Agentic, Context-Aware Risk Intelligence in the Internet of Value
Abstract: The Internet of Value (IoV) is a heterogeneous, partially-trusted network in which the dominant marginal risk is composite (route, sentiment, liquidity, and the policy a system is willing to commit to) rather than a property of any single chain. We argue that a risk primitive adequate for this regime is a composition of five engines: a prediction engine over price, liquidity, volatility, and route health; a Bittensor verification subnet that decentralises and economically scores prediction outputs; a sentiment-fusion engine over text, on-chain flow, and grey-literature feeds; an agentic engine under constitutional, role-bound action constraints; and an API-risk and scenario engine that converts forecasts into pre-committed action programs in the sense of Monte-Carlo scenario generation. We anchor the architecture in two empirical artefacts: a 27-hour policy-constrained liquidity stress-response experiment on Solana, and a 168-hour prediction-router calibration arc reported with explicit class-imbalance honesty. The case study supports deployability; the validator-loss decomposition is stated formally and is falsifiable.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Agentic, Context-Aware Risk Intelligence in the Internet of Value”
1. What is this paper about?
This paper is about making smarter and safer tools for moving money across many different blockchains. Think of blockchains like separate highways, and “bridges” as the roads that connect them. Today, the biggest risks don’t come from just one highway—they come from how all the highways, bridges, news, and even automated “robot” traders interact. The authors propose a five-part system that predicts risks, checks those predictions, watches online mood, follows strict rules when acting, and turns forecasts into clear “if-this-then-do-that” plans.
2. What questions are they trying to answer?
- What should a modern “risk tool” do when value moves across many chains, not just one?
- How can we keep this tool honest, so it doesn’t cheat, overreact, or get fooled by hype?
- Can such a system work in the real world, with clear rules and safety checks?
3. How did they do it? (Approach in everyday language)
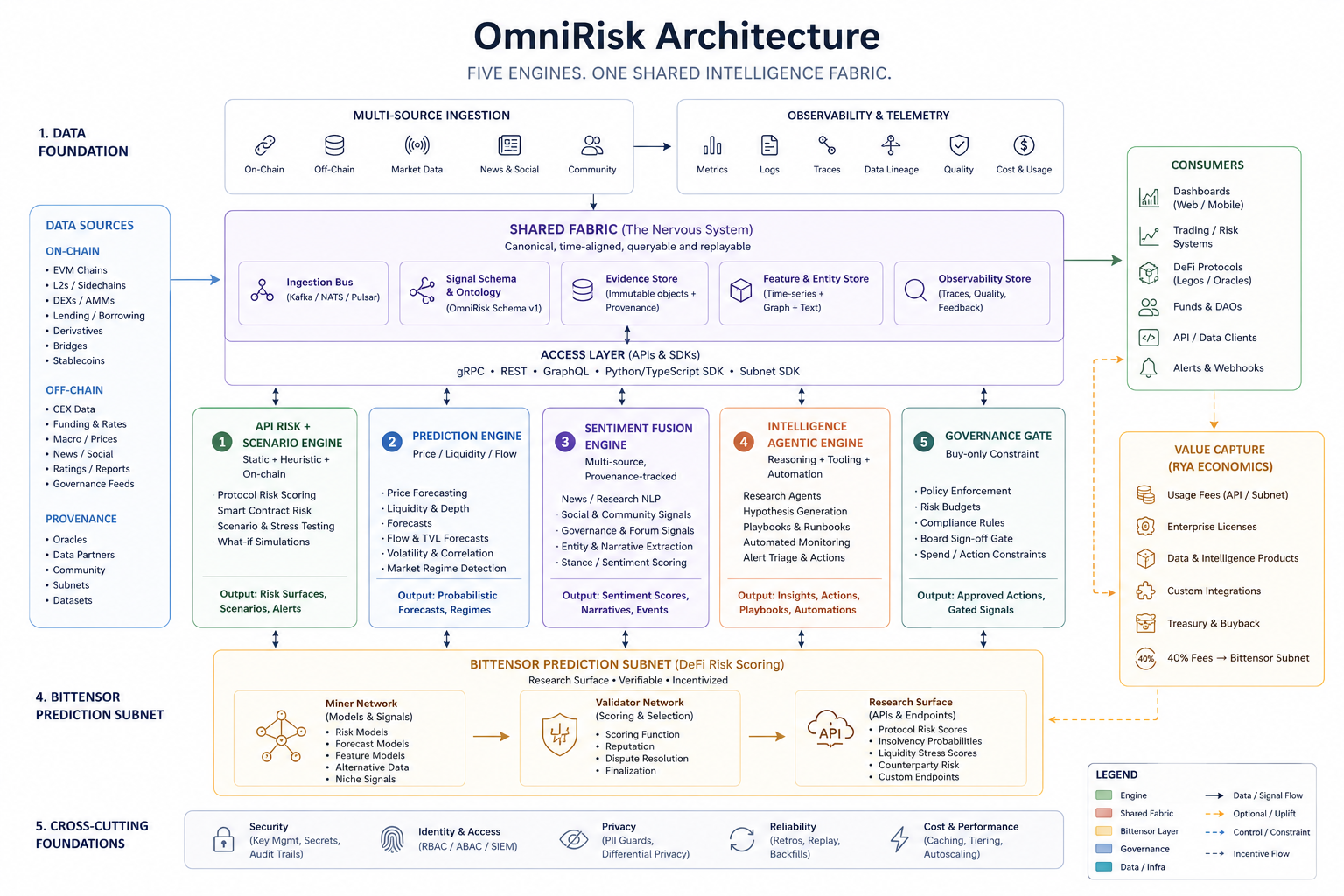
The system has five engines that work together, all fed by a shared data hub that gathers on-chain activity, market data, news, and community signals. Below are the five engines with simple analogies:
- Prediction engine: Like a weather forecast, but for crypto. It estimates price moves, how easy it is to trade (liquidity), and route health across chains.
- Verification engine (Bittensor subnet): Like a league of referees who independently score those forecasts and reward the best ones. If this referee layer becomes noisy or unhelpful, the system can switch it off and keep going (“killable uplift”).
- Sentiment-fusion engine: Like listening to both the crowd and the scoreboard. It blends news, social chatter, and on-chain flows to measure the market’s mood, because rumors can spread faster than transactions.
- Agentic engine (rule-following robot): An AI assistant that can act, but only inside a strict rulebook (a “constitution”). For example: “buy-only,” “don’t touch the deployer wallet,” “stay paused unless humans approve going live,” and “stop if the price crashes too fast.”
- API-risk and scenario engine: Like a fire drill. It turns forecasts into pre-committed plans: “If A happens within time window B and probability is high enough, then do action C, using at most D resources.”
Technical terms made simple:
- Liquidity: How easily you can buy/sell without moving the price too much (like how much water is in a pool).
- Time-weighted slicing: Splitting one big trade into many small ones over time so you don’t splash the pool.
- Constant-product pool (AMM): A pricing rule that keeps the product of two token amounts the same; bigger trades move the price more (like a seesaw).
- Brier score: A way to grade predictions; lower is better because it punishes wrong and overconfident guesses.
- Class imbalance: When “bad events” are rare, saying “nothing bad happens” can look very accurate, even if it’s not a smart prediction.
They also separate “who is allowed to act with what rules” (human approvals, caps, and audit logs) from “how the software runs each step.” This separation makes it easier to audit and trust.
4. What did they find, and why is it important?
They tested the system in three ways:
- Solana stress-response experiment (27 hours):
- They ran a simple “buy-only” policy on a small Solana token (RYA), using many tiny buys over time with strict safety rules: daily spending caps, human approvals, and an automatic “stop-loss” that pauses if the price drops too fast.
- The safety circuit worked: when the price fell sharply, the engine auto-paused exactly as designed—like hitting an emergency brake.
- The rules were followed even during pressure: all exceptions (like raising the daily cap) required written reasons and human approval, recorded publicly. This shows the system can act but still stay inside its rulebook.
- Prediction calibration (168 hours):
- Their live predictions improved from “barely above chance” (about 53% accurate) to very high directional accuracy on a specific, large-asset group.
- Important honesty note: those very high numbers come from a group where crashes are rare (class imbalance). The better metric, the Brier score (~0.1335), shows they’re better than random but not perfect. The big point: they have real, trackable measurements that a verification network could score.
- Bittensor verification “shadow run”:
- They rehearsed the referee network on testnet for ~57 hours with thousands of successful rounds and no auth failures. This shows the plumbing works, though they still need to test scoring with many real participants at scale.
Why this matters:
- The system isn’t just ideas—it ran with real money under strict safety rules.
- It shows you can combine forecasts, public mood, and rule-bound actions, and you can measure and audit the whole process.
- It lays out a formal scoring plan for rewarding good predictors and penalizing inconsistency or overconfidence.
5. What’s the impact? Why should we care?
- Safer cross-chain world: Money moves across many blockchains now. A system that predicts trouble early, listens to news, and only acts under strict rules can reduce losses from panics, scams, or broken bridges.
- Honest AI agents: Letting AI act with money is risky. A constitution, human approvals, and stop-loss rules keep the AI from going rogue.
- Verifiable forecasting: A decentralized referee layer can reward accurate, well-calibrated predictions—pushing the whole ecosystem toward better risk signals.
- Clear limits and next steps: The authors openly say what hasn’t been proven yet (for example, large-scale verification scoring) and explain the smallest experiments that could prove or disprove their claims. That makes the work testable and trustworthy.
In short, the paper introduces a five-part “risk brain” for the Internet of Value: it forecasts, cross-checks, listens to the crowd, follows a rulebook, and prepares “if-then” plans. Early tests show it can run safely in the wild, and the authors explain exactly how others can verify and challenge it next.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work.
- Verification subnet not evaluated at scale: no multi-miner, multi-validator live metagraph experiment has measured the proposed three-component validator loss (Brier, inconsistency, calibration) or its stability under real incentives.
- Unspecified disable criteria for the “killable-uplift” property: the variance threshold and monitoring window that trigger disabling the subnet are not defined or justified.
- Event resolver design is underspecified: thresholds and exact definitions for – (“material chain-state event”) are not enumerated, and no sensitivity analysis shows how different resolver choices affect scores or incentives.
- Label alignment gap in evaluation: the “didCrashAcc.” metric in the 168-hour calibration arc is not explicitly mapped to the – resolver used by the verification design, leaving potential mismatch between training/evaluation labels and subnet scoring labels.
- Class imbalance not fully addressed: beyond reporting Brier score, there is no reporting of recall/precision, ROC/AUPRC, or cost-weighted metrics under low base-rate conditions; the true error profile remains unknown.
- Horizon mismatch: prediction router uses a 168-hour evaluation window while the verification loss proposal uses hours; the effect of horizon choice on miner incentives, timing, and performance is untested.
- Optimal scoring-window and reward-lag choices are open: the impact of and one-epoch reward lag on strategic behavior (e.g., “no-crash” predictions harvesting base-rate) and calibration is not evaluated.
- Anti-gaming for inconsistency component is incomplete: the paper notes miners might learn the query distribution; no countermeasures (e.g., randomized/obfuscated queries, commit–reveal, private sampling) are designed or tested.
- Stake concentration and collusion risks lack quantitative analysis: the conditions under which Yuma clipping fails (e.g., stake ≥ 50%) and the governance mechanisms to prevent or respond to such concentration are not specified or stress-tested.
- Sybil and bribery resistance unassessed: there is no empirical or theoretical analysis of validator/miner sybil strategies, bribery attacks, or their economic feasibility under the proposed scoring and reward rules.
- Parameterization of calibration binning is unvalidated: bin width 0.1 and window size are proposed without empirical justification; convergence speed and reliability-curve smoothness vs. variance trade-offs remain unknown.
- Sentiment-fusion performance is unmeasured: no accuracy, calibration, or ablation results are provided for early vs. late vs. stacking fusion; contribution of each modality (news, social, on-chain) remains unquantified.
- Robustness to sentiment/data poisoning is untested: the “fusion-divergence detector” is mentioned but no detection thresholds, false-positive/negative rates, or red-teaming results (e.g., coordinated news + wash-trade attacks) are reported.
- Multilingual and low-resource sentiment coverage is unknown: there is no assessment of non-English channels or micro-cap discourse quality on sentiment signal fidelity across chains/ecosystems.
- Cross-chain generality is unvalidated: empirical work is confined to a single Solana micro-cap pool; there is no experiment on multi-chain tokens, bridges, or heterogeneous venues where route-level risk is central.
- No causal attribution in the case study: reconvergence is described without a counterfactual or causal analysis (e.g., synthetic control), leaving the policy’s effect size unestimated.
- Agentic engine not evaluated in LLM-mediated mode: the case study uses a deterministic Trader policy; there is no evidence on how the constitutional, role-bound LLM agent performs under prompt injection, tool-use errors, or adversarial inputs.
- Policy-compliance and safety KPIs are missing: rates of policy violations, escalation latency, mean time to pause/resume (MTTD/MTTR), and false-positive/negative action triggers are not reported.
- Scenario engine complexity untested: only a simple buy-only program is exercised; multi-trigger, multi-role, concurrent programs with resource bounds and conflict resolution are not evaluated.
- Action-ladder and ratchet parameter sensitivity is unstudied: the impact of tier thresholds, basis-point ratchets, cooldowns, and stop-loss settings on outcomes (e.g., slippage, drawdown) lacks analysis.
- Liquidity and route-health metrics are undefined: the paper references “liquidity depth” and “route-health scalars” without formal definitions, computation methods, or benchmarks for accuracy and stability.
- Price-impact effects of time-weighted slicing are unmeasured: no estimate of slippage reduction, adverse selection, or measurable pool impact relative to unsliced execution is provided.
- Distribution shift and regime robustness are unassessed: model performance under volatility spikes, liquidity droughts, and narrative cascades over longer horizons is not quantified.
- Baseline comparisons are absent: there is no head-to-head against simpler baselines (e.g., “no-crash” predictor, volatility thresholds, single-chain risk engines) on common datasets.
- Lead-time benefit is unverified: Hypothesis H1 (cross-chain liquidity-fragmentation features improve early-detection lead time) is stated but not tested with timestamped detection lead-time metrics vs. single-chain baselines.
- Miner calibration reward hypothesis is untested: Hypothesis H2 (calibrated miners receive higher Yuma weight) lacks experimental validation with multiple distinct miner protocols.
- Operational performance and cost are unmeasured: throughput, latency, and cost scaling for ingestion, fusion, prediction, and subnet verification are not reported; SLOs/SLA targets are absent.
- Audit-trail integrity lacks cryptographic guarantees: while logs are “append-only, replicated,” no cryptographic anchoring (e.g., hashing to a blockchain), third-party attestation, or tamper-evidence is demonstrated.
- Governance-controls assurance is partial: approvals live in issue threads; there is no formal verification of the “runtime cannot bypass policy boundary” property, nor proofs that approval records cannot be forged on a compromised host.
- Residual security risks are acknowledged without mitigation metrics: no detection efficacy, false-alarm rates, or red-team results are provided for replay within windows, oracle/venue manipulation across sources, or host compromise scenarios.
- Key management and execution security are opaque: hot-wallet protections, HSM/TEE use, nonce management, and transaction signing policies are not detailed or evaluated against real attack models.
- Event-frequency and class-imbalance handling in rewards is unresolved: how the reward function avoids over-incentivizing trivial base-rate predictions (e.g., “no crash”) is not analyzed.
- Optimal probability-to-action mapping is undeveloped: how forecast distributions translate into triggers and resource bounds (e.g., threshold selection, risk budgets) lacks formalism and empirical tuning.
- Ground-truth datasets are limited: while some logs and CSVs are provided, the underlying datasets for miner scoring, sentiment labels, and resolver outcomes are not openly available for independent replication.
- Regulatory/compliance implications are unaddressed: the legality and governance requirements of autonomous or semi-autonomous trading agents across jurisdictions (e.g., KYC/AML, market-manipulation safeguards) are not analyzed.
- Explainability is absent: there is no interpretability method (e.g., SHAP, feature attributions) for forecasts or sentiment scores to aid auditor trust and error analysis.
- Chain-agnostic ingestion and time alignment need validation: the “shared fabric” claims time alignment and replayability, but no benchmarks show synchronization accuracy across chains, venues, and news streams.
Practical Applications
Overview
Based on the paper’s five-engine architecture (prediction, Bittensor-based verification, sentiment fusion, constitutional agentic execution, and API-risk/scenario programming) and the reported Solana case study plus production telemetry, the following are actionable real-world applications. Each item names sectors, outlines a concrete workflow or product, and notes assumptions/dependencies that may affect feasibility.
Immediate Applications
These can be deployed now using the paper’s measured or policy-validated components (scenario engine, governance-gated agentic execution, sentiment fusion pipeline, telemetry and calibration harness, orchestration separation).
- Constitutional, governance-gated DAO treasury executor
- Sectors: finance (DeFi, DAOs), software (agent governance), policy/compliance
- What it does: Executes pre-approved, cap-bounded, stop‑loss‑protected treasury actions (e.g., buy-only stabilization, liquidity seeding) under a formal role contract; every cap raise or live flip requires recorded approval; paused-by-default with kill switch.
- Tools/workflows: Paperclip-style task management + LangGraph runtime; JSON‑schema-validated emissions; three-tier fallback (remote → in‑process → legacy); append-only audit logs.
- Assumptions/dependencies: Clear governance process and board sign-off; wallet segregation (no deployer key); reliable on-chain data; operational playbooks; adherence to constitutional constraints by all actors.
- Cross-chain route/bridge health guardrails for wallets and custodians
- Sectors: finance (wallets, custodians), software (wallet plugins), security
- What it does: Monitors route-health scalars and E1–E4 event classes; auto-disables or warns on risky bridges/routes; enforces “killable-uplift” when verification signal quality degrades.
- Tools/workflows: Route Guard plugin using API-risk engine and resolver thresholds; divergence flags when oracles/venues disagree; opt-in user prompts to switch routes.
- Assumptions/dependencies: Multi-source price/liquidity feeds; well-tuned thresholds; transparent failure modes; user UX for escalations; class-imbalance awareness for low base-rate events.
- Liquidity stress-response playbooks for DEX pools and market makers
- Sectors: finance (exchanges/AMMs, MM desks)
- What it does: Deploys deterministic, time‑weighted slice buys (or widening spreads for MMs) during liquidity contractions; bound by daily caps and automatic stop-loss circuits proven in the case study.
- Tools/workflows: Scenario engine with pre-committed programs (if Σ in W with p>τ → execute P within bound B); ratchet tiers; cooldowns; human-in-the-loop escalations.
- Assumptions/dependencies: Venue-specific constraints (AMM vs order book); fee and price impact modeling; replayable evidence store; approval latency compatible with markets.
- Narrative divergence detector for listings/risk teams
- Sectors: finance (exchanges/listings, asset issuers), media analytics
- What it does: Fuses news/social streams with on-chain flows to detect sentiment shocks propagating ahead of chain-state changes; flags divergence for manual review or pre-emptive controls (e.g., fee adjustments).
- Tools/workflows: Late-fusion + stacking sentiment pipeline; provenance tracking; grey-literature adapters (e.g., DexScreener, Pump.fun); alerting dashboards.
- Assumptions/dependencies: Source provenance to mitigate poisoning; coverage breadth for micro-cap universes; periodic re-tuning for concept drift; on-chain wash trading can confound signals.
- Verifiable agent operations for audits and compliance
- Sectors: policy/compliance, software (platforms with agents), finance (regulated algotrading)
- What it does: Enforces separation of agent-task management from runtime; forbids direct LLM HTTP from runtime; requires structured, schema‑validated outputs and immutable audit trails for all agent actions.
- Tools/workflows: Contract layer with role constitutions; runtime emitting {valid|degraded|fallback}; automated rejection of non-conforming emissions.
- Assumptions/dependencies: Organizational willingness to adopt audit-first patterns; integration with existing SIEM/GRC systems; incident playbooks for deviations.
- Risk telemetry and calibration arc dashboards
- Sectors: finance (risk teams), academia (evaluation), software (observability)
- What it does: Continuously reports directional accuracy and Brier scores per cohort; transparently surfaces class imbalance and cohort restrictions; supports model governance and de-biasing.
- Tools/workflows: Scheduled evaluation harness (e.g., Lambda + EventBridge); cohorting; versioned calibration manifests; reproducible CSV snapshots.
- Assumptions/dependencies: Stable resolvers; consistent time alignment; acceptance that 99% directional accuracy on top-cap cohorts is not headline-grade without calibration.
- On-chain incident tabletop exercises and live drills
- Sectors: security (SOC for DeFi), finance (protocol operations)
- What it does: Runs NIST-style tabletop exercises operationalized for on-chain actions; validates stop-loss, caps, escalation, and fallback behavior under scripted scenarios.
- Tools/workflows: Program registry + trigger evaluator; synthetic stressors; red-team/blue-team exercises using the scenario engine.
- Assumptions/dependencies: Safe sandboxes/testnets; clear rollback procedures; telemetry for post-mortems.
- Retail portfolio risk companion (alerting, not auto-execution)
- Sectors: finance (retail wallets/brokers), consumer apps
- What it does: Delivers user-facing warnings on route health, bridge anomalies, and liquidity risk; suggests disabling risky routes or setting personal stop-loss alerts.
- Tools/workflows: Lightweight client using API-risk engine and sentiment divergence; notification settings; explainable rationale snippets.
- Assumptions/dependencies: Conservative defaults to avoid alert fatigue; clarity on non-advisory nature; minimal data collection.
- API-risk scoring and kill-switch for third-party model integrations
- Sectors: software (platform integrators), finance (risk vendors)
- What it does: Scores model APIs feeding production pipelines; enforces “killable-uplift” if variance or latency breaches thresholds, reverting to baseline.
- Tools/workflows: Health monitors; variance gates on validator-loss proxies; safe fallbacks; contract-level SLAs with vendors.
- Assumptions/dependencies: Defined baselines; robust fallbacks; vendor cooperation for observability.
- Open metagraph experiment kit for academic replication
- Sectors: academia (ML, mechanism design), open-source communities
- What it does: Provides testnet-ready validator/miner templates, event resolvers, and analysis notebooks to study three-component validator loss and incentive alignment.
- Tools/workflows: Bittensor testnet deployment scripts; canned datasets; reproducibility harness.
- Assumptions/dependencies: Access to testnet; stable netuid configurations; community governance for stake distribution in experiments.
Long-Term Applications
These require further research, scaling, and/or ecosystem/regulatory maturation (notably the Bittensor verification subnet at production scale and robust LLM‑mediated agentic execution).
- Decentralized, verifiable risk oracle network (Bittensor‑backed)
- Sectors: finance (DeFi protocols, oracles), software (data marketplaces)
- What it does: Provides economically‑incentivized, calibrated feeds of crash probability, route health, and liquidity depth; integrated into AMMs, lending protocols, and insurance.
- Tools/products: “Risk Subnet” with Yuma rewards; on-chain oracle adapters; miner/validator marketplaces.
- Assumptions/dependencies: Diverse miner population; robust validator-loss measurement; Sybil‑resistant stake distribution; governance for resolver thresholds.
- Predictive cross-chain trade and bridge routing
- Sectors: finance (aggregators, wallets, HFT routing)
- What it does: Optimizes routes by forecasting slippage, volatility, and failure risk; pre-commits to alternative routes under scenario triggers.
- Tools/products: Smart order routers augmented by prediction + sentiment surfaces; fallback ladders; SLA-aware execution.
- Assumptions/dependencies: Sufficient forecast lead times; CEX/DEX API reliability; legal clarity for auto-routing decisions.
- Standardized “Role Contract” specification for autonomous agents
- Sectors: software (agent frameworks), policy/compliance, finance (algorithmic ops)
- What it does: Defines interoperable constitutions for agent roles (e.g., Trader, Treasurer, Risk Officer) with machine‑checkable constraints and auditable approvals.
- Tools/products: Open standard akin to EIP/SIP; conformance test suites; registry of vetted constitutions.
- Assumptions/dependencies: Industry and regulator buy‑in; toolchain support across runtimes; formal verification advances.
- Regulatory frameworks for verifiable agentic execution
- Sectors: policy/regulation, finance (brokers/exchanges), critical infrastructure
- What it does: Establishes requirements for paused‑by‑default, audit logs, schema‑validated emissions, and kill‑switches in AI‑driven operational systems.
- Tools/products: Compliance toolkits; certification regimes; supervisory APIs.
- Assumptions/dependencies: Evidence that these controls reduce systemic risk; harmonization across jurisdictions.
- Marketplaces for verifiable multimodal sentiment signals
- Sectors: finance (research vendors), media analytics
- What it does: Opens a market where providers sell sentiment features scored by a public verification subnet; consumers select by calibration performance.
- Tools/products: Sentiment miner SDKs; provenance attestations; buyer dashboards.
- Assumptions/dependencies: Robust anti‑poisoning methods; IP/licensing clarity; standardized evaluation cohorts.
- Autonomous market‑making and treasury rebalancing under constitutional constraints
- Sectors: finance (AMMs, treasuries), software (agent tooling)
- What it does: LLM‑mediated agents propose and execute parameter shifts (fees, inventories) or rebalances, bounded by role contracts and scenario triggers.
- Tools/products: Strategy Alpha with tool use; guardrail libraries; simulation sandboxes.
- Assumptions/dependencies: Verified tool-use reliability; safe exploration methods; human oversight at critical thresholds.
- Safety‑circuit pattern generalized beyond finance
- Sectors: energy (grid ops), healthcare (hospital ops), robotics (industrial automation)
- What it does: Translates stop‑loss and cap‑bounded scenario execution to domains like auto‑shedding loads, reallocating beds, or pausing robot tasks when risk thresholds are breached.
- Tools/products: Domain‑specific resolvers (e.g., load/occupancy thresholds); certified agent constitutions; audit trails.
- Assumptions/dependencies: Domain‑specific safety standards; high‑quality telemetry; rigorous incident testing.
- Cybersecurity SOC automation with bounded containment
- Sectors: security (SOC, MDR), software (IT operations)
- What it does: Uses scenario engine to trigger pre‑committed containment actions (isolation, key rotations) when multimodal risk signals cross thresholds; constitutional rules limit blast radius.
- Tools/products: SIEM/SOAR integrations; reliability bins for confidence; human approval gates for high‑impact steps.
- Assumptions/dependencies: Low false‑positive rates; clear fallback paths; attack-aware sentiment handling.
- Parametric insurance priced by calibrated, verifiable risk feeds
- Sectors: finance (insurance/DeFi cover), actuarial science
- What it does: Issues on‑chain cover that pays out on resolver events (e.g., bridge outage class E3) with premiums adjusted by verified crash probabilities and calibration history.
- Tools/products: Policy smart contracts; risk feed oracles; capital pools with scenario‑aware reinsurance.
- Assumptions/dependencies: Regulatory acceptance; long‑horizon performance data; manipulation‑resistant resolvers.
- Curricula and research testbeds for verifiable agentic systems
- Sectors: academia (CS, econ), education technology
- What it does: Provides students with end‑to‑end labs (ingestion → fusion → prediction → verification → agentic execution) and adversarial challenge rounds on metagraphs.
- Tools/products: Modular courseware; open datasets; evaluators for validator-loss components.
- Assumptions/dependencies: Sustainable open-source maintenance; safe sandboxing of agents.
- Personal “constitutional co‑pilot” for digital asset management
- Sectors: consumer finance, fintech
- What it does: Manages multi-wallet/bridge exposure with pre‑committed, user‑approved playbooks; never exceeds daily caps; pauses on stop‑loss; documents all actions for the user.
- Tools/products: Mobile wallet integration; explainable decisions; optional social proof via public decision logs.
- Assumptions/dependencies: Mature prediction and sentiment accuracy; robust privacy; user education to set constitutions.
- Cross-domain predictive operations centers (“risk OPS”)
- Sectors: energy, logistics, public sector
- What it does: Centralizes ingestion and scenario programming to coordinate bounded, pre‑approved actions across heterogeneous systems (e.g., re‑routing shipments under disruption forecasts).
- Tools/products: Shared intelligence fabric with time alignment; scenario registry; governance gate for multi‑agency approvals.
- Assumptions/dependencies: Inter‑org data sharing; interoperable APIs; funding for continuous verification.
Cross-cutting assumptions and dependencies
- Data and infrastructure: Multi-source ingestion (on-chain, off-chain, market, news), canonical time alignment, replayable evidence stores, and secure identity/access controls are prerequisites across applications.
- Verification and incentives: Production-scale validation of the Bittensor subnet (miner diversity, validator-loss robustness, stake distribution) is needed before relying on decentralized scoring in critical paths.
- Model performance and calibration: Reported class imbalance and cohort restrictions mean directional accuracy cannot be taken at face value; Brier calibration and reliability bins should guide deployment gates.
- Governance and safety: Paused-by-default, human-in-the-loop escalations, kill-switches, and role-bound constitutions are foundational controls that must be institutionalized, not optional.
- Security and reliability: Host compromise and governance bypass remain residual risks; three-tier fallbacks and append-only audit logs mitigate but do not eliminate them.
- Legal and compliance: Auto-execution in financial and critical sectors depends on regulatory acceptance of verifiable agentic systems and clear accountability frameworks.
Glossary
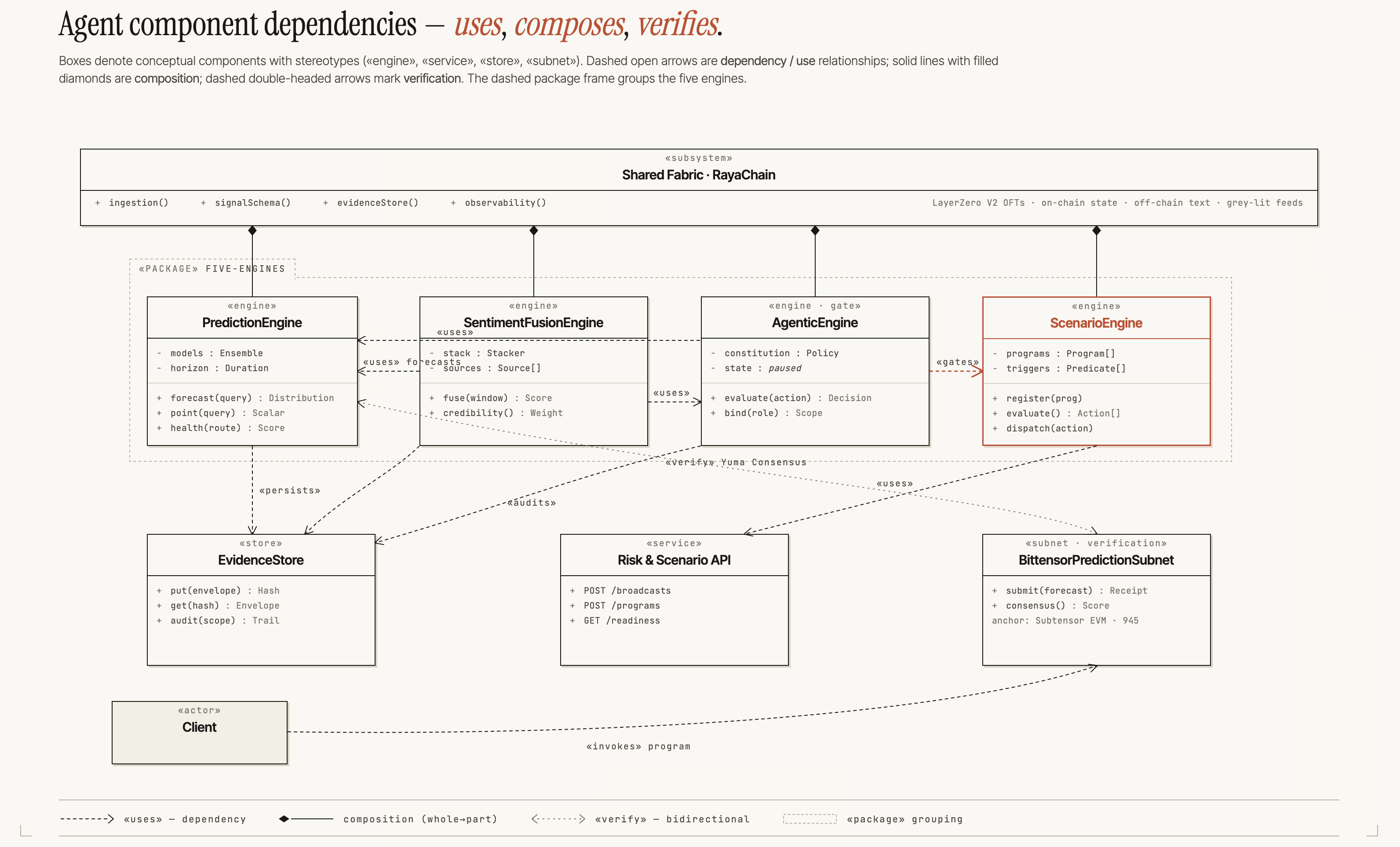
- Agentic engine: An LLM-mediated layer that selects and executes actions under explicit constraints. "The agentic engine is the LLM-mediated decision-and-action layer."
- API-risk and scenario engine: A component that transforms probabilistic forecasts into pre-committed, triggerable action programs with resource bounds. "An API-risk and scenario engine turns predicted scenarios into pre-committed action programs whose triggers and resource bounds are declared in advance."
- Basis points: A unit equal to one hundredth of a percent (0.01%), used to express small rate or price changes. "raised the bottom-tier price by 50 basis points"
- Binned reliability: A calibration technique that groups predictions by confidence bins to compare stated confidence with empirical accuracy. "Confidence calibration is binned reliability over the past paired samples with bin width $0.1$."
- Bittensor verification subnet: A decentralized network layer where miners submit forecasts and validators score them, tying rewards to performance. "A Bittensor verification subnet decentralises the prediction layer and economically scores its outputs against realised cross-chain events"
- Brier score: A proper scoring rule for probabilistic forecasts; the mean squared error between predicted probabilities and outcomes. "A calibration error (the Brier score) penalises both wrong predictions and overconfidence."
- Bridge fragmentation: The diffusion of liquidity and routes across multiple blockchain bridges, increasing complexity and attack surface. "Bridge fragmentation: cross-chain bridges are now both the dominant capital route and the dominant exploit surface"
- Class imbalance: A dataset condition where one class (e.g., “no crash”) dominates, inflating naive accuracy. "Class imbalance. The outcome resolver is bounded to the top 1{,}000 assets by market capitalisation"
- Constant-product pool: An automated market maker where the product of token reserves remains constant, causing larger trades to move the price more. "Raydium constant-product pool (the product of the two reserve quantities is held constant by the pricing function, so larger trades move the price more)"
- Constitutional AI: An approach where an AI follows an explicit set of written principles that constrain its actions. "in the sense of Anthropic's constitutional-AI specification"
- Early-fusion: A multimodal learning strategy that concatenates features from different modalities before modeling. "using the early-fusion / late-fusion / stacking taxonomy of the financial-NLP literature"
- Governance gate: A control layer that enforces approvals and pausing around agent actions. "is wrapped by a governance gate (paused on session start + board approval)."
- Grey-literature feeds: Informal or community data sources (e.g., aggregators, dashboards) used alongside news and on-chain data. "grey-literature feeds (Birdeye, DexScreener, Pump.fun for the Solana micro-cap segment)"
- Hanson's logarithmic market-scoring rule: A mechanism that aggregates predictions and incentivizes truthful probability reporting in prediction markets. "Hanson's logarithmic market-scoring rule is the canonical primitive that aggregates self-interested predictors into a calibrated forecast"
- Internet of Value (IoV): A partially trusted, heterogeneous network where digital value moves across chains and systems. "The Internet of Value (IoV) is a heterogeneous, partially-trusted network"
- Killable-uplift property: The architectural capability to disable a subsystem (e.g., the subnet) without collapsing core functionality. "The Bittensor prediction subnet is a killable uplift to the prediction engine."
- LangGraph: A runtime orchestration framework used to structure and execute agent workflows. "names the production orchestration runtime (LangGraph) and the agent-task management surface (Paperclip)."
- Late-fusion: A multimodal strategy that combines outputs from modality-specific models at a higher level. "using the early-fusion / late-fusion / stacking taxonomy of the financial-NLP literature"
- Liquidity fragmentation: Divergent pricing and liquidity for the same logical asset across chains and venues, creating route-specific illiquidity. "Liquidity fragmentation: the same logical asset prices differently across chains and venues, and a route that is liquid in aggregate can be illiquid at the slice that matters"
- Metagraph: The global graph of subnet participants and relationships (e.g., miners, validators) used for coordination and scoring. "measure the loss against a live multi-miner metagraph"
- Monte-Carlo scenario generation: Simulation of many possible future paths to drive scenario-based decision rules. "action programs in the sense of Monte-Carlo scenario generation"
- Narrative contagion: The rapid propagation of sentiment-driven shocks that precede on-chain changes. "Narrative contagion: sentiment shocks propagate at a faster cadence than chain-state changes"
- NIST tabletop-exercise structure: A formal framework for planning and evaluating incident response scenarios, adapted here for on-chain actions. "follows the NIST tabletop-exercise structure adapted to an on-chain execution context"
- Prediction router: A production system that routes, evaluates, and calibrates predictions across cohorts and windows. "the live OmniRisk prediction router"
- Role contract: A formal specification of an agent’s allowed actions and constraints (e.g., buy-only) that must hold during operations. "the role contract held across two stop-loss events"
- Route-health scalars: Quantitative indicators summarizing the robustness and risk of cross-chain routes. "and route-health scalars."
- Sentiment-fusion engine: A module that fuses text, on-chain, and other signals to produce route- or asset-level sentiment. "A sentiment-fusion engine combines off-chain text streams with on-chain flow signals"
- Shared Fabric: The canonical, time-aligned data layer (ingestion bus, schemas, stores) that supplies all engines. "Shared Fabric (the ingestion bus, signal schema, evidence store, feature/entity store, and observability store)"
- Squads multisig: A multi-signature wallet framework on Solana used for secure operational custody. "Squads multisig"
- Stake-weighted majority threshold: A rule that clips outlier validator inputs based on the stake-weighted majority. "clips outliers against a stake-weighted majority threshold"
- Stacking: A meta-learning strategy that learns from the outputs of other models (often after late fusion). "using the early-fusion / late-fusion / stacking taxonomy of the financial-NLP literature"
- Stop-loss circuit: An automated safety mechanism that pauses execution when losses exceed a predefined threshold in a time window. "a stop-loss circuit auto-pauses the engine on a 30\% drop within a 600-second window."
- Time-weighted slicing: Splitting a trade into smaller timed pieces to reduce price impact. "Time-weighted slicing splits a single trade into smaller pieces over a fixed window to reduce price impact."
- Validator-loss decomposition: A formal breakdown of validator scoring into components (e.g., Brier accuracy, inconsistency, calibration). "the validator-loss decomposition is stated formally and is falsifiable."
- Yuma Consensus: Bittensor’s reward-allocation mechanism that pays miners proportional to clipped validator scores. "The Bittensor reward-allocation rule (Yuma Consensus) takes a vector of validator scores per miner, clips outliers against a stake-weighted majority threshold, and pays rewards proportional to the clipped scores."
Collections
Sign up for free to add this paper to one or more collections.

