- The paper proposes a fractional-step distillation framework (1.x-Distill) that breaks traditional integer-step constraints for efficient text-to-image synthesis.
- It introduces a timestep-aware guidance control to mitigate early mode collapse, preserving structural diversity and ensuring high fidelity.
- Experimental results on SD3-Medium and SD3.5-Large show up to a 33× inference speedup with state-of-the-art performance in both image quality and diversity.
1.x-Distill: Advancements in Distribution Matching Distillation for Efficient Diffusion-based Text-to-Image Generation
Introduction
Diffusion models have set the standard for high-fidelity image synthesis in the text-to-image domain, but their formidable computation costs—driven by inherently iterative denoising—pose significant obstacles for high-throughput applications. While Distribution Matching Distillation (DMD) and related few-step distillation methodologies enable reduced inference costs, prior approaches exhibit critical limitations under aggressive step reduction, such as severe sample diversity collapse and pronounced quality degradation. The proposed 1.x-Distill framework introduces a principled fractional-step distillation pipeline that decisively breaks the integer-step constraint, establishing a new practical regime for "1.x-step" text-to-image generation.
Diagnosing and Mitigating Diversity Collapse in DMD
DMD and its derivatives typically employ a reverse KL-divergence objective to match the student’s generative distribution to a pre-trained teacher model, often incorporating Classifier-Free Guidance (CFG) to enhance prompt adherence and output fidelity. The study presents a detailed analysis revealing that strong CFG applied at high-noise timesteps imposes premature bias toward dominant sample modes, exacerbating early mode collapse and thus undermining generative diversity.
The proposed remedy is a timestep-aware guidance control, selectively disabling teacher CFG at early denoising iterations and only re-enabling strong guidance at mid-to-low noise timesteps. This intervention empirically preserves coarse structure diversity without sacrificing downstream prompt alignment or visual quality.
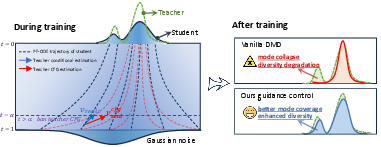
Figure 1: Teacher CFG at high noise forces mode collapse; disabling CFG in the initial denoising propagates richer structural uncertainty.
Stagewise Focused Distillation: Aligned Objectives for Extreme Few-Step Regimes
To address the learning dynamics mismatch when compressing generation to extreme few-step regimes, 1.x-Distill introduces Stagewise Focused Distillation (SFD). The process is decomposed into two specialized stages:
- Stage I (Structure-focused Distribution Matching): Employs non-uniform importance sampling to downweight low-noise (texture-centric) timesteps, focusing optimization on windows offering greater structural signal. The guidance control mechanism is applied per-timestep, as detailed above.
- Stage II (Detail-focused Adversarial Refinement): Incorporates a pixel-space adversarial objective, where the generator and a lightweight MLP parameterize the denoising cascade along the teacher’s inference path. This stage exclusively refines fine-grained visual details, maintaining full structural consistency.
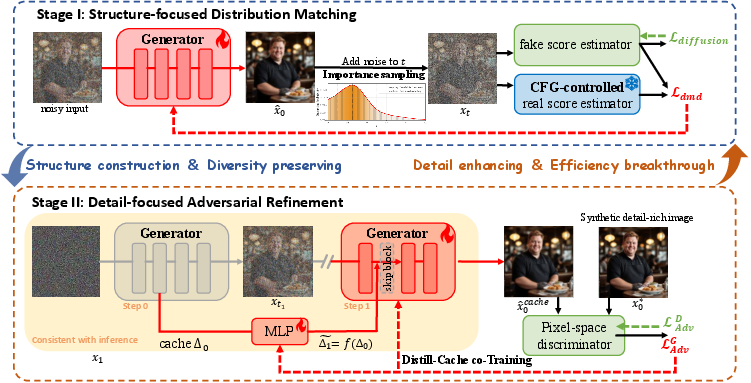
Figure 2: Schematic of 1.x-Distill, integrating guidance control and caching within a two-stage training pipeline.
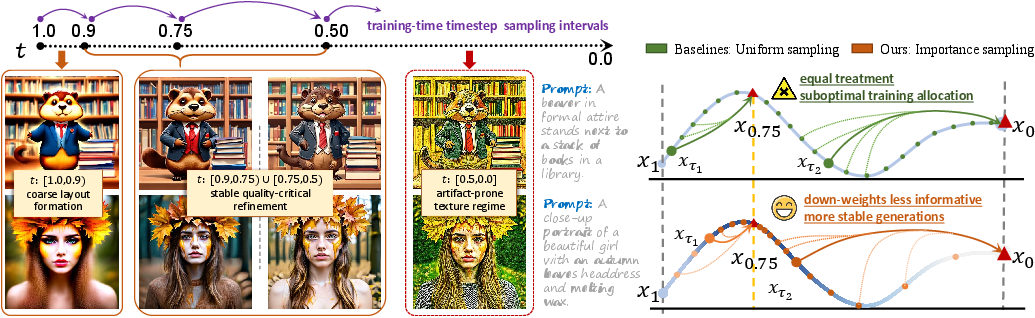
Figure 3: Importance sampling concentrates training on structurally informative timesteps, unlike uniform assignment.
Distill--Cache Co-Training: Effective Block-Level Caching for Fractional-Step Inference
A compelling innovation is the integration of block-level feature caching into the distilled model via joint Distill--Cache co-Training (DCT). Unlike prior cache-based methods tailored exclusively for multi-step diffusion, 1.x-Distill’s DCT explicitly introduces a lightweight error compensation module co-trained with the main student. The forwardpass reuses cached contributions from early blocks, and adversarial losses in Stage II provide a direct recovery signal that compensates for reuse errors at inference.
This approach enables efficient fractional-step sampling (e.g., 1.67 or 1.74 effective NFEs) while substantially mitigating visual artifacts that previously plagued plug-and-play cache application in distilled two-step regimes.
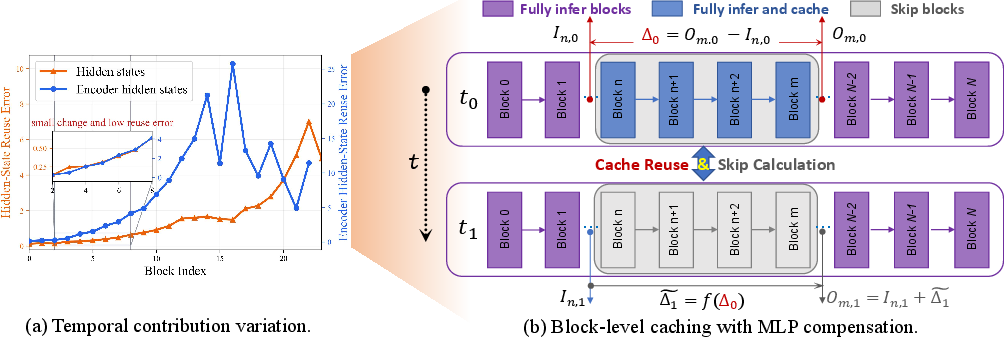
Figure 4: Block-level caching reuses intermediate feature contributions for additional timesteps, facilitating computation skip and error correction.
Experimental Results
Comprehensive benchmarking on SD3-Medium and SD3.5-Large demonstrates that 1.x-Distill achieves new SOTA in few-step text-to-image synthesis, attaining 1.67 and 1.74 effective NFE regimes, respectively, and delivering up to a 33× inference speedup compared to the standard 28×2 NFE workflow. Notably, the method consistently outperforms prior DMD, trajectory, and hybrid distillation baselines in both fidelity and sample diversity, as validated by FID, CLIP Score, HPSv2, ImageReward, Aesthetic Score, and user study evaluations.

Figure 5: 1.x-Distill maintains both fidelity and diversity with minimal steps, surpassing prior DMD in the extreme few-step domain.

Figure 6: Results of a user study indicating clear subjective preference for 1.x-Distill over competing few-step models.
Preserved structural diversity is quantitatively supported by higher LPIPS scores versus baselines. On demanding datasets such as DPG-Bench, the distilled models not only match but exceed the teacher’s performance in aggregate semantic understanding and entity binding under aggressive step compression.
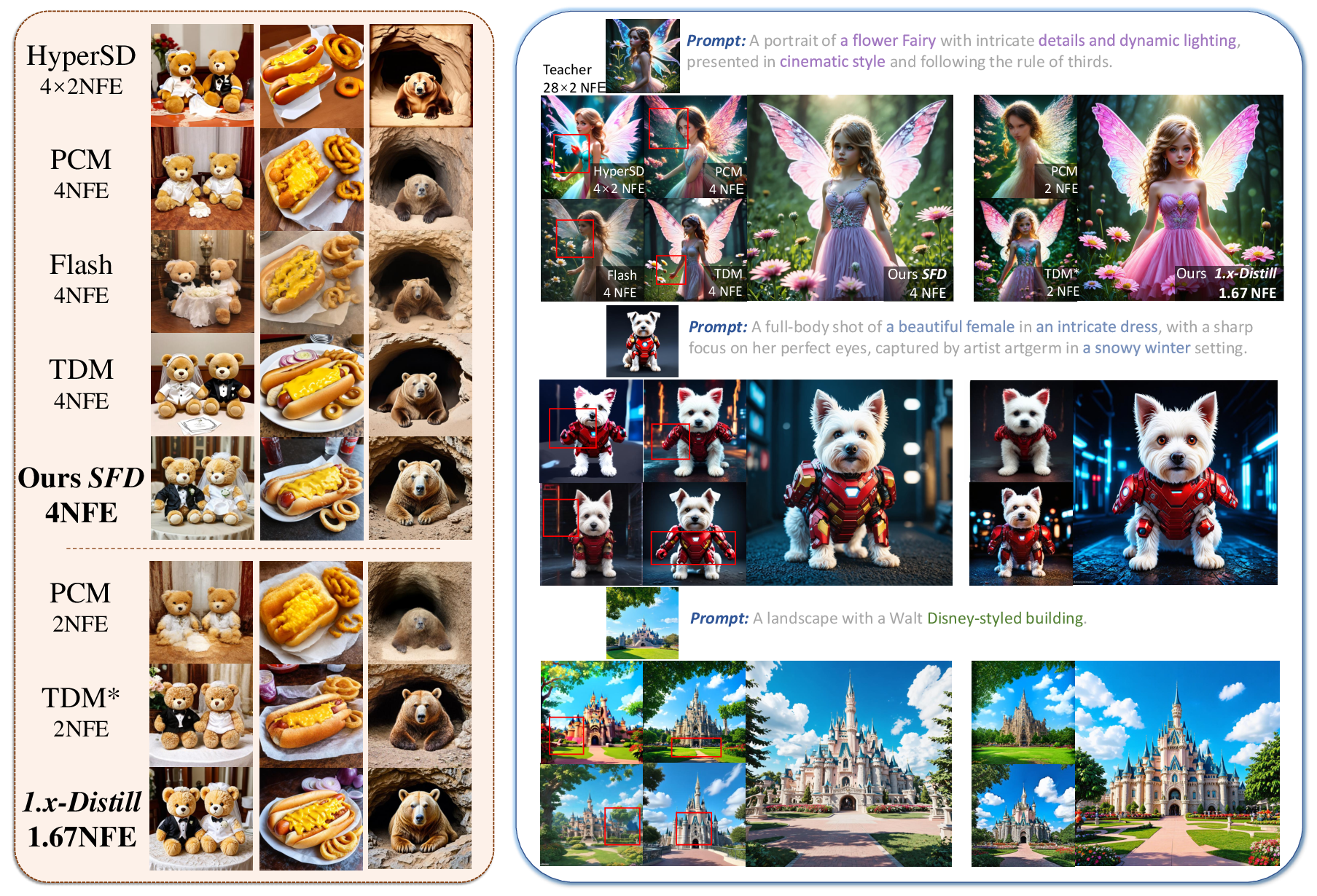
Figure 7: Qualitative comparison on SD3-Medium; 4-step and 2-step generations from SFD surpass competing methods in clarity and prompt relevance.

Figure 8: 1.x-Distill delivers greater sample diversity relative to previous distribution-matching distillation methods.
Ablation Studies and Design Analysis
Detailed ablation confirms that guidance control is essential for preserving diversity, with optimal control thresholds identified heuristically. Importance-sampling distributions that downweight low-noise timesteps consistently yield higher perceptual and preference scores. When comparing block-caching strategies, early-block caching (with residual MLP compensation) offers the best trade-off between quality retention and inference acceleration.

Figure 9: Caching early transformer blocks results in lower artifacts and better image quality compared to mid/late-block reuse.
Practical and Theoretical Implications
From a practical standpoint, 1.x-Distill demonstrates that highly compute-efficient, high-fidelity, and structurally diverse text-to-image generation can be achieved within a fractional-inference framework, fundamentally expanding the deployment space of large diffusion-based generators. Theoretically, the explicit disentanglement of stagewise learning and the characterization of guidance-induced mode collapse provide actionable insights for future distillation strategies.
By integrating block caching as a trainable, not inference-only, operation, the method bridges the previously disjoint steps of acceleration and distillation, suggesting broader applicability for efficient generative modeling beyond image synthesis—including video and multi-modal transformations.
Conclusion
1.x-Distill establishes a new paradigm for diffusion distillation, making practical and efficient few-step text-to-image generation feasible without compromising the core attributes of sample fidelity and diversity. Its innovations in guidance control, stagewise training, and cache-aware learning point toward a general recipe for further compression and acceleration of large generative models. Extensions to even larger-scale models and temporal domains (e.g., video) are anticipated future directions.

