- The paper introduces TrACE, a training-free adaptive compute controller that adjusts LLM calls per timestep based on inter-rollout action agreement.
- Experiments reveal compute cost reductions of 33% to 65% compared to fixed-budget approaches while maintaining similar accuracy on GSM8K and MiniHouse benchmarks.
- TrACE uses consensus among candidate actions as a proxy for decision uncertainty, optimizing resource allocation for both simple and complex steps.
Inter-Rollout Action Agreement as a Free Adaptive-Compute Signal for LLM Agents
Introduction and Motivation
The paper introduces TrACE (Trajectorical Adaptive Compute via agrEement), a training-free, per-timestep adaptive compute controller for LLM-based agents operating in sequential decision-making settings (2604.08369). The core problem addressed is the uniform allocation of inference compute in deployed LLM agents—each timestep in a multi-step reasoning or acting pipeline typically receives an identical compute budget (e.g., a fixed number of samples), irrespective of variance in decision difficulty. This practice results in inefficient compute use, with trivial steps overprovisioned and complex decisions starved of needed exploration.
TrACE leverages inter-rollout action agreement as a proxy for agent uncertainty. The method adaptively increases or decreases the number of LLM calls at each timestep by measuring the empirical consistency in sampled next actions: high consistency signals that a step is easy and can be decided immediately; low consistency triggers additional samples, up to a maximum, before committing to an action. Crucially, TrACE is training-free and requires no labeled data, external verifiers, or modifications to the LLM itself.
Method: TrACE Adaptive Compute Controller
TrACE employs a stepwise algorithm for allocating compute budget:
- At each decision step: Draw a small set of candidate next actions by independently sampling the model at a specified temperature.
- Agreement computation: Measure the proportion of samples agreeing (modulo canonicalization) on an action, denoted as αt.
- Threshold decision:
- If αt exceeds a tunable threshold τhigh, commit to the plurality action immediately.
- Otherwise, iteratively sample more candidates (up to a cap kmax) and repeat the agreement check, finally committing to the mode action.
This approach contrasts with fixed-k self-consistency (SC-k), which applies the same number of samples per decision and does not exploit stepwise uncertainty. The default setting uses kinit=2, kmax∈{4,8}, and τhigh=0.75.
This empirical behavioral agreement (distinct from the LLM's self-reported confidence) is repeatedly validated as a robust signal for step-level correctness, outperforming naïve or token-level uncertainty metrics and offering a compelling operational tradeoff between compute cost and reliability.
Empirical Results
Experiments were conducted using a quantized Qwen 2.5 3B Instruct model on CPU across two benchmarks: GSM8K (single-step grade-school math) and MiniHouse (custom multi-step household navigation).
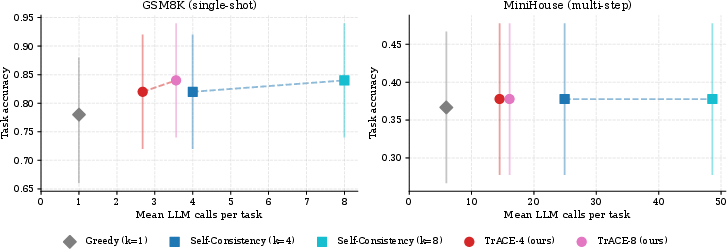
Figure 1: TrACE-4 and TrACE-8 match the accuracy of SC-4 and SC-8 while using substantially fewer LLM calls, dominating the self-consistency baseline on the compute–accuracy Pareto frontier.
TrACE demonstrates consistent efficiency improvements:
- GSM8K: TrACE-4 matches SC-4 accuracy ($0.82$) using αt0 calls/task vs. αt1 (33% reduction). TrACE-8 matches SC-8 accuracy (αt2) with αt3 calls/task vs. αt4 (55% reduction).
- MiniHouse: TrACE-4 matches SC-4 accuracy (αt5) with αt6 calls/task vs. αt7 (39% reduction). TrACE-8 matches SC-8 accuracy with αt8 vs. αt9 (65% reduction).
In all cases, TrACE matches the maximum reachable accuracy given the underlying model and task complexity but does so at significantly lower compute cost. Notably, in MiniHouse, increasing inference budget (greedy to SC-τhigh0 to TrACE-τhigh1) yields no accuracy improvement due to the model’s intrinsic weaknesses, but TrACE still provides meaningful efficiency gains.
Analysis of Agreement as a Success Signal
A core hypothesis is that inter-rollout agreement encodes genuine decision confidence. Higher observed agreement correlates with steps situated in ultimately successful task trajectories, as demonstrated empirically (see left of Figure 2). Distributional analysis of LLM call counts reveals TrACE’s adaptivity: most steps exit at low sample counts (easy steps), with high sample counts reserved for genuinely ambiguous states (right of Figure 2).
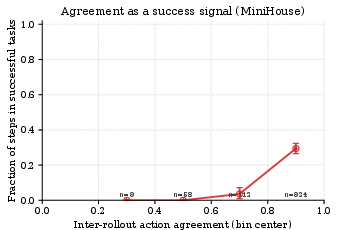
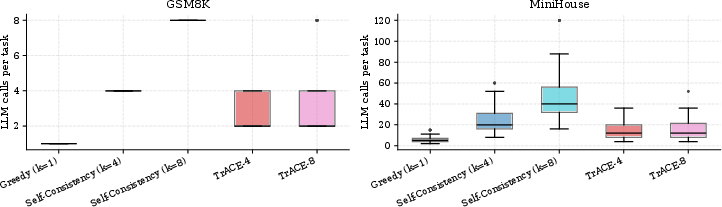
Figure 2: Left: High stepwise agreement reliably predicts task-level success. Right: TrACE adaptively concentrates compute on more challenging steps, reflected in the non-uniform call distribution.
Ablation on Agreement Threshold
The agreement threshold (τhigh2) criticality was explored via ablation. Lowering the threshold (τhigh3) leads to greater efficiency but slightly reduced accuracy, as steps may terminate early before consensus. Raising to unanimity (τhigh4) degenerates to standard SC-τhigh5 performance and cost. The default (τhigh6) maintains Pareto-optimality, trading minimal or no accuracy for large compute reductions.
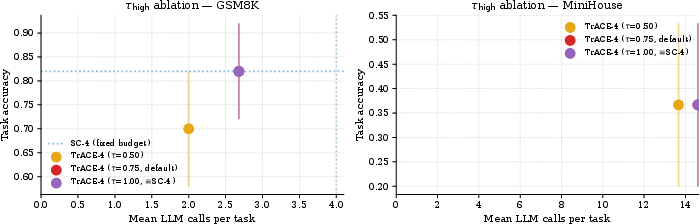
Figure 3: Tuning τhigh7 explores the tradeoff between call count and accuracy; TrACE at τhigh8 yields strong efficiency while preserving the accuracy of SC-4.
Practical and Theoretical Implications
TrACE offers a robust, training-free improvement to LLM agent deployment: it Pareto-dominates fixed-budget baselines in practical compute-constrained environments. This feature is especially pertinent as the community increasingly deploys open-weight models, where retraining or fine-tuning with reward models is often infeasible. The explicit demonstration that output agreement encodes actionable uncertainty information elevates the discussion of calibration in sequential LLM control, showing that behavioral variance is a more reliable signal than LLM self-report.
Nevertheless, limitations are acknowledged: experiments were run on a single small model on two benchmarks with relatively constrained action spaces; absolute accuracy is capped by model limitations. TrACE’s core advantage—relative compute efficiency at fixed accuracy—remains to be validated at larger scale and in more open-ended domains (e.g., code generation, complex planning).
Future Directions
Key avenues include extending TrACE to large models and domains with open-ended outputs, more systematic calibration of τhigh9, and—critically—composing behavioral agreement with complementary signals such as perturbation consistency (SPECTRA) under a meta-controller (COMPASS) for further reliability gains.
Conclusion
TrACE establishes inter-rollout action agreement as a principled, training-free signal for stepwise adaptive compute control in LLM agents. It matches the accuracy of fixed-budget self-consistency baselines at dramatically reduced inference cost and demonstrates that LLM behavioral agreement is a robust proxy for decision difficulty. Its deployment requires no additional learning or supervision, making it valuable for practical agents and suggesting a wider role for training-free signal exploitation in reliable AI systems (2604.08369).

