- The paper presents a multi-stage IR pipeline that enhances query expansion using LLMs and synthetic data to improve reasoning-intensive retrieval.
- It systematically preprocesses documents with semantic rechunking and refines queries to support abstract reasoning and multi-step inference.
- The experimental results on the BRIGHT benchmark showcase state-of-the-art nDCG@10 scores, underlining the model's efficacy in complex retrieval tasks.
Introduction
"DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval" presents an information retrieval (IR) framework designed to address the challenges inherent in reasoning-intensive tasks. Traditional retrieval models often falter when queries necessitate abstract reasoning, analogical thinking, or multi-step inference, as they typically rely on direct lexical or semantic matching. DIVER proposes a comprehensive pipeline that systematically enhances both query and document processing to better handle these complex scenarios.
DIVER Pipeline and Model
DIVER is structured into four key components aimed at improving retrieval accuracy for complex queries:
- Document Preprocessing: The initial stage focuses on augmenting document readability by removing noise and re-segmenting lengthy documents. Instead of truncating documents exceeding the encoder token limit, DIVER rechunks content into semantically coherent parts, enhancing retrieval input quality.
- Query Expansion: Leveraging LLMs, the DIVER-QExpand module iteratively refines user queries by incorporating explicit reasoning chains extracted from retrieved evidence. This process fosters diverse interpretations of queries, thereby enriching the retrieval context.
- Reasoning-Enhanced Retrieval: In contrast with models typically trained on fact-based queries, DIVER trains its retriever using synthetic data that span multiple domains, including medical and mathematical fields. This approach incorporates hard negatives to build a model fine-tuned for complex reasoning tasks.
- Hybrid Reranking: Using both pointwise and listwise strategies, DIVER-Rerank assigns document helpfulness scores through an LLM, enabling more nuanced and context-aware document ordering. Pointwise scores focus on individual document evaluation, while listwise scores assess overall order consistency.
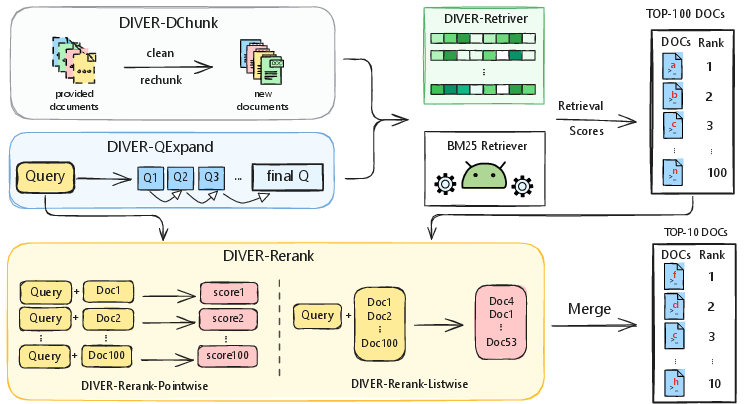
Figure 1: Overview of DIVER pipeline. The DIVER pipeline begins with document cleaning and semantic-based rechunking to improve textual coherence.
Experimental Setup and Results
The BRIGHT benchmark, which emphasizes reasoning-intensive IR scenarios across diverse domains such as economics, psychology, mathematics, and programming, serves as the primary evaluation platform for DIVER. The model achieves state-of-the-art normalized Discounted Cumulative Gain at the 10th position (nDCG@10) scores of 45.8 overall and 28.9 on original queries. These results substantiate the efficacy of DIVER's strategies compared to prior models focused on similar IR challenges.
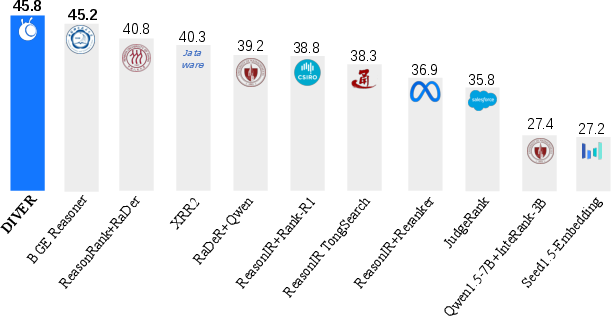
Figure 2: DIVER achieves state-of-the-art performance on BRIGHT benchmark.
The experimental evaluation also includes comparisons with competitive retrieval models utilizing various query expansion and reranking methods. DIVER consistently surpasses these models, highlighted by significant gains in retrieval performance metrics. This is primarily attributed to DIVER's iterative query refinement and reasoning-oriented retriever trained on high-quality synthetic data.
Implementation Considerations
DIVER's reliance on LLMs for query expansion and reranking necessitates computational overhead, primarily due to interactive query evaluations and complex reasoning requirements. However, the use of synthetic datasets in model training allows for robust performance in reasoning-intensive tasks, providing a balanced trade-off between computational cost and retrieval accuracy.
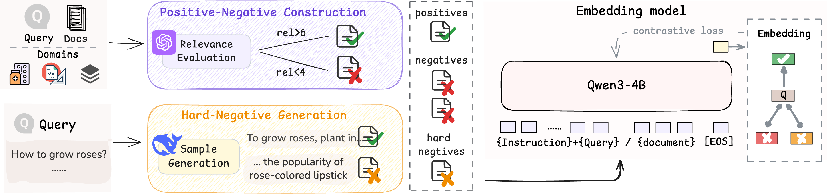
Figure 3: The training process of DIVER-Retriever efficiently integrates reasoning-centric fine-tuning.
Conclusion
DIVER represents a sophisticated blend of retrieval and reranking strategies tailored to the nuanced requirements of reasoning-intensive information retrieval tasks. Its incorporation of advanced query expansion techniques, combined with reasoning-adapted retrievers and a robust reranking framework, establishes DIVER as a leading approach in this domain. Future research could focus on integrating these components into a unified model to optimize system efficiency and potentially reduce latency. This evolution would support broader applicability in real-time information retrieval systems.