- The paper introduces a novel reasoning-based reward paradigm that replaces scalar values with multi-dimensional, interpretable rationales for visual generation.
- The methodology leverages Preference-Anchored Rationalization (PARROT) and dual-space optimization—via RL fine-tuning and test-time prompt tuning—to boost model efficiency and counter reward hacking.
- Empirical results demonstrate that RationalRewards outperforms legacy models in both text-to-image and image editing tasks using 10–20× less annotated data.
RationalRewards: Reasoning-Based Reward Modeling for Scalable Visual Generation
Motivation and Contribution
RationalRewards introduces a shift from scalar, opaque reward models to a reasoning-driven, multi-dimensional reward paradigm in visual generation models. Instead of compressing human preferences into single scalar values, RationalRewards generates explicit, structured rationales across multiple evaluation dimensions (e.g., text faithfulness, image faithfulness, physical/visual quality, text rendering) before scoring outputs. This enables both interpretable assessment and actionable guidance for reinforcement learning (RL) and test-time inference. The dual-space optimization—training-time (parameter updates) and test-time (prompt refinement)—yields high-efficiency model improvements, mitigates reward hacking, and exposes underutilized generative capacity without increasing model size.
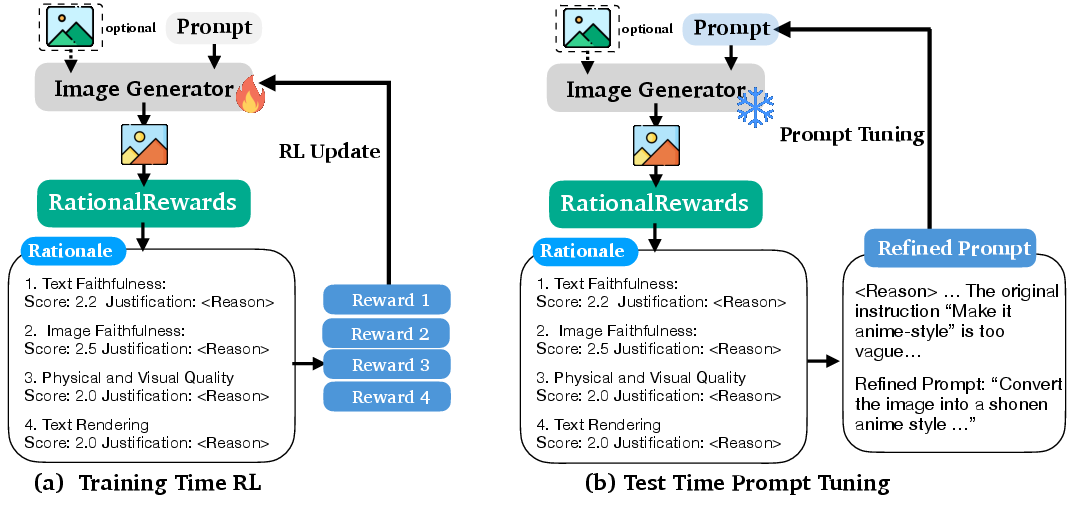
Figure 1: RationalRewards model pipeline, leveraging multi-dimensional rationales for both RL fine-tuning and test-time quality improvement.
Preference-Anchored Rationalization (PARROT)
A central technical contribution is Preference-Anchored Rationalization (PARROT), a variational framework that treats rationales as latent variables and learns to produce them using only existing binary/ordinal preference data, bypassing the need for large-scale manual rationale annotation. The training pipeline involves:
- Posterior rationale generation: Teacher VLMs generate rationales conditioned on known preference decisions, anchoring language reasoning to human labels.
- Consistency filtering: Retain only rationales that are genuinely predictive—that is, those from which the preference label can be reliably recovered.
- Student distillation: Train the reward model (student) to generate rationales and scores from input data alone, without preference labels.
This scalable rationale distillation achieves state-of-the-art open-source reward model accuracy with up to 10–20× less annotated data compared to prior baselines.
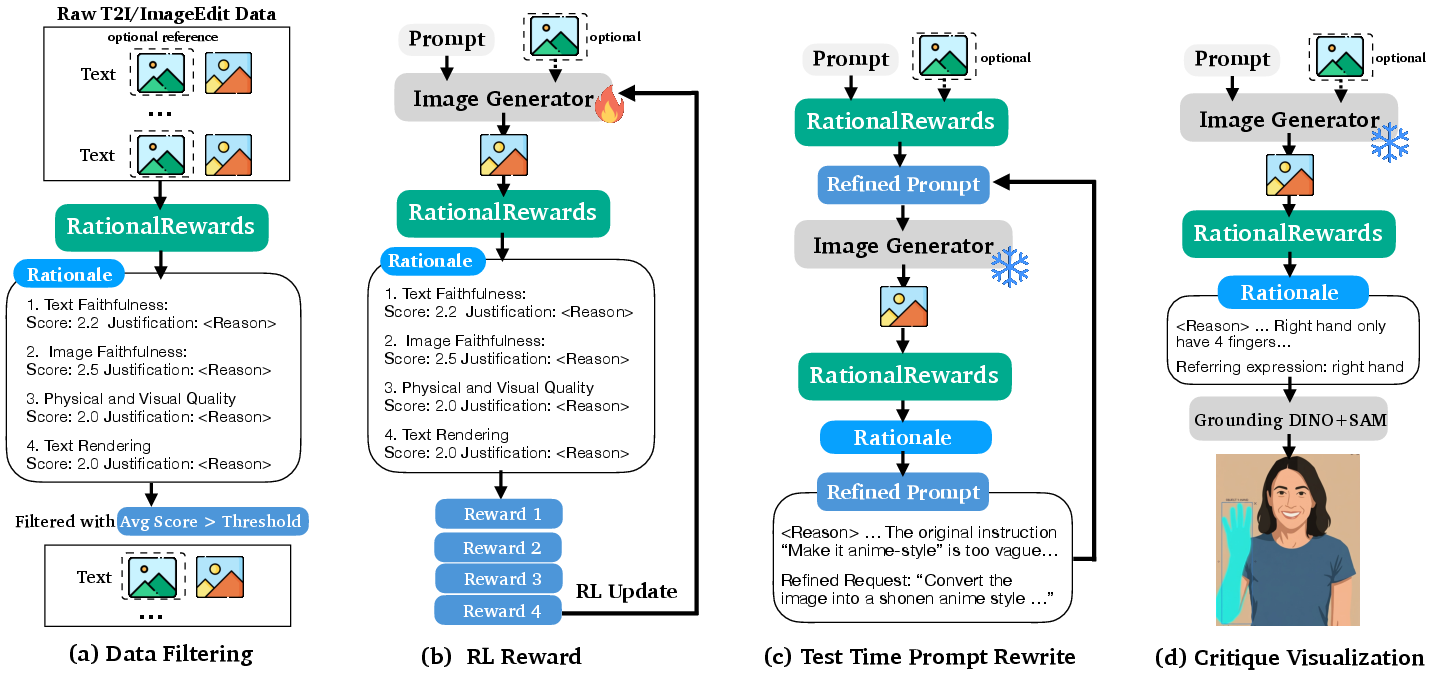
Figure 2: Application spectrum for RationalRewards, from explainable data curation to dense regional reward assignment and prompt-tuned generation.
Dual-Space Optimization: RL and Test-Time Prompt Tuning
Parameter-Space RL Fine-Tuning
Multi-dimensional reward signals produced by RationalRewards enable semantically dense RL updates, replacing typical black-box scalar gradients. Empirical results show substantial improvements over baseline reward models in both text-to-image and image-to-image editing settings. The fine-grained feedback resolves common RL issues such as reward hacking—where generators over-optimize to misaligned reward signals—by providing interpretable, attribute-specific guidance.
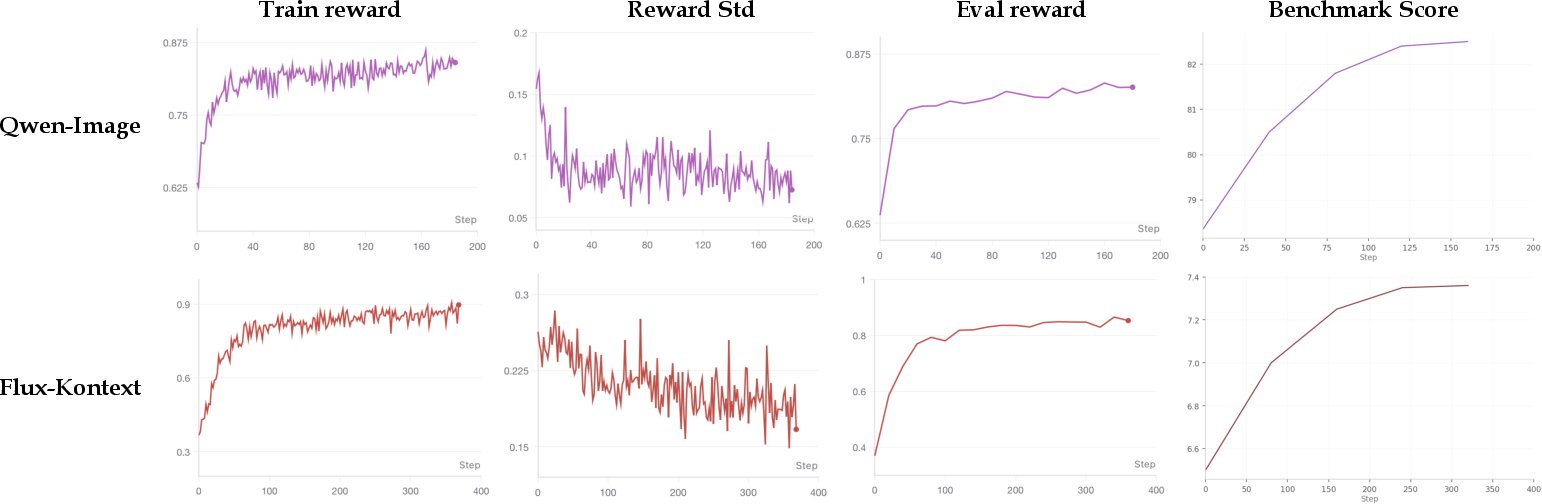
Figure 4: RL with RationalRewards yields stable reward signals; both training and evaluation rewards align with improved generation quality.

Figure 6: Generation quality consistently increases during RL driven by structured, multi-dimensional reward supervision.
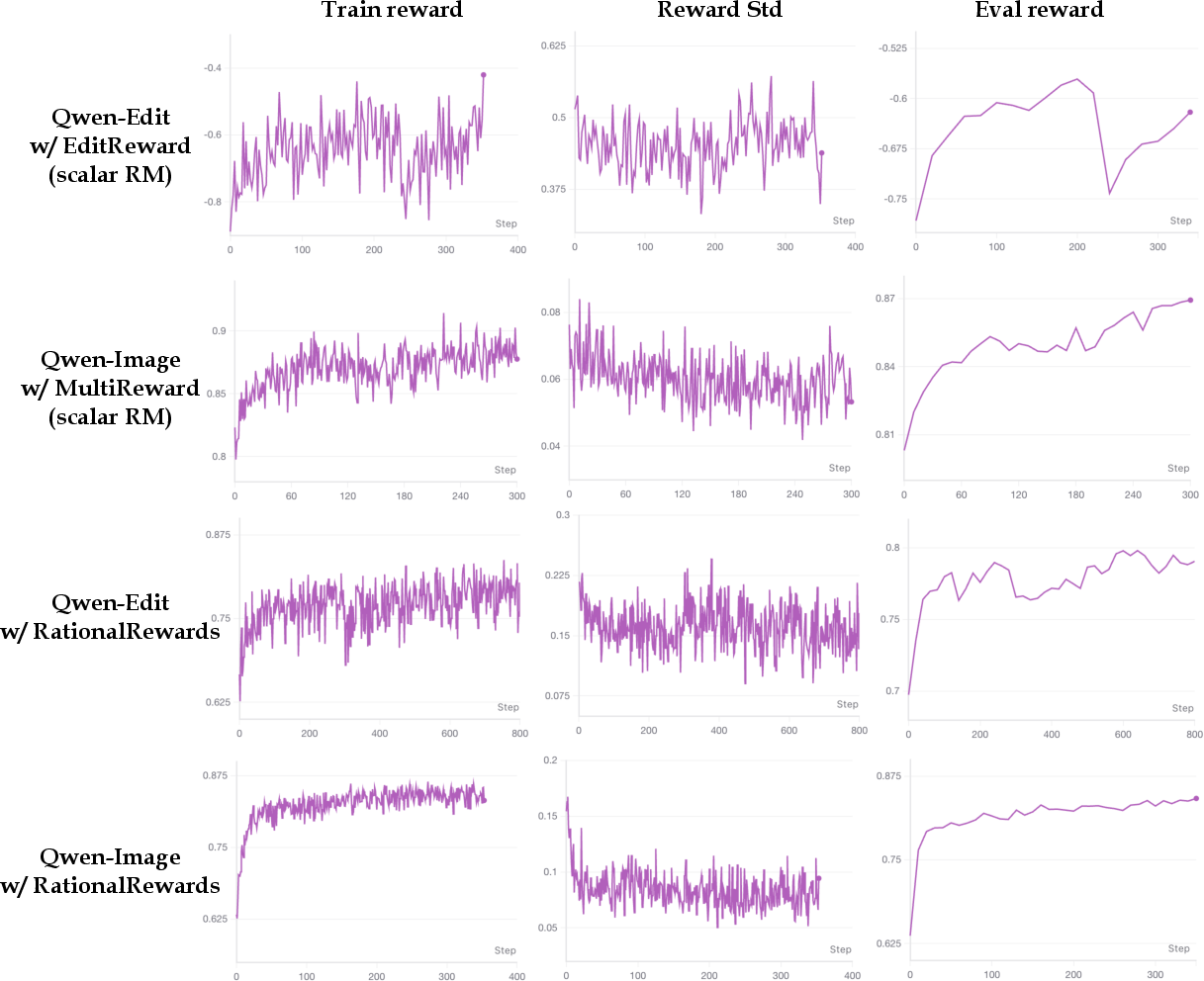
Figure 8: Training curves: RationalRewards suppresses reward hacking compared to legacy scalar reward baselines.
Test-Time Generate–Critique–Refine Loop
A critical finding is that RationalRewards can act as an optimizer at inference without model updates. The Generate–Critique–Refine (GCR) loop operates as follows: an image is synthesized, RationalRewards critiques it by generating structured rationales and improvement suggestions, then the prompt is revised and resubmitted. Notably, this finetuning-free, instance-based optimization can match or surpass expensive RL in several benchmarks, directly improving output quality by leveraging the underutilized capacity of frozen generators guided by explicit rationale feedback.

Figure 9: The GCR loop operationalizes test-time, post-hoc prompt refinement using RationalRewards’ critiques.
Empirical Results
Comprehensive evaluation benchmarks confirm several strong claims:
- Preference Modeling: RationalRewards (8B) approaches or exceeds the accuracy of recent commercial models (e.g., Gemini-2.5-Pro, GPT-4.1) in preference prediction, while using a fraction of the training data.
- Downstream Generation Quality: In text-to-image (UniGen, HPDv3) and image editing (ImgEdit-Bench, GEdit-Bench-EN) tasks, RL fine-tuned with RationalRewards consistently outperforms both scalar reward (EditReward, MultiReward) and generic reasoning-based (Qwen3-VL-32B) baselines. On several editing tasks, GCR prompt tuning delivers gains that exceed those from RL alone.
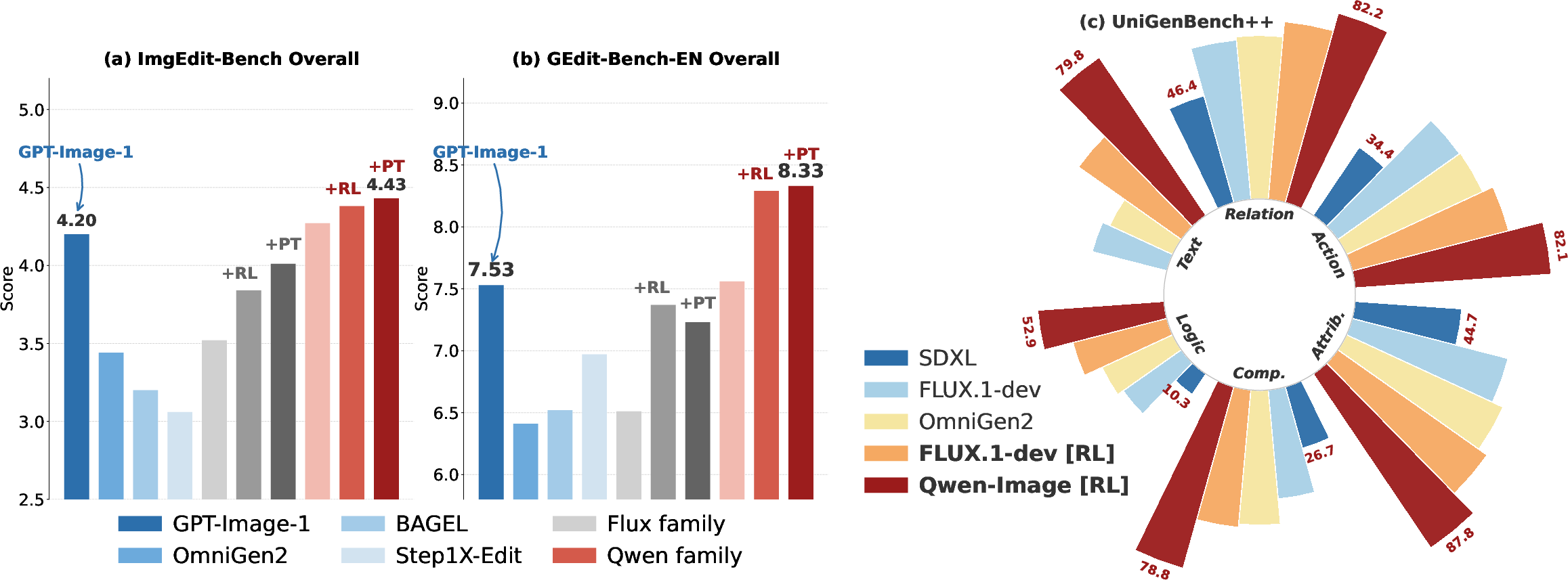
Figure 10: RationalRewards-based RL and prompt tuning—prompt optimization at inference can outperform or complement RL on multiple datasets.

Figure 11: Example multi-dimensional scores from RationalRewards highlight nuanced, per-aspect evaluation capabilities.

Figure 3: Qualitative samples: generation refinement—both in RL and prompt-tuned regimes—lead to substantial visual improvement.
Interpretability, Reward Hacking, and Flaw Grounding
The production of explicit rationales supports model interpretability and debuggability. Moreover, RationalRewards can ground critiques in pixel regions via referring expressions and produces dense, explainable visual diagnostics for generator failures (e.g., identifying and localizing specific flaws).

Figure 5: RationalRewards can link language-based critiques to spatial grounding, supporting dense segmentation of visual flaws.
RationalRewards exhibits strong resistance to classical reward hacking: training curves show robust, monotonically increasing quality metrics and much slower variance growth than scalar models, which commonly decouple score escalation from genuine quality (often resulting in visually degraded outputs).

Figure 7: Scalar reward models are prone to reward hacking, where visual quality degrades despite rising reward signals.
Implications and Future Directions
The RationalRewards paradigm has several major implications:
- Reward Rationalization: Shift from opaque scoring to generative, chain-of-thought reward assignment offers significant gains in sample efficiency, alignment, and model robustness.
- Test-Time Compute Trade-Offs: Test-time prompt optimization provides an additional axis for performance scaling, orthogonal to model/dataset/training increases. This is especially relevant in scenarios where retraining is costly or infeasible.
- Generalization and Stress Testing: RationalRewards demonstrates robustness under out-of-distribution physics-aware editing benchmarks, suggesting that structured reasoning can transfer to complex, under-explored domains.
Ongoing research should further examine rationale-based reward models in multilingual environments, video and 3D generation, and extend grounding and critique mechanisms for fine-grained failure diagnosis. Additionally, the model's bias profile, dependence on teacher VLMs, and domain-specific calibration merit comprehensive analysis before deployment in high-stakes applications.
Conclusion
RationalRewards presents a rigorous, scalable, and interpretable reward modeling paradigm for visual generation, bridging the gap between human-aligned, multi-dimensional judgment and practical optimization for contemporary generative models. Both its variational rationale distillation framework and dual-space optimization utility significantly reduce data requirements while outperforming legacy baselines in RL and prompt optimization. The findings lend strong empirical support to the latent capability hypothesis: modern generators possess substantial, under-exploited quality reserves, which can be unlocked by structured, rationale-driven critique and optimization.
Reference: "RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time" (2604.11626).