- The paper establishes a rigorous decomposition of return error by attributing policy suboptimality to errors in learned dynamics and reward models via Lipschitz constants.
- It demonstrates that reducing Lipschitz constants through techniques like spectral normalization tightens error bounds, enhancing long-horizon policy performance.
- It provides an optimal sample allocation formula under power-law error scaling, balancing reward fidelity and rollout quantity to mitigate noise and bias.
Training in Imagination: Error Attribution, Sample Allocation, and Reward Fidelity in Model-Based RL
Introduction
The paradigm of "training in imagination," wherein agent policies are optimized exclusively on trajectories simulated by learned dynamics and reward models, has gained increasing prominence in model-based RL. Prominent recent systems such as Dreamer3 and Dreamer4 instantiate this approach, leveraging learned world models to facilitate efficient and scalable control with minimal environment interaction. Despite clear empirical progress, theoretical understanding of the interplay between dynamics and reward model errors—and their implications for sample complexity, policy performance, and annotation budget allocation—has lagged. This work provides a rigorous quantitative analysis of error propagation and sample allocation in model-based RL with learned reward models, delivering formal decompositions, sample complexity results, and guidelines for budget allocation under realistic power-law error scaling and reward noise.
Decomposition of Return Error and Attribution
The central technical contribution is an extension of Lipschitz-based simulation-lemma-style bounds to settings where both the dynamics (f^) and the reward model (r^) are learned. The derived error decomposition establishes a bound on the policy return gap between the imagined and true environments that separates contributions from dynamics and reward model errors, each modulated by explicit, independently-controlled coefficients parameterized by their respective Lipschitz constants. Formally, under contraction conditions (γLf(1+Lπ)<1), the following bound for a fixed Lipschitz policy π is established:
∣J(π,M)−J(π,M^)∣≤1−γ1εr+(1−γ)(1−γLf(1+Lπ))γLr(1+Lπ)εf
where εf and εr are the worst-case ℓ2 dynamics and reward model errors, and Lf,Lr,Lπ are the Lipschitz constants of the learned dynamics, reward, and policy, respectively.
This explicitly attributes the return suboptimality to the respective error sources and provides a framework for independent control and mitigation.
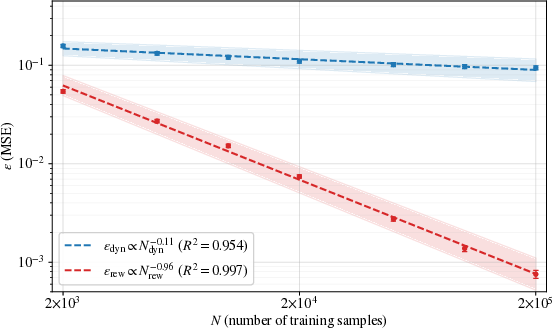
Figure 1: Dynamics and reward errors exhibit distinct power-law scaling with dataset size; reward model error typically decays ≈9× faster with increasing data—crucial for sample allocation.
Representation Desiderata: Tightening the Error Bound
The bound demonstrates that the impact of dynamics errors compounds along the rollout trajectory with a coefficient that is monotone in r^0, r^1, and r^2. Consequently, learned latent representations that reduce these Lipschitz constants directly tighten the value gap bound, motivating regularization schemes such as spectral normalization and objectives like temporal straightening in latent space.
The link between smooth, contractive latent dynamics and tighter error bounds is explicit: lower Lipschitz constants attenuate the exponential accumulation of compounding model errors, particularly in long-horizon tasks. The temporal straightening objective, enforcing parallelism in consecutive latent velocities, is shown to upper-bound incremental rollout curvature by a function of the latent velocity map's Lipschitz constant. Minimizing this regularity yields better long-horizon accuracy in imagination.
Sample Budget Allocation under Power-Law Error Scaling
A key practical question is how to divide a finite annotation and interaction budget between dynamics and reward data, given that reward annotations (e.g., human preferences) are often more expensive and may scale differently with sample size. Empirical analyses confirm that, for standard neural architectures, reward model error decays with training data at rates nearly an order of magnitude faster than dynamics error (see Figure 1). Theoretically, if the error curves scale as r^3 and r^4 for r^5 samples, the optimal allocation ratio is
r^6
where r^7 and r^8 are per-sample costs. This formula quantifies how the power-law exponents, cost ratios, and error coefficients jointly determine optimal budget distribution; for instance, favorable reward error exponents and lower annotation cost shift the optimal mix toward reward samples.
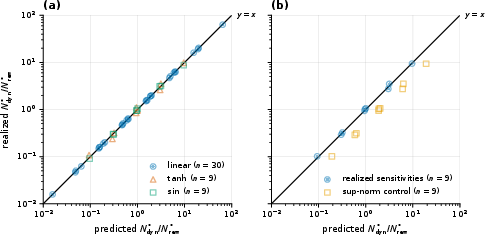
Figure 2: Agreement between predicted and realized sample allocation ratios when leveraging value-function sensitivities, demonstrating practical accuracy of the optimal sample split formula.
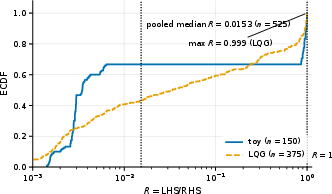
Figure 3: The derived decomposed return error bound holds empirically, but with notable looseness when instantiating global Lipschitz constants.
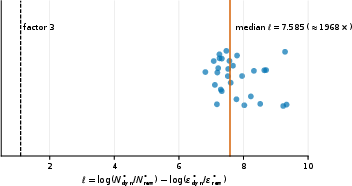
Figure 4: The multiplier in the optimal sample ratio formula, when computed with practical Lipschitz constants, can overshoot realized ratios by orders of magnitude; local value-function sensitivities are recommended for more accurate allocation.
Empirically, the proportionality relationship between realized allocation and error ratios holds strongly when value-function sensitivities are used, but the bound is loose—by up to three orders of magnitude—when only global Lipschitz constants are available.
Analysis of Policy Gradient Variance: Reward Noise and Fidelity
In model-based RL with imitation or preference data, reward signals are often subject to stochastic noise or systematic bias. The analysis considers the consequences of noisy reward observations for policy gradient estimation. When noise is zero-mean, the expected gradient is unbiased, but the variance is inflated by an explicit term proportional to per-step noise variance and inversely with the number of rollouts. This gives rise to a fidelity–quantity tradeoff: for a fixed annotation budget, should one prioritize fewer high-fidelity (low-noise) samples, or increase rollout count at the expense of higher per-step noise?
The optimal fidelity resolves as a one-dimensional minimization over the product r^9, where γLf(1+Lπ)<10 is noise variance as a decreasing function of per-rollout annotation cost γLf(1+Lπ)<11. Analytical cases show that when γLf(1+Lπ)<12 drops sufficiently fast with γLf(1+Lπ)<13, it is optimal to buy higher-fidelity data; otherwise, maximizing rollout quantity is preferable. Crucially, if reward noise has an irreducible floor, the optimal strategy is to maximize rollout number regardless of fidelity cost. In contrast, systematic reward biases introduce persistent, nonvanishing gradient bias that trajectory averaging cannot remedy.
Empirical Calibration and Numerical Evaluations
Extensive empirical studies on synthetic dynamics/reward environments and LQG control tasks illustrate several crucial findings:
- The decomposed return error bound is always satisfied but is typically conservative by at least an order of magnitude.
- Power-law scaling exponents extracted from actual model learning trajectories confirm the marked gap between reward and dynamics learning rates.
- Optimal sample ratios derived from the theoretical framework align with observed minimal return error allocations when realized value-function sensitivities are substituted for worst-case Lipschitz constants.
This underscores that practical systems should avoid the use of global Lipschitz overestimates when tuning data acquisition pipelines for model-based RL.
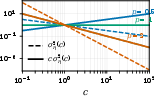
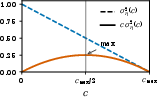
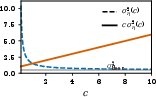
Figure 5: Empirical reward and dynamics model errors versus dataset size, confirming distinct power-law regimes; reward error decays nearly an order of magnitude faster per decade.
Implications and Future Directions
The analysis provides explicit, actionable guidelines for model-based RL practitioners building learning systems around imagined rollouts:
- Prioritize model architectures and regularization choices that directly minimize the Lipschitz constants of learned system components to limit long-horizon compounding of errors.
- Use empirical power-law scaling exponents to inform data acquisition decisions; reward annotations can often be successful with much less data than dynamics transitions.
- Where possible, use realized local value-function sensitivities—not global model Lipschitz constants—to calibrate sample allocations, as the latter grossly overestimate required data.
- For reward annotation, adopt fidelity regimes guided by the empirical behavior of annotation noise as a function of cost, maximizing rollout quantity unless high-fidelity yields a superlinear improvement in variance reduction.
- Detect and mitigate systematic reward bias early; averaging cannot remove bias-induced gradient drift.
The theoretical machinery presented here forms a foundation for future study of sample-efficient RL under imperfect generative models, especially in offline and human-in-the-loop scenarios. Of particular interest are extensions to stochastic dynamics, unbounded operating regimes, and dynamic weighting of annotation fidelity in nonstationary environments.
Conclusion
This work delivers a comprehensive and rigorous quantitative analysis of policy error decomposition, representation regularity, sample allocation, and fidelity-variance tradeoffs in model-based RL with learned dynamics and reward functions. The derived bounds, optimality results, and empirical findings guide both theoretical understanding and practical implementation. The connection between tight Lipschitz-induced bounds and representation learning objectives (e.g., temporal straightening) establishes a critical link between architectural choices and downstream policy performance. These results provide a toolkit for principled, cost-aware training of high-performing RL agents in imagination, contributing formally to the methodology underpinning efficient RL from limited and noisy data (2605.06732).

