SOAR: Self-Correction for Optimal Alignment and Refinement in Diffusion Models
Abstract: The post-training pipeline for diffusion models currently has two stages: supervised fine-tuning (SFT) on curated data and reinforcement learning (RL) with reward models. A fundamental gap separates them. SFT optimizes the denoiser only on ground-truth states sampled from the forward noising process; once inference deviates from these ideal states, subsequent denoising relies on out-of-distribution generalization rather than learned correction, exhibiting the same exposure bias that afflicts autoregressive models, but accumulated along the denoising trajectory instead of the token sequence. RL can in principle address this mismatch, yet its terminal reward signal is sparse, suffers from credit-assignment difficulty, and risks reward hacking. We propose SOAR (Self-Correction for Optimal Alignment and Refinement), a bias-correction post-training method that fills this gap. Starting from a real sample, SOAR performs a single stop-gradient rollout with the current model, re-noises the resulting off-trajectory state, and supervises the model to steer back toward the original clean target. The method is on-policy, reward-free, and provides dense per-timestep supervision with no credit-assignment problem. On SD3.5-Medium, SOAR improves GenEval from 0.70 to 0.78 and OCR from 0.64 to 0.67 over SFT, while simultaneously raising all model-based preference scores. In controlled reward-specific experiments, SOAR surpasses Flow-GRPO in final metric value on both aesthetic and text-image alignment tasks, despite having no access to a reward model. Since SOAR's base loss subsumes the standard SFT objective, it can directly replace SFT as a stronger first post-training stage after pretraining, while remaining fully compatible with subsequent RL alignment.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train image-generating AI models (called diffusion or flow-matching models) so they make fewer mistakes. The method is named SOAR, which stands for Self-Correction for Optimal Alignment and Refinement. The big idea: instead of only teaching the model with perfect examples or waiting until the very end to judge a finished picture, SOAR teaches the model how to notice and fix its own small mistakes as they happen during the image-making process.
What questions are the authors trying to answer?
In simple terms, they ask:
- Why do image generators still mess up things like counting objects, drawing hands, or writing text correctly, even after lots of training?
- Can we train them in a way that helps them correct small errors early, before those errors grow into big problems?
- Can we do that without needing a separate “reward” model that scores images after they’re finished?
How do diffusion models work, and what’s the problem?
Think of a diffusion model as an artist who starts with a canvas full of random noise and, step by step, turns that noise into a clear picture. Each step is like following a “route” from noisy to clean.
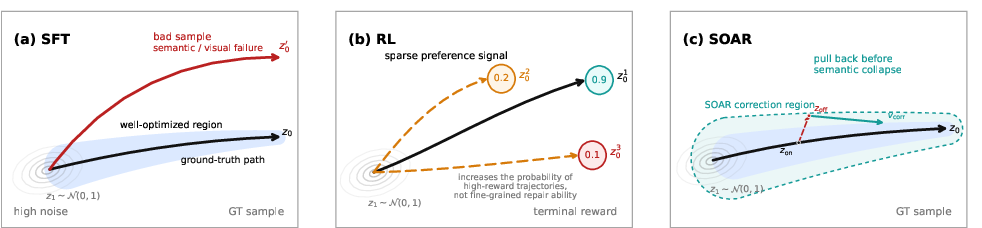
- Today’s standard training (SFT) teaches the model only on perfect, classroom-like examples: the steps are created from real images with carefully added noise. But during real use, the model has to follow its own steps. If it makes a small mistake early on, it ends up in a place it never practiced for, and errors pile up. This is called “exposure bias.”
- Another approach (RL, or reinforcement learning) waits until the final image is done, then gives a score (a “reward”) and tries to push the model toward higher-scoring pictures. But this feedback comes too late and too sparsely—it’s hard to know which step caused the mistake. It can also cause “reward hacking,” where the model chases the score in a narrow way and hurts other qualities.
What is SOAR, and how does it work?
SOAR teaches the model to correct itself mid-route, right where mistakes start. Here’s the idea in everyday language:
- Imagine you’re learning to draw a straight line. Standard training shows you perfect examples. RL grades your finished line with a single number. SOAR watches you as you draw and gently nudges your pencil back on track the moment you start to drift.
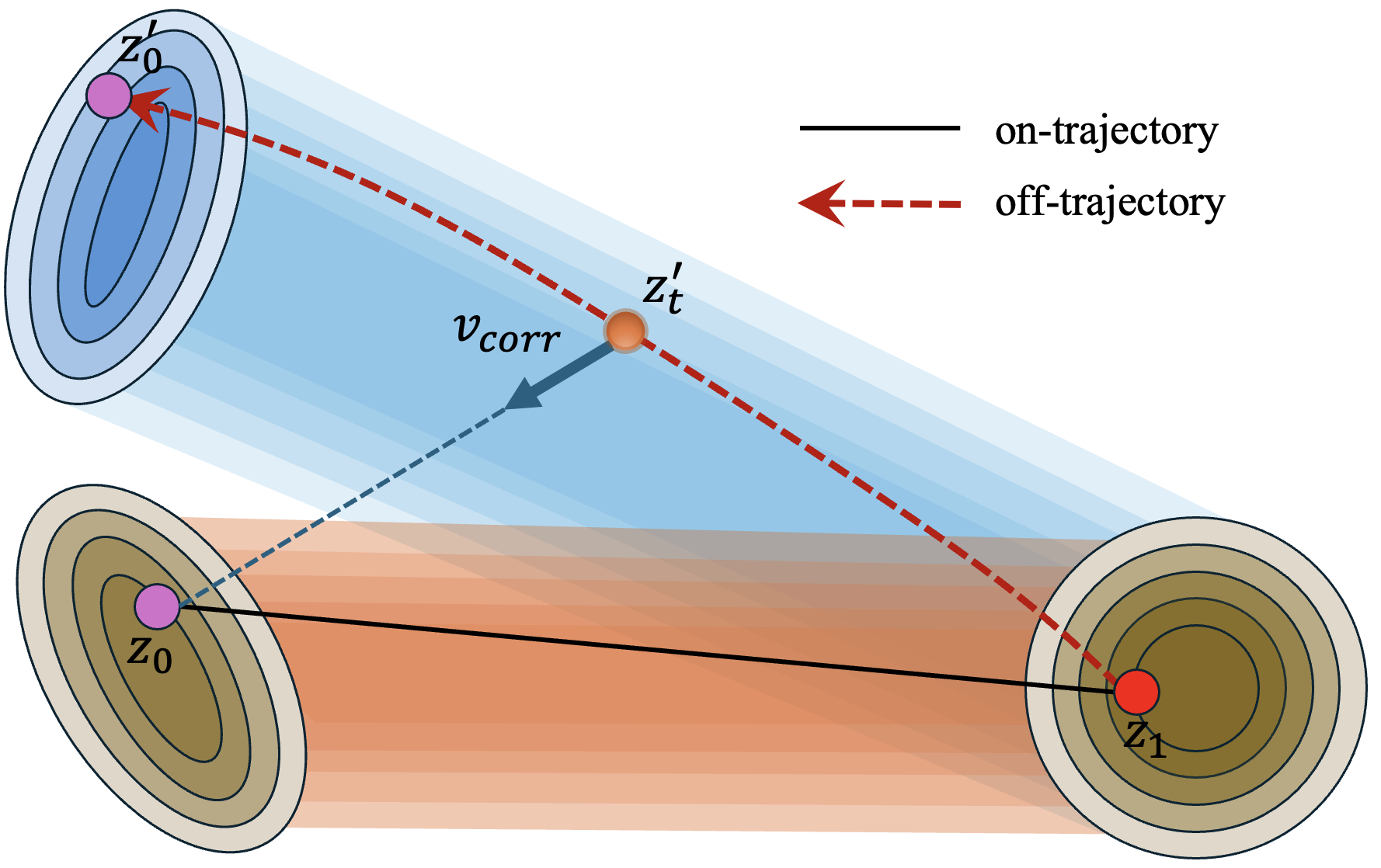
Concretely, for each real training image and its caption:
- The model creates a slightly noisy version of the image (a normal training step).
- The model takes just one real “inference-like” step using its current skills—this produces a state that’s a little off the ideal path (like drifting slightly from the lane).
- SOAR then “re-noises” this off-path state a bit (to get a few related checkpoints).
- For each of those checkpoints, SOAR teaches the model how to step back toward the original clean image. In other words, it learns the direction that corrects the drift.
Key points, in simple terms:
- On-policy: The model practices on the kinds of states it actually produces, including its own small mistakes.
- Dense feedback: It gets guidance at many steps, not just at the end.
- No reward model: It doesn’t need a separate scorer. The “right direction” is defined by aiming back at the original image.
- No credit-assignment headache: Because the fix happens at the exact step where the drift occurs, we don’t have to guess which step caused the error.
What did the experiments show?
The authors trained and tested on a popular backbone model (SD3.5-Medium) and used common benchmarks. Here’s what they found:
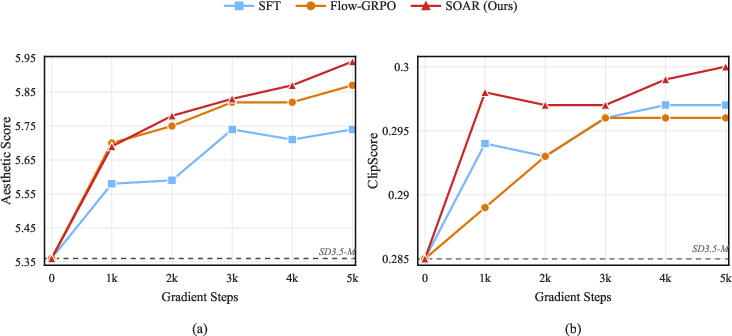
- Better accuracy on rule-based tests:
- GenEval (checks if images match complex prompts) improved from 0.70 to 0.78.
- OCR (checks text rendering in images) improved from 0.64 to 0.67.
- Better preference/model-based scores across the board (things like overall appeal and prompt-image match) improved at the same time, without using any reward model.
- When they trained on small, high-quality subsets (e.g., “high-aesthetic” or “high-CLIP-score” data), SOAR beat a state-of-the-art RL method (Flow-GRPO) on the final metrics—even though Flow-GRPO had direct access to a reward function and SOAR did not. SOAR’s improvements were also smooth and steady over time (monotonic), while RL could trade off other qualities or plateau.
Why this matters: The biggest wins were in areas where early decisions matter (like arranging objects correctly or drawing readable text). By correcting the route early, SOAR prevents small missteps from turning into big failures later.
What does this mean for the future?
- Stronger first stage after pretraining: SOAR can replace standard supervised fine-tuning (SFT) as the first post-training step because it directly fixes the “exposure bias” problem. It’s still fully compatible with later RL if you need to fine-tune a specific metric.
- Less reliance on reward models: You can get broad, reliable gains without building or trusting an external “image scorer.”
- Fewer weird failures: Things like wrong object counts, broken text, or malformed hands should happen less often, because the model learns to steer back to the right path mid-generation.
- Broader applications: The same idea—fix errors along a multi-step route—could help in video generation, 3D synthesis, or any model that improves an output step by step.
In short: SOAR teaches image models to “stay in their lane” while they’re driving from noise to picture. By correcting early and often, it makes images that match the prompt better, render text more accurately, and keep overall quality high—without needing a separate reward system.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable items for future work.
- Generalization across backbones and parameterizations: Validate SOAR on diverse architectures (e.g., SD-XL/FLUX DiTs, U-Nets), alternative diffusion parameterizations (-prediction, -prediction), and different samplers/schedules beyond rectified flow.
- Resolution and scaling: Assess performance at 768–1024+ resolutions and with larger backbones; quantify whether gains persist or diminish with higher-res sampling and larger step counts.
- Fairness of RL comparison: Re-run Flow-GRPO (and other RL baselines) with full-parameter finetuning (not LoRA) and comparable compute to isolate objective benefits from capacity limitations.
- Combined pipeline evidence: Empirically test the proposed staged pipeline (SOAR → RL) to measure synergy, stability, and reward-hacking resistance versus RL alone or SFT → RL.
- Diversity impact: Quantify effects on sample diversity using per-prompt LPIPS variance, Vendi Score, and coverage metrics; analyze prompt-conditional diversity vs. semantic validity.
- Robustness to data noise: Study sensitivity to caption noise/misalignment and propose robust targets or filtering (e.g., confidence-weighted anchors, caption denoising) for real-world imperfect datasets.
- Correction-loss weighting: Systematically design and ablate noise-dependent weights to prevent low- gradient amplification and optimize the semantic/detail trade-off.
- Multi-step vs single-step rollouts: Evaluate multi-step (or curriculum) off-trajectory rollouts and different step sizes/solvers (Heun, DPM-Solver++) to see if deeper corrections yield further gains or instability.
- Guidance-scale mismatch: Analyze sensitivity to classifier-free guidance (CFG) scales used during training rollouts vs inference, and test generalization across a range of CFG settings and guidance types.
- Off-trajectory anchor validity: Characterize when the “same anchor” assumption breaks (especially at high noise or larger drifts) and develop diagnostics/adaptive schemes (e.g., anchor confidence, early stopping of re-noising).
- Re-noising strategy: Explore alternatives to “shared ” (e.g., partial sharing, noise mixing, annealed blends) with principled weighting to balance geometric validity and supervision diversity.
- Distributional coverage: Determine how well single-step, on-policy rollouts approximate the true across later timesteps; investigate mechanisms to cover longer-horizon deviations without destabilizing training.
- Compute and memory cost: Quantify training overhead relative to SFT (FLOPs, wall time, memory) and amortized cost per improvement in metrics; profile scalability to larger batches and resolutions.
- OOD robustness and breadth: Evaluate on broader benchmarks (e.g., VBench, TIFA, VQG, long/descriptive prompts, multilingual text rendering) and domains beyond DrawBench to establish generality.
- Human preference verification: Complement model-based metrics with human studies to confirm perceptual and semantic improvements and detect failure modes not captured by automated scorers.
- Safety, bias, and fairness: Investigate how SOAR interacts with curated preferences (e.g., “high aesthetic”) and whether it amplifies dataset biases; run targeted safety/toxicity and fairness audits.
- Modality extensions: Implement and test SOAR for text-to-video, 3D generation, and inpainting/conditioned tasks (e.g., control, segmentation maps) to validate the claimed generality.
- Interaction with distillation: Examine whether applying SOAR before/after model distillation (e.g., consistency distillation) compounds gains or introduces conflicts.
- Compatibility with DPO/contrastive methods: Compare or combine SOAR with diffusion-DPO/DiffusionNFT-style objectives to assess complementary benefits and failure cases.
- Stability under different samplers: Test SDE-based training rollouts more extensively (beyond a single ablation) and across various stochastic samplers to understand when stochastic branches help/hurt.
- Metric trade-offs and reward hacking: Although SOAR is reward-free, thoroughly probe for unintended degradations across non-target metrics (e.g., realism, FID/KID, caption faithfulness) under different data curation criteria.
- Hyperparameter sensitivity: Provide a full sweep for K (steps), N (auxiliary points), M (branches), noise schedules, learning rates, and normalizers; publish best-practice ranges and failure regimes.
- Theoretical guarantees: Strengthen or formalize the conditions under which the endpoint-consistency target is optimal for off-trajectory states, especially for multi-modal endpoints and non-linear forward processes.
- Long-prompt and layout reasoning: Study whether trajectory correction scales to complex compositional reasoning (nested attributes, multi-line typography) and whether additional mechanisms are needed at high-noise stages.
- Real-world deployment: Analyze inference-time cost/benefit trade-offs, compatibility with quantization/low-precision training, and robustness under mixed-precision and distributed settings.
Practical Applications
Practical Applications of SOAR (Self-Correction for Optimal Alignment and Refinement)
SOAR is a post-training method for diffusion models that replaces standard supervised fine-tuning (SFT) with an on-policy, reward-free, per-timestep “trajectory correction.” It reduces exposure bias by supervising the model to correct its own off-trajectory states (generated via a single stop‑gradient rollout), improving compositional accuracy and text rendering while mitigating reward hacking risks typical of RL-based methods.
Below we list actionable applications, grouped by immediacy. Each item notes sectors, potential tools/workflows/products, and key assumptions/dependencies.
Immediate Applications
- Improved text rendering and compositional reliability in generative media
- Sectors: advertising/marketing, e‑commerce, publishing, gaming, film/animation, education
- What: Use SOAR to fine-tune text-to-image models to reduce wrong object counts, improve OCR (text legibility), and stabilize layouts (e.g., posters, packaging, in-game signage, book covers, worksheets).
- Tools/products/workflows:
- “Text-correct” SOAR fine-tune profiles trained on caption-accurate, typography-heavy datasets (posters, UI mockups, product labels).
- Integration into existing creative pipelines (e.g., Photoshop/Blender plug-ins or WebUI generators) as a “Trajectory Correction” toggle.
- Assumptions/dependencies: Requires curated, text-aligned (caption-image consistent) datasets; best results with rectified-flow/DiT backbones; modest compute for full-parameter fine-tuning or LoRA variants.
- Drop-in replacement for SFT in diffusion post-training pipelines
- Sectors: foundation model labs, open-source model builders, MLOps
- What: Replace SFT with SOAR as the first post-training stage to achieve on-policy, dense supervision without reward models—improving GenEval and OCR while boosting model-based preference metrics (PickScore, HPSv2.1, Aesthetic, ImageReward).
- Tools/products/workflows:
- A SOAR “trainer” module for PyTorch/Hugging Face Diffusers with default hyperparameters (single ODE step, shared z1 re-noising, configurable auxiliary points N and weight λ).
- CI/CD pipelines that run SOAR + standardized evals (GenEval, OCR, DrawBench) for regression checks.
- Assumptions/dependencies: Works best when data quality is high; validated on SD3.5-M; compute similar to SFT; depends on CFG-based ODE sampler access.
- Data-efficient alignment without reward models
- Sectors: startups, small labs, academia
- What: Achieve targeted improvements (e.g., higher aesthetics or better CLIP alignment) by training on small, reward-curated subsets—without implementing RL or maintaining reward model services.
- Tools/products/workflows:
- “Implicit reward” SOAR fine-tunes on filtered subsets (e.g., aesthetic≥6.8); lightweight LoRA variants for quick iteration.
- Automated data filtering pipelines (aesthetic/CLIP thresholds) + SOAR loop.
- Assumptions/dependencies: Relies on quality of filtering (reward-model-based filters used only for data selection, not training); monitor non-target metrics to avoid skew.
- Safer alignment with reduced reward-hacking risk
- Sectors: enterprise AI, compliance/QA, regulated industries
- What: Adopt SOAR to raise targeted quality dimensions while keeping broad quality metrics stable or improved (i.e., fewer regressions across non-target metrics compared to RL).
- Tools/products/workflows:
- SOAR-first, RL-second alignment stacks; guardrail policies requiring SOAR pass before any RL stage.
- Metric dashboards monitoring multiple dimensions (aesthetics, CLIP, OCR, HPSv2.1, ImageReward) for balanced improvements.
- Assumptions/dependencies: Requires multi-metric validation suites; governance processes to flag regressions.
- Robust UI/UX and layout-aware generation
- Sectors: software, product design, web/app prototyping, enterprise design systems
- What: Use SOAR fine-tunes on UI datasets (web/app mockups) to stabilize element placement, typography, and visual hierarchy in generated interfaces.
- Tools/products/workflows:
- “Layout-consistent” SOAR checkpoint for interface generation; integrated into design tools (Figma plugins).
- Assumptions/dependencies: High-quality UI datasets with accurate captions/annotations; verify style and brand constraints.
- Faster, simpler training cycles than RL-based methods
- Sectors: MLOps, cloud providers, research groups
- What: Reduce training complexity and compute cost vs. RL—no stochastic exploration, reward model inference, or group sampling—while achieving comparable or better final metrics on targeted subsets.
- Tools/products/workflows:
- SOAR-as-a-service for internal teams; reproducible recipes (batch size, steps, λ, N) with default ODE-only path.
- Assumptions/dependencies: Benefits depend on model family and data quality; limited exploration compared with RL may cap gains for some niche objectives.
- Training-time debugging of exposure bias
- Sectors: research, QA/quality engineering
- What: Use SOAR’s one-step rollout and re-noising to probe where denoising deviates early; visualize off-trajectory states to identify failure modes before full sampling.
- Tools/products/workflows:
- “One-step rollout” diagnostic dashboards that track deviation magnitude vs. noise level; per-prompt failure analysis.
- Assumptions/dependencies: Requires sampler hooks and logging infrastructure; helps prioritize data curation at problematic timesteps.
- Enhanced consumer-facing generative apps
- Sectors: creator tools, social apps, print-on-demand
- What: Deliver more reliable text and compositional outputs in consumer apps (e.g., posters with correct names, merch with crisp typography).
- Tools/products/workflows:
- Deploy SOAR-tuned checkpoints in mobile/web apps; expose “Text fidelity” mode with minimal latency overhead.
- Assumptions/dependencies: Ensure on-device constraints or serve via optimized inference endpoints; align content moderation policies.
Long-Term Applications
- Video generation with frame-consistent semantics and text
- Sectors: media, advertising, education, AR/VR
- What: Extend SOAR to text-to-video to correct trajectory drift across time—maintaining object counts, identity, and legible on-screen text over frames.
- Tools/products/workflows:
- SOAR-Video with temporal re-noising and off-trajectory construction; integration with video flows/SDEs.
- Assumptions/dependencies: Requires memory-efficient temporal training; generalized correction objective across time; not yet validated; likely higher compute.
- 3D and CAD-aware generation with structural consistency
- Sectors: industrial design, architecture, gaming, manufacturing
- What: Apply trajectory correction to 3D diffusion/flow models (e.g., shape/scene synthesis) to reduce off-trajectory geometry errors and maintain object structure/constraints.
- Tools/products/workflows:
- SOAR-3D modules for score/flow-based 3D pipelines; plugins for NeRF/mesh diffusion frameworks.
- Assumptions/dependencies: High-quality 3D datasets with consistent conditioning; extended correction derivations for 3D latent parameterizations.
- Foundation model distillation and fast-sampler training
- Sectors: AI labs, on-device AI, edge computing
- What: Use SOAR during model distillation (teacher→student) to maintain student on-trajectory behavior, improving sample quality at lower compute.
- Tools/products/workflows:
- “SOAR-assisted distillation” combining teacher signals with per-timestep correction on student rollouts.
- Assumptions/dependencies: Requires access to teacher/student samplers and intermediate states; careful weighting to avoid over-constraint.
- Multi-objective alignment stacks (SOAR + RL)
- Sectors: enterprise AI, creative studios
- What: Employ SOAR to stabilize general quality, then apply targeted RL (e.g., Flow-GRPO) for domain-specific gains (e.g., strict brand compliance, composition rules).
- Tools/products/workflows:
- Automated pipelines: Stage 1 (SOAR), Stage 2 (RL), with regression gating; prompt-specific reward heads only where deficits remain.
- Assumptions/dependencies: RL stage requires reward models and exploration compute; monitor for reward hacking post-RL.
- Domain-constrained generation (policy and compliance aware)
- Sectors: regulated industries (healthcare, finance), public sector
- What: Use reward-free trajectory correction as a first alignment step to reduce metric gaming and preserve broad quality, then add narrow safety/compliance constraints.
- Tools/products/workflows:
- Compliance-first alignment policy: “SOAR baseline before any reward optimization,” plus multi-metric auditing.
- Assumptions/dependencies: Requires domain-specific datasets and governance; ensure safety classifiers/filters remain effective.
- Medical and scientific image synthesis (with strict validation)
- Sectors: healthcare, life sciences, materials science
- What: Potentially improve semantic correctness in synthetic data (e.g., consistent anatomy/labels) for augmentation or simulation.
- Tools/products/workflows:
- SOAR fine-tunes on expert-annotated datasets (e.g., segmentation/labels) to reduce structural errors during denoising.
- Assumptions/dependencies: Strong clinical validation and ethics review required; high-quality annotations; regulatory clearance for downstream use; risk of reduced diversity must be quantified.
- Curriculum and pedagogy for generative model training
- Sectors: academia, education
- What: Use SOAR as a teachable module illustrating exposure bias and trajectory-level supervision in advanced ML courses; standardized lab assignments.
- Tools/products/workflows:
- Open-source notebooks implementing one-step rollout correction with visualizations over noise levels; ablation studies (z1-sharing, N, λ).
- Assumptions/dependencies: Availability of teaching-friendly datasets and compute; proper licensing.
- Standards and procurement guidance for public sector AI
- Sectors: policy, standards bodies
- What: Recommend reward-free, dense-supervision post-training (like SOAR) as a first-line alignment step to reduce reward hacking and improve auditability.
- Tools/products/workflows:
- Best-practice documents: dataset curation standards (text–image alignment), multi-metric eval suites, staged alignment (SOAR→RL if needed).
- Assumptions/dependencies: Consensus among stakeholders; empirical benchmarks to support policy.
Cross-Cutting Assumptions and Dependencies
- Data quality is pivotal: SOAR anchors correction to z0 from real samples; miscaptioned or noisy pairs reduce effectiveness and can misalign corrections.
- Method assumptions: single-step rollout deviation remains small; re-noising uses shared z1 to stay near the transport ray; current derivation assumes rectified-flow ODE with CFG access.
- Compute and integration: Similar cost to SFT; simpler than RL, but still requires access to intermediate sampler states and model internals.
- Generalization: Demonstrated on SD3.5-M; adaptation to other architectures (e.g., score-based diffusion) may require derivation tweaks.
- Diversity considerations: Trajectory correction can reduce off-trajectory variation; teams should track diversity metrics (e.g., LPIPS variance, Vendi Score) alongside quality metrics.
- Release maturity: Adoption speed depends on code availability and reference implementations; initial engineering is simplified by the provided algorithm and by leveraging existing training stacks.
By adopting SOAR as a first-stage, on-policy, reward-free post-training step, organizations can achieve immediate reliability gains in compositional and text fidelity, simplify training infrastructure, and lay a stronger foundation for targeted RL alignment when necessary.
Glossary
- 2-Wasserstein distance: A metric on probability distributions used to measure differences in predicted vs. true endpoints. "both terms minimize the 2-Wasserstein distance between the model's clean-endpoint prediction and the true "
- Aesthetic score: A learned metric estimating perceptual attractiveness of images. "reaching 5.94 aesthetic score"
- auxiliary noise levels: Additional noise levels used during training to generate extra supervision points. "re-noises this state to multiple auxiliary noise levels"
- classifier-free guidance (CFG): A sampling technique that mixes conditional and unconditional predictions to steer generation. "with classifier-free guidance (CFG)."
- clean-endpoint estimate: The model’s predicted clean latent corresponding to a noisy state. "The velocity prediction at any state and noise level implies a clean-endpoint estimate:"
- ClipScore: A model-based text–image alignment metric computed with CLIP. "model-based (PickScore, ClipScore, HPSv2.1, Aesthetic, ImageReward) metrics"
- coefficient-preserving sampling: An SDE sampling variant that preserves certain sampler coefficients while introducing stochasticity. "SDE samplers (e.g., coefficient-preserving sampling)."
- conditional optimal-transport: The OT perspective on mapping noise to data conditioned on prompts. "the conditional optimal-transport structure of rectified flow."
- credit assignment: The RL challenge of attributing terminal rewards back to individual time steps. "eliminating the credit-assignment problem entirely."
- denoiser: The network that predicts the velocity/noise needed to denoise current states. "SFT optimizes the denoiser only on ground-truth states sampled from the forward noising process"
- denoising trajectory: The sequence of latent states during iterative denoising from noise to data. "We argue that these failures share a common root: exposure bias in the denoising trajectory."
- DiT architecture: Diffusion Transformer, a transformer-based backbone for diffusion/flow models. "and the DiT architecture has become the standard backbone."
- Direct Preference Optimization (DPO): A preference-learning method that adjusts likelihoods to prefer better samples. "adapt direct preference optimization to diffusion models"
- Euler discretization: A numerical ODE integration scheme used for step-by-step sampling. "With Euler discretization over steps, each update reads"
- exposure bias: The train–test mismatch where models learn on ground-truth conditioning but infer on their own predictions. "exposure bias refers to the mismatch between ground-truth-conditioned training and autoregressive inference"
- flow matching: Training a velocity field to map noise to data along a continuous path. "minimizing the flow matching objective:"
- Flow-GRPO: An RL approach for diffusion/flow models using group-relative policy optimization with stochastic exploration. "Among the latter, Flow-GRPO is representative: it converts the deterministic ODE sampler into an equivalent SDE that preserves the marginal distribution at all timesteps, enabling stochastic exploration, and applies group-relative policy optimization (GRPO)"
- forward noising process: The corruption process that takes clean data to noisy states used for training. "ground-truth states sampled from the forward noising process"
- GenEval: A rule-based benchmark for compositional accuracy in text-to-image generation. "SOAR improves GenEval from 0.70 to 0.78"
- group-relative policy optimization (GRPO): An RL update that normalizes rewards within a group of samples to compute advantages. "applies group-relative policy optimization (GRPO)"
- HPSv2.1: A learned preference score for human-perceived image quality/alignment. "model-based (PickScore, ClipScore, HPSv2.1, Aesthetic, ImageReward) metrics"
- ImageReward: A reward model for images trained from human preferences. "model-based (PickScore, ClipScore, HPSv2.1, Aesthetic, ImageReward) metrics"
- Latent diffusion: Diffusion performed in a compressed latent space rather than pixel space. "Latent diffusion~\citep{LDM_rombach_2022} moves this process into a compressed latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that updates low-rank adapters instead of full weights. "LoRA-based policy gradients"
- Markov Decision Process (MDP): The formalism for sequential decision-making used to frame denoising for RL. "RL-style methods treat denoising as an MDP and apply policy gradients."
- ODE (ordinary differential equation): A deterministic continuous-time system used to model the denoising path. "sampling proceeds by solving the ODE from (pure noise) to (clean data)."
- off-trajectory state: A model-induced state reached during rollout that deviates from the ground-truth path. "re-noises the resulting off-trajectory state"
- on-policy: Training on states generated by the current model/policy itself. "The method is on-policy, reward-free, and provides dense per-timestep supervision"
- out-of-distribution generalization: The need for a model to handle states not seen during training. "out-of-distribution generalization rather than learned correction"
- out-of-domain (OOD): Data distributions different from the training set, used here for evaluation prompts. "out-of-domain (OOD) DrawBench"
- PickScore: A preference-based score predicting human choices for image–text pairs. "model-based (PickScore, ClipScore, HPSv2.1, Aesthetic, ImageReward) metrics"
- policy-gradient exploration: Stochastic sampling guided by policy gradients to improve reward. "apply policy-gradient exploration"
- rectified flow: A flow-matching variant with a linear interpolation path between noise and data. "Rectified flow defines a linear interpolation path between data and noise:"
- re-noising: Pushing a latent back toward higher noise to create auxiliary training states. "To generate diverse auxiliary supervision, we re-noise this off-trajectory state by interpolating it back toward the noise endpoint ."
- reward hacking: Improving a targeted metric at the cost of other qualities or diversity. "aggressive single-reward optimization risks reward hacking"
- reward model: A learned function that scores generated samples for RL-based alignment. "requiring no external reward model"
- scheduled sampling: A curriculum technique that mixes ground-truth and model predictions during training to reduce exposure bias. "Scheduled sampling and related curriculum strategies partially mitigate this gap"
- SDE (stochastic differential equation): A stochastic continuous-time system used to model noisy denoising dynamics. "converts the deterministic ODE sampler into an equivalent SDE that preserves the marginal distribution at all timesteps, enabling stochastic exploration"
- SFT (supervised fine-tuning): Post-training on curated data using the standard diffusion/flow objective. "supervised fine-tuning (SFT)"
- stop-gradient: Preventing gradients from flowing through certain computations during training. "single stop-gradient rollout"
- transport ray: The straight-line path in latent space between a data sample and its noise endpoint. "the original transport ray "
- velocity field: The vector field the model predicts to transport noisy states toward clean data. "A neural network is trained to predict the velocity field"
Collections
Sign up for free to add this paper to one or more collections.

