- The paper presents a taxonomy categorizing five key data-centric methods to enhance LLM post-training performance.
- It details techniques for data selection, quality enhancement, synthetic data generation, distillation, and self-evolving ecosystems to reduce manual annotation costs.
- The study highlights challenges in domain adaptation, scalability, and evaluation, offering directions for future research in data-efficient LLM training.
Efficient LLM Post-Training: Data-Centric Strategies
This paper systematically explores the data-efficient post-training of LLMs, proposing a comprehensive taxonomy of methodologies aimed at optimizing data usage to enhance model performance. The work addresses the key challenges facing the current paradigms of LLMs, particularly the high costs associated with manual data annotation and the diminishing marginal returns as data scales. By categorizing cutting-edge methods within five distinct areas—data selection, quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems—the paper offers a structured framework for improving data efficiency in LLM post-training.
Introduction to Data-Efficient Post-Training
Post-training of LLMs is increasingly pivotal for achieving domain adaptation and exploiting their full potential. This paper addresses the data challenges inherent in post-training, emphasizing the prohibitive costs and inefficiencies of traditional data practices. It illustrates that the solution lies not merely in increasing the volume of data, but rather in refining its quality and selection.
Theoretical insights are grounded on achieving superior LLM performance through efficient data practices that integrate reinforcement learning strategies, evidenced by successful applications like DeepSeek-R1. This methodological shift is crucial for advancing LLM capabilities across various tasks, from human alignment to complex instruction tuning.
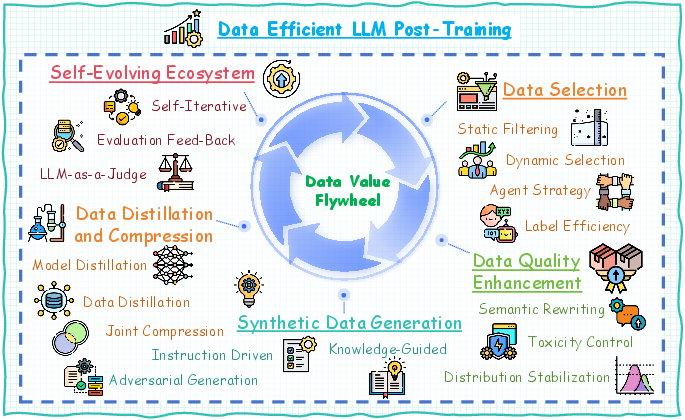
Figure 1: Illustration of the data flywheel in Data-Efficient LLM Post-Training, depicting the iterative cycle of data selection, data quality enhancement, synthetic data generation, knowledge distillation, and self-evolving data ecosystems to maximize model performance with minimal data requirements.
Taxonomy of Data-Efficient Methods
The authors categorize advanced post-training methodologies into five core areas:
- Data Selection: Identifying valuable data subsets using static and dynamic filtering approaches to optimize training efficiency.
- Data Quality Enhancement: Implementing techniques like semantic rewriting and toxicity control to improve data utility and safety.
- Synthetic Data Generation: Developing new training samples through instruction-driven, knowledge-guided, and adversarial generation strategies.
- Data Distillation and Compression: Extracting essential learning components to facilitate model efficiency without sacrificing performance.
- Self-Evolving Data Ecosystems: Establishing systems for real-time data generation and continuous learning enhancements.
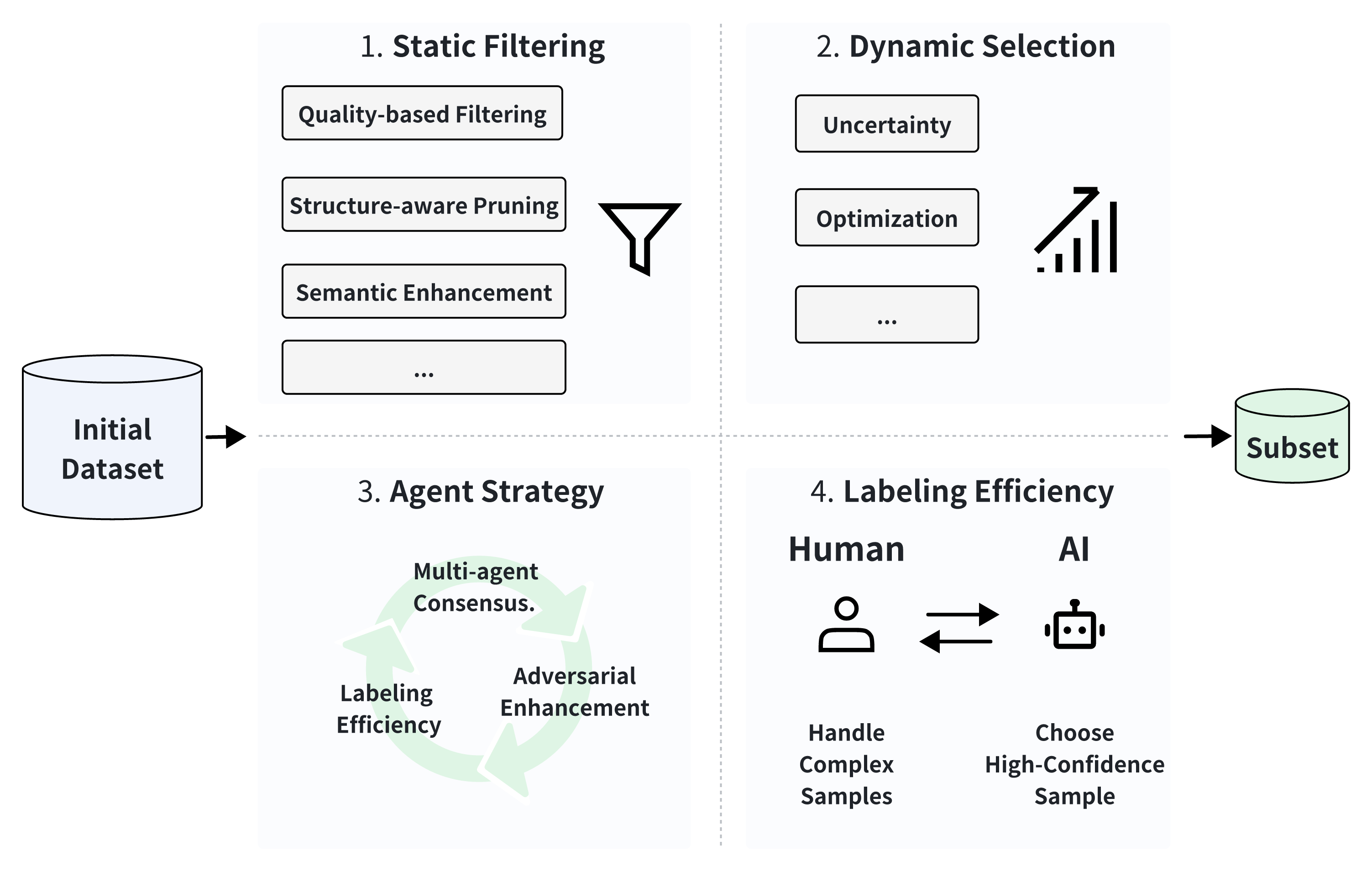
Figure 2: Overview of four major data selection approach categories: static filtering, dynamic selection, agent strategy, and labeling efficiency.
Key Challenges and Directions for Future Research
Despite notable progress in data-efficient post-training techniques, several challenges remain:
- Domain-Specific Optimization: Current methods often lack the capability to fully leverage domain-specific knowledge without substantial manual intervention.
- Scalability: Many efficient data generation frameworks face scalability limitations, which impact large-scale LLM management.
- Standardized Evaluation Metrics: The complexity of accurate quality evaluation in synthetic datasets necessitates robust, standardized approaches.
Future research should focus on integrating domain-specific models with efficient refinement techniques, enhancing scalability in large-scale data environments, and developing reliable evaluation metrics that can universally assess synthetic data quality.
Conclusion
The paper "A Survey on Efficient LLM Training: From Data-centric Perspectives" (2510.25817) underscores the evolving landscape of LLM post-training, highlighting critical methodologies and their implications. By presenting a unified taxonomy of data-efficient methods and detailing the intricacies of each strategy, the work serves as a foundational resource for ongoing research and innovation in the field. The proposed methodologies not only aim to optimize data usage but also to establish frameworks for sustainable and adaptable LLM development, fostering the growth of sophisticated model training approaches.
In essence, the pursuit of data efficiency in LLM post-training is more than an academic endeavor—it represents a strategic alignment of resources, methodologies, and innovative thinking to propel the capabilities and applications of LLMs into new domains.

