- The paper introduces POISE, a novel RL algorithm that replaces high-overhead critics by extracting value estimates from LLM internal states.
- It leverages a lightweight regression probe with cross-rollout pairing to achieve efficient, unbiased gradient estimation and competitive performance on math benchmarks.
- Empirical results show POISE reduces compute costs and gradient variance, enabling up to 30% faster training compared to traditional methods.
Reinforcement Learning with Internal State Value Estimation: A Technical Analysis of POISE
Introduction
The paper "Your LLM is Its Own Critic: Reinforcement Learning with Value Estimation from Actor's Internal States" (2605.07579) introduces POISE, a reinforcement learning algorithm targeting LLMs under verifiable reward regimes. The central contribution is the replacement of high-overhead value estimation, typical in Proximal Policy Optimization (PPO) or Group Relative Policy Optimization (GRPO), with a probe that leverages the actor's own hidden representations for efficient, accurate value prediction. This probe operates over both prompt and trajectory-level hidden states, with cross-rollout pairing to preserve policy gradient unbiasedness. The study exhibits that POISE achieves competitive sample efficiency and final performance on advanced mathematical reasoning benchmarks compared to state-of-the-art algorithms while drastically reducing compute requirements.
Motivation and Context
RL for LLMs with verifiable rewards necessitates baseline value estimation to mitigate gradient variance inherent in sparse, high-variance reward signals typical of complex reasoning tasks. PPO entails doubling forward passes with a parameter-scaled critic, imposing substantial compute and memory taxes; GRPO exchanges critic cost for increased sampling—requiring multiple rollouts per prompt—which inversely impacts prompt diversity and further elevates estimator variance. Both approaches bottleneck throughput and efficiency, especially as task complexity and sequence length grow.
The novel proposal underlying POISE is to extract baseline estimates from internal activations already computed by the policy model during its standard forward pass. These representations, empirically proven to encode outcome-relevant signals such as perceived difficulty or correctness, are utilized via a lightweight regression probe trained jointly with the policy. This architecture seeks to reduce both parameter and sample complexity without sacrificing variance reduction or estimator performance.
Methodology
Internal State Value Probe
Policy Optimization
Policy updates mirror PPO-style clipped surrogate objectives, with advantages computed via cross-rollout pairing. Both probe and actor are trained online with a sliding buffer of trajectories, permitting the value estimator to track the evolving policy distribution with negligible additional cost.
Sample Efficiency and Variance Reduction
A key analytic result is that, under constant compute, maximizing the number of distinct prompts per batch (enabled by the reduced per-prompt sample requirements of POISE) leads to lower gradient variance. This is formalized via a decomposition showing the batch variance is monotonically minimized as the number of rollouts per prompt decreases, provided the baseline is appropriately estimated.
Experimental Evaluation
Mathematical Reasoning Benchmarks
POISE is validated on Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B models trained on DAPO-Math-17K, and evaluated on AMC, AIME, HMMT, and BRUMO olympiad datasets using avg@32 accuracy. POISE matches DAPO—an optimized GRPO variant—within statistical variance, outperforming it in some configurations and on crucial benchmarks.
Training Efficiency
Wall-clock efficiency is noticeably superior for POISE. DAPO’s need for large, informative rollout groups inflates per-step time and compute, especially as prompts yielding uniform (degenerate) rewards must be discarded, necessitating further sampling. POISE, utilizing a continuous baseline from internal states, both increases the proportion of informative rollouts and reduces rollout sampling for the same batch size. Quantitatively, comparable training curves are realized in substantially reduced time—up to 30% faster in experimental runs.
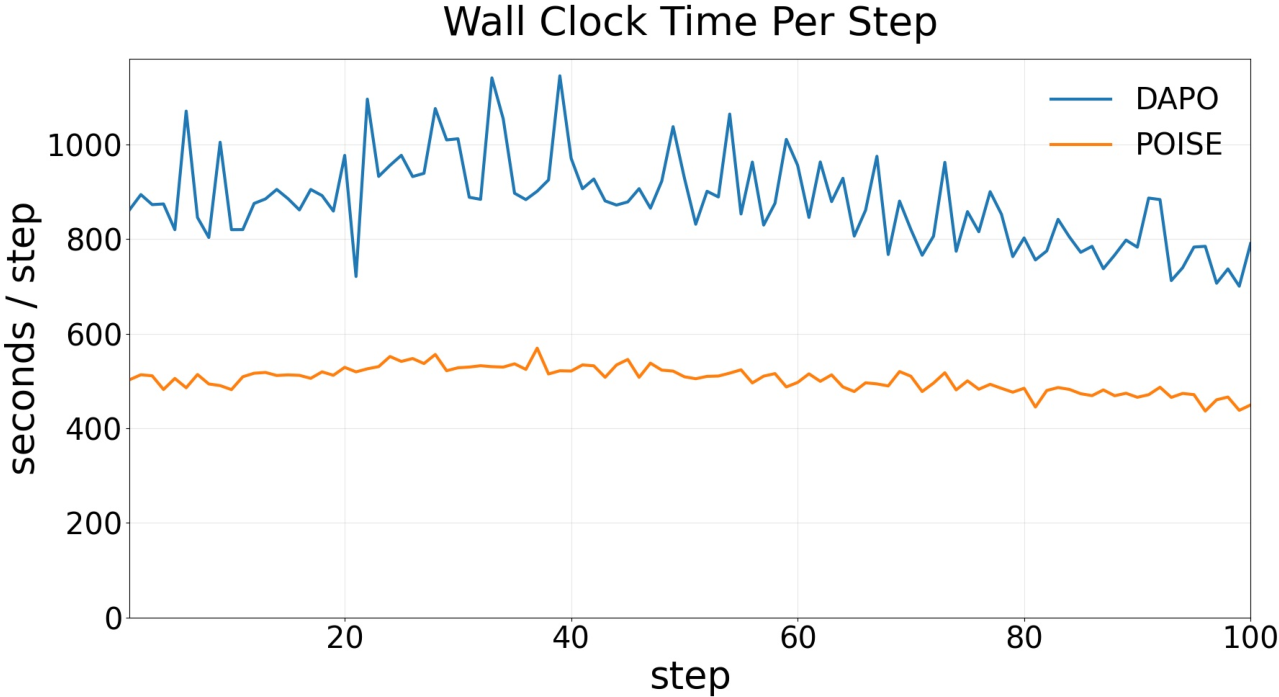
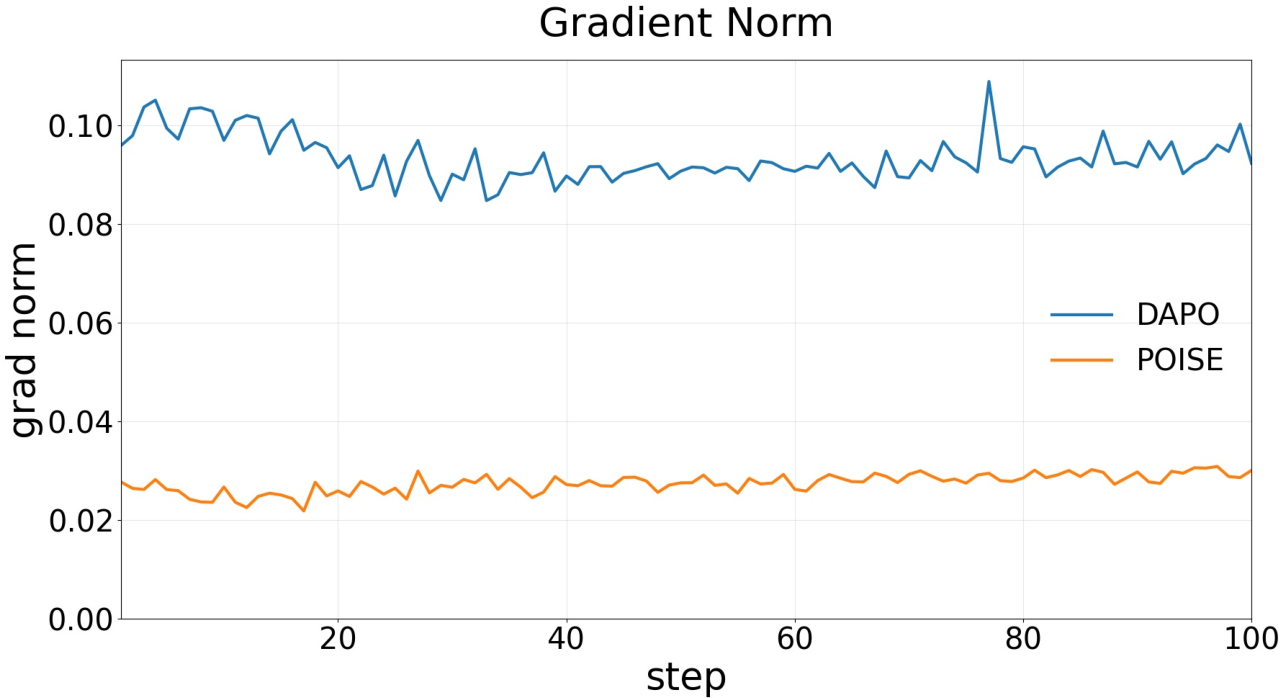
Figure 2: POISE exhibits lower wall-clock time per training step and manifests reduced gradient norm throughout training, indicating both sample efficiency and gradient stability.
Estimator Dynamics
Online mean absolute error between predicted value and empirical rollout mean remains bounded and stable across extended training, confirming the value estimator’s continuous adaptation to policy drift. The variance reduction ratio plateaus around 30%, evidencing robust advantage stabilization.
Generalization and Ablation Studies
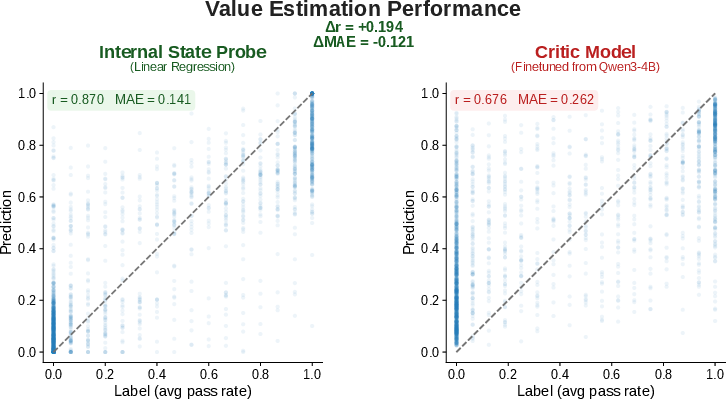
The probe’s performance is robust across domains—math, coding, tool use, and instruction following—and across model sizes, rivaling or exceeding separate LLM-scale critics in most settings. Ablation reveals that trajectory-level hidden states and entropy collectively contribute principal signal; prompt-only or length-based regressors are strictly inferior. Notably, a linear probe matches or surpasses MLP-based alternatives, validating the hypothesis that value-relevant signals are largely linearly accessible in policy activations.
Implications
Practical
POISE eliminates the need for auxiliary critic models and reduces sample requirements per prompt, enabling higher throughput and cost efficiency in RL fine-tuning of LLMs. This is particularly impactful as application domains move to longer-horizon, high-variance tasks.
Theoretical
The work substantiates that policy hidden states encapsulate sufficient statistics for verifiable reward prediction post hoc, expanding their utility from interpretability and diagnostics to online RL optimization. The cross-rollout construction and variance decomposition analyses provide generalizable methodology for future RL algorithm design under similar constraints.
Future Directions
Future extensions may adapt the estimator for token-level credit assignment, enhancing its applicability for longer-chain reasoning where location-specific advantages are required. Its integration into preference-based RL (e.g., DPO-style algorithms), or more broadly, agentic and instruction-following domains with verifiable reward functions, is a promising avenue. Scaling up and characterizing the estimator’s stability across much larger backbones or longer horizons remains open for exploration.
Conclusion
POISE demonstrates that LLMs’ own internal representations, accessed via lightweight probes, are effective, low-cost signals for baseline value estimation in RL with verifiable rewards. The approach matches state-of-the-art RLVR sample efficiency and final performance while offering substantial compute and stability advantages. The results advocate for harnessing latent knowledge inherent to the actor in future RL algorithms, reducing reliance on auxiliary critics and high-cost empirical baselines.