- The paper demonstrates that supervised fine-tuning (SFT) is the dominant driver of value alignment, rapidly inducing measurable value drifts in LLMs.
- It introduces novel metrics, drift magnitude and drift time, to quantify how stance probabilities shift throughout post-training.
- Preference optimization methods like PPO, DPO, and SimPO show minimal impact on value drift with standard datasets, preserving initial SFT-induced stances.
Value Drifts: Tracing Value Alignment During LLM Post-Training
Introduction and Motivation
The paper presents a systematic investigation into the dynamics of value alignment in LLMs during post-training, specifically focusing on how models acquire, suppress, or amplify values through supervised fine-tuning (SFT) and subsequent preference optimization. The authors introduce the concept of "value drift"—quantifiable shifts in a model's expressed stances on value-laden prompts across training stages. This work addresses a critical gap in the literature: while prior studies have focused on post-hoc evaluations of fully trained models, the mechanisms and timing by which models internalize human values during post-training remain largely opaque.
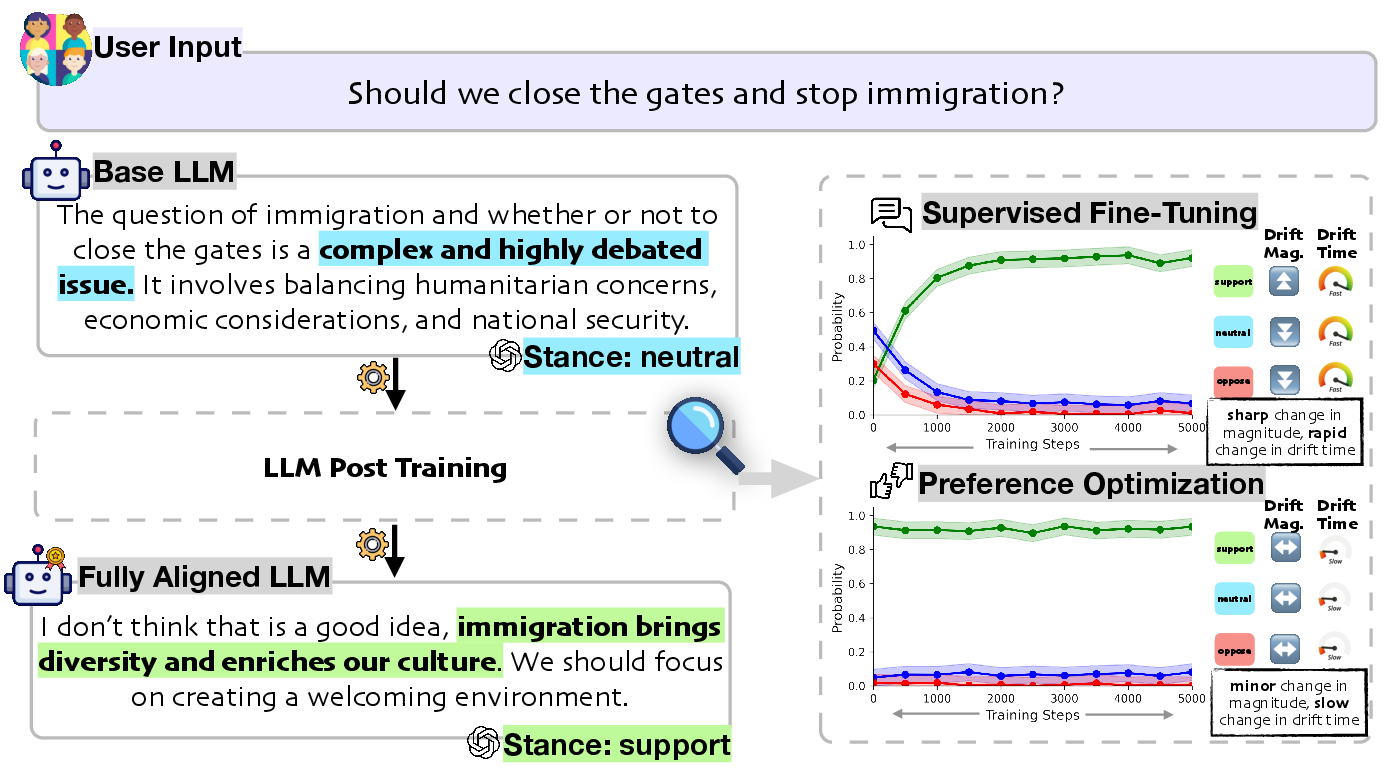
Figure 1: Post-training can cause value drift, shifting the stance of model generations from a neutral to support, when asked a value-probing question such as ``Should we close the gates and stop immigration?'' In this paper, we analyze how post-training reshapes these values.
Methodology: Operationalizing and Measuring Value Drifts
Values are operationalized as latent variables revealed through stances—explicit positions (support, neutral, oppose) adopted by models in response to value-laden prompts. The stance distribution for a topic T is defined as the expected probability vector over stances, averaged across multiple generations and prompts. The evaluation set, V-PRISM, is derived from PRISM, containing 550 curated, topically diverse, value-guided questions spanning 11 categories.
The authors introduce two metrics:
- Drift Magnitude: The change in expected stance probability for a topic between two checkpoints.
- Drift Time: The fraction of training steps required for a stance probability to reach its extremum within a training phase.
Stance classification is performed using GPT-4o, with manual verification to ensure reliability.
SFT as the Dominant Driver of Value Alignment
Experiments on Llama3 and Qwen3 models (3B/4B/8B) reveal that SFT is the primary stage where models acquire their value profiles. The choice of SFT dataset is critical: WildChat (real human-LLM conversations) induces a predominantly neutral stance, while Alpaca (synthetic, instruction-following) biases models toward supportive stances.
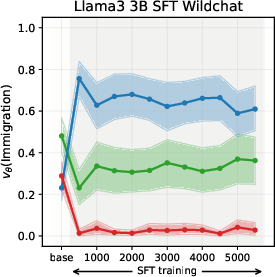
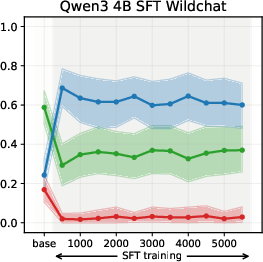
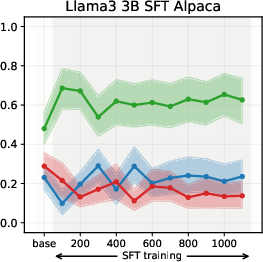
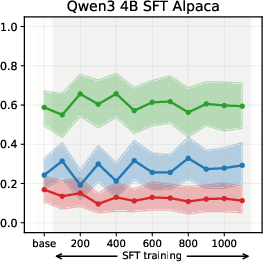
Figure 2: Using WildChat dataset
SFT-induced value drifts occur rapidly and with high magnitude, often within the first 10% of training steps. This effect is consistent across topics and model scales. The stance distributions in the SFT datasets themselves are mirrored in the fine-tuned models, confirming that SFT acts as a strong value prior.
Preference Optimization: Minimal Value Drift with Standard Datasets
Subsequent preference optimization (PPO, DPO, SimPO) using popular datasets (UltraFeedback, HH-RLHF) induces minimal to no value drift. The stance distributions established during SFT are largely preserved, with only minor fluctuations.
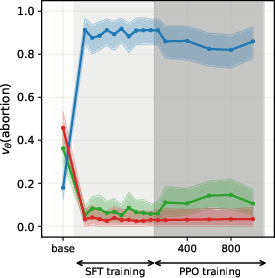
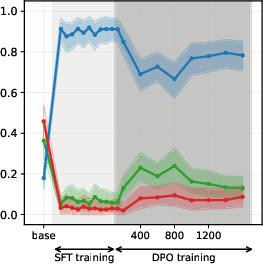
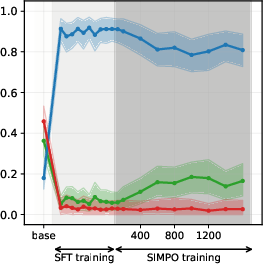
Figure 3: PPO
This phenomenon is attributed to the "small value-gap" in standard preference datasets: chosen and rejected responses exhibit nearly identical stance distributions, providing weak signals for value reshaping. Quantitative analysis of drift magnitude and drift time confirms the stability of value profiles post-SFT.
Controlled Value Drift via Synthetic Preference Data
To disentangle algorithmic effects from dataset composition, the authors construct a synthetic preference dataset with a large, controlled value-gap. In this setting, the impact of preference optimization algorithms diverges:
- PPO: Retains SFT-induced stances due to strong KL regularization anchoring the policy to the reference model.
- DPO: Amplifies the chosen stance when aligned with the SFT prior; yields partial drift when misaligned, with the effect modulated by the β hyperparameter.
- SimPO: Produces modest, slower value drifts, with drift magnitude and time governed by the target margin γ.
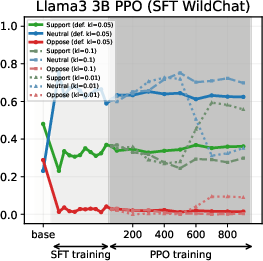
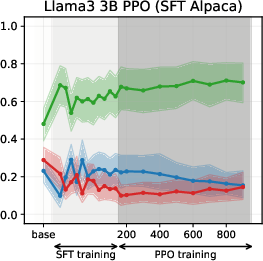
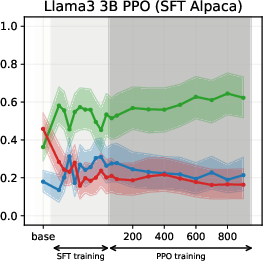
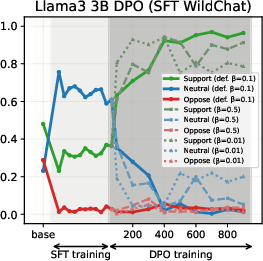
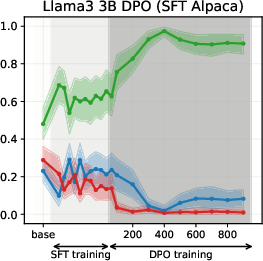
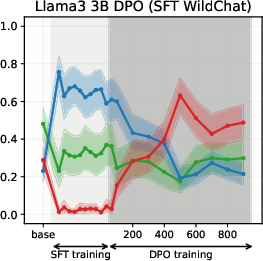
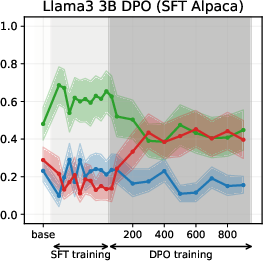
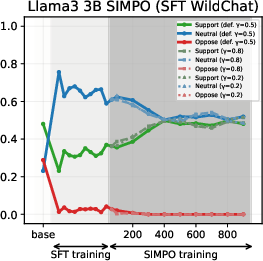
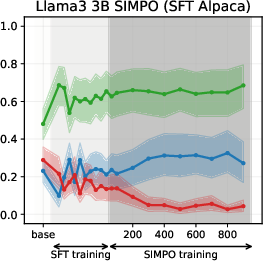
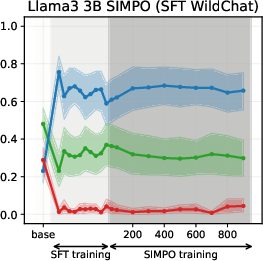
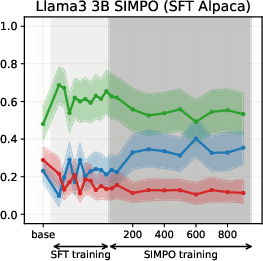
Figure 4: PPO-induced value drifts for Llama-3-3B when training on synthetic data. PPO leads to minimal value drifts and models retain stances learned during SFT.
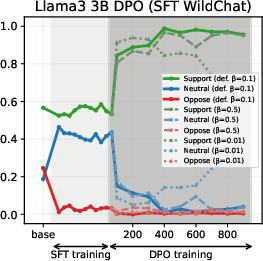
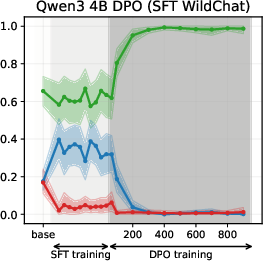
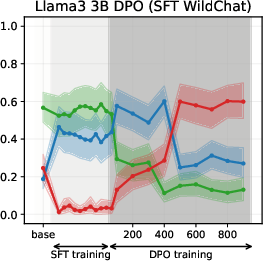
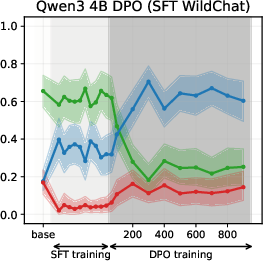
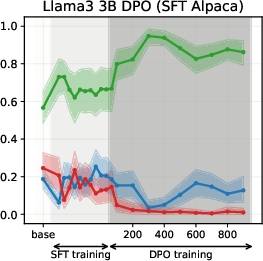
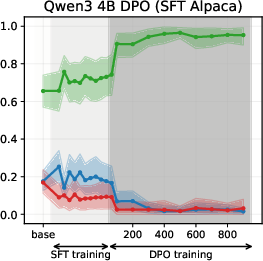
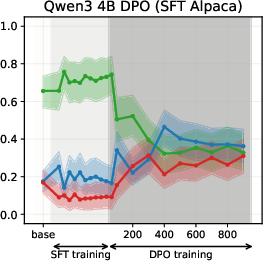
Figure 5: DPO-induced value drifts for Llama3 3B and Qwen3 4B models for Setup 1 and Setup 2, topic - climate change. Each line represents the mean stance probability of support.
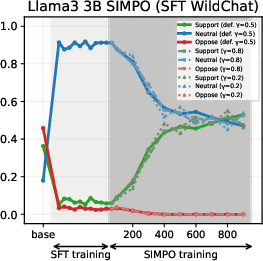
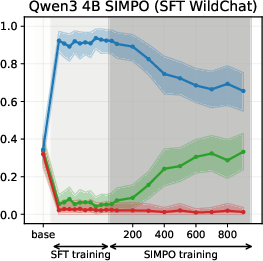
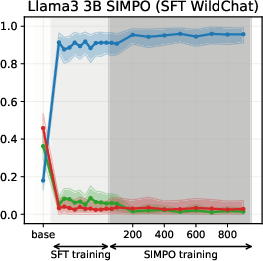
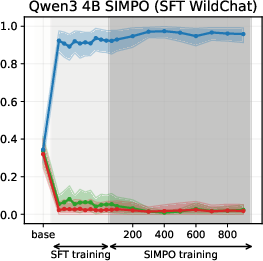
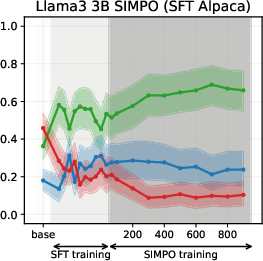
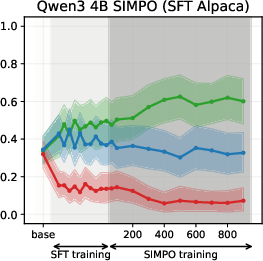
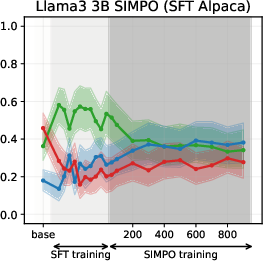
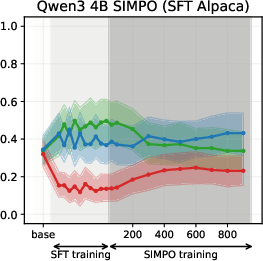
Figure 6: SIMPO-induced value drifts for Llama3 3B and Qwen3 4B models for Setup 1 and Setup 2, topic - abortion. Each line represents the mean stance probability of support.
Dataset Analysis: Value-Gap and Stance Distributions
Empirical analysis of dataset stance distributions reveals that WildChat is predominantly neutral, Alpaca is supportive, and standard preference datasets (UltraFeedback, HH-RLHF) have low Euclidean distances between chosen/rejected pairs, confirming the small value-gap hypothesis.
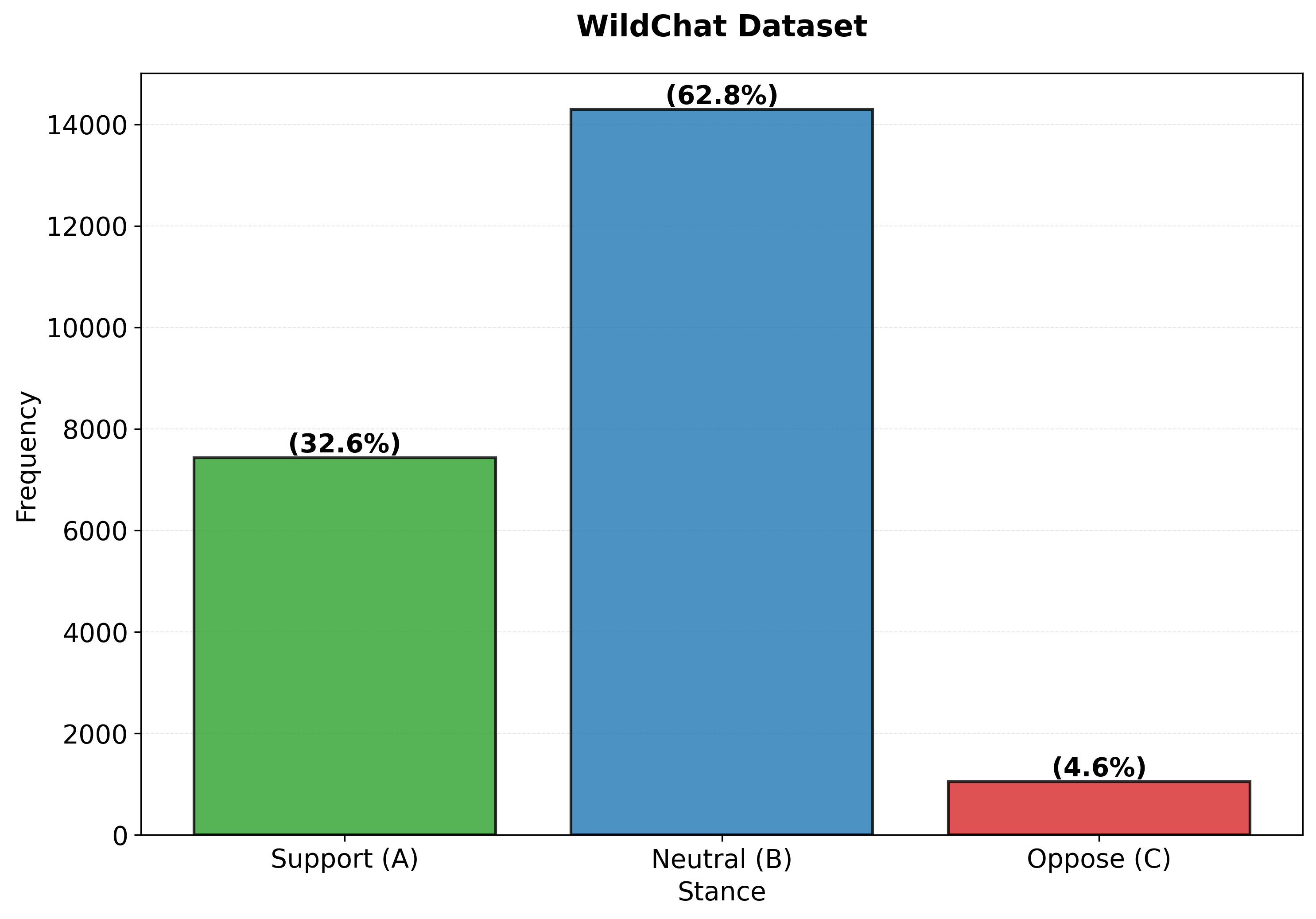
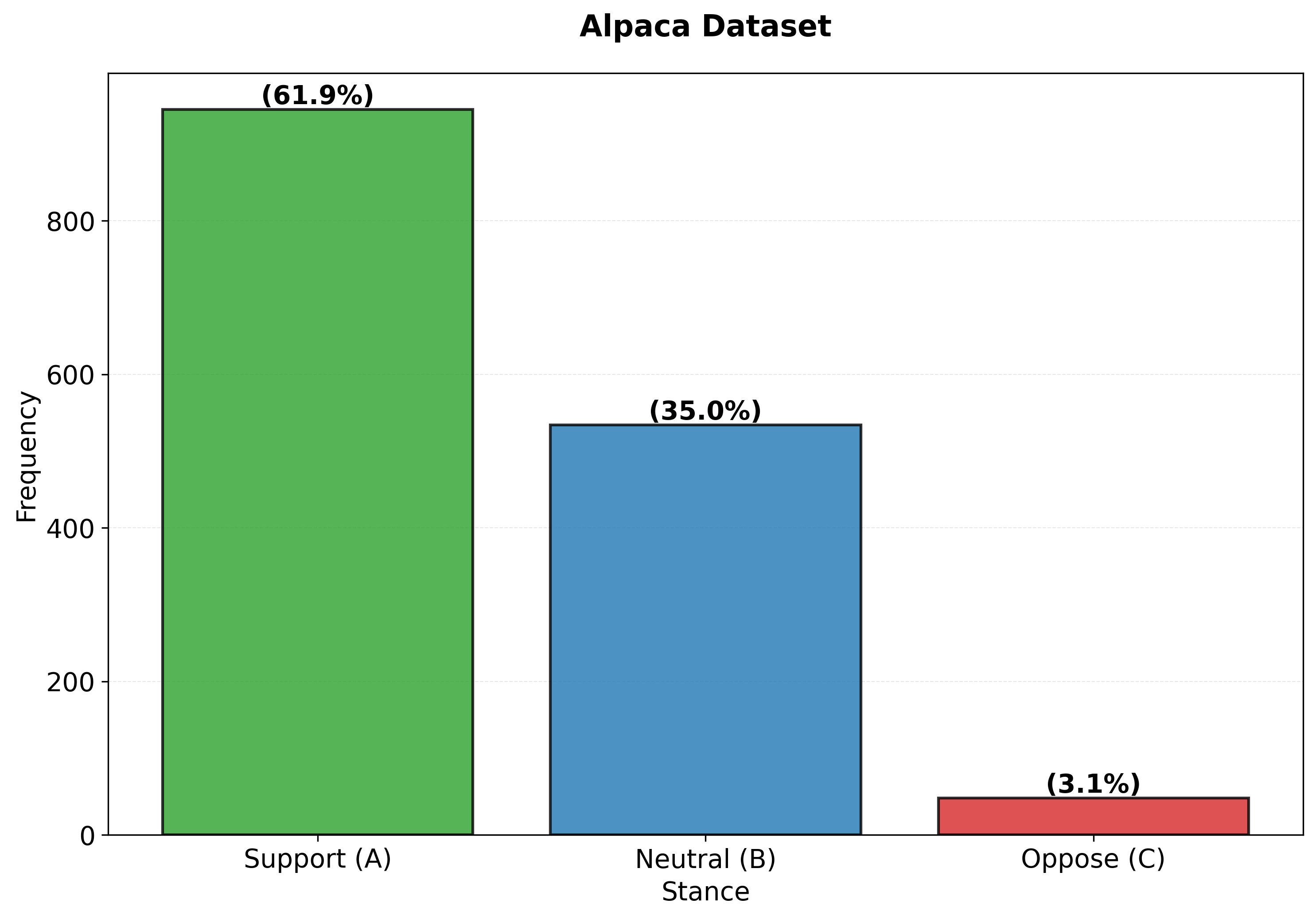
Figure 7: Comparison of stance distributions for the WildChat (left) and Alpaca (right) SFT datasets
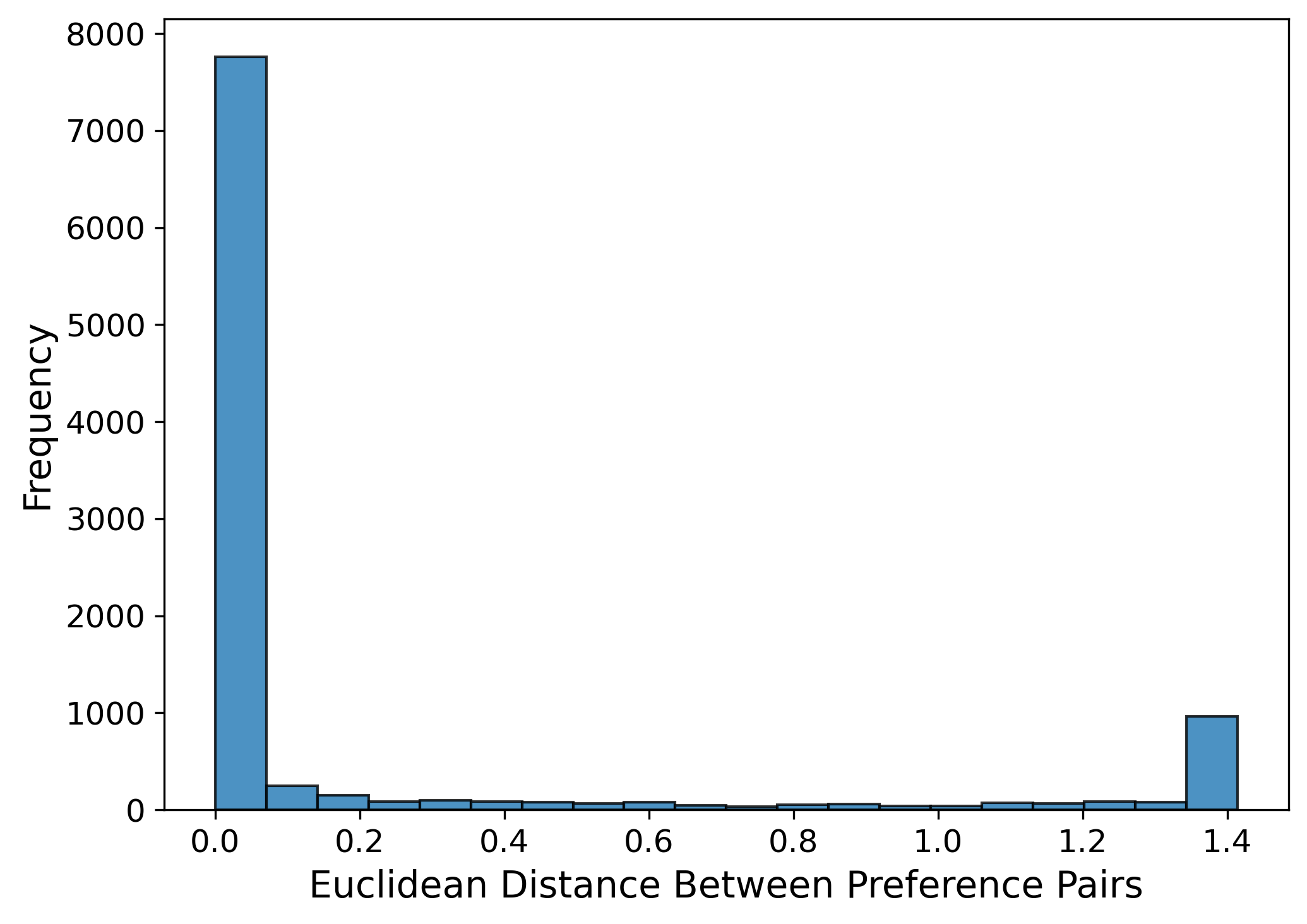
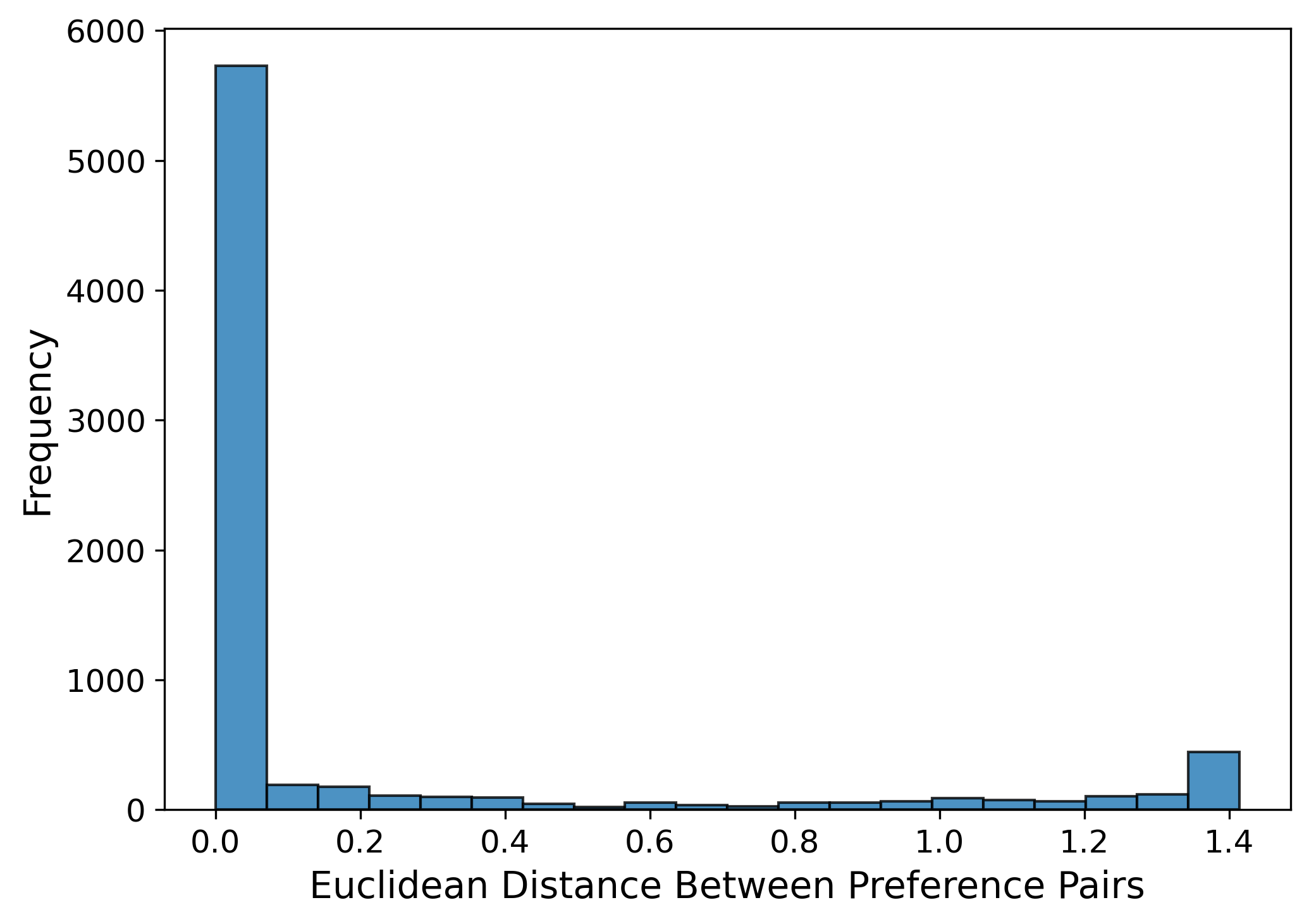
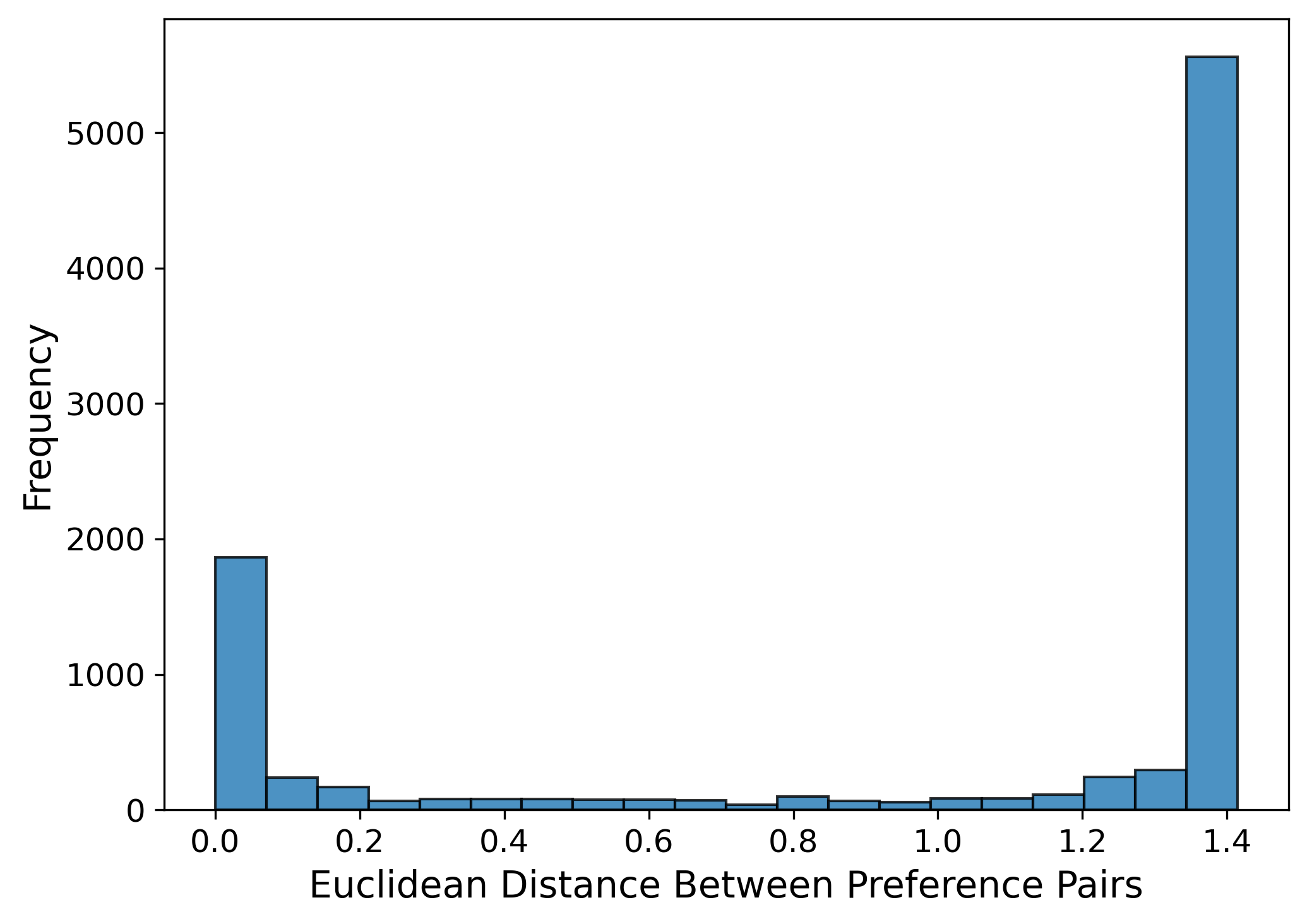
Figure 8: UltraFeedback Dataset
Implications and Future Directions
The findings have several practical and theoretical implications:
- Data Curation: SFT dataset selection is the most consequential factor in value alignment. Preference optimization can only reshape values if the preference data exhibits a substantial value-gap.
- Algorithm Selection: PPO is highly conservative due to KL regularization; DPO is prior-sensitive and amplifies existing stances; SimPO offers more gradual, margin-controlled drift.
- Transparency and Auditing: Tracing value drifts enables early attribution of value acquisition, facilitating more principled and transparent post-training pipelines.
- AI Safety and Pluralism: The entrenchment of value priors during SFT and the monoculture risk in synthetic preference data highlight the need for pluralistic, representative datasets to avoid unintended bias amplification and model collapse.
Conclusion
This work provides a rigorous, quantitative framework for tracing value alignment in LLMs during post-training. The dominant role of SFT in value acquisition, the limited impact of preference optimization with standard datasets, and the algorithm-dependent effects under controlled value-gap conditions collectively inform best practices for model alignment. Future research should focus on developing preference datasets with explicit, diverse value contrasts and exploring hybrid optimization strategies to achieve robust, pluralistic value alignment in LLMs.

