- The paper introduces an adaptive token budgeting method (TAB) that dynamically allocates per-turn token budgets to optimize compute efficiency in multi-turn LLM reasoning.
- It formulates the budgeting process as a multi-objective MDP optimized using Group Relative Policy Optimization, balancing accuracy and token usage.
- Empirical results demonstrate TAB achieves up to 35% token savings and improved accuracy across benchmarks, even generalizing to out-of-distribution problems.
Adaptive Token Budgeting for Multi-Turn LLM Reasoning: The TAB Method
Problem Motivation and Context
As recent advances in LLMs have led to increased deployment of multi-turn reasoning systems, compute efficiency during inference has become a key bottleneck. Classical methods for improving efficiency focus on test-time compute allocation at the single-turn or entire-instance level, neglecting the temporal dependencies and sequential resource allocation challenges that are unique to multi-turn reasoning. In such settings, inefficient budgeting not only increases costs, but also compounds over turns, inflating the context length and exacerbating serving bottlenecks. The paper "Not All Turns Are Equally Hard: Adaptive Thinking Budgets For Efficient Multi-Turn Reasoning" (2604.05164) systematically addresses these issues by proposing a flexible, learning-based approach for dynamic token allocation in multi-step LLM workflows.
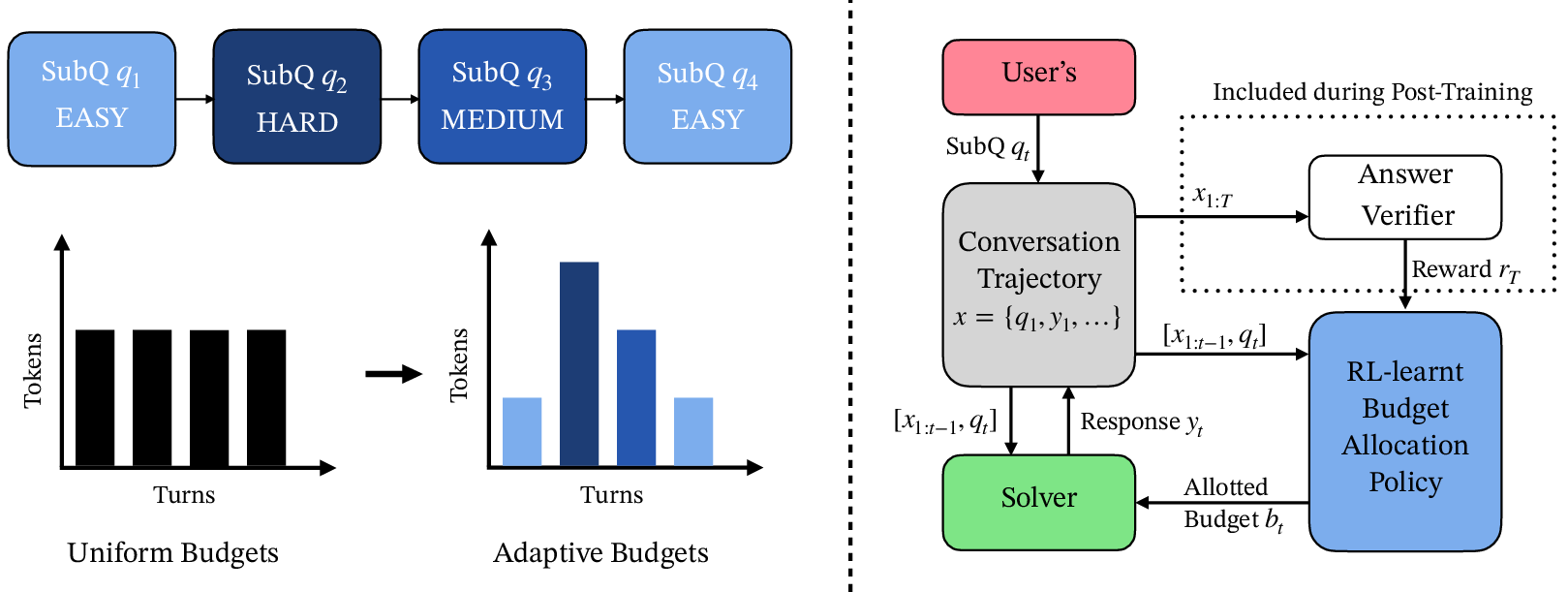
Figure 1: A multi-turn reasoning system where the budgeter allocates per-turn token budgets adaptively, informed by conversation history and sub-question context, leading to efficient compute utilization.
Unlike previous approaches that statically or myopically allocate per-turn budgets, this work models multi-turn compute allocation as a sequential decision-making problem, formalized as a multi-objective Markov Decision Process (MDP). The state encompasses the conversation trajectory and upcoming sub-question; the action is the selection of a discrete token budget for the current turn. The MDP objective targets maximizing expected final task accuracy, regularized by a soft penalty for violating a problem-wide token budget. The scalarization:
π⋆=argπmaxE[acc(x)−λ⋅max(0,t=1∑Tbt−B)]
where λ controls the accuracy-efficiency tradeoff.
Crucially, this sequential framing handles three core challenges: (1) temporal dependency—early budget decisions constrain future compute; (2) delayed feedback—correctness is verifiable only at the trajectory's end, yielding difficult credit assignment; (3) nontrivial multi-objective optimization over entire reasoning episodes.
The TAB Algorithm: Turn-Adaptive Budgets via GRPO
The proposed Turn-Adaptive Budgets (TAB) method involves a budget allocation policy LLM (the "Budgeter") trained with Group Relative Policy Optimization (GRPO). At each turn, the Budgeter observes the conversation trajectory and the next sub-question, then outputs a budget from a discrete set. The RL reward is a convex combination of final solution accuracy and token budget adherence. Using GRPO over standard PPO avoids value function learning, which is especially brittle in the long-horizon, sparse-reward multi-turn regime.
The training setup involves three specialized LLMs: a "User" LLM generates plausible sub-questions from MATH benchmark instances, the "Budgeter" proposes per-turn budgets, and a length-controlled "Solver" LLM produces the responses, constrained to allocated budgets.
Experimental Results
Strong Accuracy-Tokens Tradeoff
Empirical evaluation across MATH-500, AMC23, OlympiadBench, Math Level-5, and AIME25 demonstrates that RL-trained TAB policies consistently yield superior accuracy-tokens Pareto frontiers relative to static and LLM-Judge baselines. TAB achieves up to 35% total token savings without accuracy degradation. Notably, at moderate global token budgets (B=5k), TAB matches or exceeds baseline accuracy (e.g., 4.4pp higher) while using 40% fewer tokens.
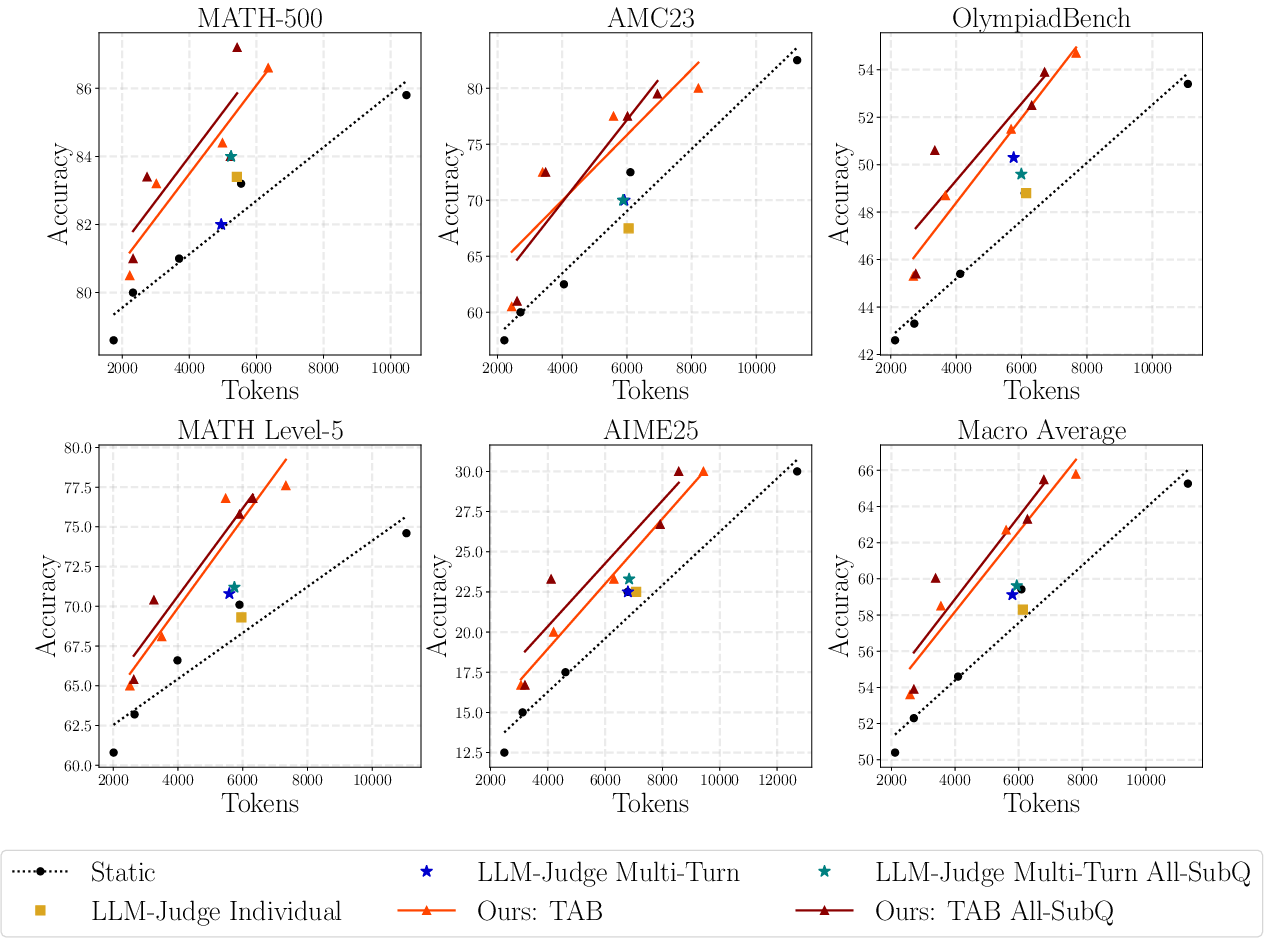
Figure 2: RL-trained TAB achieves significant token savings at parity or better accuracy compared to static and context-unaware LLM baseline allocation methods.
TAB's adaptive policy learns to allocate sparse tokens to routine (easy) steps and concentrate token budgets on steps empirically associated with high reasoning complexity or "crucial" advances in the solution trace. Static and myopic LLM-Judge policies, in contrast, tend to over-allocate uniformly, often saturating high-compute buckets and causing ineffective downstream allocation.
Multi-Turn Planning and Anticipation
A key extension, TAB All-SubQ, operates in settings where the full sequence of sub-questions is available a priori. By conditioning on all sub-questions (both past and future), the budgeter achieves up to 40% savings over baselines, and a further 12% reduction versus standard TAB, corroborating the hypothesis that multi-turn reasoning is fundamentally a planning and anticipation problem.
Robustness and Model Scaling
TAB demonstrates robust generalization to out-of-distribution problems, including TheoremQA, BIG-Bench Extra Hard, and GPQA benchmarks, despite being trained on MATH. The improved accuracy-tokens tradeoff persists in these harder and structurally distinct domains (Figure 3).
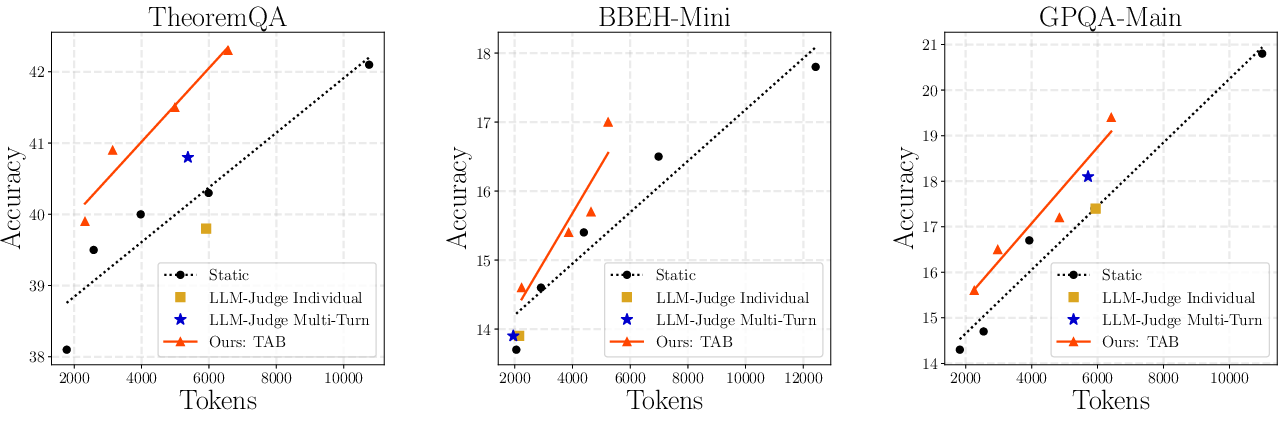
Figure 3: TAB outperforms baselines on out-of-distribution datasets, providing enhanced accuracy vs. compute even for theorem and algorithmic reasoning.
Scaling the budgeter model capacity from Qwen3-1.7B to Qwen3-4B results in an additional performance gain, indicating that richer trajectory interpretation and implicit difficulty estimation are facilitated by larger policies (Figure 4).
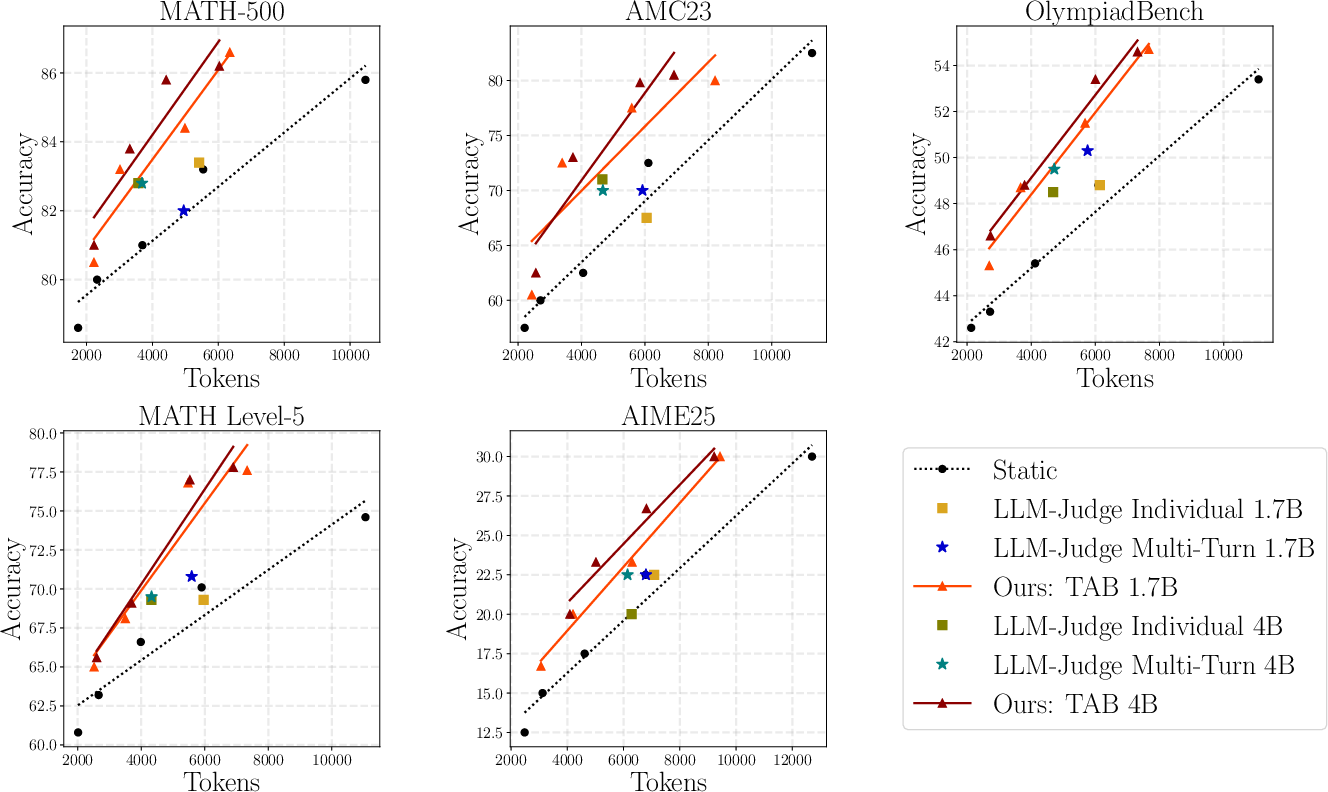
Figure 4: The Qwen3-4B Budgeter surpasses the 1.7B variant, supporting the trend that greater LLM budgets yield stronger allocation policies.
Theoretical and Practical Implications
The TAB framework demonstrates that dynamic, history-aware token budgeting significantly improves compute efficiency in LLM-powered multi-turn systems. This has direct operational implications for production LLM deployments—higher throughput, lower serving costs, and improved utilization under constrained latency and quota.
Theoretically, the results support recasting multi-turn LLM orchestration as a sequential, temporally extended resource planning problem, emphasizing the need for anticipation and credit assignment. The methodology (scalarized multi-objective RL with GRPO) generalizes to richer reward formulations, non-verifiable objectives, and agentic setups with external tools or actions.
Future Directions
Relevant research avenues include: (1) joint end-to-end optimization of planning, solving, and budgeting modules via hierarchical or meta-RL; (2) extending to non-verifiable or subjective supervision (e.g., human preferences, multi-agent interaction); (3) integrating richer credit assignment and delayed feedback mechanisms; (4) application to large-scale tool orchestration and persistent agent settings; and (5) generalization to open-ended dialogue and mixed-initiative multi-turn workflows.
Conclusion
The study rigorously demonstrates that efficient multi-turn reasoning with LLMs necessitates sequential, adaptive compute allocation rather than one-shot or context-insensitive methods. TAB and its extensions achieve substantial improvements in accuracy-token efficiency by leveraging trajectory-aware allocation policies trained via multi-objective RL. These results establish multi-turn token budgeting as critical for scaling LLM systems to longer horizons, more complex interaction patterns, and resource-constrained environments.

