- The paper introduces the Plasticity-Ceiling Framework that decomposes post-training performance into foundational SFT achievements and subsequent RL plasticity.
- Benchmarking reveals that a sequential SFT-then-RL pipeline outperforms pure RL and synchronous methods in stability and final performance.
- The study finds optimal transition points during stable overfitting phases, emphasizing high data scale to maximize LLM reasoning capabilities.
Summary of "Rethinking Expert Trajectory Utilization in LLM Post-training"
This paper explores the optimal mechanisms for utilizing expert trajectory data during the post-training phase of LLMs, involving both Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). The authors introduce the Plasticity-Ceiling Framework to decompose post-training performance into foundational SFT achievements and the subsequent RL plasticity.
Key Contributions and Findings
Plasticity-Ceiling Framework
The framework allows for theoretical grounding of expert trajectory utilization strategies by splitting the post-training performance ceiling into measurable components: the SFT performance and RL plasticity. This decomposition provides actionable insights, particularly emphasizing the sequential application of SFT followed by RL as a superior pipeline that surpasses synchronized approaches in terms of stability and performance.
Benchmarking and Sequential Paradigm Dominance
Through extensive benchmarking across different paradigms, the study establishes that the Sequential SFT-then-RL pipeline significantly outperforms pure RL approaches and synchronized SFT-RL methods regarding the stability and overall final performance ceiling. Early RL-like runs converge quickly but often show instability, whereas early SFT phases exhibit mild disruptions due to policy shifts.
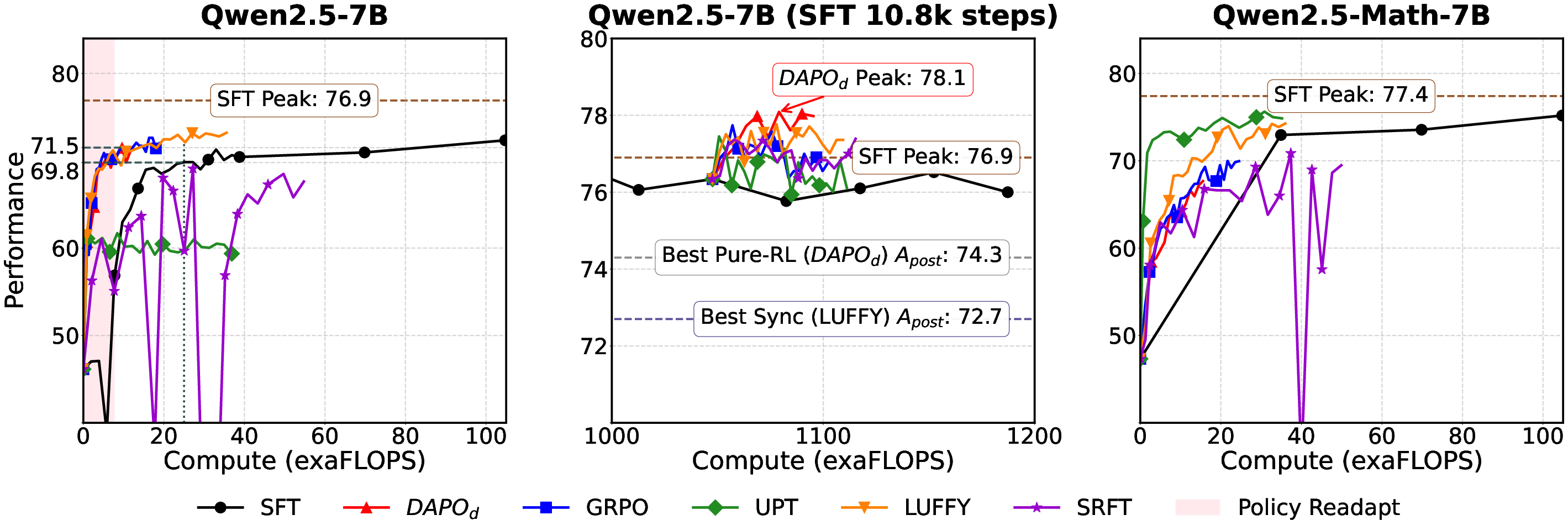
Figure 1: Computeâperformance scaling of post-training paradigms under different initialization conditions.
Optimal SFT-to-RL Transition and Scaling Factors
The paper identifies the conditions under which the transition from SFT to RL should occur. Transitioning during the Stable or Mild Overfitting Sub-phase maximizes the final performance ceiling by securing foundational SFT performance without compromising RL plasticity. The results refute the "Less is More" hypothesis, establishing that large data scale is necessary for state-of-the-art performance, while trajectory difficulty acts as a performance multiplier.
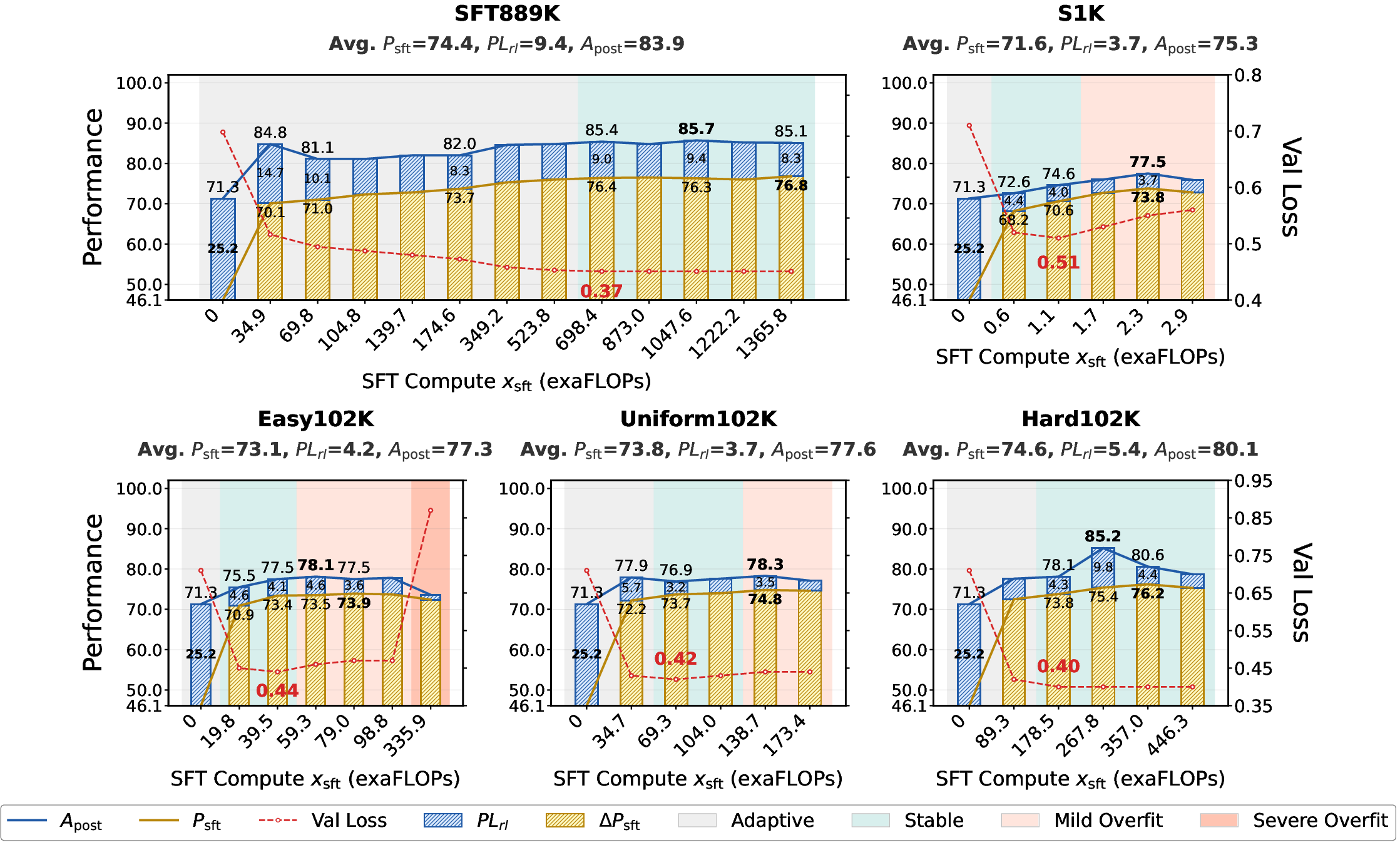
Figure 2: SFT Compute Scaling Dynamics of the SFT-then-RL Pipeline across Diverse Data Properties.
Theoretical and Practical Implications
The framework and findings imply that practitioners should prioritize extensive and high-quality expert trajectories in SFT to solidify foundational performance, which subsequently enhances RL plasticity and overall model performance. Systematic benchmarks support these guidelines, offering predictable development paths for reasoning models.
Impact on Future LLM Post-training Strategies
The insights from this study provide a systematic framework for optimizing expert trajectory utilization in LLM post-training. By emphasizing the sequential SFT-then-RL pipeline, focusing on data scale and trajectory difficulty, and timing transitions based on validation loss indicators, the research sets a rigorous standard for maximizing model reasoning capabilities.
This foundational work advances the understanding of post-training dynamics and establishes a roadmap for efficiently leveraging expert trajectories, impacting future AI developments and strategies for deploying LLMs in complex reasoning tasks.
Conclusion
In summary, this paper provides a comprehensive framework for expert trajectory utilization that combines theoretical insights with practical guidelines. This can effectively guide the next generation of LLMs towards enhanced reasoning capabilities, grounded in systematic post-training practices.

