Dr. Post-Training: A Data Regularization Perspective on LLM Post-Training
Abstract: Data selection methods address a critical challenge in LLM post-training: effectively leveraging scarce, high-fidelity target data alongside abundant but imperfectly aligned general training data. In this work, we move beyond the data-selection framing and introduce Dr. Post-Training (Data-Regularized Post-Training), a novel framework that reconceptualizes general training data as a data-induced regularizer that prevents overfitting to the scarce target objective, rather than serving as a pool for selection. Specifically, our framework proposes that at each training step, construct a feasible set of model update directions using the general training data, and project the model update direction specified by the scarce target data onto that feasible set. Standard training and existing data selection methods arise as special cases with different choices of the data-induced regularizer, and these methods correspond to different points on a bias--variance spectrum with different regularization strength. Building on this view, we propose a family of methods offering a richer design space and more flexible bias--variance tradeoffs. For practical LLM-scale use, we introduce careful system optimizations that realize these methods with minimal overhead. Extensive experiments across SFT, RLHF, and RLVR show that our methods consistently outperform state-of-the-art data selection baselines, and system benchmarks confirm their efficiency.

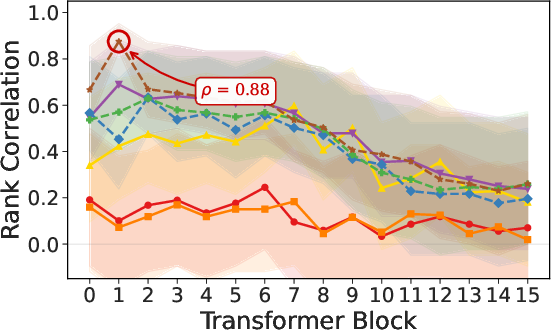
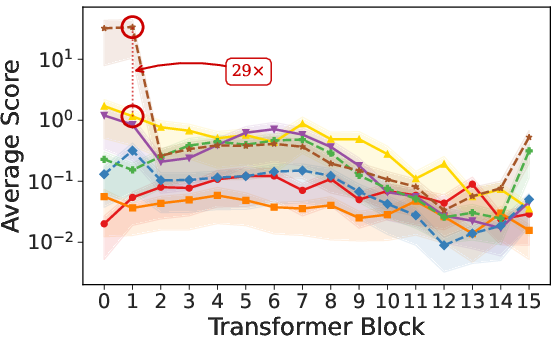
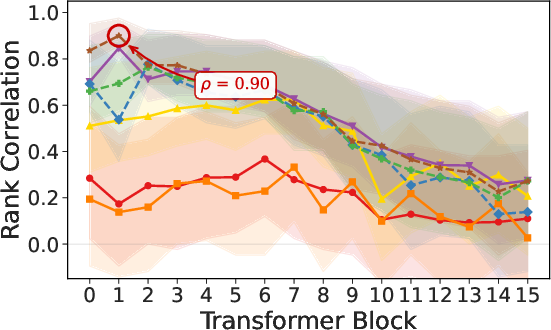
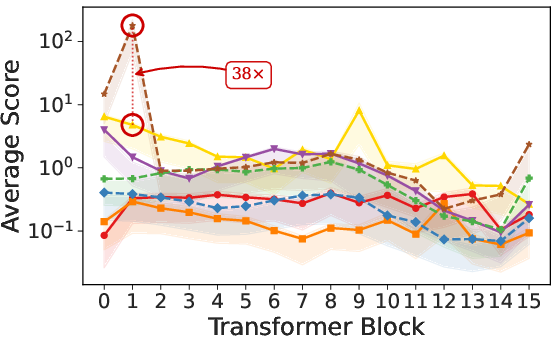
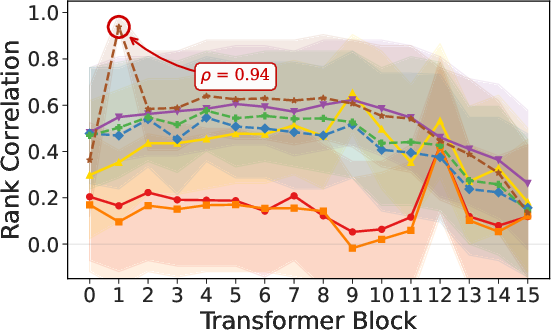
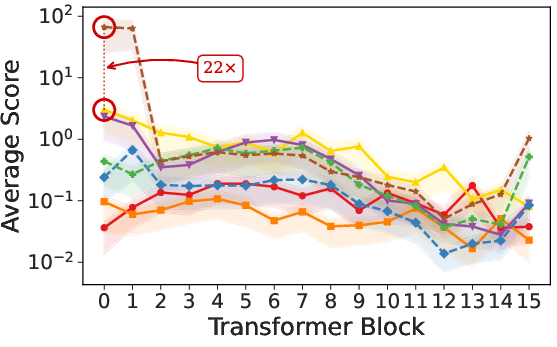
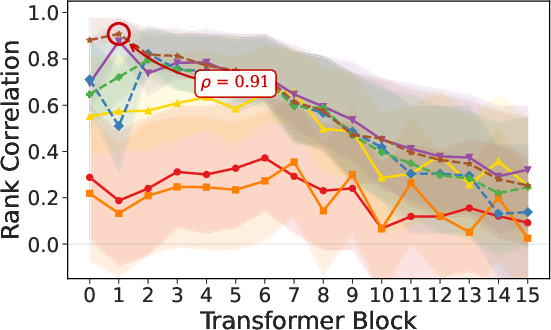
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a smarter way to train LLMs after they’ve been pre-trained, so they behave better on specific tasks. The authors introduce “Dr. Post-Training” (Data-Regularized Post-Training), a method that uses tons of general but imperfect data as helpful “guardrails” to keep the model from overfitting to a tiny amount of high-quality, task-specific data.
What questions does it try to answer?
In simple terms, the paper asks:
- We often have a little bit of excellent, expensive data (the exact behavior we want) and a lot of cheaper, somewhat related data. How can we use both together in the best way?
- Instead of just picking which general data to train on, can we treat that general data as rules that guide how the model is allowed to change, step by step?
- Can this idea give us better control over the tradeoff between being accurate to the target and being stable during training?
How did the researchers approach it?
Think of training as walking toward a destination (the target goal). Each step is a model update:
- The scarce target data tells you the “ideal direction” to walk.
- The abundant general data sets up a set of “allowed paths” so you don’t wander into bad areas (overfitting).
The key idea: at each training step, the method takes the “ideal move” suggested by the target data and then “projects” (snaps) it onto the closest move that’s allowed by the general data. In everyday terms, it’s like wanting to head straight across a field (target direction), but you agree to stick to paths (allowed directions) to avoid getting stuck in mud (overfitting).
To make this concrete, the paper shows that familiar training strategies fit inside this “allowed paths” view:
- Target-Only Update: Follow the target direction directly. This can be very accurate but wobbly (high variance) if the target data is tiny.
- Full-Training Update: Ignore the target step-by-step and just follow the average direction suggested by the general data. Very stable, but can drift away from the true target (bias).
- Global Subset Update (data selection): Pick a single small subset of general examples that best matches the target direction and move along their average. This sits between the two extremes.
Their new method, Group-Wise Subset Update, adds flexibility:
- Different parts of the model (for example, each layer) can choose their own small set of helpful general examples to follow.
- This relaxes the “one subset for the entire model” rule, so each part can better align with the target without going off the rails.
- It gives you a dial to tune how strict or flexible the “allowed paths” are, balancing accuracy vs. stability.
Because LLMs are huge, the authors also add system-level tricks to keep training efficient:
- They organize the computation so the “projection” happens within a normal forward–backward pass, avoiding big memory or time costs.
- They provide fast approximations and show it works with common memory-saving techniques like LoRA and activation checkpointing.
What did they find, and why is it important?
Main ideas and results:
- Clear tradeoff (bias–variance): Stronger rules from general data make training steady but can push you away from the exact target. Weaker rules let you match the target better but can be noisy if target data is scarce.
- Theory: They formalize this tradeoff. Target-Only has no bias (it aims exactly at the target) but can be very noisy. Full-Training is very stable (low variance) but can be biased if general and target data don’t match. Subset methods sit in between, and Group-Wise Subset Update reduces bias further by letting different model parts pick their own helpful examples.
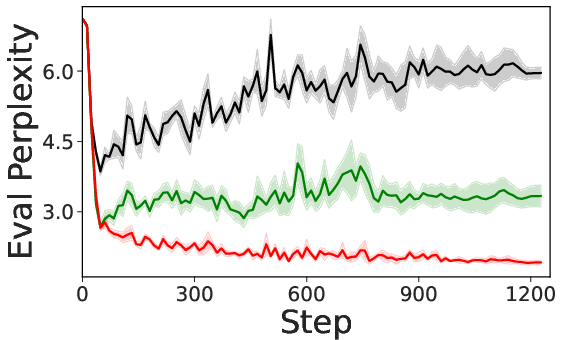
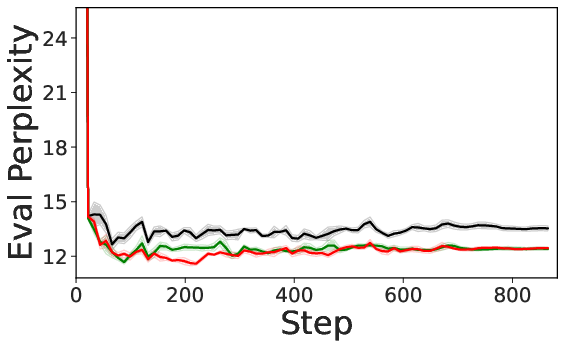
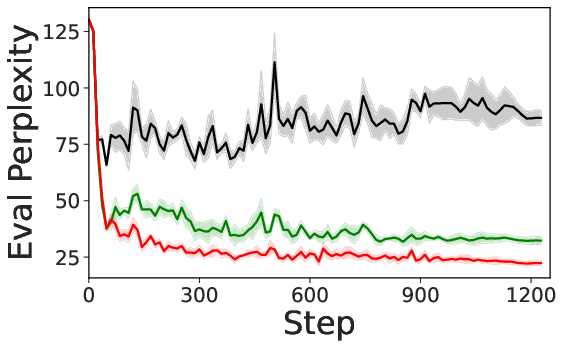
- Practice: Across three major post-training styles—SFT (supervised fine-tuning), RLHF (reinforcement learning from human feedback), and RLVR (reinforcement learning with verifiable rewards)—their methods consistently beat strong data-selection baselines. They also show the runtime and memory costs are small.
Why this matters:
- It goes beyond “which data do we pick?” to “how should the general data shape each update?” That opens a bigger and more powerful design space.
- It gives practitioners control: you can tune how cautious or aggressive your updates are, depending on how much reliable target data you have.
- It works at real LLM scale and with popular memory-saving tools.
What are the broader implications?
- Better use of scarce, high-quality data: You can get more out of a little gold-standard data by letting abundant general data safely guide each step.
- Safer and more controllable training: You can decide how strict the “guardrails” should be for your use case (for example, safety alignment vs. domain specialization).
- Unifying viewpoint: Many existing methods fit as special cases under this “data-as-regularizer” lens, helping researchers compare, improve, and invent new algorithms.
- Beyond two datasets: The same idea applies wherever you have a noisy but meaningful target signal and a more stable training signal (for example, in RL with high-variance rewards). This suggests the approach could influence future training strategies across many settings.
Key terms, simply explained
- Regularizer: A rule that keeps a model from overfitting by limiting how it can change.
- Projection: Picking the closest allowed move to your ideal move.
- Bias–variance tradeoff: A balance between being exactly right on average (low bias) and being stable across small samples (low variance). You usually can’t minimize both at once, so you tune the balance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, organized to guide future investigations.
- End-to-end convergence guarantees: The framework’s theory centers on one-step majorization and projection onto the feasible set. It lacks analysis of the full stochastic iterative process (with noisy batches, changing feasible sets U_t, adaptive optimizers) and conditions under which training converges to a stationary point or improves target risk over multiple steps.
- Optimizer compatibility: All derivations assume Euclidean projections and plain gradient descent with step size η ≤ 1/β. Practical LLM post-training typically uses Adam/AdamW, trust-region variants (e.g., PPO), and gradient clipping. How to define and analyze projections in non-Euclidean geometries (e.g., preconditioned norms, Fisher/Riemannian metrics) and with adaptive optimizers remains open.
- Robustness of assumptions: The bounds rely on β-smoothness of the target loss, bounded per-sample gradients, and sub-Gaussian target-gradient noise. These assumptions are questionable for RLHF/RLVR (non-smooth clipping, heavy-tailed gradients). A key gap is to derive guarantees under more realistic, possibly non-smooth and heavy-tailed regimes.
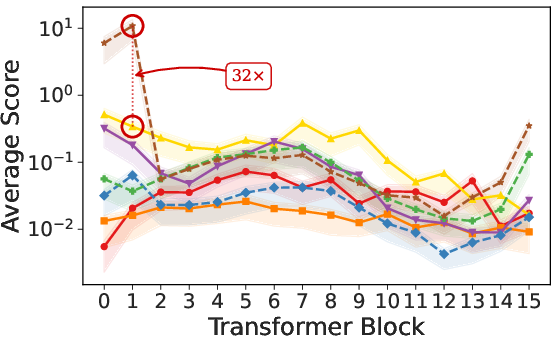
- Choice of group partition 𝓖: The group-wise subset design critically depends on how parameters are partitioned (layers, modules, heads, LoRA adapters). No principled method is provided to select or learn 𝓖. Open questions include criteria for partition granularity, automatic group discovery (e.g., gradient clustering), and adaptivity over training.
- Tuning k (subset size) and thresholds: The framework offers k and thresholding as regularization knobs, but lacks procedures to set them adaptively based on observed signal-to-noise ratios, gradient covariance estimates, or validation targets. Designing data-driven schedules for k and thresholds is an open problem.
- Redundancy-aware selection at scale: The ideal objective incorporates a redundancy penalty via ∥g_S∥², but all tractable instantiations either ignore redundancy (top‑k, thresholding) or use greedy approximations with O(nk) cost. Efficient large-scale approximations (e.g., submodular relaxations, determinantal point processes, diversity-aware sampling) are not developed.
- Complexity–variance tradeoff: Variance bounds scale with log(choose(n,k)) and linearly with the number of groups P, but bias is only characterized via set inclusions. There is no guidance for choosing P and k to minimize the combined error 𝔅(U_t)+𝔙(u_t) given target and training gradient covariances. A practical rule for optimal trade-offs is missing.
- Estimating covariance to guide regularization: The bounds and intuition depend on Σtr and Σ⋆, yet the paper does not propose estimators or use them to adapt k, P, or thresholds. Developing robust, online covariance estimation and policies that exploit these statistics is an open direction.
- Stability and forgetting: While “data regularization” is motivated as a stabilizer, there is no analysis of catastrophic forgetting, stability under distribution shift, or whether Group-Wise Subset Updates reduce/induce forgetting across tasks compared to standard SFT.
- Target-gradient availability in RLHF/RLVR: The framework assumes a differentiable target loss and per-sample gradients for both training and target batches. In RLHF/RLVR, rewards are often sparse/implicit, objectives include non-differentiable components (clipping, sampling), and per-sample gradients are non-trivial. A precise mapping from these RL objectives to “target gradients” (or suitable surrogates/control variates) and corresponding feasible sets is not formalized.
- Generalization beyond two distributions: The paper sketches extensions to multi-signal settings but does not specify how to combine multiple training signals (e.g., safety, helpfulness, domain-specific objectives) as regularizers, nor how to weigh or schedule their influence on U_t over time.
- Interaction with parameter-efficient finetuning: While compatibility is claimed, there is no analysis of how group-wise feasible sets interact with LoRA/GaLore/MeSO subspaces, whether projections should happen in the adapter subspace or full parameter space, and whether the order of subspace projection and data-regularization projection matters.
- System-level scalability and distributed training: The method requires per-sample gradients and selection, which challenges pipeline and tensor-parallel setups. The paper mentions “careful tensor lifetime scheduling” but does not analyze communication overheads, multi-GPU/multi-node scalability, or failure modes under activation checkpointing and gradient accumulation.
- Memory–compute trade-offs: There is no quantitative exploration of the memory footprint vs. throughput trade-offs introduced by per-sample gradient retention, approximate selection, or group-wise computations, nor guidelines for when approximations degrade performance.
- Adversarial and noisy training data: Using general data to constrain updates may let adversarial or low-quality samples restrict target progress. Robust feasible sets (e.g., outlier-resistant or certified-safe constraints) and defenses against malicious constraints are not explored.
- Safety and alignment impacts: The paper focuses on bias–variance but does not assess how data-induced constraints influence safety alignment, whether they propagate biases from general data, or how to incorporate safety signals explicitly into U_t.
- Metric and benchmark coverage: Empirical claims are broad (SFT, RLHF, RLVR), but the text provided lacks details on benchmarks, ablations, sensitivity analyses over k/P/thresholds, and comparisons under varying target-data scarcity. Systematic stress tests under extreme scarcity and distribution shift are needed.
- Selection proxies and cheaper signals: Computing per-sample gradients is costly. The paper does not evaluate proxies (loss, margin, Fisher, influence approximations, representation similarity) that could approximate alignment scores s_i = ⟨g_i, ĝ_⋆⟩ with lower overhead.
- Scheduling of feasible sets: U_t is rebuilt from each training batch B_t, which may introduce instability if B_t is unrepresentative. There is no exploration of temporal smoothing (momentum over feasible sets), memory of past subsets, or trust-region constraints that accumulate across steps.
- Non-convex projection behavior: Projecting onto discrete feasible sets in highly non-convex landscapes may produce undesirable local dynamics. An analysis of how these projections interact with curvature, saddle points, and layer-wise anisotropy is missing.
- Alternative norms and constraints: The Euclidean projection objective ∥u − ĝ_⋆∥² is one choice. It remains open whether other distances (Mahalanobis via Σ̂, cosine distance, layer-wise scaling), sparsity constraints, or trust-region radii yield better target progress or stability.
- Multi-objective fairness: Group-wise selection may unevenly favor layers/modules associated with high alignment scores, potentially skewing capacity across tasks. Methods to ensure fairness or balanced progress across objectives are not addressed.
- Practical selection of step size η_t: The theory uses η_t ≤ 1/β, but β is unknown in LLM settings. Adaptive step-size strategies consistent with the projection framework (including learning-rate schedules and warmup) are not specified or analyzed.
- Combining with variance-reduction techniques: Beyond data regularization, classical variance reduction (control variates, baselines, antithetic sampling) could be combined with the framework; the paper does not investigate such hybrids.
- Evaluation under label noise and partial alignment: The method assumes general data are “imperfectly aligned,” but it does not quantify sensitivity to label/reward noise and misalignment degrees, nor propose diagnostics to decide when data regularization helps vs. harms.
Practical Applications
Immediate Applications
The following items describe concrete, deployable ways to use the paper’s data-regularized post-training (Dr. Post-Training) framework, its group-wise subset update method, and the system optimizations that enable efficient LLM-scale training.
- Domain-adaptive supervised fine-tuning with scarce target data
- Sectors: healthcare (clinical note summarization), legal (contract Q&A), finance (report analysis), customer support (policy-specific responses), education (curriculum style adaptation).
- What to do: Fine-tune on a small, high-fidelity target set while using large general instruction data as a data-induced regularizer via global or group-wise subset updates. Tune the “bias–variance knobs” (subset size k and parameter grouping) to stabilize learning without biasing away from target intent.
- Tools/workflows: LoRA fine-tuning with group-wise top-k selection; training loop that computes per-step target gradient and projects onto training-batch–induced feasible sets; integrate with activation checkpointing and gradient accumulation.
- Assumptions/dependencies: Access to a modest target dataset; per-sample gradient scoring (supported by the paper’s one-pass system design); differentiable loss; mild smoothness assumptions; legal right to use general data.
- Safer RLHF with reduced overfitting to noisy preferences
- Sectors: consumer chatbots, enterprise assistants, content safety.
- What to do: During RLHF, treat human-labeled preferences as the target signal and project per-step updates onto a training-batch–induced feasible set to mitigate variance and reward overfitting.
- Tools/workflows: TRL/DeepSpeed-based RLHF training with Dr. Post-Training projection; combine with PPO/GRPO losses; monitor bias–variance via k and grouping granularity.
- Assumptions/dependencies: Preference data and reward model; ability to compute or approximate per-sample gradients; alignment with existing RLHF pipelines.
- More sample-efficient RL with verifiable rewards (RLVR)
- Sectors: coding assistants (unit-test rewards), math/logic solvers (checker/verifier rewards).
- What to do: Use verifiable rewards as a noisy but trustworthy target and regularize updates using general training data for stability and faster convergence.
- Tools/workflows: RLVR training loop with feasible-set projection; group-wise selection tuned per layer or module that most benefits from verifier feedback.
- Assumptions/dependencies: Availability of verifiers/tests; per-sample signal extraction; integration within existing RLVR frameworks.
- Online data mixture optimization without fragile offline filtering
- Sectors: model providers and ML platforms.
- What to do: Replace static data filtering/mixtures with per-step global or group-wise subset selection driven by target alignment scores s_i = <g_i, ĝ⋆>, optionally with redundancy-aware greedy selection.
- Tools/workflows: Streaming selection inside the trainer rather than pre-curation; dashboards for per-step alignment scores and effective regularization strength.
- Assumptions/dependencies: Compute budget for per-sample scoring (mitigated by the paper’s one-pass scheduling and approximations); scalable data loaders.
- Memory- and compute-aware training at LLM scale
- Sectors: MLOps/infrastructure, model labs.
- What to do: Adopt the paper’s tensor lifetime scheduling to compute and use per-sample signals in a single forward–backward pass; combine with LoRA, activation checkpointing, gradient accumulation.
- Tools/workflows: PyTorch/DeepSpeed plugin implementing Dr. Post-Training projection, per-layer top-k selectors, and approximate selection algorithms.
- Assumptions/dependencies: GPU memory budget consistent with LoRA + checkpointing; compatibility with existing trainers; operator support for per-sample gradient access.
- Enterprise guardrails and red-teaming reinforcement
- Sectors: trust & safety, compliance.
- What to do: Use a broad safety corpus to regularize updates derived from scarce, high-severity red-team findings; reduce regressions by restricting target-driven updates to safety-supported directions.
- Tools/workflows: Safety-tuned feasible sets (e.g., larger safety-aligned groups, conservative k); monitoring of harmful-output metrics alongside target-task improvements.
- Assumptions/dependencies: Availability of safety data; agreement on safety taxonomies; consistent red-team target set.
- Cost-effective data programs and labeling strategy
- Sectors: data operations, labeling vendors.
- What to do: Reduce reliance on large target datasets by leveraging abundant, cheaper general data as a regularizer; allocate label budget to the highest-value target examples.
- Tools/workflows: Labeling policy that prioritizes hard/representative target examples; continuous Dr. Post-Training to amortize general data value across iterations.
- Assumptions/dependencies: Availability and licensing of general data; modest target data for directionality.
- Academic experimentation and benchmarks on bias–variance tradeoffs in post-training
- Sectors: academia, open-source communities.
- What to do: Evaluate methods as feasible-set choices; run ablations over k and group partitions; test in SFT, RLHF, RLVR with standard suites.
- Tools/workflows: Reproducible scripts measuring approximation bias vs. variance proxies; layer-wise vs. module-wise partitions; global vs. group-wise subset comparisons.
- Assumptions/dependencies: Public datasets and models; compute for controlled studies.
- Lightweight personalization for individuals and small teams
- Sectors: prosumers, indie devs, educators.
- What to do: Fine-tune small open-source LLMs on limited personal or course data, regularized by a general instruction corpus to avoid overfitting.
- Tools/workflows: LoRA adapters with group-wise selection; simple top-k selection using cached per-sample scores; on a single or few GPUs.
- Assumptions/dependencies: Small curated target set; open general corpus; basic GPU access.
- Monitoring and observability for post-training dynamics
- Sectors: MLOps, platform tooling.
- What to do: Track alignment scores, feasible-set size, and variance bounds as training-time indicators; alert on instability or excess bias.
- Tools/workflows: Trainer callbacks exporting k, grouping, score histograms, and proxy variance metrics; tie to eval regressions.
- Assumptions/dependencies: Logging/metrics pipeline; minimal overhead acceptable in training.
Long-Term Applications
These opportunities extend the framework to broader settings or require further research, scaling, or ecosystem support.
- Automated learning of parameter groupings and regularization schedules
- Sectors: AutoML, model tooling.
- What: Learn optimal partitions (layers, heads, modules) and k over time via bandits/Bayesian optimization/curricula to adapt bias–variance to training phase and domain.
- Dependencies: Robust online selection policies; further theory for nonstationary schedules; compute for meta-optimization.
- Hardware–software co-design for per-sample operations
- Sectors: accelerators, frameworks.
- What: GPU primitives/kernels and compiler passes for efficient per-sample gradient extraction, dot products, and projections (e.g., fused scoring + selection).
- Dependencies: Vendor support (CUDA, ROCm), graph compilers, standard APIs in PyTorch/JAX.
- Privacy-preserving Dr. Post-Training
- Sectors: healthcare, finance, government.
- What: Combine feasible-set regularization with differential privacy or secure aggregation to protect per-sample gradients while retaining usefulness.
- Dependencies: DP-friendly estimators for alignment scores; privacy budget accounting; algorithmic tradeoff studies.
- Continual and streaming adaptation with shifting targets
- Sectors: consumer apps, enterprise knowledge systems.
- What: Online Dr. Post-Training where target distribution drifts; adapt group partitions and k to maintain stability and plasticity.
- Dependencies: Drift detection; memory/replay strategies; efficient on-the-fly scoring under SLAs.
- Governance and procurement policies for data-regularized training
- Sectors: policy, compliance, standards bodies.
- What: Guidelines for using abundant general data as regularizers to reduce label needs; reporting “regularization strength” (k, grouping) as part of model cards; audits to ensure target fidelity and safety.
- Dependencies: Community consensus on disclosure; regulatory adoption; third-party auditing tools.
- Extension to multimodal and embodied learning
- Sectors: vision–LLMs, robotics, autonomous systems.
- What: Apply the framework to high-variance RL/objective settings (robotics policies, VLM alignment) where verifiable rewards or weak signals guide target direction.
- Dependencies: Per-sample gradient access in multimodal stacks; verifier design (simulation/test benches); safety validation.
- Automated marketplace for “target signals”
- Sectors: model-as-a-service.
- What: Providers expose APIs for clients to upload small target batches; service runs Dr. Post-Training to produce tenant-specific adapters while regularizing with provider data.
- Dependencies: Data privacy agreements; adapter delivery; multi-tenant isolation; billing tied to data/compute.
- Stronger theoretical guarantees for nonconvex deep models
- Sectors: safety-critical applications (medical, legal).
- What: Nonasymptotic bounds relating feasible-set complexity to target loss reduction; principled rules for choosing k/grouping under constraints.
- Dependencies: Further theory beyond smoothness and boundedness assumptions; empirical validation on large models.
- On-device and edge adaptation
- Sectors: mobile, IoT, automotive.
- What: Memory-lean approximations to per-sample scoring (e.g., low-rank proxies, sketching) enabling local Dr. Post-Training on-device for personalization.
- Dependencies: Efficient approximate algorithms; limited-memory optimizers; secure local data handling.
- Integrating normative constraints into feasible sets
- Sectors: safety, fairness, policy.
- What: Define feasible sets that encode safety/fairness constraints or constitutional rules, limiting target updates to compliant directions by construction.
- Dependencies: Operationalization of constraints as gradient-space sets; certifiability; tradeoff studies between compliance and utility.
- Auto-curation and curriculum building from the regularization view
- Sectors: education technology, training platforms.
- What: Use alignment/redudancy-aware selection to automatically build curricula that progress from strong regularization to weaker as confidence grows.
- Dependencies: Confidence estimation; curriculum scheduling; cross-task transfer measurement.
- Cross-organization collaboration without data sharing
- Sectors: consortia, regulated industries.
- What: Share general-purpose regularizers (e.g., public/general corpora–induced feasible sets) while each party supplies small private target batches, achieving gains without raw data exchange.
- Dependencies: Federated or split-training protocols; policy agreements; secure aggregation of regularizer artifacts.
Each application’s feasibility depends on: access to both general and target data; support for per-sample gradients or faithful approximations; acceptable overhead (mitigated by the paper’s one-pass scheduling and approximations); and the validity of underlying assumptions (smoothness of the target loss, bounded gradients/sub-Gaussian noise for certain bounds). Careful tuning of subset size k and parameter grouping is central to controlling the bias–variance tradeoff and should be monitored as part of standard training observability.
Glossary
- Activation checkpointing: A memory-saving technique that recomputes activations during backpropagation instead of storing them, reducing peak memory usage at the cost of extra compute. "Activation checkpointing~\citep{chen2016training} discards intermediate activations during the forward pass and recomputes them on-the-fly during the backward pass, trading additional computation for reduced memory footprint."
- Bias--variance tradeoff: The fundamental tradeoff where stronger regularization reduces variance but increases bias, and weaker regularization reduces bias but increases variance. "This viewpoint suggests that the complexity of the feasible set controls a bias--variance tradeoff."
- Data-induced regularizer: A mechanism where available (general) data constrain the update directions during training, stabilizing optimization on scarce target data. "reconceptualizes general training data as a data-induced regularizer that prevents overfitting to the scarce target objective"
- Data-Regularized Post-Training (Dr. Post-Training): The paper’s framework that uses general training data to regularize target-driven updates rather than to select data. "In this work, we move beyond the data-selection framing and introduce Dr.\ Post-Training (Data-Regularized Post-Training), a novel framework that reconceptualizes general training data as a data-induced regularizer"
- Euclidean projection: The operation of projecting a vector onto a set under the L2 norm to find the closest feasible direction. "yields a Euclidean projection $u_t = \Proj_{U_t}(\hat{g}_\star)$, or equivalently"
- Feasible set: The set of permissible model update directions defined by the training batch that constrains target-driven optimization. "the training batch regularizes this update by restricting it to lie in the feasible set ."
- Full-Training Update: An instantiation where the update direction is constrained to the aggregate training-batch gradient, ignoring the target batch. "The Full-Training Update recovers standard gradient descent on the general training distribution, as in general-purpose SFT"
- Global Subset Update: An instantiation where the update is the average gradient of a single selected subset of training samples shared across all parameters. "We refer to this instantiation as the Global Subset Update, since a single subset is shared across all parameters"
- Gradient accumulation: A technique that accumulates gradients over multiple micro-batches to simulate a larger effective batch size under memory constraints. "Another technique, called gradient accumulation, is widely adopted in popular large-scale training frameworks~\citep{rasley2020deepspeed,vonwerra2022trl,sheng2024hybridflow}, partitions a large batch into micro-batches processed sequentially, accumulating gradients across micro-batches to simulate a larger effective batch size at a fraction of the peak memory cost."
- Group-Wise Subset Update: A method that selects different training-sample subsets per parameter group to relax global coupling and tune regularization strength. "We refer to this instantiation as the Group-Wise Subset Update."
- GRPO (Group Relative Policy Optimization): A reinforcement learning estimator that stabilizes training via group-relative comparisons, at the cost of bias. "or GRPO's group-relative estimator~\citep{shao2024deepseekmath}"
- Influence-style estimators: Techniques that estimate the effect of individual training examples on downstream performance for data selection. "offline example-level selection via influence-style estimators, validation-based scoring, or importance weighting"
- Layer-Wise Subset Update: A special case of group-wise selection where each layer forms a group that selects its own subset of samples. "A practically important special case is the Layer-Wise Subset Update, where each group corresponds to the parameters of a single layer."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters while keeping base model weights frozen. "Low-Rank Adaptation (LoRA)~\citep{hu2022lora} injects trainable low-rank adapters into selected layers while keeping the pretrained parameters frozen, significantly reducing memory and compute requirements"
- Majorization--minimization principle: An optimization strategy that minimizes a surrogate upper bound of the objective to obtain tractable updates. "We therefore apply the majorization--minimization principle~\citep{lange2000optimization,mairal2013optimization,lange2016mm}"
- Mean squared error (MSE): The expected squared distance between an estimated update and the true target gradient, used to analyze progress. "We measure this error by the conditional mean squared error (MSE)"
- Memory-efficient Subspace Optimization (MeSO): Methods that compress optimizer states and gradients into a low-dimensional subspace to reduce memory use. "Memory-efficient Subspace Optimization (MeSO) methods~\citep{zhao2024galore,muhamed2024grass,he2025subspace} instead compress optimizer states and gradients by projecting them into a low-dimensional representation"
- Policy gradient: A reinforcement learning method that directly estimates gradients of expected reward, often high-variance. "directly optimizing it via policy gradient is high-variance."
- Population loss: The expected loss over a data distribution, as opposed to empirical loss on a finite sample. "the corresponding population loss and the gradient are then defined as "
- PPO (Proximal Policy Optimization): A popular RL algorithm that stabilizes policy updates using a clipped objective. "PPO's clipped loss~\citep{schulman2017proximal}"
- Quadratic majorization upper bound: A smoothness-based quadratic upper bound on the loss used to derive tractable update rules. "the target loss admits the following quadratic majorization upper bound:"
- Reinforcement learning from human feedback (RLHF): An RL approach that optimizes models using human preference signals. "reinforcement learning (RL) variants such as reinforcement learning from human feedback (RLHF)~\citep{christiano2017deep,ouyang2022training}"
- Reinforcement learning with verifiable rewards (RLVR): An RL approach that uses programmatically verifiable reward signals. "reinforcement learning with verifiable rewards (RLVR)~\citep{guo2025deepseek}"
- Sub-Gaussian noise: A probabilistic assumption that noise has tail behavior bounded by a Gaussian, enabling concentration bounds. "and also a standard sub-Gaussian noise assumption~\citep{lan2020first,liu2023high}"
- Supervised fine-tuning (SFT): Post-training that adapts a pretrained LLM using labeled instruction-following data. "It is typically carried out through supervised fine-tuning (SFT)~\citep{mishra2022cross,muennighoff2024generative}"
- Target-Only Update: An instantiation that updates purely using target-batch gradients, ignoring general training data. "The Target-Only Update recovers gradient descent on the target batch , completely ignoring the training batch ."
- Tensor lifetime scheduling: A systems optimization that schedules when tensors are retained or freed to meet memory constraints. "a customized tensor lifetime scheduling strategy that selectively retains and releases intermediate quantities in the computation graph"
- Top-k selection: A subset selection heuristic that picks the k highest-scoring samples, ignoring redundancy. "Top-. Choose the samples with the largest scores , ignoring the redundancy penalty."
Collections
Sign up for free to add this paper to one or more collections.

