pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
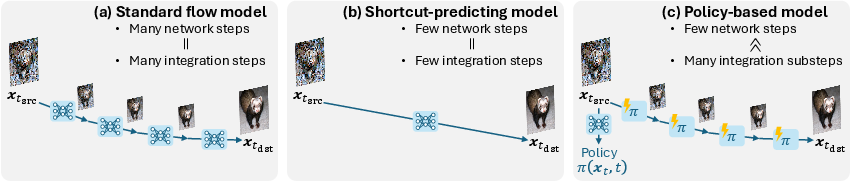
Abstract: Few-step diffusion or flow-based generative models typically distill a velocity-predicting teacher into a student that predicts a shortcut towards denoised data. This format mismatch has led to complex distillation procedures that often suffer from a quality-diversity trade-off. To address this, we propose policy-based flow models ($\pi$-Flow). $\pi$-Flow modifies the output layer of a student flow model to predict a network-free policy at one timestep. The policy then produces dynamic flow velocities at future substeps with negligible overhead, enabling fast and accurate ODE integration on these substeps without extra network evaluations. To match the policy's ODE trajectory to the teacher's, we introduce a novel imitation distillation approach, which matches the policy's velocity to the teacher's along the policy's trajectory using a standard $\ell_2$ flow matching loss. By simply mimicking the teacher's behavior, $\pi$-Flow enables stable and scalable training and avoids the quality-diversity trade-off. On ImageNet 256$2$, it attains a 1-NFE FID of 2.85, outperforming MeanFlow of the same DiT architecture. On FLUX.1-12B and Qwen-Image-20B at 4 NFEs, $\pi$-Flow achieves substantially better diversity than state-of-the-art few-step methods, while maintaining teacher-level quality.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make AI image generators faster without losing quality or variety. The method is called pi-Flow. Instead of asking a big neural network for help at many steps to turn random noise into a picture, pi-Flow teaches a smaller “student” to output a simple set of rules (a “policy”) that can guide many tiny steps on its own. This makes image creation much quicker while keeping images sharp, accurate, and diverse.
Key Questions the Paper Answers
- How can we make powerful image models generate pictures in just a few steps without sacrificing quality or variety?
- Why do many “fast” methods produce good-looking but repetitive images, and how can we avoid that?
- Can a student model learn to mimic a teacher’s behavior using a simple, stable training process?
How the Method Works (In Everyday Terms)
Imagine the teacher model as an expert hiking guide who leads you down a mountain from foggy noise to a clear photo. Normally, you ask the guide at every step, “Where should I go next?” That’s slow because the guide is expensive to consult.
pi-Flow changes this in two clever ways:
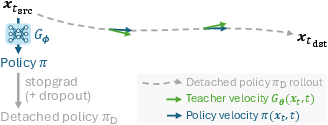
- The student predicts a policy (a lightweight rulebook).
- The student looks at where you are (the current “noisy” state) and produces a tiny, portable “set of instructions” that tells you how to move at future mini-steps.
- Using this policy, you can take many small steps downhill without asking the big network again. This saves lots of time.
- The student learns by imitation (copying the teacher along its own path).
- During training, the student rolls out its policy for a short time.
- At random checkpoints, it asks the teacher, “What direction should I be moving right here?”
- It then adjusts its policy to match the teacher’s direction.
- This simple “copy the direction” rule uses a basic loss (think: minimizing the difference between the student’s and teacher’s advice), which keeps training stable and avoids complicated tricks.
Two types of policies:
- DX policy: a simple plan that predicts a few key “anchor points” over time and connects them with straight lines. It’s fast and easy but less flexible.
- GMFlow policy: a more advanced plan that represents directions using mixtures of simple shapes (Gaussians). It adapts better when the path wiggles or encounters small errors. In practice, GMFlow is more robust and performs better.
Why this is different from older fast methods:
- Older “shortcut” students try to jump straight from fog to photo in one or a few leaps. That’s hard to learn and often leads to repeated, similar images (mode collapse).
- pi-Flow keeps the many tiny steps (so the path stays accurate), but makes each step cheap by using the student’s policy instead of calling the big network every time.
Main Findings and Why They Matter
On class-conditioned ImageNet (256×256 images):
- With just 1 network call per image (1-NFE), pi-Flow achieves a strong FID score of 2.85, beating a popular method (MeanFlow) using the same architecture.
- Translation: extremely fast generation with high image quality.
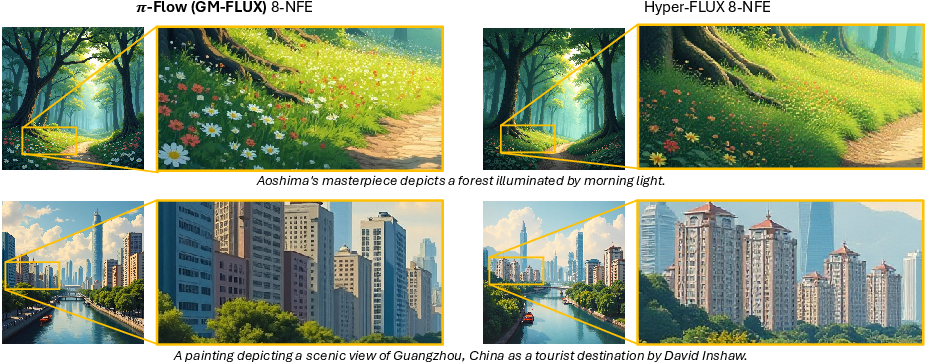
On big text-to-image models (FLUX.1-12B and Qwen-Image-20B) at 1024×1024 resolution:
- With only 4 network calls (4-NFE), pi-Flow matches the teacher’s image quality and keeps text accurate, while showing significantly better diversity than other fast methods (it avoids making many images that look alike).
- It also aligns well with the teacher’s “style” and structure, keeping details like faces, hair, and text crisp.
- Training can be “data-dependent” (using real images) or “data-free” (using only prompts and starting from noise); both work similarly well. That’s practical if you don’t have a big dataset.
Other observations:
- The GMFlow policy consistently outperforms the simpler DX policy.
- Training is stable and scales to large models without needing complex extra losses or adversarial tricks.
Implications and Potential Impact
- Faster, cheaper image generation: Fewer network calls mean lower cost and quicker results—great for phones, websites, and interactive apps.
- No trade-off between quality and variety: pi-Flow retains sharp details and faithful text while avoiding repetitive outputs.
- Simple, scalable training: A single, straightforward “imitate the teacher’s direction” loss reduces complexity and makes large-scale training more reliable.
- Broad applicability: The approach could extend beyond images to videos or other generative tasks that benefit from fast, accurate step-by-step guidance.
In short, pi-Flow shows a principled way to speed up image generation by teaching a student to produce a smart, reusable rulebook and then learn by copying a trusted teacher along its own trajectory. It’s fast, faithful, and diverse—without the usual compromises.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future research could address to strengthen and extend the pi-Flow framework.
- Lack of formal guarantees for continuous-time approximation: provide global error bounds for GMFlow policies approximating teacher ODE trajectories over continuous time (not only at discrete ), and characterize how approximation error scales with , step size, and trajectory curvature.
- Robustness theory to trajectory perturbations: quantify Lipschitz/stability properties of policy velocities under state perturbations and derive conditions ensuring recovery from deviations along the rollout.
- Impact of factorized GM parametrization: assess how the factorization limits modeling cross-channel/spatial correlations; compare against full-dimensional mixtures or coupled components and measure quality/diversity/runtime trade-offs.
- Minimal mixture complexity: determine practical lower bounds on required to achieve target quality/diversity at given NFE and resolution; provide principled selection rules or auto-tuning for and mixture temperature.
- Solver and substep schedule specification: rigorously evaluate which ODE integrators (Euler, Heun, RK4, adaptive solvers) best balance error and cost for policy velocities; study adaptive step-size control and its effect on stability and quality.
- Precise speed and resource accounting: report wall-clock latency, throughput, memory footprint, energy use, and GPU utilization across hardware for pi-Flow vs teacher and competing students; quantify overhead of policy queries vs network evaluations and dense substeps.
- Multi-NFE chaining strategy: clarify how policies are regenerated or reused across segments (e.g., 4-NFE), analyze cumulative error across segments, and explore joint training objectives for multi-segment trajectories.
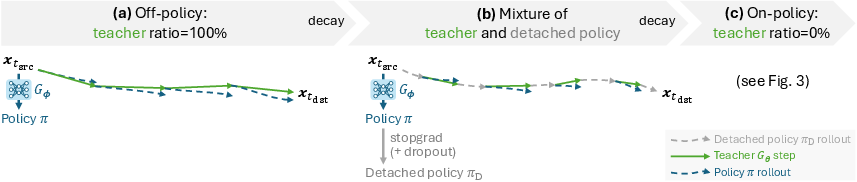
- Teacher robustness dependence: systematically measure how pi-Flow performance degrades with brittle teachers (e.g., guidance-distilled without true CFG), and develop general mitigation beyond scheduled trajectory mixing (e.g., robust matching, teacher ensembling, OOD-aware loss).
- Diversity preservation mechanisms: provide a theoretical or empirical explanation linking on-policy velocity matching to diversity preservation; evaluate diversity with stronger coverage diagnostics (e.g., precision–recall curves over multiple seeds, distribution coverage metrics).
- Policy family exploration: investigate alternative network-free policy families (e.g., spline-based velocity fields, low-rank dynamical systems, lightweight neural ODE surrogates) and compare expressiveness/robustness/efficiency.
- Hyperparameter sensitivity and auto-tuning: conduct systematic ablations on GM temperature, GM dropout rate, step-size, schedule selection, and policy output dimensionality; propose automated tuning strategies or meta-learning for stable performance across teachers/datasets.
- Data-free vs data-dependent limits: analyze scenarios with limited or noisy captions/data, domain shift (e.g., non-COCO distributions), and multilingual prompts; determine when data-free imitation underperforms and how to bridge gaps (e.g., synthetic replay or caption refinement).
- Backbone generality: test compatibility and performance with non-DiT backbones (e.g., UNet, hybrid latent transformers), smaller models, and non-visual modalities; identify architectural constraints on the expanded output head and policy generation.
- Parameter efficiency and memory scaling: quantify the overhead from expanded output layers and LoRA adapters at high resolutions; study memory–quality trade-offs and strategies to compress policy outputs without harming performance.
- Text rendering and reasoning robustness: evaluate failure modes on long, complex, or multilingual text prompts, and compositional/chain-of-thought prompts; add OCR-based metrics and controlled reasoning benchmarks to diagnose gaps vs teacher.
- CFG-scale and guidance schedule effects: analyze sensitivity to guidance scales and interval-CFG settings during teacher queries and student inference; explore whether policy-aware guidance schedules improve text alignment without harming diversity.
- Reliability across seeds and checkpoints: report confidence intervals over multiple seeds, training runs, and inference seeds to establish statistical significance of improvements; assess training stability at scale beyond single convergence plots.
- Extensibility beyond images: validate pi-Flow on video generation, 3D/NeRF, audio, and image editing tasks (e.g., inpainting, SDEdit); identify policy requirements unique to temporal consistency and geometric coherence.
- Objective enhancements: explore weighting schemes for rare modes, uncertainty-aware matching, or teacher-ensemble targets to further improve coverage; compare pure flow matching against hybrid objectives (e.g., weak adversarial/score components) without sacrificing stability.
- OOD and adversarial robustness at inference: test robustness when initial noise or conditions are corrupted, adversarially perturbed, or out-of-distribution; design policy regularizers or rollout safeguards for safety-critical deployment.
- Practical reproducibility details: provide missing specifications for scheduled trajectory mixing, GM temperature handling, and exact inference substep counts/schedules used per NFE; include ablations to show their impact on final metrics.
Practical Applications
Overview
The paper introduces pi-Flow (policy-based flow models) and π-ID (policy-based imitation distillation), a new approach to few-step generation that decouples neural network evaluations from ODE integration substeps. A student network predicts a “network-free” policy that outputs flow velocities for dense ODE substeps with negligible overhead, enabling 1–4 NFE sampling that preserves teacher-level quality and diversity. The training is a simple, stable, on-policy imitation learning procedure (DAgger-style) with a standard ℓ2 flow matching loss, avoiding complex distillation objectives and reducing quality–diversity trade-offs. It is demonstrated on ImageNet DiT and large text-to-image models (FLUX.1-12B and Qwen-Image-20B), showing superior diversity and strong teacher alignment, including successful data-free distillation.
Immediate Applications
These applications can be deployed now with existing diffusion/flow teachers and standard MLOps practices.
- Rapid, low-latency image generation for creative platforms and design tools
- pi-Flow inference engine wrapping existing DiT/Rectified Flow teachers
- “Turbo preview” toggle using GMFlow policy (K≈8–32), GM dropout during training, adjustable policy temperature at inference
- Scheduled trajectory mixing when distilling guidance-distilled teachers (e.g., FLUX.1 dev)
- Dependencies/assumptions: Access to teacher weights and licenses; simple expansion of output layers and LoRA adapters; availability of high-accuracy ODE integrators; GPU/TPU capacity for student fine-tuning.
- On-device text-to-image apps with near-teacher quality
- Quantized student models with policy-based sampling
- Lightweight LoRA personalization on-device
- Dependencies/assumptions: Model size still significant (12–20B teacher backbones); requires quantization/pruning and memory-optimized ODE integration; safety filters inherited from the teacher.
- Batch content generation for e-commerce and gaming
- Diversity audit dashboards using teacher-referenced FID/pFID
- A/B testing pipelines comparing π-ID students vs. VSD or GAN-distilled students
- Dependencies/assumptions: Compliance with brand/style guidelines; monitoring diversity to avoid unintended homogenization; compute for initial student training.
- Synthetic datasets for computer vision training
- Data-free π-ID distillation using only captions and reverse denoising
- Policy temperature/dropping to control variance and reduce mode collapse
- Dependencies/assumptions: Validation of downstream task performance; domain gap assessments; careful prompt design and bias analysis.
- Stable and scalable distillation pipelines for model deployment
- “π-ID Trainer” CI/CD jobs with reproducible configs (GM dropout rate ~0.05, LoRA rank=256, 1MP training resolution)
- Automated teacher-alignment and diversity checks (FID, pFID, CLIP, VQA, HPSv2)
- Dependencies/assumptions: Teacher must be reasonably robust to OOD states; use scheduled teacher–student mixing if guidance-distilled teacher is brittle.
- Sustainability and cost reduction in generative AI services
- “Green inference calculator” to quantify energy saved per million generations
- Procurement guidelines favoring diversity-preserving distillation (π-ID) over collapse-prone methods
- Dependencies/assumptions: Accurate measurement of energy use; governance alignment; sustainability reporting frameworks.
- Trust and safety continuity via teacher alignment
- Safety filter reuse and delta-evaluation against teacher outputs
- Watermarking/provenance tools applied consistently across teacher and student
- Dependencies/assumptions: Teacher policies are well-calibrated; periodic audits for drift and rare failure modes.
- Educational use for creative learning and prototyping
- “pi-Flow teaching kit” with interactive notebooks and tuning exercises (GM vs. DX policies, varying K/N)
- Dependencies/assumptions: Access to appropriate compute; use of public teachers or small models; consideration of content safety for minors.
Long-Term Applications
These directions require further research, scaling, or domain-specific adaptation.
- Video generation with policy-based few-step integration
- Spatiotemporal GMFlow policies with temporal smoothing and adaptive policy temperatures
- ODE integrators optimized for long horizons and temporal consistency
- Dependencies/assumptions: New policy families for temporal dynamics; teacher models for video; memory and throughput optimization; robust evaluation metrics for temporal coherence.
- Multi-modal generative systems (audio, 3D, multimodal)
- Policy-based velocity fields for waveforms or signed distance fields
- Hybrid pipelines combining π-ID with 3D optimization (DreamFusion-like workflows)
- Dependencies/assumptions: Mapping of probability flow ODEs to non-image domains; closed-form policies for new modalities; robustness to OOD trajectories.
- Robotics simulation and planning via fast synthetic visuals
- On-the-fly scene generation with controlled diversity using policy temperature
- Coupling with physics engines and task-specific annotation pipelines
- Dependencies/assumptions: High-fidelity, task-relevant visuals; rigorous validation of transfer; integration with robot perception stacks.
- Privacy-preserving synthetic medical imaging
- Domain-specific teachers and π-ID students with strict governance and auditing
- Bias and utility assessment protocols; clinical evaluation loops
- Dependencies/assumptions: Regulatory compliance (HIPAA, GDPR); thorough clinical validation; domain shift and fairness analyses.
- Personalized and on-device fine-tuning at scale
- “Personal pi-Flow Studio” for style transfer and brand kits
- Federated or on-device LoRA training with privacy guarantees
- Dependencies/assumptions: Memory constraints; private data handling; federated learning infra.
- Hardware–software co-design for policy-based generative inference
- “pi-Flow Accelerator” libraries for GPUs/NPUs; kernel-level ODE integrators
- Quantization-aware policy representations (e.g., compressed GM parameters)
- Dependencies/assumptions: Vendor support; standardized APIs; careful numerical stability guarantees.
- Standards for diversity-preserving distillation and auditing
- Diversity and alignment audit suites; reporting templates
- Best-practice guidelines recommending on-policy (π-ID) approaches over collapse-prone training
- Dependencies/assumptions: Community consensus on metrics; independent evaluation bodies; transparency about training data and licenses.
- Real-time interactive generation and streaming
- “Policy rollout servers” streaming intermediate states
- Client-side interactive controls for policy parameters (temperature, mixture dropout)
- Dependencies/assumptions: Efficient streaming protocols; low-latency inference; UX testing and human factors studies.
- Enterprise governance and risk management for generative pipelines
- Mode-collapse detectors; automated policy retraining triggers
- Multi-model ensembles with π-ID students and fallback teachers
- Dependencies/assumptions: Strong observability; change-management processes; licensing clarity for teacher weights.
Notes on Assumptions and Dependencies
- Teacher availability and robustness: π-ID assumes access to teacher models and that teachers can provide corrective velocities for on-policy states. Guidance-distilled teachers may need scheduled trajectory mixing.
- Architecture compatibility: The approach is demonstrated with DiT-style backbones and flow-matching teachers; extensions to other architectures may need reparameterization and policy design (e.g., GM factorization over sequence/channel dimensions).
- Hyperparameters and policy choices: GMFlow policies generally outperform DX policies and are more robust to trajectory perturbations; K values (e.g., 8–32) and GM dropout rates (~0.05) affect performance.
- Data needs: Data-free distillation is viable (captions + reverse denoising), but data-dependent distillation can improve domain fit; high-quality captions or prompt engineering may be required.
- Safety and compliance: Teacher-aligned students simplify reuse of safety filters, but continuous auditing for drift, bias, and misuse remains necessary.
- Compute and sustainability: Distillation requires fine-tuning compute; benefits accrue in inference at scale via reduced NFEs.
- Licensing and IP: Access to teacher weights, training data licenses, and permissible distillation practices must be verified for commercial use.
Glossary
- Classifier-Free Guidance (CFG): A guidance technique that steers generation by combining conditional and unconditional model outputs without an external classifier. Example: "classifier-free guidance (CFG)"
- Consistency Distillation (CD): A distillation approach that trains a student to be consistent with a teacher’s denoising trajectory or outputs across timesteps. Example: "consistency distillation (CD)"
- DAgger: A dataset aggregation algorithm for imitation learning that trains policies on states visited by the learner to mitigate compounding errors. Example: "a DAgger-style~\citep{dagger} on-policy imitation learning (IL) method."
- Denoising posterior: The conditional distribution of clean data given a noisy observation at time t in diffusion/flow models. Example: "with the denoising posterior $p(_0 | _t) \coloneqq \frac{\mathcal{N}(_t; \alpha_t _0, \sigma_t^2 ) p(_0)}{p(_t)}$."
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion/flow generative modeling. Example: "the standard DiT architecture"
- Distribution Matching Distillation (DMD): A distillation framework that matches the student’s output distribution to the teacher’s, often using adversarial or score-based objectives. Example: "also known as distribution matching distillation (DMD)"
- DX policy: A simple policy that uses a time-dependent estimate of the clean signal to define velocities for ODE integration. Example: "DX policy defines $\pi(_t, t)\coloneqq \frac{_t - \hat{}_0^{(t)}{t}$"
- Flow Matching: A generative modeling framework that learns a velocity field to transport noise to data via an ODE using an L2 loss. Example: "flow matching models~\citep{lipman2023flow, liu2022flow}"
- Fréchet Inception Distance (FID): A metric that measures distributional similarity between generated and reference images in a learned feature space. Example: "Fréchet Inception Distance (FID)"
- Gaussian Mixture (GM): A probabilistic model expressing a distribution as a weighted sum of Gaussian components; used here to parameterize velocity fields. Example: "factorized Gaussian mixture (GM) velocity distribution"
- GM dropout: A training regularization that stochastically drops Gaussian mixture components to improve policy robustness. Example: "we introduce GM dropout in training"
- GM temperature: A scaling of mixture component variances or logits during inference to adjust sharpness/diversity. Example: "GM temperature in inference (\S~\ref{sec:gm_temp})"
- GMFlow policy: A policy parameterization that uses a closed-form Gaussian mixture velocity field for robust, network-free substep integration. Example: "GMFlow policy"
- Guidance-distilled: A model trained to internalize guidance (e.g., CFG) within its weights, reducing reliance on external guidance at inference. Example: "is a guidance-distilled model without true CFG"
- HPSv2.1: A human preference scoring metric/version used to evaluate perceptual preference alignment of generated images. Example: "HPSv2.1"
- Imitation Learning (IL): A paradigm where a policy learns by mimicking expert (teacher) behavior, often via supervised signals. Example: "on-policy imitation learning (IL) method"
- Interval CFG: Applying classifier-free guidance only over a limited time interval to improve sample and distribution quality. Example: "Interval CFG~\citep{intervalcfg} is applied to both teachers"
- Jacobian–Vector Product (JVP): A directional derivative computation that applies a Jacobian to a vector efficiently without forming the full Jacobian; used in some distillation losses. Example: "Jacobian--vector products (JVPs)"
- LoRA adapters: Low-rank adaptation modules that enable efficient finetuning of large models by injecting trainable low-rank updates. Example: "256-rank LoRA adapters~\citep{hu2022lora}"
- Number of Function Evaluations (NFE): A measure of sampling cost counting how many times the neural network is evaluated during generation. Example: "the number of function (network) evaluations (NFEs)"
- On-policy imitation learning: Imitation learning where training uses states visited by the current learner policy to reduce covariate shift and error accumulation. Example: "On-policy imitation learning is robust to error accumulation"
- OneIG-Bench: A benchmark suite for evaluating image generation on alignment, text rendering, diversity, style, and reasoning. Example: "1120 prompts from OneIG-Bench~\citep{oneig}"
- Patch FID (pFID): A variant of FID computed on image patches to better capture local texture and detail fidelity. Example: "patch FID (pFID)"
- Policy-based imitation distillation (π-ID): The proposed distillation method that trains a policy to match teacher velocities along the policy’s own trajectory with an L2 loss. Example: "we introduce policy-based imitation distillation (-ID)"
- Posterior moment: The expected clean signal under the denoising posterior at time t; used to define velocities in DX policy. Example: "the posterior moment is only dependent on ."
- Precision–Recall: Metrics that jointly assess sample quality (precision) and sample diversity/coverage (recall). Example: "PrecisionâRecall"
- Probability flow ODE: The deterministic ODE whose solution transports noise to data following the model’s probability flow, enabling generation without stochasticity. Example: "probability flow ODE"
- Scheduled trajectory mixing: A training strategy that blends teacher and student rollouts with a time-varying ratio to improve robustness on out-of-distribution states. Example: "we adopt a scheduled trajectory mixing strategy"
- Variational Score Distillation (VSD): A distillation method that optimizes a variational objective using the teacher’s score function, often prone to mode collapse if unregularized. Example: "variational score distillation (VSD)"
- VQAScore: An automatic metric that uses visual question answering to assess text–image alignment. Example: "VQAScore~\citep{vqascore}"
Collections
Sign up for free to add this paper to one or more collections.

