- The paper identifies a persistent super-outlier channel in early DLM layers that triggers layer collapse and redundancy.
- It employs heavy-tailed spectral analysis to show that overtraining causes extreme collinearity in the early layers of diffusion models.
- The paper demonstrates that DLMs achieve superior compression robustness and reversed sparsity allocation compared to autoregressive models.
Layer Collapse Phenomena in Diffusion LLMs: Activation Dynamics, Redundancy, and Compression Implications
Diffusion vs. Autoregressive Models: Divergence in Layer Activation Structure
Diffusion LLMs (DLMs) have recently garnered attention as alternatives to autoregressive (AR) transformers, primarily through their ability to generate text via iterative denoising and parallel decoding. This paper conducts a rigorous empirical comparison between DLMs (specifically LLaDA-8B) and AR models of matched architecture (Llama-3.1-8B), uncovering a pronounced divergence in their layer activation dynamics and representational redundancy. Central to these findings is the identification of a persistent, layer-spanning super-outlier activation channel in LLaDA-8B, sharply contrasting with the activation profile seen in AR models.
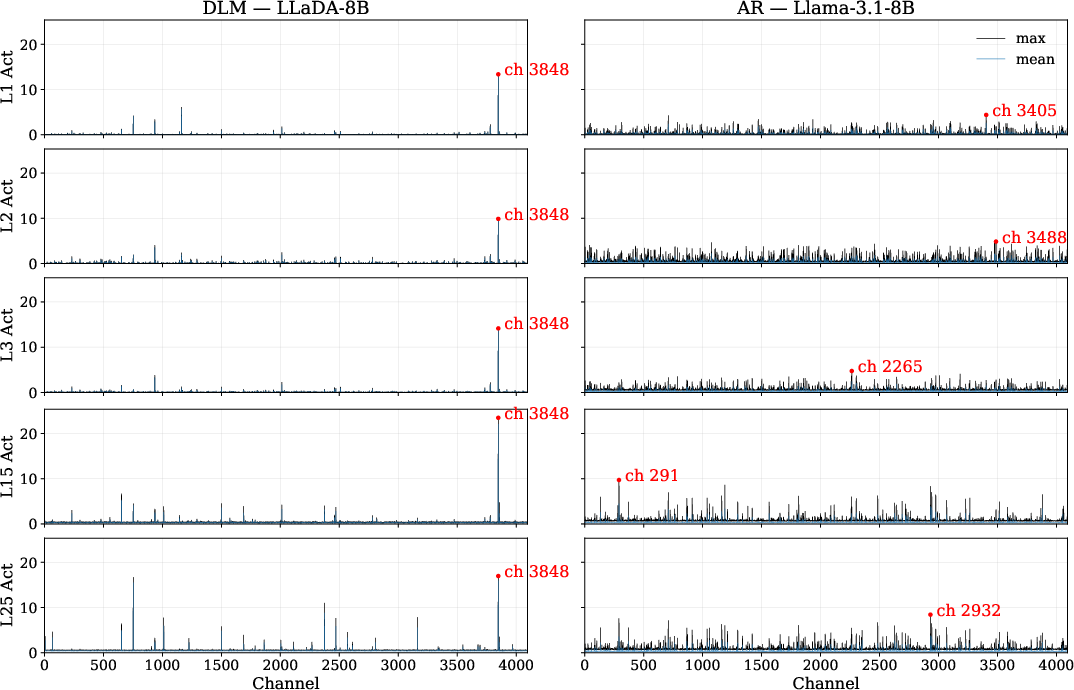
Figure 1: LLaDA activations contain a single consistent, very large super-outlier channel which persists well into the middle layers.
This super-outlier channel is not transient or token-specific, but dominates activations across early layers and for broad token ranges, driving a phenomenon the authors term "layer collapse." When this channel in LLaDA-8B is ablated, model output devolves into repetitive token loops—a catastrophic degradation unique to DLMs, as AR models exhibit only marginal accuracy drops under analogous single-channel pruning.
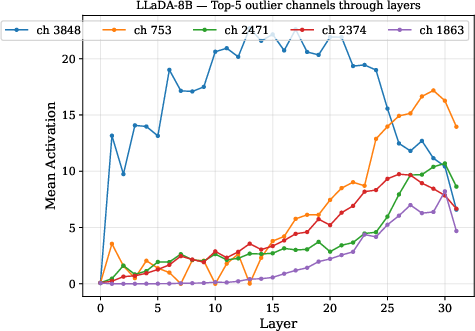
Figure 2: LLaDA-8B: the super-outlier channel dominates the top-5 magnitudes consistently across early-middle layers.
Redundancy and Similarity Patterns: Early-Layer Collapse in DLMs
Quantitative analysis of per-token cosine similarity between layer activations reveals that LLaDA-8B’s early layers are highly collinear, exhibiting extreme redundancy. Removing the super-outlier channel attenuates, but does not fully eliminate, this redundancy. In AR models, redundancy emerges predominantly in deep layers, consistent with the established "curse of depth"—undertraining in late layers resulting in near-identity transformations.
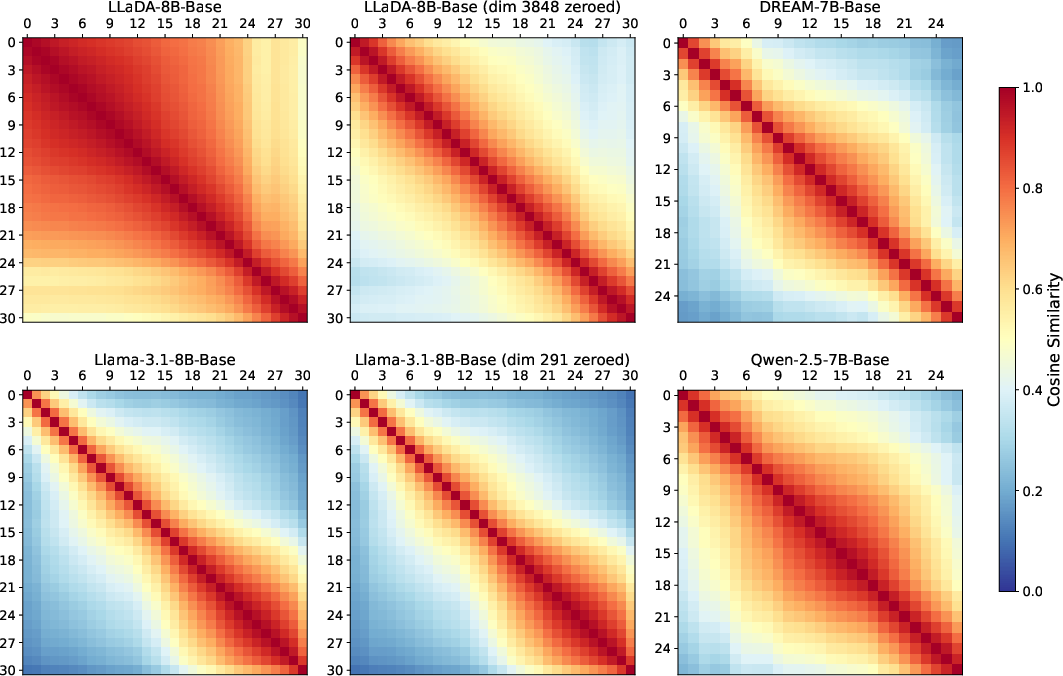
Figure 3: Per-token cosine similarity for different models. LLaDA-8B demonstrates collapsed layer similarities in early layers; AR models display distinct early layers and redundant deep layers.
The redundancy in LLaDA-8B is verified not to be an artifact of undertraining, but rather of "overtraining" of early layers. Using heavy-tailed spectral analysis (Hill estimator), early LLaDA-8B layers display significantly heavier tails and lower values of the tail exponent, indicating strong, low-dimensional feature learning and concentration of representation into a small subset of channels.
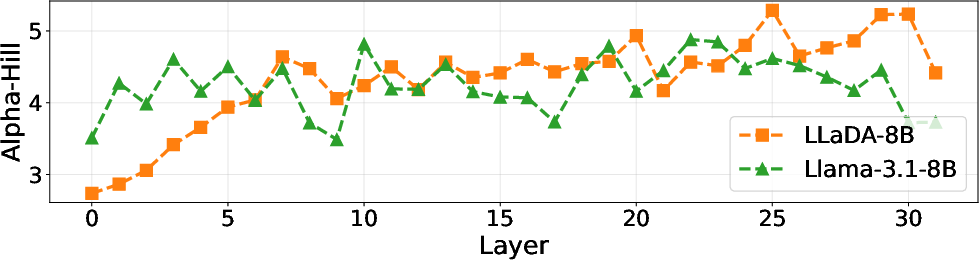
Figure 4: The Hill estimator value is very low in the early layers of LLaDA-8B, indicating overtraining and collapse into dominant directions.
Practical Consequences: Compression Robustness and Sparsity Allocation Flipped
One of the strongest numerical results in this work concerns the robustness of DLMs to compression. Despite the presence of an extremely sensitive super-outlier, LLaDA-8B is remarkably resilient to both pruning and quantization compared to AR models. For example, under 3-bit GPTQ quantization, LLaDA-8B’s GSM8K accuracy drops only 1.8%, while Llama-3.1-8B degrades by 64.7%. Furthermore, optimal sparsity allocation is reversed: allocating higher sparsity to early layers in LLaDA-8B yields a +8.4% accuracy improvement over allocating it to deep layers, while the same strategy is highly detrimental (-8.4%) in AR models.
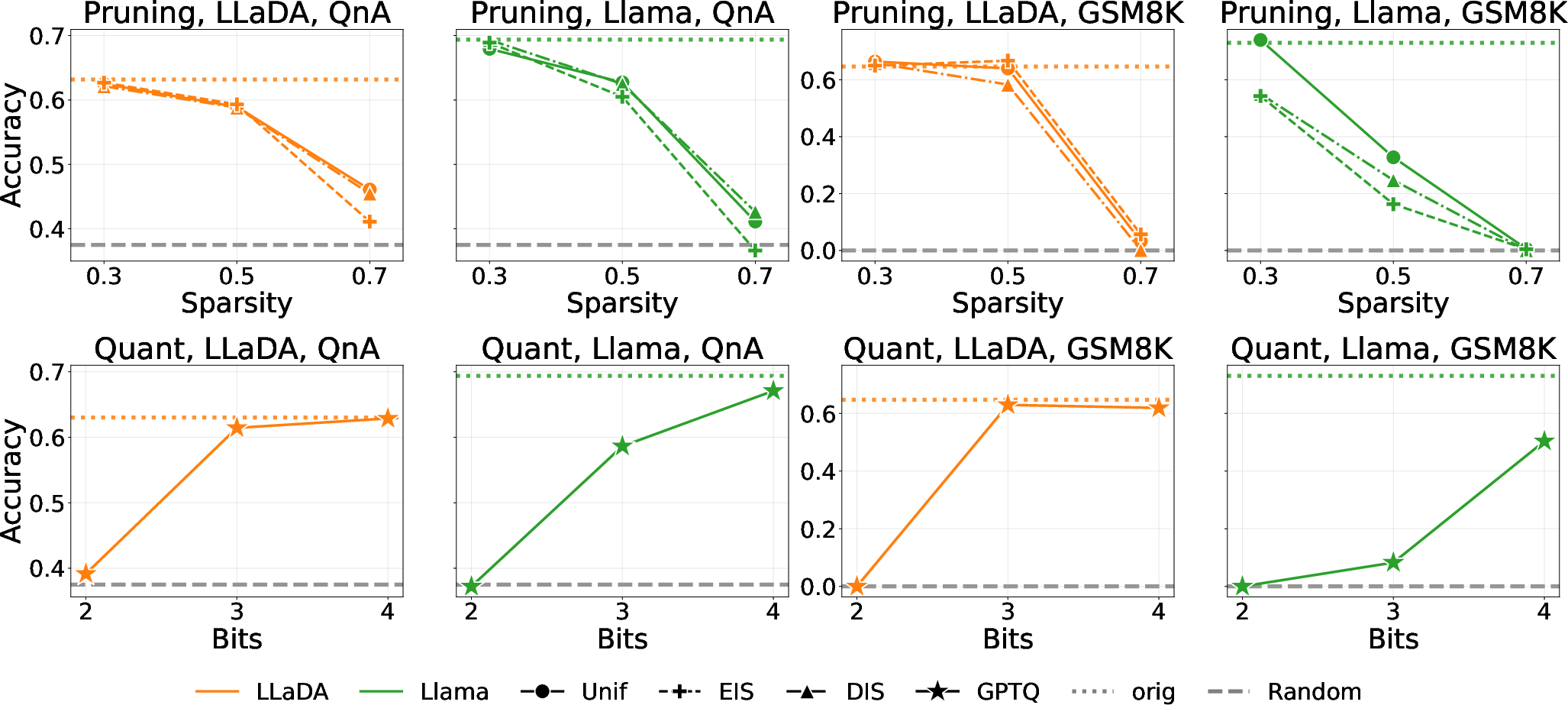
Figure 5: Compression performance for LLaDA-8B and Llama-3.1-8B: LLaDA-8B shows superior robustness under pruning and quantization, with inverted optimal sparsity allocation.
Controlled experiments at smaller scale (160M parameter models) further reinforce that these phenomena are inherent to the diffusion training objective, not architectural quirks; DLM-160M trained identically to AR-160M exhibits the same early-layer redundancy and compression robustness, without displaying a super-outlier due to its smaller scale.
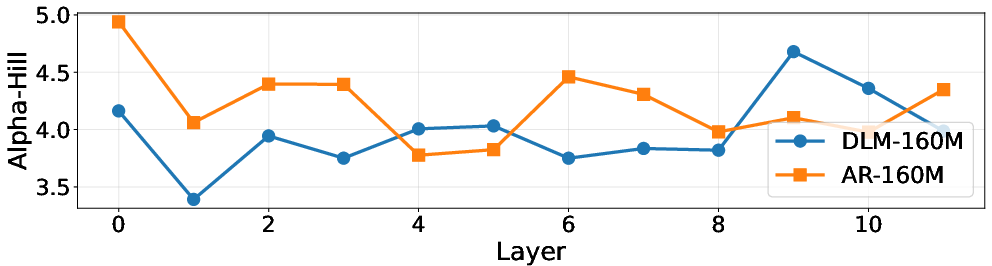
Figure 6: The Hill estimator signature replicates at small scale: DLM-160M displays more heavy-tailed early layers compared to AR-160M.
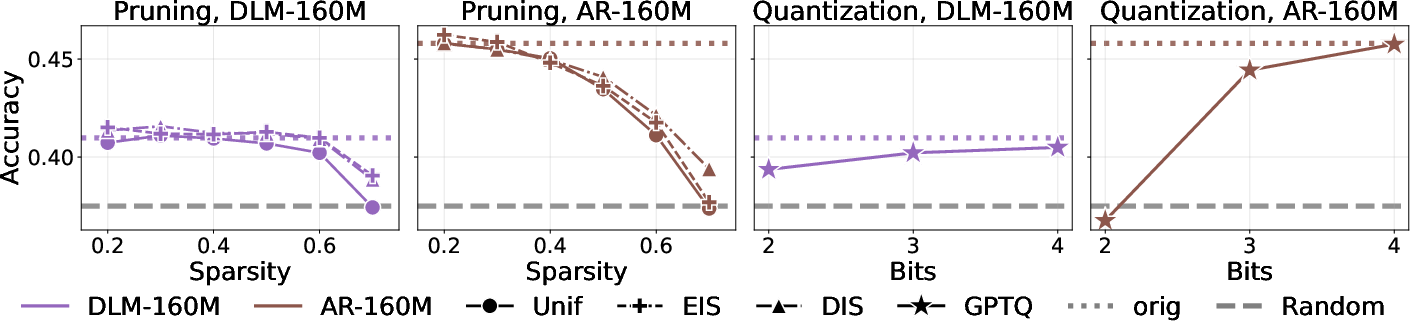
Figure 7: Robustness replication on the controlled 160M pair: DLM-160M outperforms AR-160M under quantization from 2 bits onward.
Theoretical Implications and Future Directions
The identification of layer collapse in DLMs due to overtraining and outlier channel domination fundamentally alters the understanding of internal representation dynamics in non-autoregressive models. These findings challenge assumptions inherited from AR transformer analyses and demand bespoke compression strategies tuned to DLM activation structure.
The emergence of a super-outlier suggests that diffusion objectives promote information concentration, potentially as a mechanism for managing the bidirectional, masked-noise context. However, this also introduces fragility: the model’s capabilities are acutely dependent on the integrity of this channel. Whether this is an artifact to be mitigated or a necessary architectural adaptation remains an open question.
Further, the pronounced compressibility of DLMs, and the inversion of optimal sparsity allocation heuristics, indicates that DLMs may be more suitable for deployment in resource-constrained environments, given appropriate compression algorithms. The heavy-tailed spectral evidence also opens the avenue for tailored training paradigms aiming to distribute learned features more evenly across channels and layers, potentially reducing redundancy and improving model generalization.
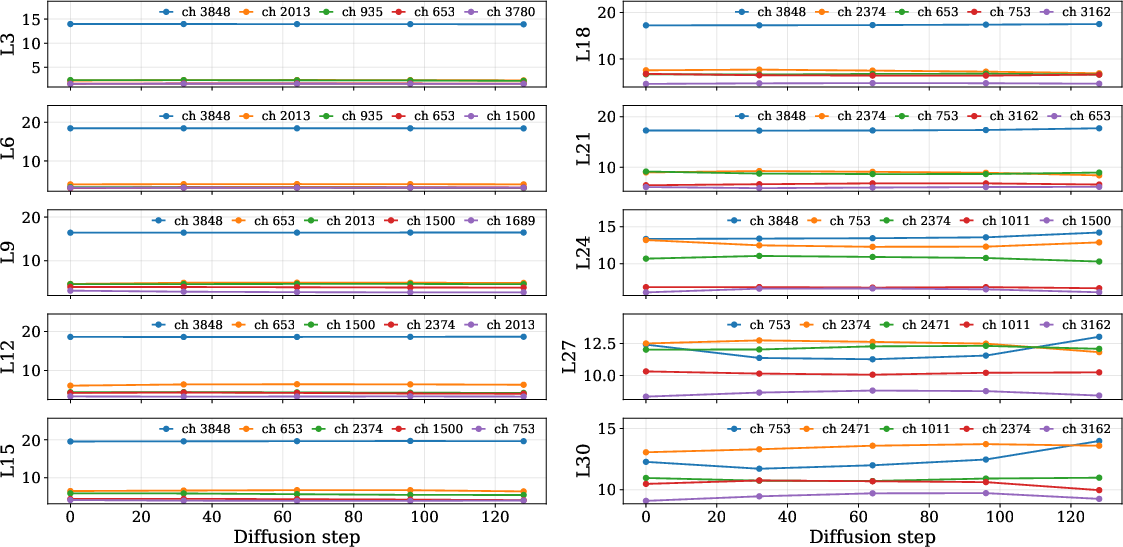
Figure 8: Channel magnitude mean of the top-5 largest channels in LLaDA-8B is invariant over diffusion steps, indicating persistent activation structure.
Conclusion
This paper provides a rigorous empirical and theoretical characterization of layer collapse in diffusion LLMs, identifying the critical role of a persistent super-outlier in driving early-layer redundancy and invertible compression behaviour compared to autoregressive transformers (2605.06366). The diffusion objective, rather than architecture, is shown to reshape internal activation dynamics, with practical consequences for optimal model compression and deployment. Future research is needed to dissect the formation mechanism and functional role of super-outlier channels and to develop diffusion-specific training and compression paradigms that better exploit or mitigate these structural phenomena.