- The paper demonstrates that reasoning-specialized retrievers achieve superior accuracy and lower latency compared to general LLM-based dense models.
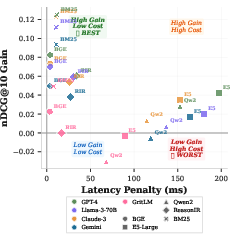
- The paper finds that reasoning augmentation offers significant gains for lightweight models while incurring excessive latency in larger LLM setups.
- The paper reveals trade-offs between peak performance, robustness against query perturbations, and poor calibration across retriever architectures.
Are LLM-Based Retrievers Worth Their Cost? An Empirical Evaluation of Efficiency, Robustness, and Reasoning Overhead
Introduction
This paper presents an exhaustive empirical analysis of LLM-based retrievers in reasoning-intensive information retrieval, moving beyond isolated effectiveness metrics by incorporating cost, efficiency, robustness, and calibration perspectives. The study uses the BRIGHT benchmark, covering 12 diverse tasks that require reasoning and non-trivial compositional capabilities, and systematically profiles 14 retrieval models, including classical sparse lexical models (BM25), dense bi-encoders, instruction-tuned LLM retrievers, and reasoning-specialized architectures. The core research thrust evaluates if the gains in retrieval accuracy from LLM-based retrievers justify their substantial computational and deployment overhead, a critical question for practitioners in reasoning-oriented retrieval augmented generation systems.
Reproducibility and Effectiveness Analysis
The authors reproduce the BRIGHT benchmark's results for various state-of-the-art sparse and dense retrievers, confirming the stability of model rankings across tasks. Reasoning-specialized retrievers, notably Diver, RaDeR, and ReasonIR, exhibit a dominance in effectiveness: Diver achieves 29.4 nDCG@10, outperforming the best LLM-based dense model (GTE-Qwen2 at 23.3) and the best sub-1B model (SBERT at 14.9). Consistency with the original BRIGHT baseline is tight, validating the benchmark.
However, these effectiveness margins obscure profound disparities in computational cost. Indexing throughput ranges from 7,950 docs/sec (BM25) to only 13–68 docs/sec for LLM-based dense and reasoning-specialized retrievers, with the slowest models (E5-Mistral/SFR-Mistral, GTE-Qwen/Qwen2) lagging by over 600× compared to BM25. This indexing efficiency gap establishes an important practical constraint, particularly in dynamic environments where frequent re-indexing or adaptation is needed.
Query-Time Efficiency: Throughput, Latency, and Pareto Frontier
A detailed profiling of query latency and throughput reveals pronounced differences in real-time query processing cost:
- Sub-1B dense bi-encoders (SBERT, BGE, Contriever, etc.) achieve 59–95 QPS (mean 12–22 ms), with negligible tail latency. BM25 maintains high, stable throughput on CPU.
- LLM-based dense retrievers (7B models such as GTE-Qwen, GTE-Qwen2, E5-Mistral) plummet to 5–6 QPS (mean 209–240 ms, p99 > 800ms), rendering them infeasible for latency-sensitive applications.
- Reasoning-specialized approaches (Diver, ReasonIR, RaDeR) demonstrate a superior efficiency/effectiveness curve, e.g., Diver delivers 47.3 QPS at 27.6 ms query time, Pareto-dominating larger LLM baselines both in accuracy and throughput.
This is visualized in the nDCG@10 vs. QPS Pareto frontier: all LLM-based dense models are universally dominated by reasoning-specialized alternatives, refuting the claim that mere scale brings commensurate practical benefit.
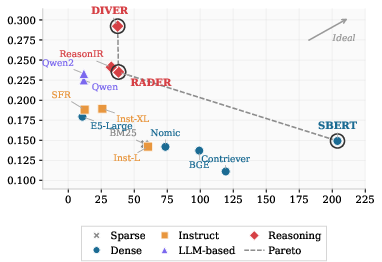
Figure 1: Pareto frontier of nDCG@10 and QPS, indicating that reasoning-specialized retrievers dominate LLM-based dense models in both throughput and effectiveness.
Reasoning Augmentation: Gains, Overheads, and Domain Sensitivity
The BRIGHT setting introduces chain-of-thought (CoT) reasoning-augmented queries using various LLMs (GPT-4, Llama-3-70B, Claude-3, Gemini, GritLM). For weak baselines (BM25, Contriever), reasoning augmentation may yield up to +12.5 nDCG@10 (BM25 with GPT-4) at negligible latency, making it a practically free benefit. However, the utility and cost structure is highly model-dependent:
Domain-wise, argumentation provides the largest improvements for science and community Q&A tasks (Biology, Earth Science, Psychology), but degrades performance on code/math (AoPS, LeetCode), where queries are already precise. This indicates that reasoning augmentation should not be uniformly applied: task-aware gating and query classification are necessary to avoid performance regressions where verbose augmentation injects noise.
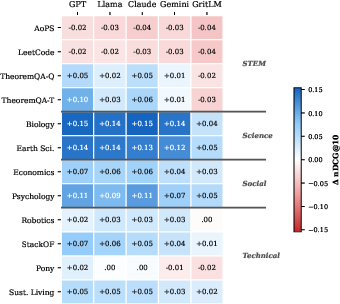
Figure 3: Task-level effectiveness gain from reasoning-augmented queries; science and social Q&A tasks benefit, while formal code/math tasks degrade.
Context Length and Robustness: Impact on Retrieval
Long-context capability dramatically improves retrieval on tasks for which relevant evidence spans multiple paragraphs. Models with context windows ≥4K tokens (E5-Mistral, GTE-Qwen, Diver) see nDCG@10 increases of ~28–30 points upon transitioning to full-document (non-chunked) input, far exceeding the gains in short-context settings. Smaller-context models benefit only marginally, demonstrating that context size is a major limiting factor for IR effectiveness when working with long-form or web-scale content.
On robustness, lexical and adversarial perturbation exposes meaningful fragility in the most effective reasoning-specialized retrievers. E.g., ReasonIR's nDCG@10 drops by >20% under synonym-based or adversarial token perturbation, whereas large-scale bi-encoders (GTE-Qwen2) and smaller denses (BGE) are more stable, sometimes even improving. This points to hidden trade-offs between peak task accuracy and real-world resilience to noisy or rephrased queries.
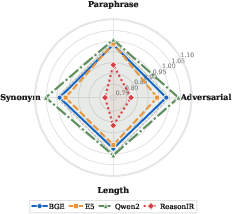
Figure 4: Robustness to query perturbation, as measured by nDCG@10 retention ratio. High-performing reasoning models show significant degradation under perturbation.
Hybrid Fusion and Confidence Calibration
Fusion of BM25 with mid-tier dense retrievers via linear interpolation delivers additive effectiveness improvements (up to +4.8 nDCG@10), rivaling or exceeding reasoning augmentation without inference overhead. However, for top-tier retrievers, fusion harms effectiveness, likely due to lexical-semantic conflict. The optimal strategy is to enable fusion only for retrievers below a certain effectiveness threshold.
Raw retrieval confidence scores (top-1 document similarity) exhibit poor calibration for all retrievers, with AUROC clustering near 0.60, barely above random. Neither scale nor architectural specialization delivers reliable query-level confidence for downstream RAG routing. This indicates that robust calibration or confidence modeling remains an unsolved problem in neural IR, limiting automated downstream deployment without additional mechanisms.
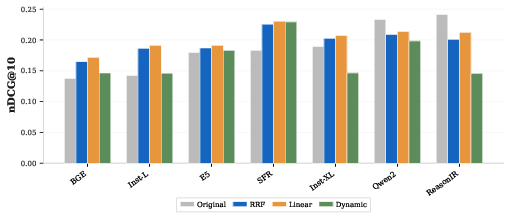
Figure 5: Comparative effectiveness of hybrid retrieval fusion (BM25 + dense retriever) strategies across model families.
Theoretical and Practical Implications
The results substantiate several fundamental claims:
- Architectural specialization outstrips scale: Reasoning-specialized retrievers (Diver et al.) Pareto-dominate much larger general-purpose LLM bi-encoders (e.g., GTE-Qwen2/E5-Mistral), achieving higher accuracy and lower real-time latency.
- Reasoning augmentation is conditionally beneficial: The trade-off is model- and domain-sensitive, often free for lightweight models but costly and marginal for large models and formal tasks.
- Robustness cannot be inferred from effectiveness alone: Top-performing models are not necessarily robust to naturalistic query variation, which may threaten reliability in practical deployment.
- Calibration is universally weak: No model provides reliably discriminative confidence signals from raw similarity scores, suggesting a critical gap for further research prior to scalable downstream adoption.
Looking forward, model selection for production IR pipelines should prioritize architectural optimization and task-awareness over indiscriminately scaling parameter count or applying LLM-generated reasoning augmentation. Future work should focus on robustifying reasoning-specialized models to probabilistic and lexical perturbations and developing methods for genuine retrieval confidence calibration.
Conclusion
This study sets a new standard for empirical evaluation of neural retrievers by incorporating multi-dimensional cost-accuracy-latency-robustness-calibration analysis. LLM-based retrievers, in their current form, rarely justify their computational overhead in deployment for reasoning-intensive tasks when compared to targeted, efficient, and robust reasoning-specialized models. The release of unified evaluation code and analysis artifacts underpins reproducibility and transparency, and the findings offer tailored recommendations for retriever selection, query augmentation policy, and robust IR deployment. Further research into effective calibration and robustness of retriever confidence will be required to close the gap for fully autonomous retrieval-augmented LLM systems.