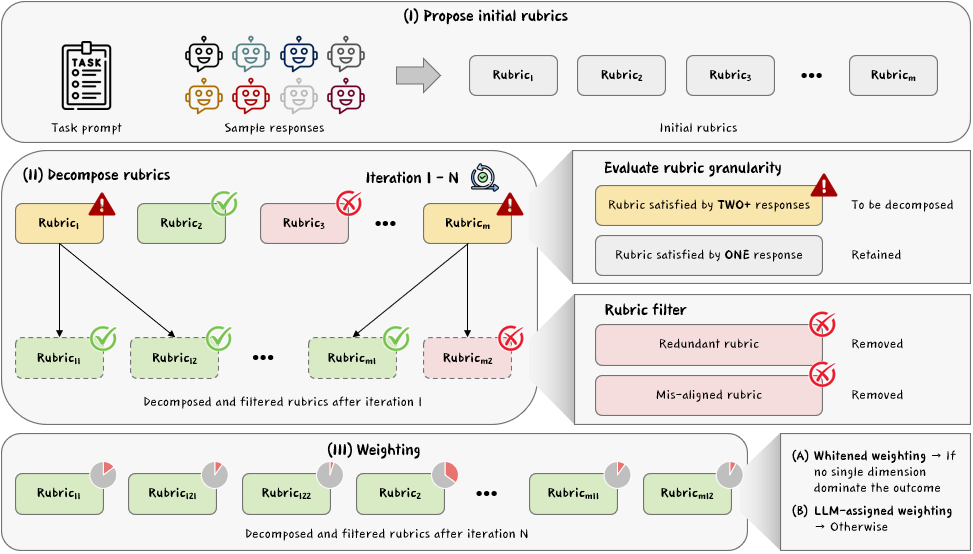
RRD improves rubrics through three main stages:
- First, the AI proposes initial rubric items based on the task and some example answers.
- Second, it runs a “decompose–filter” cycle:
- Decompose: If a rubric is too broad (it applies to many answers), it gets split into smaller, more specific checks. For example, “good explanation” might split into “defines key terms,” “uses examples,” and “explains steps clearly.”
- Filter: Remove rubrics that are misaligned (they favor clearly worse answers) or redundant (they overlap too much with other items).
- Third, it assigns smarter weights to rubric items:
- Instead of just averaging everything or guessing which item matters most, RRD uses a correlation-aware approach. In simple terms, if two rubrics measure almost the same thing, they shouldn’t be counted twice. RRD “whitens” the rubric space—like untangling overlapping signals—so each criterion contributes fairly.
Why this matters: The authors also give a simple theory showing that if each rubric is at least a little helpful and not too similar to others, and we weight them smartly, the judge’s chance of making a wrong decision drops quickly.
Main Findings: What did they discover?
- Better judging accuracy:
- On two benchmarks (JudgeBench and PPE), RRD made both GPT-4o and Llama-3.1 judges agree with human preferences much more often.
- Example: On JudgeBench with GPT-4o, accuracy jumped by up to +17.7 points (from 55.6% to 73.3%).
- Importantly, simple rubrics (made without looking at example answers) could actually hurt accuracy. RRD fixes this by refining and filtering.
- Stronger training signals (rewards) for AI:
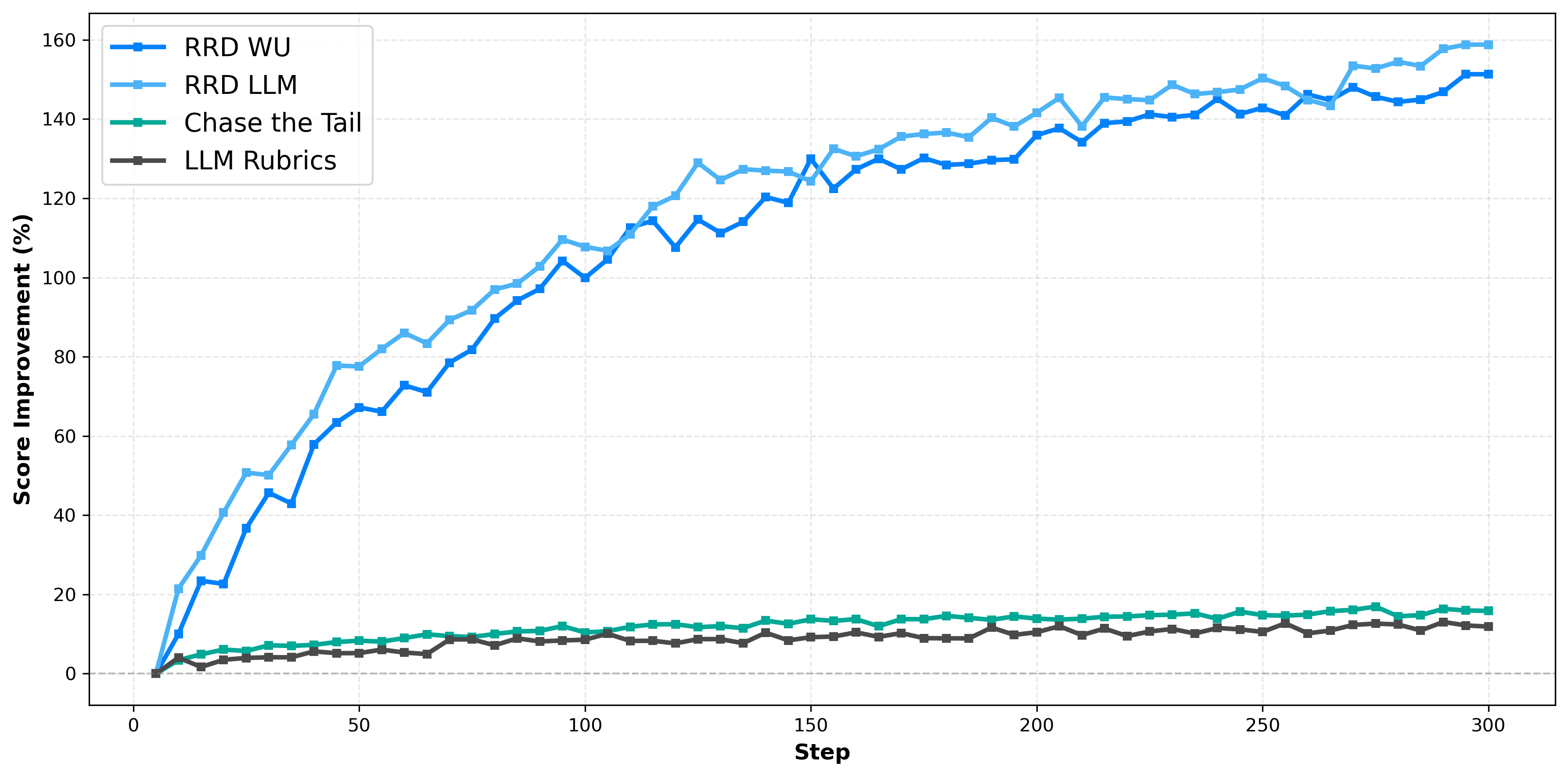
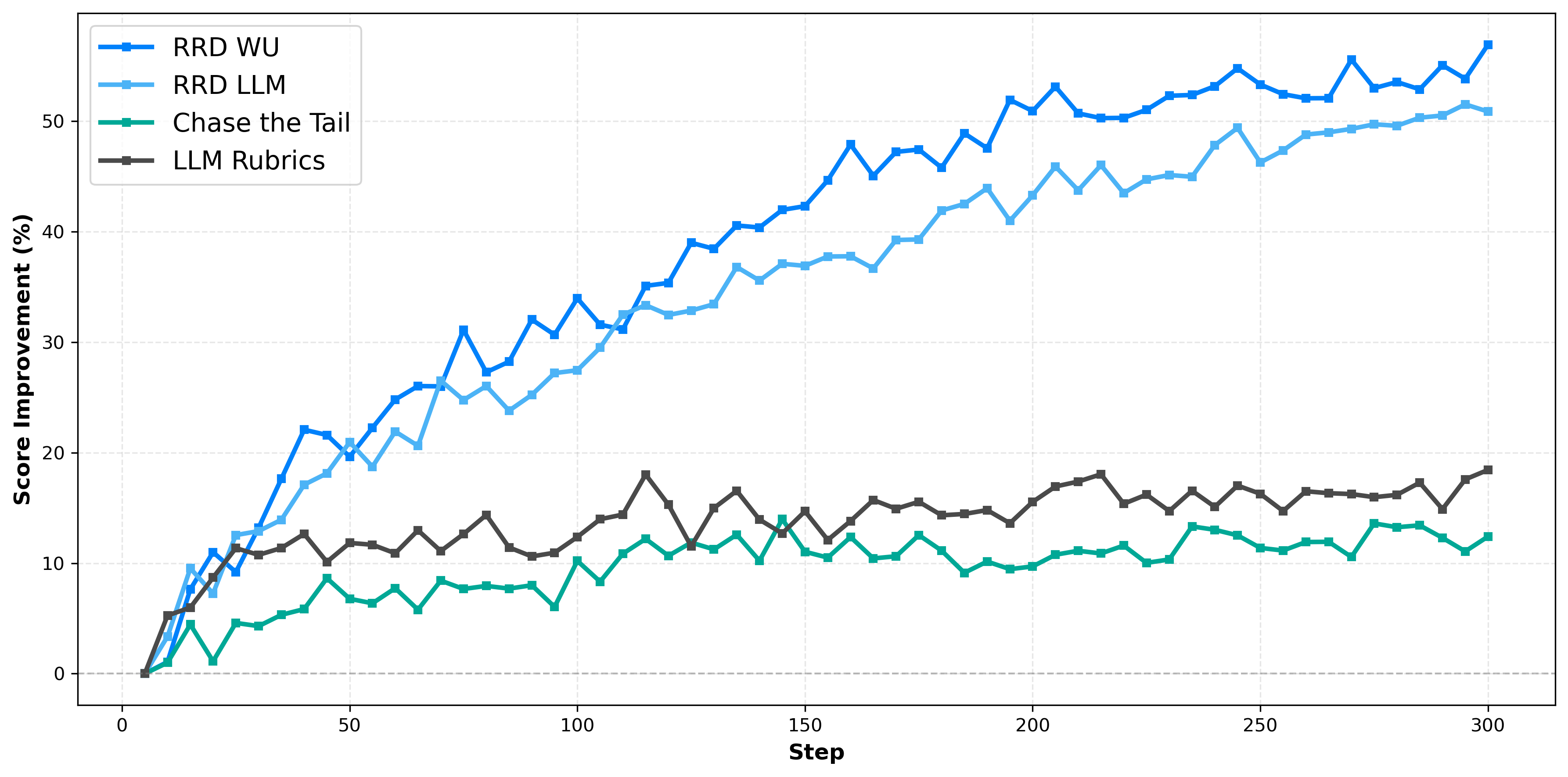
- When the rubrics were used as rewards to train models (a process called Reinforcement Fine-Tuning, or RFT), RRD produced much bigger improvements.
- Qwen3-4B: Up to 160% reward boost.
- Llama3.1-8B: About 60% reward boost.
- Competing methods only reached around 10–20%.
- Gains carry over to other tests:
- Models trained with RRD did better on BiGGen Bench (a broad skills test) and HealthBench-Hard (a medical dialog benchmark with expert-made rubrics), showing the improvements were real and general, not just overfitting.
Why is this important?
Open-ended tasks don’t have a single “correct” answer, and quality depends on many things at once (like safety, clarity, logic, helpfulness). That makes judging hard and training risky: small biases can get amplified. RRD gives AI judges structured, trustworthy guidance—like a refined teacher’s rubric—so they score more accurately. Those improved scores then make training more stable and effective, helping models learn better behaviors across different kinds of tasks.
Simple Takeaways and Impact
- Rubrics are powerful—but only if they’re comprehensive, precise, and not repetitive.
- RRD builds better rubrics by breaking broad rules into specific ones, removing bad or overlapping items, and fairly weighing the rest.
- This leads to:
- More reliable AI judges that align better with human preferences.
- Stronger, steadier reward signals for training models on open-ended tasks.
- Improved performance on both general and high-stakes domains (like medicine).
In short, RRD turns messy, one-size-fits-all judging into a careful, step-by-step evaluation process, making AI assessments clearer and AI training more effective.
Knowledge Gaps
Unresolved Gaps and Open Questions
Below is a consolidated list of specific knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is framed to be actionable for future research.
- Empirical verification of the theoretical assumptions (A1: positive edge, A2: bounded correlation): quantify rubric edges (), sub-Gaussian noise, and pairwise correlations on multiple datasets; test how often rubrics truly have positive edge and how violations affect performance.
- Robustness of covariance estimation for whitened-uniform (WU) weighting: determine the sample size required for stable estimation of the rubric covariance ; report regularization/shrinkage strategies when is ill-conditioned, especially with small m (e.g., m=8 sample responses).
- Per-prompt versus global weighting: clarify whether is estimated per prompt or globally; evaluate the trade-offs and accuracy gains of adaptive per-prompt reweighting versus a fixed global covariance under domain shift.
- Alternative label-free weighting schemes: compare WU with robust optimization (e.g., distributionally robust weights), Bayesian/shrinkage estimators, or self-supervised/meta-learned weights under misspecified correlation structures and non-sub-Gaussian noise.
- Misalignment filtering via “strong vs. weak” proxy: quantify bias introduced by discarding criteria that favor weaker-model outputs; identify tasks where weaker models outperform (safety, concision) and evaluate human-grounded alternatives to this proxy.
- LLM-based redundancy filtering reliability: measure false positives/negatives in identifying overlapping rubrics; compare to embedding-based clustering, mutual information, or correlation thresholds; establish principled similarity metrics and thresholds.
- Generalization across languages and domains: extend RRD beyond English to multilingual prompts (especially low-resource languages) and specialized domains (law, education, safety-critical engineering); report performance and failure modes.
- Human evaluation coverage: complement rubric-based and LLM-judge evaluations with human studies (crowd and domain experts) to validate judge accuracy and policy gains; report inter-rater reliability and calibration.
- Reward hacking and adversarial robustness: systematically test whether policies exploit rubric wording or structure; design adversarial prompts and randomized/hard-negative rubrics; develop defenses and audit mechanisms.
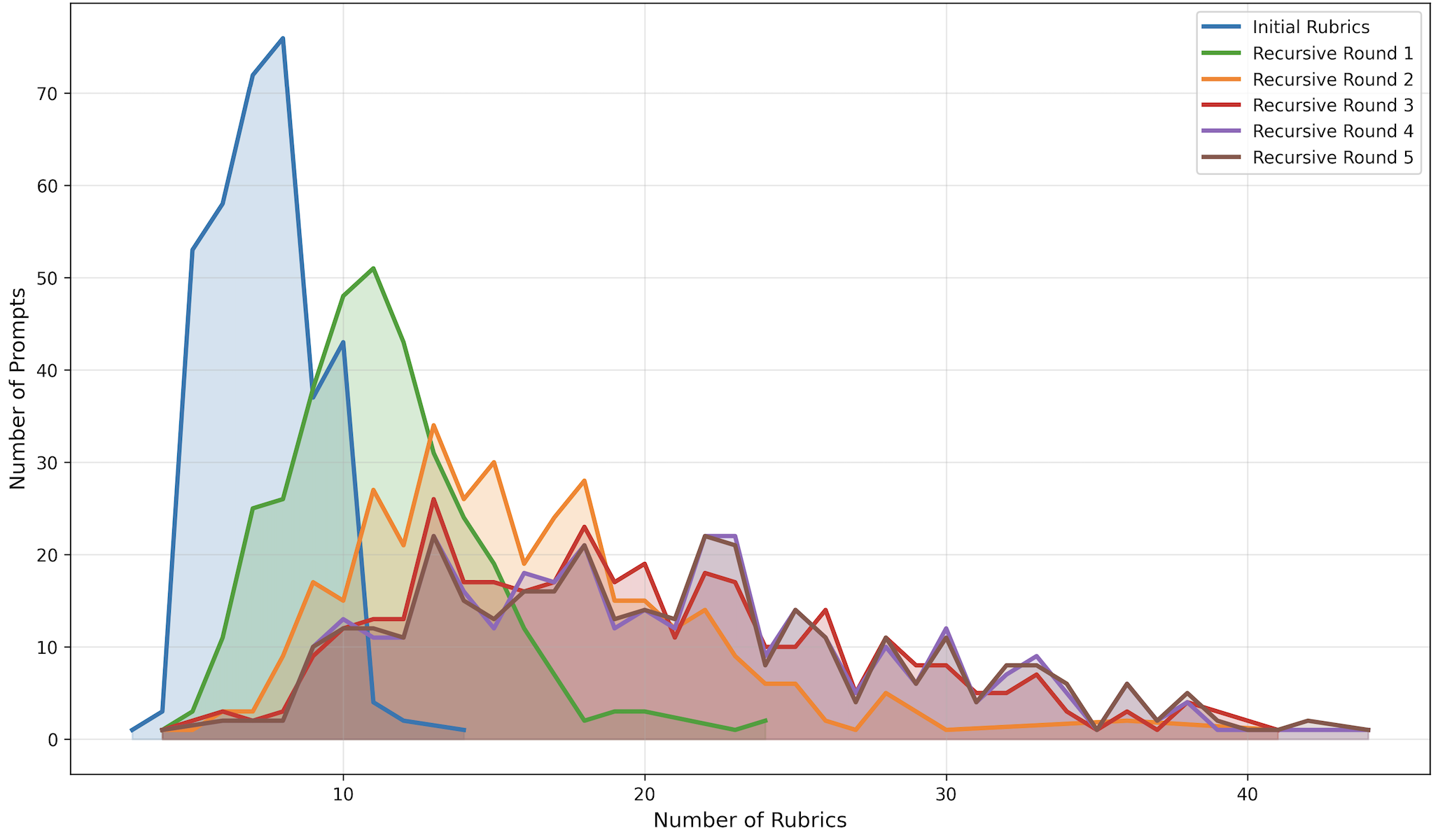
- Interpretability and stability of generated rubrics: provide a qualitative taxonomy and analyze variance of produced rubrics across runs/prompts; detect contradictory or degenerate criteria; study how rubric count and granularity affect user interpretability.
- Principled stopping criteria for recursion: replace fixed termination threshold (number of rejected proposals) with data-driven criteria based on marginal utility (e.g., mutual information gain, coverage metrics, diminishing returns) or held-out validation.
- Sensitivity to decomposition hyperparameters: ablate and optimize the decomposition trigger n (number of matched rollouts), the number of sample responses m, and proposal prompts; study their effect on coverage, redundancy, and accuracy.
- Extension to process-level rubrics: incorporate chain-of-thought and stepwise verification (process rewards) for multi-hop reasoning and multi-turn dialogues; evaluate RRD on temporal decomposition and consistency across turns.
- Ground-truth calibration for theory: build small labeled corpora to estimate and validate the misclassification bound; test whether bound tightening correlates with real accuracy gains and under what conditions.
- Covariance stationarity over training: monitor how rubric correlations change across prompts and as policies improve; evaluate the need for periodic re-estimation and adaptive weighting schedules during RFT.
- Model dependence and transfer: test RRD with a wider range of open-weight and proprietary judges/proposers/reward models; quantify how much gains depend on specific frontier models (GPT-4o, Gemini, GPT-OSS-120B).
- Computational cost and scalability: report end-to-end compute, latency, and dollar cost of RRD (proposal/decomposition/filtering) and rubric satisfaction checking during RFT; explore caching, distillation, and lightweight verifiers for practical deployment.
- Safety and fairness audits: evaluate rubrics and trained policies for toxicity, demographic bias, verbosity bias, cultural skew; add fairness-aware filters and negative rubrics; report trade-offs between helpfulness and safety axes.
- Hybrid verification: integrate programmatic checks (regex, retrieval, fact-checkers, knowledge graphs) with LLM rubrics; measure additive benefits and failure interactions; develop compositional verifiers.
- Reproducibility and transparency: release full prompts, templates, seeds, code, and filtering criteria; document thresholds for redundancy/misalignment; provide standardized pipeline configs for independent replication.
- Benchmark-level error analysis: break down JudgeBench and PPE results by category and language; identify where RRD underperforms; use these insights to target rubric gaps and specialized decomposition strategies.
- Evaluation breadth beyond rubric scores: test on MT-Bench, Arena Elo, and user studies; measure real-world utility, satisfaction, and safety outcomes beyond rubric-derived metrics.
- Training stability and variance: report variance across RFT runs, sensitivity to Dr.GRPO hyperparameters, and potential mode collapse or catastrophic forgetting; propose stabilization techniques.
- Numerical stability in WU weighting: ensure stable computation of (e.g., eigenvalue clipping, shrinkage to identity); characterize failure modes when rubrics are binary with low variance or highly collinear.
- Hierarchical and tree-aware weighting: exploit the decomposition tree structure to assign hierarchical weights (parent-child attenuation, uncertainty-aware aggregation); study whether tree-informed schemes outperform flat WU.
- Use of large reward models (GPT-OSS-120B): assess feasibility of smaller or distilled reward models; quantify trade-offs in accuracy, cost, and latency; explore ensemble or committee approaches for reliability.
- Consistency of negative rubrics and penalties: clarify handling of negative penalties (e.g., HealthBench clipping); study the impact of penalty design and clipping on training dynamics and reported scores.
Glossary
- Aggregation mechanism: A method for combining multiple rubric signals into a single, more reliable judgment. "we introduce an aggregation mechanism to mitigate noise"
- BiGGen Bench: A free-form, rubric-based benchmark assessing multiple generation capabilities. "BiGGen Bench is a free-form generation benchmark spanning multiple core capabilities"
- Bounded correlation: An assumption that pairwise correlations among rubric noises are limited below a fixed threshold. "(A2) (Bounded correlation) Letting , the vector is mean-zero sub-Gaussian with covariance "
- Concentration bounds: Probabilistic inequalities that bound deviations of random variables, used here to control aggregated rubric noise. "This enables standard concentration bounds over the aggregated, non-redundant decisions."
- Correlation-aware weighting: A weighting strategy that accounts for correlations among rubric criteria to avoid over-counting overlapping signals. "a correlation-aware weighting scheme to prevent over-representing highly correlated criteria"
- Correlation structure: The pattern of dependencies among rubric scores used to guide weighting. "assign whitened uniform (WU) weights to account for correlation structure"
- Covariance: A matrix describing joint variability of rubric residuals. "with covariance "
- Dr.GRPO: A reinforcement fine-tuning algorithm variant used to train policies with rubric rewards. "We employ Dr.GRPO \citep{drgrpo} as our RFT algorithm"
- Frontier models: State-of-the-art LLMs at the leading edge of capability. "even frontier models can be near chance on preference benchmarks"
- Generative Verifier: An LLM-driven mechanism providing verifier-like feedback for open-ended tasks. "by providing a ``Generative Verifier'' via RRD"
- HealthBench-Hard: A challenging subset of a clinical dialogue benchmark with physician-authored rubrics. "HealthBench-Hard \citep{arora2025healthbench}"
- JudgeBench: A benchmark for evaluating the accuracy of LLM-based judges. "JudgeBench \citep{tan2024judgebench}"
- LLM judge: A LLM used to evaluate and compare generated responses. "LLMs are increasingly used as judges (``LLM judge'')"
- Macro-average score: The mean of per-example rubric scores, giving equal weight to each example. "We report the macro-average score, computed as the mean of per-example rubric scores"
- Measurable map: A formal function mapping a prompt–response pair to a binary criterion value. "Each rubric is a measurable map"
- Misalignment filtering: A filter that removes rubrics whose preference direction conflicts with stronger model outputs. "misalignment filtering: which discards rubrics that prefer outputs from a weaker model (Llama3-8B) over a stronger model (GPT-4o) as a proxy for incorrect preference direction"
- Misclassification probability: The probability that the aggregated rubric-based judge yields an incorrect verdict. "produces an incorrect verdict (misclassification probability)"
- Open-weights: Models whose parameters are publicly available for use and inspection. "open-weights (Llama3.1-405B)"
- Positive edge: The property that a rubric’s expected verdict aligns positively with the true preference label by some margin. "(A1) (Positive edge) There exist such that"
- Preference Proxy Evaluations (PPE): A benchmark of human preference pairs from Chatbot Arena across many languages and models. "Preference Proxy Evaluations (PPE) \citep{frick2024evaluate}"
- Preference verdict: The outcome expressing which response is preferred among candidates. "An LLM judge outputs a preference verdict"
- Preference-judgment accuracy: The rate at which a judge’s preferences agree with human preferences. "preference-judgment accuracy on JudgeBench and PPE"
- Recursive Rubric Decomposition (RRD): A framework that recursively refines rubrics, filters misaligned/redundant items, and optimizes weights. "we propose Recursive Rubric Decomposition (RRD)"
- Redundancy filtering: A process that removes rubrics overlapping with existing ones to avoid duplication. "redundancy filtering, which removes rubrics that are substantially overlapping with existing ones"
- Reinforcement Learning from Verifiable Rewards (RLVR): RL methods that rely on objectively checkable outcomes (e.g., coding, math). "Reinforcement Learning from Verifiable Rewards (RLVR)"
- Reinforcement fine-tuning (RFT): Using reinforcement learning with reward signals to fine-tune LLM policies. "reinforcement fine-tuning (RFT)"
- Rubric predicates: Binary criteria used by the judge to assess specific aspects of responses. "a set of rubric predicates, evaluated separately"
- Rubrics-as-Rewards paradigm: Using rubric-level signals as structured rewards for training models. "motivating the Rubrics-as-Rewards paradigm"
- Sub-Gaussian: A class of random variables with tails dominated by a Gaussian, used to model rubric noise. "sub-Gaussian with bounded dependence"
- Termination threshold: A stopping rule for recursion based on the count of rejected rubric proposals. "termination threshold"
- Variance proxy: A scalar capturing the weighted variance of rubric residuals in the misclassification bound. "variance proxy of the weighted residuals"
- Weight optimization: The process of choosing aggregation weights to reduce error and avoid over-representing correlated rubrics. "Finally, optimize weights to prevent over-representation of highly correlated rubrics."
- Whitened uniform (WU) weights: Equal weights applied after decorrelating rubric dimensions via whitening. "assign whitened uniform (WU) weights"
- Whitening (rubric space): Transforming rubric scores to remove correlations and normalize scales. "whiten the rubric space via "
- WildChat: A dataset of real user–AI interactions used as prompts for training. "WildChat \citep{zhao2024wildchat}"
Practical Applications
Immediate Applications
The following applications can be deployed now using the RRD framework and its demonstrated components (recursive decompose–filter rubric generation, misalignment and redundancy filtering, and correlation-aware “whitened uniform” weighting), which showed substantial gains in judge accuracy and RFT reward quality.
- Upgrade LLM-as-judge systems in evaluation pipelines
- Sector: software, content platforms, ML Ops
- Use case: Replace holistic or naive rubric judges with RRD-based judges to score open-ended outputs (creative writing, planning, explanations) in A/B testing, model selection, and dataset curation. Expect improved agreement with human preferences (e.g., +17.7 points on JudgeBench with GPT-4o).
- Tools/workflows: “RRD Judge” microservice wrapping the decompose–filter–weight pipeline; API for pairwise comparison and rubric-scored evaluation.
- Assumptions/dependencies: Access to a high-quality LLM for rubric proposal (e.g., GPT-4o, Gemini); diverse sample responses; compute to estimate rubric covariance for whitening.
- Reinforcement fine-tuning of small and mid-size models using rubrics-as-rewards
- Sector: software, education, customer support
- Use case: Apply RRD-derived rubric rewards in GRPO-style RFT for open-source models (e.g., Qwen3-4B, Llama3.1-8B) to boost helpfulness, instruction following, and completeness without costly human labels (observed +160%/+60% reward gains).
- Tools/workflows: “RRD Rewards” library (rubric scoring service + Σ{-1/2} weighting) plugged into existing PPO/GRPO training loops; training dashboards tracking reward stability.
- Assumptions/dependencies: Stable rubric scoring LLM (e.g., GPT-OSS-120B or equivalent); careful prompt hygiene; toxicity filtering; adequate compute/budget for RFT.
- Domain-specific evaluation with transparent rubrics (healthcare exemplar)
- Sector: healthcare
- Use case: Evaluate clinical dialogue systems against physician-authored, instance-specific rubrics refined by RRD to reduce redundancy and misalignment; track axes like accuracy, completeness, communication style (improvements observed on HealthBench-Hard).
- Tools/workflows: “ClinEval-RRD” scoring toolkit; rubric editor for clinicians to iteratively refine criteria; correlation-aware weighting to prevent double-counting (e.g., CRP/ESR analog).
- Assumptions/dependencies: Expert rubric seeds; guardrails to avoid clinical decision automation; governance for model scoring and release.
- Curriculum-aligned grading and feedback generation
- Sector: education
- Use case: Teachers auto-generate prompt-specific rubrics for essays, projects, and coding assignments, then apply RRD filtering and weighting for fair, interpretable grading; students use rubrics for self-assessment.
- Tools/workflows: LMS plugin that takes assignments + sample responses, produces RRD rubrics and criterion-level feedback; batch grading with rubric scores.
- Assumptions/dependencies: Diverse samples to trigger decomposition; policy settings for weighting (e.g., whitened uniform vs. instructor override); data privacy safeguards.
- Customer support QA and agent coaching
- Sector: CX, enterprise software
- Use case: Score agent/chatbot responses with RRD rubrics covering compliance, empathy, resolution quality, and actionability; use criterion-level feedback to coach agents and tune bots.
- Tools/workflows: “SupportEval-RRD” integrated into QA dashboards; feedback loop to update agent playbooks; RFT for bot refinement using rubric rewards.
- Assumptions/dependencies: Company-specific rubric seeds; representative sample dialogs to reveal coarse criteria; continuous monitoring for drift.
- Content quality review and editorial workflows
- Sector: media, marketing, documentation
- Use case: Evaluate copy for clarity, factuality, tone, brand alignment via decomposed, non-redundant rubrics; highlight criterion-level deltas across candidate drafts to accelerate editing.
- Tools/workflows: “Editorial Rubrics” assistant; side-by-side comparison with RRD scores; rubric reuse templates for campaigns and docs.
- Assumptions/dependencies: Brand/style guides for rubric seeds; periodic recalibration with human editors.
- Benchmark curation and reproducible academic evaluation
- Sector: academia
- Use case: Build more discriminative, prompt-specific rubrics for open-ended benchmarks (e.g., BiGGen Bench variants), reducing judge bias and improving reproducibility; publish criterion-level reports.
- Tools/workflows: “RRD-Bench” toolkit to auto-generate and version rubrics, estimate covariance, and export standardized scoring artifacts.
- Assumptions/dependencies: Access to strong LLMs for proposing rubrics; documented rubric provenance; community-agreed weighting strategy.
- AI governance and audit scoring
- Sector: policy, compliance, AI governance
- Use case: Conduct transparent audits of open-ended assistant behavior using RRD rubrics, with defensible aggregation (correlation-aware weighting) to avoid double-counting and document judgment logic.
- Tools/workflows: “AuditStack-RRD” with rubric catalogs for safety, privacy, misleading content, and responsible use; audit trails with criterion-level evidence.
- Assumptions/dependencies: Governance frameworks defining acceptable criteria and risk weights; legal review; regular recalibration against human audits.
- Data selection and preference dataset bootstrapping
- Sector: ML Ops, data engineering
- Use case: Use RRD judges to filter and rank synthetic or user-generated responses to curate high-signal preference datasets for post-training, reducing label noise and bias.
- Tools/workflows: Data pipeline step that scores candidates with RRD rubrics, down-weights correlated criteria, and retains high-margin examples.
- Assumptions/dependencies: Sufficient sample diversity to expose rubric gaps; periodic sanitization for leakage/bias.
- Product A/B testing with criterion-level insights
- Sector: consumer and enterprise software
- Use case: Compare new LLM features or prompts with RRD judges that report which specific criteria improved/regressed (e.g., instruction following vs. safety), enabling targeted iteration.
- Tools/workflows: Experimentation platform integration; dashboards with axis-level deltas and covariance diagnostics.
- Assumptions/dependencies: Calibrated rubrics per product domain; enough traffic to estimate covariance and confidence intervals.
Long-Term Applications
These applications require further research, scaling, or development to reach maturity, including robust standardization, broader domain generalization, multimodal extensions, or regulatory acceptance.
- Regulatory-grade, standardized rubric suites for certification
- Sector: policy, compliance
- Use case: Codify sector-specific RRD rubric catalogs (healthcare, finance, education) and correlation-aware aggregation methods as part of certification and procurement standards.
- Tools/workflows: Standards body-maintained rubric repositories; conformance tests; public scoring APIs.
- Assumptions/dependencies: Multi-stakeholder consensus; legal frameworks; external validation (human panels, uncertainty estimation).
- Frontier-model post-training with RRD rewards at scale
- Sector: AI labs, platforms
- Use case: Replace or augment RLHF/RLAIF with RRD-based rewards for open-ended capabilities, reducing dependence on expensive human labels while improving interpretability and stability.
- Tools/workflows: Distributed RFT pipelines; online rubric generation with automated decomposition and filtering; robust whitening under streaming covariance estimation.
- Assumptions/dependencies: Efficient, low-latency rubric scoring; scalable covariance estimation; safeguards against reward hacking and drift.
- Multimodal rubric judging and rewards
- Sector: vision, speech, robotics
- Use case: Extend RRD to multimodal tasks (image explanation, video summarization, speech coaching, embodied planning) with decomposed cross-modal criteria and correlation-aware weighting.
- Tools/workflows: “MM-RRD” rubric generators that understand visual/audio cues; multimodal covariance modeling; agent reward shaping.
- Assumptions/dependencies: High-quality multimodal judges; domain-specific rubrics; evaluation datasets.
- Dynamic, online rubric adaptation for agents
- Sector: autonomous assistants, orchestration platforms
- Use case: Agents generate and refine rubrics on-the-fly as task context evolves, decomposing coarse goals into discriminative subgoals and using them as internal reward signals for planning.
- Tools/workflows: “Rubric-in-the-loop” agent runtime; online decomposition thresholds; streaming whitening with uncertainty controls.
- Assumptions/dependencies: Robust safety guardrails; detection of misalignment; compute budgets for continuous rubric updates.
- Human–LLM co-judging frameworks
- Sector: governance, research, enterprise review
- Use case: Combine human rubric weights/edits with RRD’s correlation-aware aggregation to align scoring with organizational priorities and fairness constraints; estimate rubric “edges” with human-labeled subsets.
- Tools/workflows: Interactive rubric editors; active learning to calibrate weights; fairness audits on criterion distributions.
- Assumptions/dependencies: Human capacity for periodic calibration; transparent documentation; bias and privacy controls.
- Sector-specific rubric repositories and search (“RubricNet”)
- Sector: cross-sector
- Use case: Curate reusable, peer-reviewed rubric libraries (e.g., clinical communication, legal clarity, scientific exposition), with decomposition histories and covariance metadata for plug-and-play use.
- Tools/workflows: Versioned catalogs; search interfaces; compatibility layers with evaluation platforms.
- Assumptions/dependencies: Community stewardship; licensing; continuous quality assurance.
- Financial compliance and disclosure evaluation
- Sector: finance
- Use case: Evaluate the completeness, clarity, and risk disclosure in reports and customer communications with transparent RRD rubrics; support internal audits and training.
- Tools/workflows: “FinEval-RRD” scoring with compliance criteria; explainable axis-level reports for auditors and executives.
- Assumptions/dependencies: Regulatory acceptance; domain-expert rubric seeds; high-stakes validation to avoid false confidence.
- Safety-critical reward modeling for robotics and operations
- Sector: robotics, energy, manufacturing
- Use case: Use decomposed rubrics to shape rewards for language-guided task planning and incident reporting (e.g., clarity, safety compliance, actionable steps), improving agent reliability.
- Tools/workflows: Integration with task planners; rubric-based safety gates; off-policy evaluation with criterion-level safety scores.
- Assumptions/dependencies: Verified mappings from language rubrics to physical outcomes; human oversight; robust simulation/testing.
- Personal decision-making assistants with rubric-guided planning
- Sector: consumer apps
- Use case: Assist users in complex choices (travel planning, budgeting, career moves) by decomposing goals into discriminative criteria and weighting them transparently; enable checklist-style evaluations.
- Tools/workflows: “MyRubrics” app; user-edited weights; adaptive decomposition based on context.
- Assumptions/dependencies: UX that supports interpretability; safeguards to avoid over-automation of sensitive decisions.
- Auditable model marketplaces with rubric-based comparability
- Sector: AI platforms
- Use case: Standardize multi-criterion comparisons of models and prompts using RRD rubrics; publish criterion-level profiles ensuring fair, correlation-aware aggregation.
- Tools/workflows: Marketplace scoring APIs; public dashboards; audit logs.
- Assumptions/dependencies: Community adoption; reproducible covariance estimates; defenses against gaming.
Collections
Sign up for free to add this paper to one or more collections.