When to Trust Imagination: Adaptive Action Execution for World Action Models
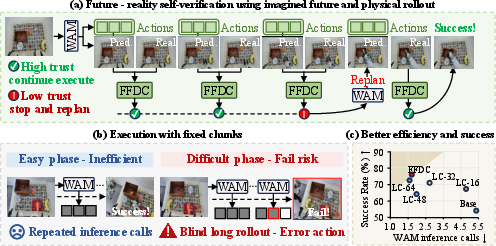
Abstract: World Action Models (WAMs) have recently emerged as a promising paradigm for robotic manipulation by jointly predicting future visual observations and future actions. However, current WAMs typically execute a fixed number of predicted actions after each model inference, leaving the robot blind to whether the imagined future remains consistent with the actual physical rollout. In this work, we formulate adaptive WAM execution as a future-reality verification problem: the robot should execute longer when the WAM-predicted future remains reliable, and replan earlier when reality deviates from imagination. To this end, we propose Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to estimate whether the remaining action rollout can still be trusted. FFDC enables adaptive action chunk sizes as an emergent consequence of prediction-observation consistency, preserving the efficiency of long-horizon execution while restoring responsiveness in contact-rich or difficult phases. We further introduce Mixture-of-Horizon Training to improve long-horizon trajectory coverage for adaptive execution. Experiments on the RoboTwin benchmark and in the real world demonstrate that our method achieves a strong robustness-efficiency trade-off: on RoboTwin, it reduces WAM forward passes by 69.10% and execution time by 34.02%, while improving success rate by 2.54% over the short-chunk baseline; in real-world experiments, it improves success rate by 35%.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Imagine a robot that can “daydream” a few seconds into the future: it predicts what it will see and what moves it will make next. Many modern robot brains do this, but they usually follow a fixed number of those imagined moves before checking again if things are still going to plan. This paper teaches robots a smarter way: keep going when your daydream matches reality, and stop early to replan when it doesn’t.
What questions did the researchers want to answer?
- Can a robot decide, moment by moment, whether to trust its imagined future?
- Can it automatically do longer stretches of action when things are predictable, and shorter stretches when things get tricky?
- Will this make robots both faster (fewer pauses to think) and more reliable (fewer mistakes)?
How did they try to solve it?
They built on “World Action Models” (WAMs). In simple terms, a WAM is a robot model that:
- looks at a camera image and a written instruction,
- imagines a short “future video” of what the world will look like,
- and plans a short sequence of actions (an “action chunk”) to make that future happen.
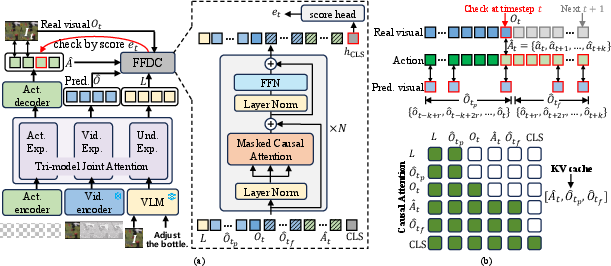
The new idea is to add a lightweight checker called FFDC (Future Forward Dynamics Causal Attention). Think of it like a coach watching both the robot’s plan and the live game:
- What the robot imagines: the future pictures and moves it plans.
- What actually happens: the real camera image now.
- What it’s trying to do: the instruction in words.
FFDC compares these and gives a trust score from 0 to 1:
- If the score is high, the robot keeps executing the current plan without asking the big model to think again.
- If the score drops, it stops and asks the model to replan from the latest camera view.
Why this helps:
- In easy, predictable parts (like moving straight toward a cup), the imagined future stays accurate for longer—so the robot acts longer without stopping, saving time and computation.
- In hard, messy parts (like precise contact or deformable objects), small errors can build up fast—so the robot checks more often and replans sooner, avoiding failure.
Training in kid-friendly terms:
- Mixture-of-Horizon Training: The robot practices planning with both short and long futures so it’s comfortable acting confidently for different lengths.
- Teaching the checker: They made a “yes/no” dataset of good and bad plan segments using real successes, real failures, and also “fake” bad examples by deliberately messing up good action sequences (like shuffling steps or adding noise). FFDC learns to tell which future rollouts are still safe to execute.
What did they find?
In simulation (RoboTwin benchmark with 50 tasks):
- 69.10% fewer calls to the big model (fewer “think again” moments).
- 34.02% less execution time (finished tasks faster).
- 2.54% higher success rate than a baseline that always executes short chunks.
In real robot tests:
- 35% higher success rate on two pick-and-place tasks.
Why this matters:
- The robot automatically adapts its “chunk size”—longer when its imagination matches reality, shorter when it starts to drift—without you hand-tuning a fixed number. This gives a better balance between being fast and being reliable.
Why is this important?
- More capable robots: They’ll move smoothly through easy parts and be cautious in hard parts, like humans do.
- Better use of compute: Fewer expensive “think again” steps when things are going to plan.
- Safer and more robust behavior: Early detection of mismatches prevents small errors from turning into failures.
Simple limitation to keep in mind:
- The checker currently learns with yes/no labels and a fixed decision threshold. Training it on richer kinds of mistakes and tuning the threshold more flexibly could make it even better.
In short, the paper shows a practical way for robots to decide “when to trust their imagination.” That simple idea—compare what you expected with what you see now—helps them act both faster and more safely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Calibration and decision thresholding
- Fixed global threshold () is used without systematic calibration; no per-task or adaptive thresholding, hysteresis, or cost-sensitive tuning to trade off false-continue vs false-replan decisions.
- Binary verification target
- The verifier predicts a binary executability score rather than a calibrated time-to-failure, remaining-horizon length, or risk-to-go; it is unclear whether continuous horizon estimation or survival analysis would yield better control.
- Error analysis and calibration
- No analysis of false positives/negatives, ROC curves, or post-hoc calibration (e.g., temperature scaling, conformal prediction) for ; uncertainty quantification and confidence calibration are not studied.
- Data coverage and labeling for verifier
- Verifier is trained from a small set of successful/failed rollouts plus synthetic corruptions; the diversity and representativeness of failure modes are unclear, and labeling noise or bias is not analyzed.
- Online/continual learning
- The verifier does not update from online experience (detected mismatches are not used for self-supervised refinement); no mechanism for active data collection of difficult or novel failure modes.
- Sensitivity to predicted-video quality
- FFDC depends on the WAM’s predicted latent video tokens; there is no ablation of verifier reliability as video-prediction fidelity degrades, nor strategies to mitigate failure when future imagination is poor.
- Applicability to WAMs without test-time video
- Some WAMs skip explicit future video generation at inference (e.g., latent-only or “Fast-WAM” variants); how FFDC adapts when predicted visual tokens are unavailable or too costly is not explored.
- Modality limitations
- Verification uses vision and language but excludes proprioception, force/torque, tactile, or audio; the impact of these modalities on detecting subtle contact deviations remains untested.
- Synchronization and timing assumptions
- The approach assumes a fixed action-to-video ratio and aligned tokens; robustness to sensor/actuator latency, dropped frames, variable frame rates, and time-stamp jitter is not evaluated.
- Verification frequency and latency
- The paper does not specify or study verification cadence, computation latency at control rates, or policies to adapt check frequency under tight real-time constraints.
- Attention-mask and windowing design
- The local-window causal mask size and structure are fixed; sensitivity analyses on window length, masking strategies, and cross-token interactions are missing.
- Mixture-of-Horizon Training
- Introduced but not ablated; its contribution to long-horizon coverage, executability prediction, and downstream task success is not quantified.
- Generalization across backbones
- Experiments rely on Motus; portability to other WAM families (e.g., unified video-action diffusion, action-centered WAMs) and different latent/tokenization schemes is untested.
- Comparative baselines for adaptive execution
- No head-to-head comparisons against existing adaptive methods (e.g., entropy/uncertainty schedulers, verifier-based replanning for VLA/diffusion) adapted to WAMs; ablations on combining policy-side uncertainty with FFDC are absent.
- Theoretical guarantees
- No formal analysis of stability, safety, or bounded regret (e.g., maximum steps executed after a mismatch before detection), and no guarantees on worst-case failure lengths.
- Chattering and oscillations
- Without hysteresis or temporal smoothing, rapid switching between “execute” and “replan” may occur; strategies to prevent oscillations and their impact on efficiency/safety are not examined.
- Robustness under severe distribution shifts
- While RoboTwin randomization is used, real-world tests cover only two simple pick-and-place tasks; performance on deformable objects, heavy occlusions, dynamic distractors, and cluttered/contact-rich scenes remains largely unknown.
- Embodiment and viewpoint generalization
- Cross-embodiment transfer (different arms/grippers) and multi-view or egocentric vs exocentric camera setups are not evaluated in the real world.
- Long-horizon scaling
- The maximum chunk/horizon (up to 64) is limited; behavior and verifier reliability on tasks requiring hundreds of steps or extended durations are untested.
- Computational footprint on embedded hardware
- Although the verifier is “lightweight,” there are no wall-clock benchmarks at control frequency, memory/KV-cache footprints, or viability on resource-constrained robots.
- Cache staleness and replanning protocols
- The impact of stale KV caches when the environment changes abruptly, cache-refresh policies, and potential hazards of executing with outdated predicted futures are not analyzed.
- Partial observability and occlusions
- The system assumes sufficient visual evidence at verification time; robustness to occlusions or missing observations, and the benefits of temporal memory, are not studied.
- Task semantics and instruction dynamics
- Only static language instructions are considered; handling changing goals or multi-stage instructions during execution is not explored.
- Recovery strategies beyond replanning
- The only response to detected mismatch is to replan; alternatives (e.g., slowing/smoothing, switching impedance, invoking recovery primitives, requesting human help) are not integrated or evaluated.
- Dataset transparency and reproducibility
- Exact counts of positive/negative samples, corruption distributions, and release plans for code/data are unspecified, hindering reproducibility and fair comparison.
- Safety evaluation
- No safety metrics (e.g., contact forces, collision counts) or failure-mode taxonomy in real-world trials; effects of verification mistakes in safety-critical settings remain unassessed.
Practical Applications
Overview
This paper introduces FFDC-WAM: a lightweight, future–reality verifier layered on top of World Action Models (WAMs) that adaptively decides how long to execute an action sequence before replanning, based on the consistency between imagined futures (predicted visual dynamics and actions) and real-time observations. The result is fewer model calls and faster task completion in predictable phases, and earlier replanning in contact-rich or uncertain phases—improving both efficiency and robustness.
Below are concrete, real-world applications that leverage the paper’s findings, methods, and innovations. Each item states the sector, what is enabled, the potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These are deployable now (pilot-ready or integrable into existing robotics stacks) assuming access to a WAM that can output predicted actions and latent future visual tokens and a GPU/edge accelerator for on-robot inference.
- Adaptive cobot execution for assembly and insertion
- Sector: Robotics (manufacturing)
- What: Plug FFDC into cobot/WAM controllers to execute long open-loop motions in free-space phases (e.g., approach) and replan at contact/precision stages (e.g., insertion, fastening), reducing cycle time and failures.
- Tools/workflows: ROS 2 “FFDC Executor” node; “Horizon Scheduler” that adjusts chunk size per confidence; integration with teach-by-demonstration pipelines; shop-floor dashboards showing FFDC confidence timelines.
- Assumptions/dependencies: Trained WAM for target tasks; calibrated RGB cameras; controller synchronization with action and video token frequencies; GPU or edge TPU for intermittent WAM calls and high-rate FFDC.
- Faster and safer bin picking and kitting
- Sector: Logistics/warehousing, e-commerce fulfillment
- What: Use FFDC to sprint through predictable pick trajectories and slow/replan near clutter, deformables, or ambiguous grasps, cutting regrasp and drop rates.
- Tools/workflows: Bin picking stacks with perception–WAM–FFDC; telemetry that gates gripper closure when FFDC confidence drops; escalation to re-detection or alternate grasp proposals.
- Assumptions/dependencies: Sufficient pretraining on diverse objects/motions; stable camera viewpoints; confident pose/instance estimates feeding WAM context.
- Service and home robots with compute-aware autonomy
- Sector: Consumer/service robotics (hospitality, cleaning, tidying)
- What: Reduce battery and cloud costs by calling the WAM less often in predictable phases while maintaining responsiveness near obstacles/contacts.
- Tools/workflows: On-device FFDC module with budget-aware inference scheduling; low-confidence triggers for scene re-scan or motion slowing.
- Assumptions/dependencies: Onboard compute capable of intermittent WAM calls; reliable vision in clutter; task instructions provided via natural language or presets.
- Shared autonomy and teleoperation assistance
- Sector: Robotics operations, field service
- What: Use FFDC confidence as a gating signal to hand control back to a human operator or request teleop when future–reality consistency degrades.
- Tools/workflows: Operator UIs with FFDC confidence overlays; policy arbitration that blends autonomy with teleop based on thresholds.
- Assumptions/dependencies: Reliable comms for teleop fallback; tuned FFDC thresholds for the desired autonomy–safety trade-off.
- Robust robotic data collection and MLOps for control
- Sector: Software/infrastructure for robotics
- What: Use FFDC to annotate “hard” segments (low confidence) and “easy” segments (high confidence) during rollouts, enabling targeted data collection and re-training of WAMs.
- Tools/workflows: FFDC-driven active data gathering; automated replay of low-confidence intervals; Mixture-of-Horizon Training recipes integrated into training jobs; confidence-driven curriculum learning.
- Assumptions/dependencies: Logging pipelines for predicted tokens, actions, and real observations; scalable training infrastructure.
- Compute and latency budgeting at the edge
- Sector: Edge AI/embedded systems
- What: Decrease average WAM forward passes while maintaining success rates; extend battery life and reduce thermal load on mobile platforms.
- Tools/workflows: FFDC-based inference throttling; KPI dashboards linking “calls saved per task” to energy usage; per-task confidence calibration.
- Assumptions/dependencies: Stable time synchronization; accurate timing of action-to-video frequency ratio r to align tokens.
- Safer manipulation via confidence-aware speed and force limits
- Sector: Industrial safety, HRI
- What: Tie speed/force scaling to FFDC confidence (e.g., ISO/TS 15066 compliant modes), slowing near contacts or unknowns.
- Tools/workflows: Runtime safety layer that maps low confidence to reduced speed and force; automatic stops and replans on sustained low scores.
- Assumptions/dependencies: Safety-certified controllers; validated FFDC thresholds; reliable detection of persistent low-consistency conditions.
- Academic benchmarking and teaching modules
- Sector: Academia (robotics, machine learning)
- What: Use FFDC as a reproducible baseline for adaptive execution research; incorporate Mixture-of-Horizon Training and synthetic negative generation in coursework.
- Tools/workflows: Open-source FFDC “verifier” library; RoboTwin-based labs; ablation protocols for comparing chunking vs verification strategies.
- Assumptions/dependencies: Access to RoboTwin or equivalent simulators; public WAM checkpoints or reproducible training scripts.
- Simulation-to-real stability checks
- Sector: Research and prototyping
- What: Deploy FFDC during sim2real transfer to detect when learned policies drift under real noise and contacts, triggering localized replans or policy swaps.
- Tools/workflows: Real-time drift monitors; structured logs of prediction–observation mismatches for diagnostics; automated parameter sweeps for threshold tuning.
- Assumptions/dependencies: Comparable observation spaces between sim and real; consistent tokenizers/encoders.
- Synthetic corruption library for verification training
- Sector: Software tooling for robotics ML
- What: Reuse the paper’s negative-sample augmentations (temporal swap, gripper flip, late-stage noise, tail scaling) to quickly bootstrap verifiers for new tasks.
- Tools/workflows: Standalone “Verifier-DataKit” to generate positives/negatives; integration with data versioning and labeling tools.
- Assumptions/dependencies: Access to demonstration trajectories; task-specific gripper/action semantics for meaningful corruptions.
Long-Term Applications
These require further research, scaling, or development (e.g., domain adaptation, certification, formal guarantees, or broader pretraining).
- Assisted surgical and medical manipulation
- Sector: Healthcare
- What: Employ FFDC-like verification to adapt action horizons in tissue manipulation, suturing, or catheter routing—replanning as soon as predicted tissue response diverges.
- Tools/workflows: Sterile-certified robotic stacks; FFDC integrated with force/vision sensing; human-in-the-loop gating.
- Assumptions/dependencies: Regulatory approval; stronger safety guarantees; specialized WAMs trained on medical tasks and multimodal sensing (force, ultrasound).
- Autonomous driving and mobile manipulation with receding-horizon verification
- Sector: Mobility/transport
- What: Generalize future–reality verification to motion planning (e.g., adaptive MPC horizons) where predicted scene evolution (traffic, pedestrians) is compared against real observations to adjust replan frequency.
- Tools/workflows: Video-trajectory WAMs for driving; FFDC-like verifier gating planner calls; confidence-aware speed control.
- Assumptions/dependencies: Robust long-horizon prediction under occlusions; multi-agent reasoning; stringent safety and certification needs.
- Household humanoids and complex domestic tasks
- Sector: Consumer robotics
- What: Execute multi-step tasks (folding laundry, loading dishwashers) with adaptive horizons—long in free motion, short near deformables or tight clearances.
- Tools/workflows: Generalist WAMs pretrained on diverse household data; FFDC-based subtask schedulers; language-driven task decomposition with verifier checks.
- Assumptions/dependencies: Larger-scale pretraining on deformables and long-horizon tasks; reliable perception in clutter; safe HRI policies.
- Agricultural harvesting and handling of deformables
- Sector: Agriculture
- What: Apply verification-aware control during fruit picking, vine handling, or pruning where contact dynamics are uncertain.
- Tools/workflows: Outdoor-capable WAMs; multimodal sensing (depth, tactile) fused into predicted dynamics; confidence-triggered replans or human oversight.
- Assumptions/dependencies: Robustness to lighting/weather; domain-specific data; seasonal retraining.
- Formal safety layers combining learned verification with guarantees
- Sector: Safety engineering, certification
- What: Compose FFDC confidence with control barrier functions or formal monitors to enforce hard constraints while benefitting from learned adaptability.
- Tools/workflows: Hybrid runtime assurance (RTA) stack with FFDC as the early-warning channel; certified fallback controllers.
- Assumptions/dependencies: Theoretical analyses linking FFDC scores to risk bounds; verification of token alignment and failure coverage.
- Fleet-level compute orchestration and cost-aware autonomy
- Sector: Cloud robotics, operations
- What: Schedule heavy planner/WAM inference on shared edge/cloud resources only when FFDC indicates need, lowering per-robot compute budgets at scale.
- Tools/workflows: Confidence-aware inference queues; SLAs pegged to “confidence-weighted” autonomy budgets; billing tied to avoided calls.
- Assumptions/dependencies: Reliable telemetry; latency constraints; robust fallback behaviors when compute is throttled.
- Self-improving robots via low-confidence mining
- Sector: Robotics ML/RL
- What: Continually log low-confidence segments to bootstrap new tasks or expand failure coverage, driving iterative retraining of both WAM and verifier.
- Tools/workflows: Auto-labeling pipelines; human-in-the-loop triage of novel failure modes; curriculum design that emphasizes hard phases.
- Assumptions/dependencies: Data governance; mechanisms to avoid reinforcing spurious correlations; deployment-time data collection policies.
- Cross-embodiment policy transfer with verification
- Sector: General-purpose robotics
- What: Use FFDC to gate transfer of WAM-generated plans across different manipulators by rejecting segments that don’t align with the new embodiment’s observations.
- Tools/workflows: Embodiment adapters; verifier fine-tuning on small real datasets; embodiment-aware confidence calibration.
- Assumptions/dependencies: Scalable world–action pretraining across embodiments; standardized token spaces.
- Ultra-low-power verifiers and alternative sensors
- Sector: Edge AI hardware
- What: Distill FFDC to microcontrollers or leverage event cameras for low-latency verification on small mobile platforms.
- Tools/workflows: Model compression/distillation; neuromorphic front-ends; asynchronous token alignment.
- Assumptions/dependencies: Maintained verification fidelity after compression; sensor fusion to reduce visual domain gaps.
- Policy and standards for “introspective autonomy”
- Sector: Policy/regulation, standards bodies
- What: Define reporting and safety standards that require autonomous systems to demonstrate self-verification (e.g., logging confidence, halting on sustained low scores).
- Tools/workflows: Compliance test suites simulating distribution shifts; standardized interfaces for confidence telemetry and intervention.
- Assumptions/dependencies: Consensus on metrics linking confidence to safety; cross-industry adoption.
Notes on Feasibility and Dependencies
- Model capabilities: FFDC assumes access to a WAM that produces both future actions and latent visual tokens aligned in time. If a WAM omits video at inference, latent predictions must be enabled or approximated.
- Sensor quality and synchronization: Future–reality comparison depends on reliable, time-synchronized observations that match the WAM’s tokenization and frequency ratio r.
- Data coverage: Verifier quality is bounded by the diversity of positive/negative samples. Synthetic corruptions help, but broader real failure modes increase robustness.
- Compute: FFDC is lightweight but still requires on-device inference for high-rate checks and intermittent WAM calls; plan for GPU/accelerator capacity and thermal limits.
- Safety: FFDC improves responsiveness but does not provide formal guarantees; critical domains require additional certified safety layers and rigorous validation.
- Integration: Smooth deployment typically requires ROS 2 or similar middleware, controller access for dynamic chunking, and MLOps for logging and continuous improvement.
These applications leverage the paper’s core innovation—adaptive action execution via future–reality verification—to deliver practical gains in efficiency, robustness, and operational cost across multiple sectors.
Glossary
- [CLS] token: A special transformer token used to aggregate information from a sequence for classification or scoring. "a [CLS] token attends to the full visible sequence"
- Action chunk: A short sequence of consecutive actions predicted and executed as a unit between model inferences. "At each inference step, a WAM predicts a chunk of future actions"
- Action chunking: The practice of executing actions in fixed-length chunks before replanning. "Standard action chunking executes the predicted chunk in an open-loop manner"
- Action-to-video frequency ratio: The rate mapping between action steps and predicted video frames used for temporal alignment. "where is the action-to-video frequency ratio."
- Adaptive action execution: Dynamically deciding how many predicted actions to execute before replanning based on reliability signals. "A growing body of work studies adaptive action execution to mitigate the limitations of fixed open-loop rollout."
- Causal attention: An attention pattern constrained by temporal causality to prevent information leakage from future to past. "FFDC performs structured causal attention, enforcing temporally aligned interaction between action and predicted visual dynamics."
- Causal consistency: The alignment between predicted dynamics, real observations, and planned actions under causal constraints. "If the predicted visual dynamics, the real observation, and the planned actions remain causally consistent, the robot can continue executing the current chunk"
- Contact-rich: Describing tasks or phases that involve significant physical contact and complex interactions. "restoring responsiveness in contact-rich or difficult phases."
- Cross-embodiment learning: Generalizing control policies across different robot bodies or morphologies. "strong performance in zero-shot generalization, cross-environment transfer, and cross-embodiment learning."
- Cross-environment transfer: Transferring learned policies to new environments with different layouts or conditions. "strong performance in zero-shot generalization, cross-environment transfer, and cross-embodiment learning."
- Degrees of Freedom (DoF): The number of independent joint or motion parameters a robot can control. "an Astribot S1 robot with 34 DoF"
- Diffusion policies: Robot control policies based on diffusion models that generate actions by denoising. "Existing adaptive execution methods for diffusion policies or VLA models"
- Distribution shift: A change in the data distribution between training and deployment conditions. "a challenging benchmark for testing generalization under distribution shift."
- Entropy-based chunk-size selection: Choosing action chunk length using entropy or uncertainty measures. "including multi-horizon action prediction, entropy-based chunk-size selection, verifier-based replanning"
- Executability: Whether a predicted action segment can be safely and successfully executed given current observations. "train it to predict the executability of the remaining action segment."
- Forward dynamics: The model of how observations evolve given the current state and action. "including forward dynamics "
- Future Forward Dynamics Causal Attention (FFDC): A lightweight verifier that uses causally structured attention over predicted actions/visuals and real observations to judge rollout reliability. "we propose Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier"
- Future--reality verification problem: Deciding online whether imagined futures still match reality to adapt execution length. "we formulate adaptive WAM execution as a future--reality verification problem"
- Gripper flip: A data augmentation that inverts designated gripper control dimensions to synthesize failures. "gripper flip negates the designated gripper dimensions"
- Inverse dynamics: The mapping from pairs of observations to the action that causes the transition. "inverse dynamics "
- KV cache: A stored set of key–value pairs from transformer computations reused to avoid recomputation. "and then stored as a KV cache."
- Latent visual tokens: Compressed, tokenized representations of predicted or observed images/videos used by the model. "corresponding latent future visual tokens"
- Latent world features: Compact internal representations of the world state used instead of decoded pixels at inference. "relying on latent world features or even skipping explicit future rollout at inference time"
- Local window (attention): Restricting attention to a small temporal neighborhood to reduce compute and enforce locality. "this attention is applied with a local window over the temporally ordered future tokens"
- Long-horizon execution: Executing or planning over many future steps before replanning. "preserving the efficiency of long-horizon execution"
- Marginal action distribution: The distribution of actions conditioned only on current observations. "the marginal action distribution "
- Marginal image distribution: The distribution of next observations conditioned only on current observations (video generation). "the marginal image distribution corresponding to video generation"
- Mixture-of-Horizon Training: A training approach that mixes different action horizons to improve long-horizon coverage. "We further introduce Mixture-of-Horizon Training to improve long-horizon trajectory coverage"
- Mixture-of-horizon sampling strategy: Sampling training segments with varied horizons to reduce bias toward early-episode prefixes. "we train WAM with a mixture-of-horizon sampling strategy."
- Multi-horizon action prediction: Predicting actions at several horizon lengths for flexible execution. "including multi-horizon action prediction, entropy-based chunk-size selection"
- Online executable-horizon estimation: Estimating during execution how far into the future the current plan remains feasible. "and online executable-horizon estimation"
- Open-loop rollout: Executing a fixed sequence of actions without feedback-based replanning during the chunk. "fixed open-loop rollout."
- Pixel-level video decoding: Generating full-resolution future frames, which is computationally heavy. "Since pixel-level video decoding is expensive"
- Policy-side confidence: A model-derived confidence measure used to gate execution decisions. "based on action uncertainty, entropy, or policy-side confidence."
- Rectified flow-matching losses: Training objectives based on flow matching (with rectification) for joint action and video prediction. "the model is optimized with rectified flow-matching losses for both action and video prediction"
- RoboTwin benchmark: A large-scale simulated benchmark for evaluating robotic manipulation and generalization. "Experiments on the RoboTwin benchmark and in the real world demonstrate that our method achieves"
- Scheduler-based chunk downsampling: Reducing action frequency or chunk size with a learned scheduler to accelerate execution. "scheduler-based chunk downsampling"
- Self-verification: Using the model’s own predicted future to check consistency with reality during execution. "This creates a new form of self-verification."
- Semantic tokens: Instruction-conditioned tokens capturing task semantics used by the verifier. "the semantic tokens from the Understanding expert."
- Spatiotemporal priors: Learned expectations over space and time that aid prediction and control. "WAMs acquire spatiotemporal priors and physical dynamics knowledge"
- Structured Boolean visibility matrix: An attention mask defining which tokens can attend to which, enforcing causal structure. "a structured Boolean visibility matrix , where means token can attend to token ."
- Tail scaling: A data augmentation that scales a suffix of an action sequence to synthesize failures. "tail scaling shrinks a randomly sampled suffix by a random scale factor."
- Temporal swap: A data augmentation that swaps actions in time to produce inconsistent plans. "The temporal swap operator randomly swaps two pairs of actions within a horizon"
- Understanding expert: A module producing instruction-conditioned semantic tokens for the verifier. "the semantic tokens from the Understanding expert."
- Verifier-based replanning: Triggering replanning when a learned verifier indicates the rollout is unreliable. "verifier-based replanning"
- Vision-language-action (VLA) policies: Models that map visual observations and language instructions to actions. "Unlike conventional vision-language-action policies that mainly generate actions from the current observation and instruction"
- World Action Models (WAMs): Models that jointly predict future actions and future visual observations for control. "World Action Models (WAMs) have recently emerged as a promising paradigm for robotic manipulation by jointly predicting future visual observations and future actions."
- Zero-shot control: Performing tasks without task-specific fine-tuning on the deployment environment. "Recent WAMs have demonstrated strong performance in zero-shot control, cross-environment transfer, and cross-embodiment learning."
- Zero-shot generalization: Succeeding on unseen tasks/domains without additional training. "have demonstrated strong performance in zero-shot generalization, cross-environment transfer, and cross-embodiment learning."
Collections
Sign up for free to add this paper to one or more collections.