Flow-OPD: On-Policy Distillation for Flow Matching Models
Abstract: Existing Flow Matching (FM) text-to-image models suffer from two critical bottlenecks under multi-task alignment: the reward sparsity induced by scalar-valued rewards, and the gradient interference arising from jointly optimizing heterogeneous objectives, which together give rise to a 'seesaw effect' of competing metrics and pervasive reward hacking. Inspired by the success of On-Policy Distillation (OPD) in the LLM community, we propose Flow-OPD, the first unified post-training framework that integrates on-policy distillation into Flow Matching models. Flow-OPD adopts a two-stage alignment strategy: it first cultivates domain-specialized teacher models via single-reward GRPO fine-tuning, allowing each expert to reach its performance ceiling in isolation; it then establishes a robust initial policy through a Flow-based Cold-Start scheme and seamlessly consolidates heterogeneous expertise into a single student via a three-step orchestration of on-policy sampling, task-routing labeling, and dense trajectory-level supervision. We further introduce Manifold Anchor Regularization (MAR), which leverages a task-agnostic teacher to provide full-data supervision that anchors generation to a high-quality manifold, effectively mitigating the aesthetic degradation commonly observed in purely RL-driven alignment. Built upon Stable Diffusion 3.5 Medium, Flow-OPD raises the GenEval score from 63 to 92 and the OCR accuracy from 59 to 94, yielding an overall improvement of roughly 10 points over vanilla GRPO, while preserving image fidelity and human-preference alignment and exhibiting an emergent 'teacher-surpassing' effect. These results establish Flow-OPD as a scalable alignment paradigm for building generalist text-to-image models.
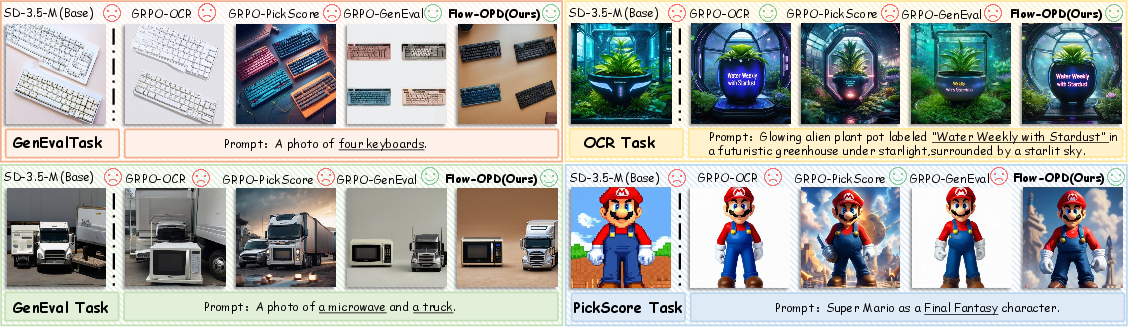
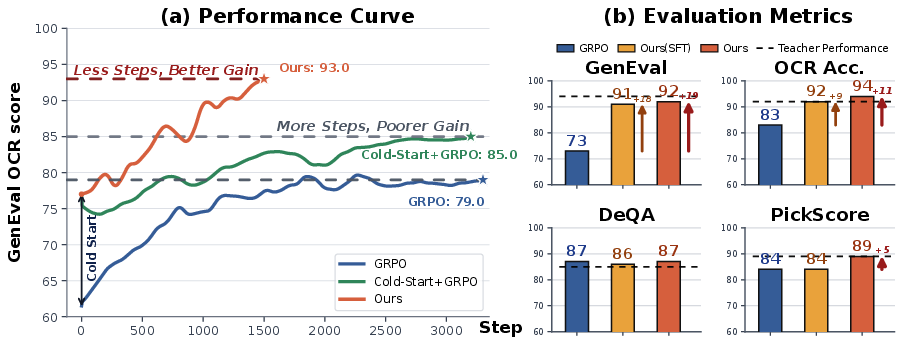

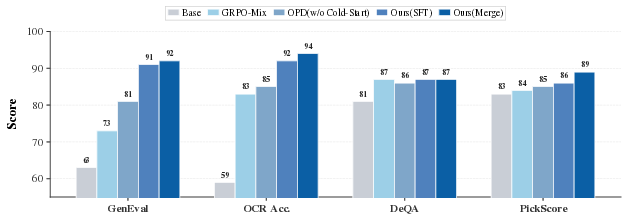






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Flow-OPD, a new way to train text-to-image AI models so they can do many different things well at the same time—like following complex instructions, drawing readable text (OCR), and making pretty, high-quality images—without one skill hurting another. It adapts a technique called on-policy distillation (OPD), popular in LLMs, to “flow matching” image models and adds a safety mechanism to keep images looking good.
What questions were the researchers trying to answer?
The team focused on four simple questions:
- How can one image model learn multiple skills (like layout, text rendering, and aesthetics) without a “seesaw effect” where improving one skill breaks another?
- Why do current reinforcement learning (RL) methods struggle when combining many goals?
- Can the success of OPD in LLMs be brought to image models that use flow matching?
- How can we keep images beautiful while improving task skills (so the model doesn’t “cheat” with ugly but high-scoring outputs)?
How did they do it?
First, a few friendly explanations:
- Flow matching: Imagine starting with a canvas full of static (noise) and moving a paintbrush over time to turn it into a picture. A flow model learns the “velocity field”—which way and how fast to move at every moment—so the final image appears smoothly.
- Distillation: Like a student learning from teachers by copying not just final answers, but how the teachers think step-by-step.
- On-policy: The student practices using its own attempts (not just pre-made examples), gets feedback from teachers on those attempts, and updates right away—like getting coaching during a scrimmage, not only in drills.
- Reward hacking: When the model finds shortcuts that boost the score but look bad to humans (e.g., readable text but ugly art).
Here’s the approach, step by step:
- Train specialist teachers
- The team first trains several “expert” teacher models, each focused on one skill (for example, one teacher is great at following instructions, another at drawing readable text, another at aesthetics), using an RL method called GRPO. Each teacher goes as far as possible on its single strength.
- Cold-start a student model
- Before combining everything, they give the student a solid starting point in one of two ways:
- SFT (Supervised Fine-Tuning): The student learns from teacher-generated examples, so it starts off “speaking the same language.”
- Model merging: They carefully blend the teachers’ parameters into a single student, like combining the best parts of multiple recipes into one.
- On-Policy Distillation (OPD) with task routing
- The student generates its own images from prompts (its “on-policy” behavior).
- A simple routing rule assigns each prompt to the right expert teacher (the one best suited to that task).
- The teacher gives dense, step-by-step guidance on the student’s own generation path (not just a single final score). This richer supervision avoids the “seesaw effect,” because each skill gives detailed feedback where it matters.
- Manifold Anchor Regularization (MAR)
- To keep images beautiful and diverse, a separate “style/aesthetic” teacher acts like guardrails. Even while the student focuses on skills like text rendering or composition, MAR pulls it back toward a high-quality “visual manifold,” so it doesn’t learn to “cheat” with low-quality but high-scoring images.
In short: multiple teachers, a well-prepared student, practice on the student’s own attempts, and a style safety net.
What did they find, and why is it important?
- Big gains on key tasks without losing image quality
- Built on Stable Diffusion 3.5 Medium, Flow-OPD improved instruction-following scores (GenEval) from about 63 to 92 and text-reading accuracy (OCR) from about 59 to 94.
- Overall, it beats standard RL training (vanilla GRPO) by about 10 points on average across benchmarks.
- No more “seesaw effect”
- Instead of trading one skill for another, the model learns multiple skills together. It avoids the common problem where tuning for, say, OCR ruins aesthetics.
- “Teacher-surpassing” effect
- Sometimes the student actually outperforms the specialized teachers on their own domains. This happens because the student learns a more balanced, holistic way to generate images by combining many teachers’ strengths.
- Better generalization
- On more challenging tests that mix skills (like compositional reasoning), the model holds up better than baselines, meaning it can handle trickier, more varied prompts.
Why this matters: It shows we can build “generalist” image generators that follow instructions well, write text clearly, and still produce beautiful, diverse images—without micromanaging lots of competing reward signals.
What’s the bigger impact?
Flow-OPD offers a scalable recipe for training future text-to-image models:
- It reduces painful reward-balancing and the risk of reward hacking.
- It combines many expert abilities into one student model in a stable way.
- It keeps image quality high while improving fine-grained skills like layout and typography.
This approach can help create next-generation creative tools that are better at understanding prompts, more reliable with complex requests, and more pleasing to humans—useful for design, education, advertising, and any place where images must be both accurate and appealing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for follow‑up work.
- Teacher selection and coverage:
- How to systematically select, validate, and refresh domain‑expert teachers, and how teacher bias or miscalibration propagates into the student.
- What happens when teacher expertise is incomplete or conflicting (e.g., prompts requiring simultaneous OCR, complex composition, and stylistic fidelity).
- Routing design and multi-domain prompts:
- The paper uses a deterministic, hard task‑routing function; no method is provided to learn, calibrate, or evaluate the router.
- Handling ambiguous or mixed‑domain prompts is not addressed (e.g., soft gating, confidence‑aware arbitration, or mixture‑of‑experts strategies).
- Robustness to misrouting and its impact on convergence and final image quality is not studied.
- Scalability beyond four tasks:
- Experiments cover four reward domains; it is unclear how performance and stability scale with many more tasks/rewards or more fine‑grained subdomains.
- Capacity limits of a single student model consolidating a larger set of experts are not analyzed.
- Computational cost and efficiency:
- The online multi‑teacher supervision at every time step is computationally heavy; no measurement or reduction strategies (e.g., caching, distillation of teachers into lightweight surrogates, step truncation, or teacher query sparsification) are reported.
- Training cost vs. GRPO baselines is not quantified (compute hours, energy), and the trade‑off between performance gains and cost is not assessed.
- Sensitivity to stochastic sampling and schedules:
- The method relies on an SDE formulation with a specific noise schedule σ_t and time weighting w(t); sensitivity analyses to these schedules, discretization (Δt), and the number of sampled trajectories G are absent.
- Impact of SDE stochasticity on final deterministic ODE inference quality and diversity is not evaluated.
- Divergence choices and optimization stability:
- Only a detached reverse‑KL (equivalently L2 on vector fields under shared covariance) is used; no comparison against forward KL, symmetric KL, α‑divergences, or entropy‑aware objectives is provided.
- No analysis of optimization stability versus reward hacking under different divergence families or trust‑region sizes (e.g., varying PPO clip ε).
- Manifold Anchor Regularization (MAR) characterization:
- MAR hinges on a single “aesthetic” teacher; robustness to teacher bias, choice of anchor teacher, and the regularization coefficient λ is not systematically explored.
- The balance between functional alignment and over‑regularization (e.g., potential suppression of rare styles or creativity) lacks quantitative study.
- No ablations on alternative anchors (e.g., base model vs. aesthetic‑optimized vs. ensemble anchors) or adaptive λ schedules.
- Cold‑start details and generality:
- Model‑merging mechanics are under‑specified (merge rules, layerwise strategies, weighting schemes); stability criteria and failure modes are not reported.
- SFT cold‑start is demonstrated only with homogeneous teachers; applicability to heterogeneous architectures/backbones is suggested but not validated.
- No head‑to‑head comparison with other initializations (e.g., LoRA merges, weight interpolation with confidence weighting, or MoE warm starts).
- Teacher‑surpassing effect:
- The hypothesized “cross‑pollination within the latent flow manifold” is not empirically dissected; no controlled ablations separating the roles of OPD, MAR, and cold‑start in producing teacher‑surpassing outcomes.
- Lack of mechanistic analysis (e.g., gradient cosine similarity tracking, representational probing, or manifold geometry diagnostics).
- Robustness and safety:
- Robustness to router errors, adversarial or out‑of‑distribution prompts, and reward misspecification is not studied.
- Safety, content moderation, and fairness are not addressed; interactions between improved OCR/compositionality and potential misuse remain unexplored.
- Evaluation breadth and validity:
- Heavy reliance on automatic metrics (GenEval, OCR accuracy, PickScore, DeQA, etc.) without a human preference study; external human evaluation is needed to validate aesthetic/semantic claims.
- Diversity and mode‑collapse are discussed qualitatively but not measured with established metrics (e.g., intra‑LPIPS, precision/recall for generative models, coverage).
- The “Avg” score aggregates differently scaled metrics; aggregation sensitivity and comparability across settings are not examined.
- Generalization and transfer:
- Results are confined to SD‑3.5‑M; transferability to other flow backbones (e.g., different latent spaces, Flux variants) and to larger/smaller model scales is untested.
- Extension to other tasks/modalities (e.g., image editing/inpainting, video, multi‑lingual OCR) remains open.
- Theoretical foundations:
- Convergence properties of the proposed OPD‑for‑flow with detached rewards and PPO clipping are not analyzed; connections to KL‑constrained RL or stability bounds are absent.
- Assumptions behind the analytic KL simplification (shared isotropic covariance between student and target) are not scrutinized for real‑world deviations.
- Interplay with multi‑objective methods:
- No comparison to alternative multi‑task conflict‑mitigation strategies (e.g., PCGrad, GradNorm, dynamic task weighting, multi‑objective RL) or to architectural MoE approaches with learned gating.
- Inference characteristics:
- Effects on sampling step counts, latency, and memory at inference are not reported; trade‑offs between improved alignment and inference efficiency remain unknown.
- Data and router supervision:
- How prompts are labeled for routing is unclear; the dataset/heuristics for building and validating the routing function are not described.
- Active data selection or curriculum strategies for on‑policy sampling under multi‑teacher supervision are not explored.
- Hyperparameter sensitivity:
- No ablation on key hyperparameters (λ for MAR, PPO ε, teacher query frequency, group size G, time‑step count T); robustness windows are not established.
- Failure cases:
- The study lacks a systematic presentation of failure modes (e.g., long texts, crowded scenes, non‑Latin scripts, complex spatial relations), making it hard to target future improvements.
Practical Applications
Practical Applications of Flow-OPD
Below are actionable applications derived from the paper’s findings, organized into immediate (deployable now) and long-term (requiring further R&D/scale) opportunities. Each item names concrete use cases, sectors, likely tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Unified, multi-objective alignment for enterprise text-to-image (T2I) models
- Sector: software, creative/advertising tech, e-commerce
- What: Replace scalar-reward GRPO fine-tuning with Flow-OPD to simultaneously hit instruction-following (GenEval), OCR accuracy, and human-preference/aesthetic targets without “seesaw” regressions or reward hacking.
- Tools/workflows: Multi-teacher orchestration (teachers per reward/domain), on-policy sampling, task routing function, MAR module; cold-start via model merging or SFT.
- Assumptions/dependencies: Access to domain teachers or reward models (e.g., GenEval, OCR, PickScore, DeQA), multi-GPU training infrastructure (on-policy sampling), rights to use base model (e.g., SD 3.5 Medium), well-defined routing rules.
- Brand-accurate ad creative and product imagery with robust text rendering
- Sector: advertising, retail/e-commerce, marketing operations
- What: Generate banners, promos, packaging mockups, and product hero images where brand names, SKUs, prices, and CTAs render accurately (OCR 59→94 reported), while preserving high aesthetics with MAR.
- Tools/workflows: Fine-tuned “student” model deployed behind creative tools; prompt templates with composition constraints; lightweight post-check with OCR.
- Assumptions/dependencies: Reliable OCR reward/teacher, brand guideline prompts/routing, content safety/usage policies.
- Poster, flyer, and social-media asset generators with layout compliance
- Sector: design tooling, SMB marketing, prosumer apps
- What: Turn spec prompts (e.g., “top-left logo, two lines of text, centered figure…”) into visually pleasing, instruction-compliant images (GenEval 63→92 reported).
- Tools/workflows: Plug-in student model within design suites; prompt validators; MAR-enabled deployment to prevent aesthetic collapse.
- Assumptions/dependencies: Access to trained Flow-OPD student; prompt schemas; UI for compositional constraints.
- Synthetic data generation for OCR and compositional vision tasks
- Sector: computer vision, VLM training, autonomous systems simulation
- What: Produce high-quality, label-consistent synthetic datasets (text-in-image, numeracy, spatial relations) for training and benchmarking OCR/VQA/grounding models.
- Tools/workflows: Automated prompt generation; curriculum of text complexity/layouts; batch generation with quality filters; teacher-based gatekeeping for consistency.
- Assumptions/dependencies: Reward/teacher coverage for targeted skills; budget for large-scale sampling; careful domain-gap analysis.
- Training pipeline stabilization for multi-task alignment
- Sector: AI infrastructure and platforms
- What: Adopt Flow-OPD (dense on-policy distillation + PPO-style clipping) to mitigate gradient interference in multi-reward settings, reducing brittle reward mixing and schedule engineering.
- Tools/workflows: Drop-in replacement for multi-reward GRPO stages; cold-start merging to reduce time-to-first-quality; MAR as an aesthetic anchor.
- Assumptions/dependencies: Logging and evaluation hooks across multiple metrics; routing heuristics or classifiers; hyperparameter tuning of noise schedules and λ for MAR.
- Enterprise customization via teacher swapping
- Sector: B2B AI services
- What: Offer customer-specific “teachers” (e.g., a brand-preference teacher or typography teacher) and distill into a single student for deployment, preserving image quality with MAR.
- Tools/workflows: Teacher registry; per-customer routing policies; periodic on-policy refresh runs to incorporate evolving preferences.
- Assumptions/dependencies: IP/licensing for teacher weights; ability to define and measure customer-aligned rewards; privacy controls.
- Safety and compliance guardrails during post-training
- Sector: platform governance, policy/compliance, content moderation
- What: Add safety/NSFW/brand-safety teachers into the OPD ensemble; route risky prompts to safety teachers while MAR preserves quality on safe content.
- Tools/workflows: Safety teacher(s) integrated into routing; audit logs of teacher attributions; red-team prompts in on-policy sampling.
- Assumptions/dependencies: High-precision safety reward models/teachers; acceptance criteria for false-positive/negative tradeoffs; regulator/enterprise policy mapping.
- Research reproducibility and benchmarking
- Sector: academia and R&D labs
- What: Use Flow-OPD as a baseline for multi-task alignment of flow models, studying teacher-surpassing effects, out-of-distribution (OOD) generalization, and trajectory-level supervision.
- Tools/workflows: Open-sourced training scripts where possible; multi-metric reporting (GenEval/OCR/DeQA/PickScore); ablations on cold-start and MAR.
- Assumptions/dependencies: Access to published teachers or the ability to train them; compute; dataset licenses.
Long-Term Applications
- Generalist visual foundation models across modalities (image→video→3D)
- Sector: media, entertainment, simulation, robotics
- What: Extend Flow-OPD to flow-based video and 3D generative models, distilling from specialist teachers (e.g., motion consistency, temporal OCR, cinematography) into a single generalist.
- Tools/products: Multi-teacher OPD for video flows; temporal MAR for visual continuity and aesthetics; scene-graph routing.
- Assumptions/dependencies: Mature flow-based video/3D backbones; scalable temporal teachers; much larger compute budgets.
- Simulation-grade synthetic worlds for autonomous systems and robotics
- Sector: robotics, AV, smart cities
- What: Generate richly composed, text-heavy environments (signage, instrument panels, dashboards) with high fidelity for training perception and planning systems.
- Tools/products: Scenario generators with domain teachers (weather, lighting, signage standards) and safety teachers; distributional coverage dashboards.
- Assumptions/dependencies: Domain-specific reward models; validation against real-world distributions; closed-loop evaluation with downstream task gains.
- Personalized multi-objective alignment for enterprises
- Sector: software/SaaS, design/marketing suites
- What: Create per-brand generalist T2I students by distilling multiple private teachers (brand style, typography, compliance, product catalog) into one deployable model.
- Tools/products: “Teacher factory” and OPD orchestration service; routing learned from customer prompt logs; MAR tuned to house aesthetic.
- Assumptions/dependencies: Secure on-prem or VPC training; data governance; ongoing on-policy refreshes as tastes change.
- Multi-lingual and domain-specific text rendering
- Sector: global marketing, education, public sector
- What: Teachers for multilingual typography and domain scripts (CJK, RTL, scientific notation) distilled into a single student for instruction-following plus OCR.
- Tools/products: Script-aware routing; locale-specific aesthetic teachers; QA harness with multilingual OCR.
- Assumptions/dependencies: High-quality multilingual OCR/reward models; typographic datasets; fairness/bias assessment.
- Safety/fairness/regulatory compliance as first-class rewards
- Sector: policy, public-interest tech, enterprise governance
- What: Incorporate fairness, watermarking, and provenance teachers alongside functionality and aesthetics to create regulation-ready models.
- Tools/products: Compliance dashboards monitoring multi-objective metrics; provenance/watermark teachers; governance playbooks.
- Assumptions/dependencies: Reliable reward models for fairness and watermarking; accepted standards; auditability of routing and updates.
- Data-centric alignment: automated teacher selection and routing
- Sector: MLOps, AI platforms
- What: Learn the routing function (which teacher to query) from data, possibly with meta-learning or confidence-aware mixtures of teachers to reduce manual rules.
- Tools/products: Router training pipeline; uncertainty-aware OPD; adaptive curriculum scheduling (competence-aware OPD).
- Assumptions/dependencies: Labels or weak signals for task attribution; monitoring for mode collapse; additional complexity in training loops.
- Cross-domain knowledge transfer via teacher-surpassing dynamics
- Sector: R&D, foundation model labs
- What: Systematically exploit the “teacher-surpassing” effect to discover composite capabilities that no single teacher provides (e.g., complex compositional reasoning with strong aesthetics).
- Tools/products: Cross-pollination experiments; latent manifold diagnostics; teacher selection strategies that maximize synergy.
- Assumptions/dependencies: Diagnostic tooling for manifold overlap; ablation bandwidth; careful metric design to avoid hidden regressions.
- OPD beyond vision: audio, code, and embodied agents
- Sector: software, gaming/audio, robotics
- What: Adapt on-policy, dense trajectory-level distillation to other flow- or policy-based generators where scalar rewards cause interference (e.g., multi-objective audio quality, code correctness + style, vision-language-action agents).
- Tools/products: Domain-appropriate dense supervision signals; anchor regularizers analogous to MAR (e.g., timbral or stylistic anchors).
- Assumptions/dependencies: Existence of robust specialist teachers per domain; tractable formulation of dense divergences; task-specific safety/compliance needs.
Notes on feasibility across all applications
- Compute and engineering: Flow-OPD is online and multi-teacher; it assumes substantial GPU resources, efficient sampling infrastructure, and PPO-style stabilization.
- Reward/teacher coverage: Practical success hinges on having reliable, diagnosable teachers/reward models per targeted competency; gaps will cap performance.
- Routing correctness: Misrouting induces interference; learned or rules-based routers must be monitored and evaluated.
- Licensing and IP: Use of base models, teachers, and datasets must comply with licenses and enterprise governance.
- Safety and misuse risks: Strong OCR/text rendering increases risks of convincing image forgeries; deploy with watermarking, provenance, and moderation teachers plus human review where needed.
Glossary
- Autoregressive (AR) models: Generative models that produce outputs sequentially, conditioning each token on previous ones. "For Autoregressive (AR) models, this optimization is formulated as minimizing the Reverse Kullback-Leibler (KL) divergence between the student and teacher distributions:"
- Cold-Start: An initialization strategy that stabilizes early training by providing a robust starting policy before online updates. "we develop a Flow-based Cold-Start strategy"
- Credit assignment: The process of attributing performance changes to specific actions or steps within a trajectory during optimization. "This formulation preserves fine-grained credit assignment while strictly bounding the policy trust region."
- DeQA: A learned image quality assessment metric/teacher used to guide aesthetic or quality alignment. "The DeQA teacher is specifically trained across the three datasets by blending DeQA and PickScore rewards at a 4:6 ratio."
- Dense trajectory-level supervision: Providing training signals at each step along generated trajectories, rather than sparse scalar rewards at the end. "dense trajectory-level supervision"
- Euler-Maruyama discretization: A numerical method for simulating stochastic differential equations by discretizing time. "Applying Euler-Maruyama discretization over a time step , the student's transition behavior acts as a local isotropic Gaussian policy:"
- Exposure bias: A mismatch arising when models trained on teacher-forced data face their own predictions at inference, degrading performance. "OPD effectively suppresses exposure bias and ensures robust generalization in interactive or iterative generation tasks."
- Flow Matching (FM): A generative modeling framework that learns continuous-time velocity fields to transport noise to data via an ODE. "Flow Matching (FM)~\cite{batifol2025flux,esser2024scaling,lipman2022flow,fang2025dualvla} has emerged as a superior paradigm for generative modeling"
- Group Relative Advantage: A normalized reward signal computed within a batch/group to stabilize policy gradients in GRPO. "it evaluates self-generated states using a Group Relative Advantage, ."
- Group Relative Policy Optimization (GRPO): An RL algorithm that optimizes policies using group-relative advantages, adapted here for flow models. "such as Group Relative Policy Optimization (GRPO)~\cite{r1}, to the flow-matching domain"
- Hard routing (mechanism): Deterministic assignment of each prompt/task to a specific expert teacher to avoid gradient interference. "we implement a hard routing mechanism "
- Isotropic Gaussian policy: A policy with equal variance in all directions, modeling transitions as Gaussian with isotropic covariance. "acts as a local isotropic Gaussian policy:"
- Kullback-Leibler (KL) divergence, Reverse: A divergence measure used here to align the student to the teacher by penalizing deviation from the teacher’s distribution. "minimizing the Reverse Kullback-Leibler (KL) divergence between the student and teacher distributions"
- Latent trajectory: The continuous path of latent variables over time that the model generates/denoises. "we map the discrete token sequence to the continuous latent trajectory ."
- Manifold Anchor Regularization (MAR): A regularizer that anchors the student to a high-quality generative manifold via a frozen teacher to prevent aesthetic collapse. "We further introduce Manifold Anchor Regularization (MAR), which leverages a task-agnostic teacher to provide full-data supervision that anchors generation to a high-quality manifold"
- Manifold collapse: Degeneration of the learned data manifold, often seen as loss of diversity or quality due to optimization pressures. "leading to manifold collapse."
- Markovian denoising process: Interpreting continuous ODE integration as a sequence of Markov state transitions for RL-style optimization. "the discretized ODE integration as a sequential Markovian denoising process."
- Model merging: Combining parameters from multiple specialized models into a unified model state to initialize training. "model merging superposes the anisotropic priors of divergent teachers into a unified parameter state."
- On-Policy Distillation (OPD): Distillation where the student learns from teachers on the student’s own sampled trajectories to avoid distribution shift. "On-Policy Distillation (OPD) dynamically couples the teacher's supervisory signal with the student’s exploration space."
- On-policy sampling: Generating samples using the current student policy to expose its own distributional errors during training. "on-policy sampling, task-routing labeling, and dense trajectory-level supervision."
- Optimal Transport (OT) formulation: A formulation where samples follow a linear path between noise and data distributions under flow matching. "Under the Optimal Transport (OT) formulation, the path is "
- Policy ratio: The ratio of new policy likelihood to old policy likelihood for an action, used in PPO-style updates. "We define the policy ratio as $\rho_{t,i,j}(\theta) = \frac{\pi_\theta(a_{t,i,j} | s_{t,i,j})}{\pi_{\theta_{old}(a_{t,i,j} | s_{t,i,j})}$."
- Probability flow ODE: The deterministic ODE equivalent of a diffusion process used to define the generative flow. "converting the deterministic probability flow ODE into an equivalent Stochastic Differential Equation (SDE)"
- Proximal Policy Optimization (PPO) clipping mechanism: A policy gradient technique that clips policy updates to enforce a trust region for stability. "we incorporate a Proximal Policy Optimization (PPO) clipping mechanism."
- Reward hacking: Exploiting imperfections in reward functions to achieve high scores with degraded true performance or quality. "which together give rise to a “seesaw effect” of competing metrics and pervasive reward hacking."
- Reward sparsity: The lack of dense or informative reward signals, making learning unstable or myopic. "the reward sparsity induced by scalar-valued rewards"
- Reward-normalization collapse: A failure mode where reward normalization across multiple objectives breaks, destabilizing training. "may suffer from reward-normalization collapse under multi-reward settings."
- Stochastic Differential Equation (SDE): A differential equation that includes stochastic (noise) terms, used to inject randomness into trajectories. "an equivalent Stochastic Differential Equation (SDE)"
- Supervised Fine-Tuning (SFT): Post-training on labeled data to adapt a model before or alongside RL/distillation. "breaking the performance ceiling of offline Supervised Fine-Tuning(SFT)."
- Task-agnostic teacher: A teacher model providing general guidance across tasks to preserve global quality. "incorporates a task-agnostic teacher to provide full-data supervision"
- Task routing: Deciding which expert teacher supervises a sample based on its task/domain. "executing task routing labeling where diverse experts provide dense supervision for respective domains"
- Teacher-surpassing effect: The phenomenon where a distilled student exceeds the performance of its teachers. "exhibiting an emergent “teacher-surpassing” effect."
- Velocity field: The time-dependent vector field that dictates how latent variables evolve during generation. "outperforming traditional diffusion models in both sampling efficiency and high-fidelity synthesis by learning continuous-time velocity fields."
Collections
Sign up for free to add this paper to one or more collections.