- The paper presents OP-GRPO, which extends traditional on-policy GRPO with off-policy learning to enhance efficiency in flow-matching model training.
- It leverages a high-quality replay buffer and sequence-level importance correction to mitigate sample clipping and stabilize gradient updates.
- Empirical results show that OP-GRPO achieves competitive or superior performance with significantly fewer training steps in image and video synthesis tasks.
OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
Introduction
Recent innovations in flow-matching models have led to their widespread adoption as a unifying continuous generative framework for both diffusion and normalizing flow-based generative modeling. While Group Relative Policy Optimization (GRPO) has proven effective for reinforcement learning-based post-alignment of such models, its reliance on on-policy learning impedes sample efficiency and scalability. This paper presents OP-GRPO—a novel off-policy variant of GRPO that systematically overcomes these efficiency bottlenecks in preference-aware flow-matching model training (2604.04142).
Methodology
OP-GRPO Framework
OP-GRPO introduces a hybrid training paradigm, as illustrated in the overall architecture (Figure 1), which augments standard GRPO with off-policy learning via a high-quality replay buffer and principled sequence-level importance sampling corrections. The framework is structured around three core innovations:
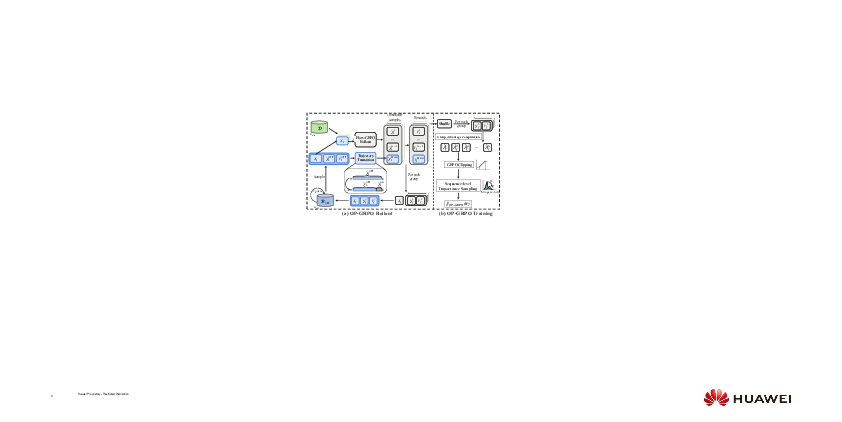
Figure 1: The overall framework of OP-GRPO, integrating off-policy trajectory sampling via a replay buffer (blue) and hybrid rollouts with dataset-driven samples (green).
- High-Quality Replay Buffer: During online rollouts, the replay buffer actively retains high-reward, diverse, and recent trajectories. A uniqueness constraint ensures one trajectory per condition, and stepwise reward decay encourages regular buffer refreshment, maintaining proximity to the current policy's distribution.
- Sequence-Level Importance Correction: To address distributional shift from buffer samples, OP-GRPO applies a correction term at the trajectory level, rather than distorting per-step importance ratios. This preserves GRPO’s update-bounding clipping while ensuring unbiased gradient estimates. Empirically, the off-policy sequence correction reduces sample clipping from 40% (naive ratio insertion) to 11.8%, enabling more effective off-policy sample utilization.
- Truncated Denoising Steps: The transition distribution sharpens rapidly toward late denoising steps, making importance weights highly ill-conditioned and numerically unstable. OP-GRPO mitigates this by truncating off-policy trajectories before these problematic regions and resampling later states with the current policy, significantly improving optimization stability.
Theoretical Analysis and Algorithmic Implications
The paper grounds its sequence-level correction via explicit policy density decomposition. It is shown that naive insertion of off-policy ratios into per-step clipping invalidates GRPO’s trust-region, with theoretical and empirical demonstrations of resultant instability and inefficient learning. By contrast, sequence-level correction integrates off-policy reweighting only when per-step updates fall within clipping bounds, enforcing the original optimization constraints.
The analysis of truncation for late denoising steps reveals that as noise decreases, the transition variance vanishes, leading to near-deterministic state transitions. This makes log-probability evaluation highly sensitive to minor errors, resulting in extremely large or small importance weights that dominate policy gradients and destabilize training. Truncating buffers before this regime, as OP-GRPO prescribes, eliminates such instability.
Empirical Evaluation
Training Efficiency and Policy Quality
On compositional image generation, visual text rendering, and human preference alignment tasks based on SD3.5-M and Wan2.1-1.4B, OP-GRPO achieves comparable or superior task and out-of-task metrics using only roughly 34.2% of Flow-GRPO’s training steps (Figure 2). Strong numerical results are observed: best compositional image generation GenEval score 0.96 versus 0.95 for Flow-GRPO; and human preference PickScore 23.44 versus 23.32.
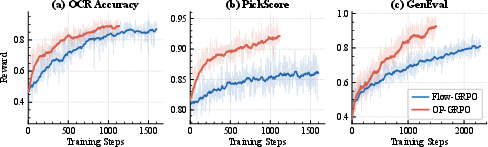
Figure 2: Training curves showcase OP-GRPO's accelerated convergence and maintenance of alignment quality compared to Flow-GRPO across several generation tasks.
Qualitative comparisons indicate more precise control over generative attributes and enhanced visual text fidelity when using OP-GRPO.
Results on Generalization and Video Generation
Comprehensive benchmarking demonstrates that OP-GRPO models trained on specific tasks generalize robustly across cross-task reward and image quality metrics, including challenging compositional text-to-image (T2I-CompBench++) evaluation, confirming the extensibility of off-policy mechanisms beyond reward overfitting.
In video generation, OP-GRPO maintains state-of-the-art sample efficiency, reaching Flow-GRPO’s terminal quality in 30.1% of training time and delivering improvements in text rendering and temporal consistency.
Ablation and Sensitivity Analysis
Ablation shows that omitting either the sequence-level correction or denoising-step truncation triggers training divergence or instability, validating the necessity of both mechanisms (Figure 3). The ratio of off-policy buffer samples is also critical: minimal use achieves only slight efficiency gain, while excessive use induces instability due to distributional drift, highlighting the importance of hyperparameter calibration.
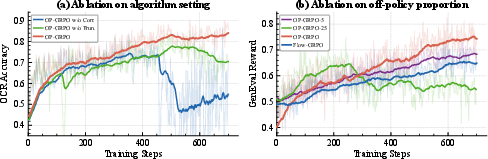
Figure 3: Ablation demonstrates that the absence of sequence correction or step truncation significantly undermines OP-GRPO stability and effectiveness.
Practical and Theoretical Implications
OP-GRPO’s contributions have direct implications for reinforcement learning-based alignment of continuous generative models:
- Scalability Improvement: Major computational reductions (up to nearly 3x sample efficiency) lower the barrier for large-scale preference optimization in diffusion and flow-matching models.
- Principled Off-Policy RL for Flows: By maintaining GRPO's trust-region and applying distribution correction only in non-clipped regimes, OP-GRPO aligns with theoretical RL stability principles and bridges off-policy RL advances in LLMs with continuous ODE-based generation.
- Robustness to Reward Sparsity: Buffer-based reuse under off-policy updates avoids vanishing gradients caused by rare high-reward events, which is pivotal for difficult tasks like video generation.
Future Directions
While this work focuses on visual generation, the approach is generalizable to other continuous generative domains (e.g., audio, 3D structure synthesis) where sample efficiency and alignment with complex rewards are critical. The design of more adaptive or prioritized replay mechanisms, dynamic truncation strategies, and integration with model-based RL for flow models represent prospective avenues for theoretical extension and empirical efficacy gains.
Conclusion
OP-GRPO extends the established on-policy GRPO framework with off-policy capabilities tailored for flow-matching generative models, systematically resolving sample efficiency bottlenecks and instability sources via replay, sequence-level correction, and denoising truncation. Extensive experimental results confirm that OP-GRPO enables faster, more robust, and more generalizable preference-aware training in both image and video synthesis contexts, marking a substantial advance in scalable RL-based alignment for generative models.