- The paper introduces PSR, a novel activation steering approach that leverages token-specific coefficients to replicate prompt steering effects.
- It demonstrates that using learned, context-sensitive interventions significantly improves trait alignment and coherence over traditional constant steering methods.
- Empirical evaluations across benchmarks show that PSR, especially its all-layer variant, achieves lower RMSE and superior behavioral control compared to baseline methods.
Activation Steering Aligned with Prompt Mechanics: "Steer Like the LLM"
Overview
The paper "Steer Like the LLM: Activation Steering that Mimics Prompting" (2605.03907) introduces a novel activation steering framework—Prompt Steering Replacement (PSR)—designed to more faithfully reproduce the effects of prompt-based steering in LLMs. Traditionally, activation steering operates through simple, scalar interventions that are agnostic to token position, typically applying a fixed direction with a uniform strength across all tokens. This work empirically demonstrates that such approaches are not faithful to the token- and position-specific influence observed with prompt steering. The authors propose PSR models that leverage token-specific steering coefficients estimated directly from activations, thereby closely imitating how LLMs are actually influenced via prompting.
Motivation: Bridging Activation and Prompt Steering
Prompting, which leverages tailored instructions or demonstrations in-context, remains the most flexible and effective mechanism for guiding LLM outputs. However, prompting is susceptible to injection attacks and not universally applicable for all types of behavioral control, and finetuning is resource-intensive and may degrade previously-aligned constraints. Activation steering, involving direct intervention in activations (additions along certain directions), offers a lightweight, interpretable mechanism and has the potential to be more robust to adversarial manipulation.
Nevertheless, prior work finds that activation steering lags substantially behind prompt-based steering in both efficacy and side effect mitigation [wu_axbench_2025]. A key insight of this paper is that the simplistic, constant interventions used in existing activation steering do not match the complex, localized interventions invoked by actual prompt-based mechanisms.
Prompt Steering as Activation Steering
The authors theoretically ground their approach by demonstrating that prompt steering can be formalized as a form of activation steering, but with token-specific magnitudes and possibly direction variations across positions and layers.
The core analytical result shows that prompt-based steering does not resemble the constant vector additions of standard activation steering—prompting typically applies highly localized, strong interventions on particular tokens, which vary greatly positionally (Figure 1).
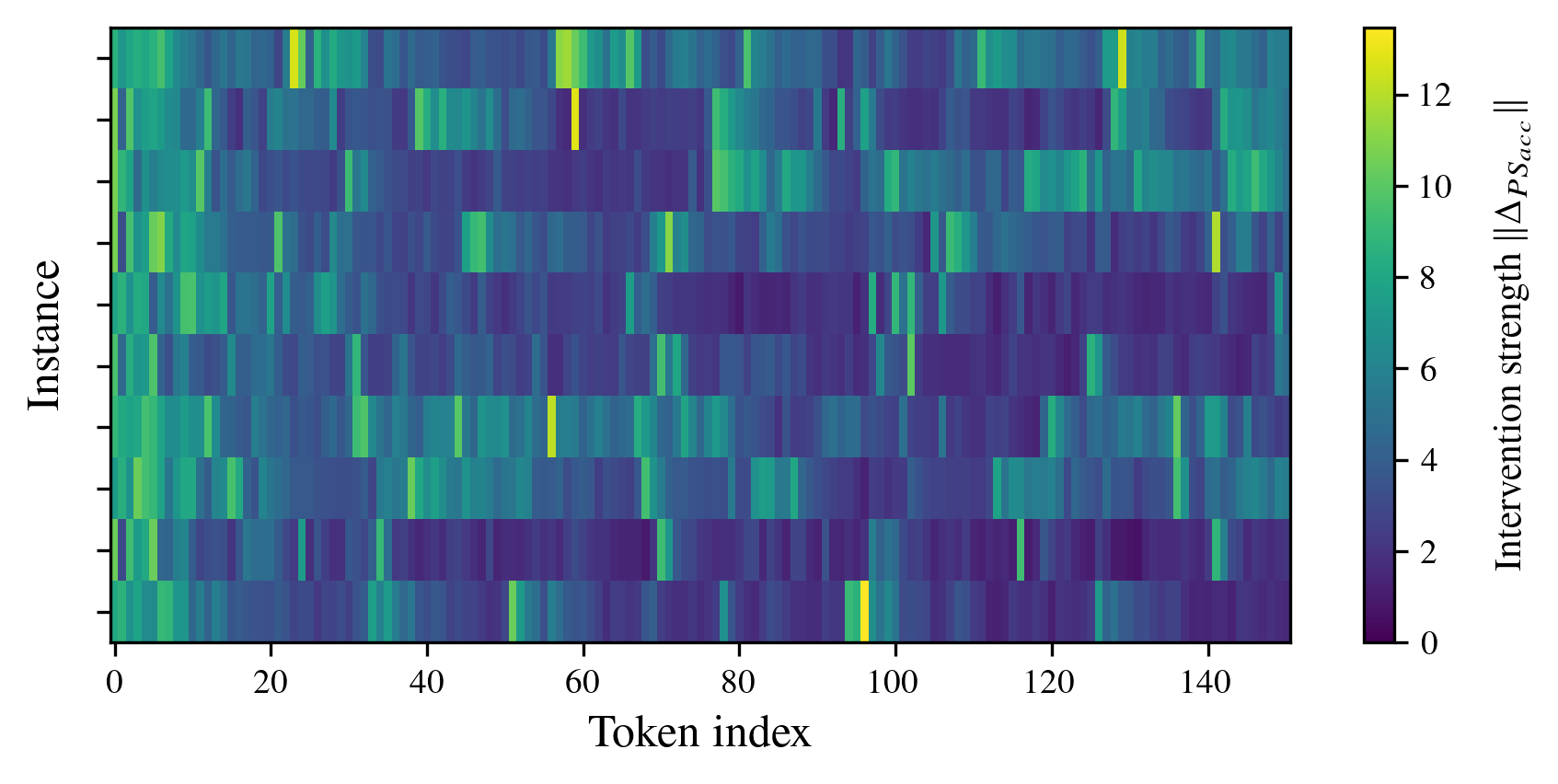
Figure 1: Prompt steering interventions display strong, localized variations in intervention strength across token positions for Llama-3.2-3B when steered toward sycophantic behavior.
This observation is quantitatively validated: prompt steering’s intervention norm fluctuates across tokens, contrasting prior assumptions of uniform steering. This is modeled both as an accumulated intervention across the stack of layers, and as a localized perturbation within specific layers (Figure 2).
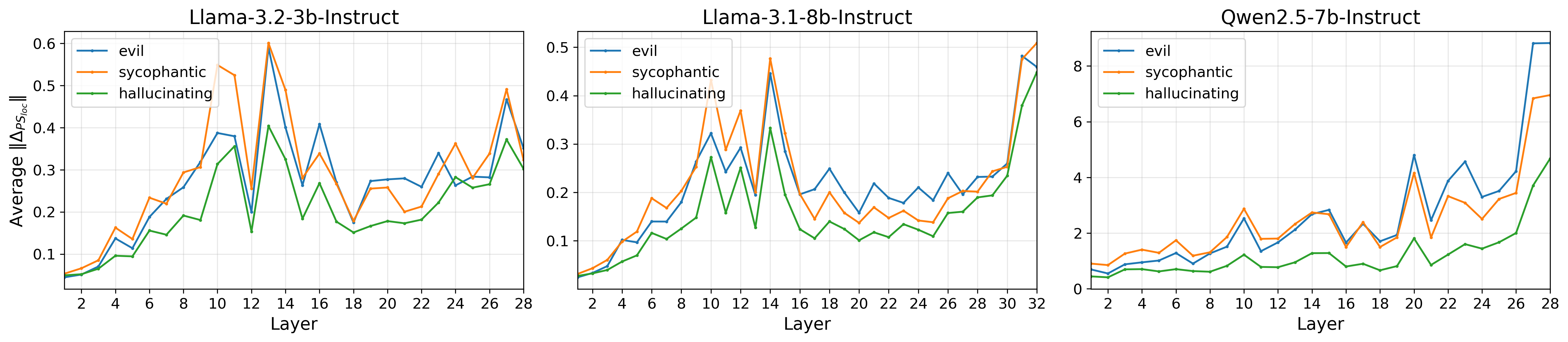
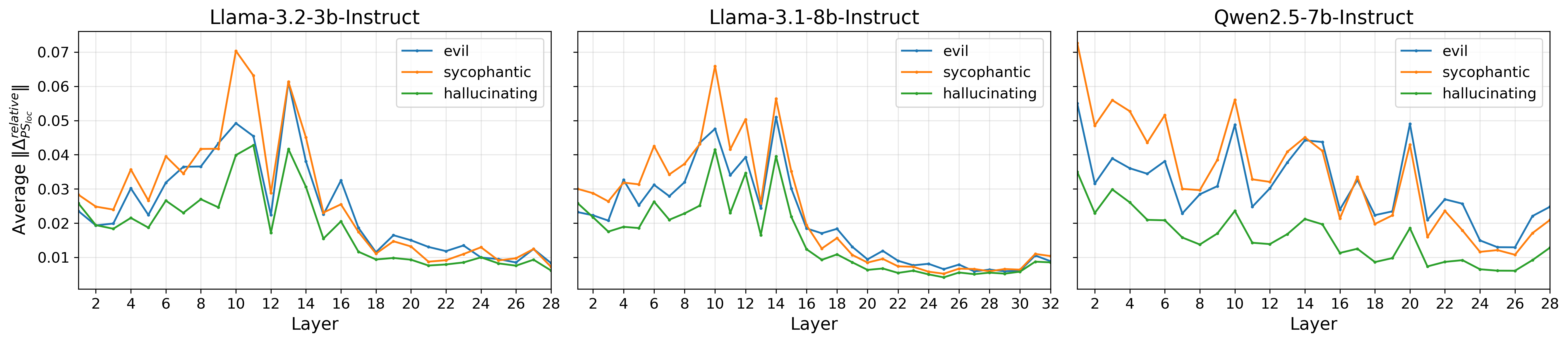
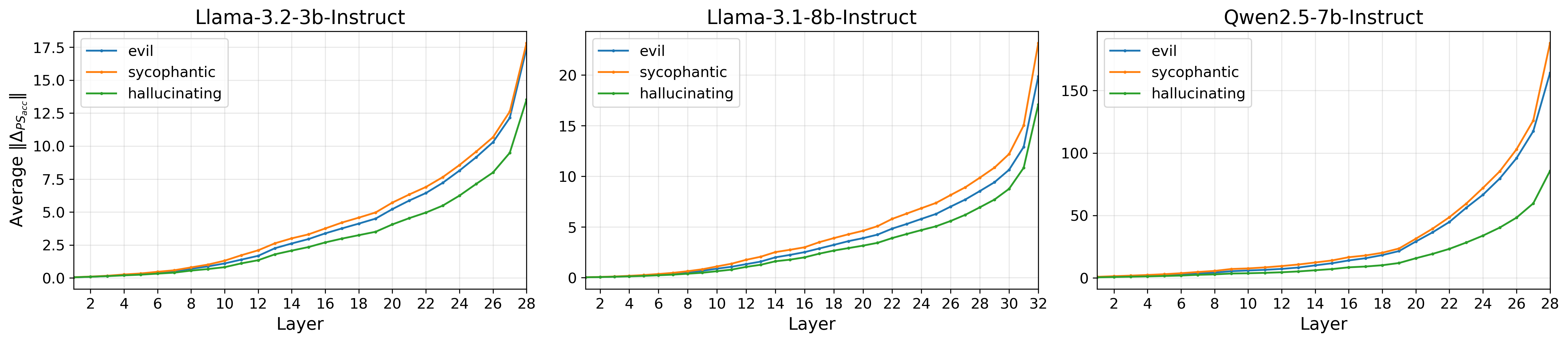
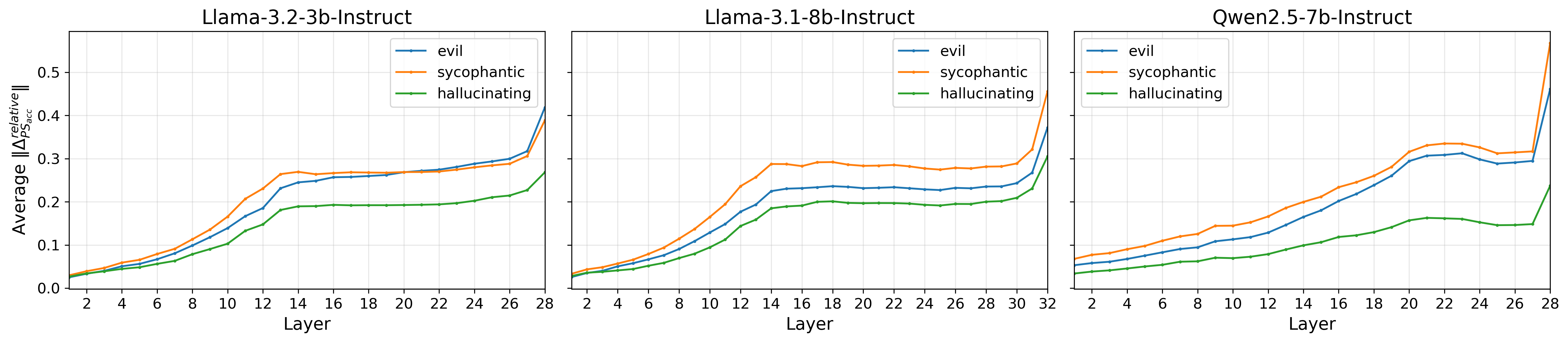
Figure 2: The local magnitude of prompt steering interventions ∥ΔPSloc∥ shows non-uniform, often sparse patterns across tokens, contrasting with uniform constant steering.
Prompt Steering Replacement (PSR) Architectures
Design
The Prompt Steering Replacement (PSR) approach replaces constant scalar steering coefficients with a learned, token-specific steering function:
Al,yisteered=Al,yi+α⋅λ(Al,yi;θ)⋅zattr
Here, λ is a probe (e.g., a single-layer perceptron with ReLU) trained to predict the appropriate steering strength from each token’s activation. zattr is the canonical direction associated with the target attribute. This framework generalizes prior work to allow context-sensitive interventions, bridging the mechanistic gap with prompt steering.
Variants
- S-PSR: Single-layer PSR, intervening at a specific layer.
- A-PSR: All-layer PSR, recursively intervening at each layer with jointly trained parameters.
Training Objectives
- MSE Matching: Parameters are trained by minimizing mean squared error (MSE) between steered activations produced by prompt steering and those by the PSR.
- Loglikelihood Maximization: Alternatively, parameters are tuned to maximize the loglikelihood of target outputs, given steered activations.
Empirical Analysis
The PSR models are evaluated on three benchmarks focused on attribute steering:
- Persona Vectors: Trait-based generation (e.g., sycophancy, evilness) [chen_persona_2025].
- IFEval: Instruction-following.
- AxBench: Diverse concept intervention [wu_axbench_2025].
Steering effectiveness is measured both for attribute alignment at specified coherence thresholds and faithfulness of interventions (RMSE alignment to prompt steering's intervention).
Trait Alignment and Coherence
On Persona Vectors, S-PSR and especially A-PSR consistently outperform conventional constant methods, with A-PSRMSE achieving stronger trait alignment at matched coherence than prompt steering itself (Figure 3, Figure 4).
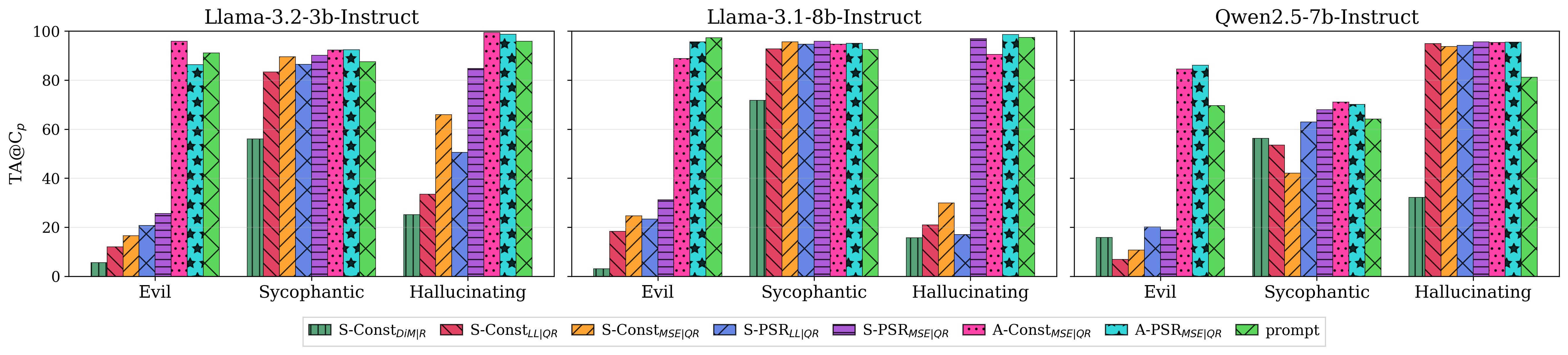
Figure 3: Trait alignment across multiple traits for three LLMs at prompt steering coherence, showing A-PSRMSE surpassing prompt steering's efficacy.
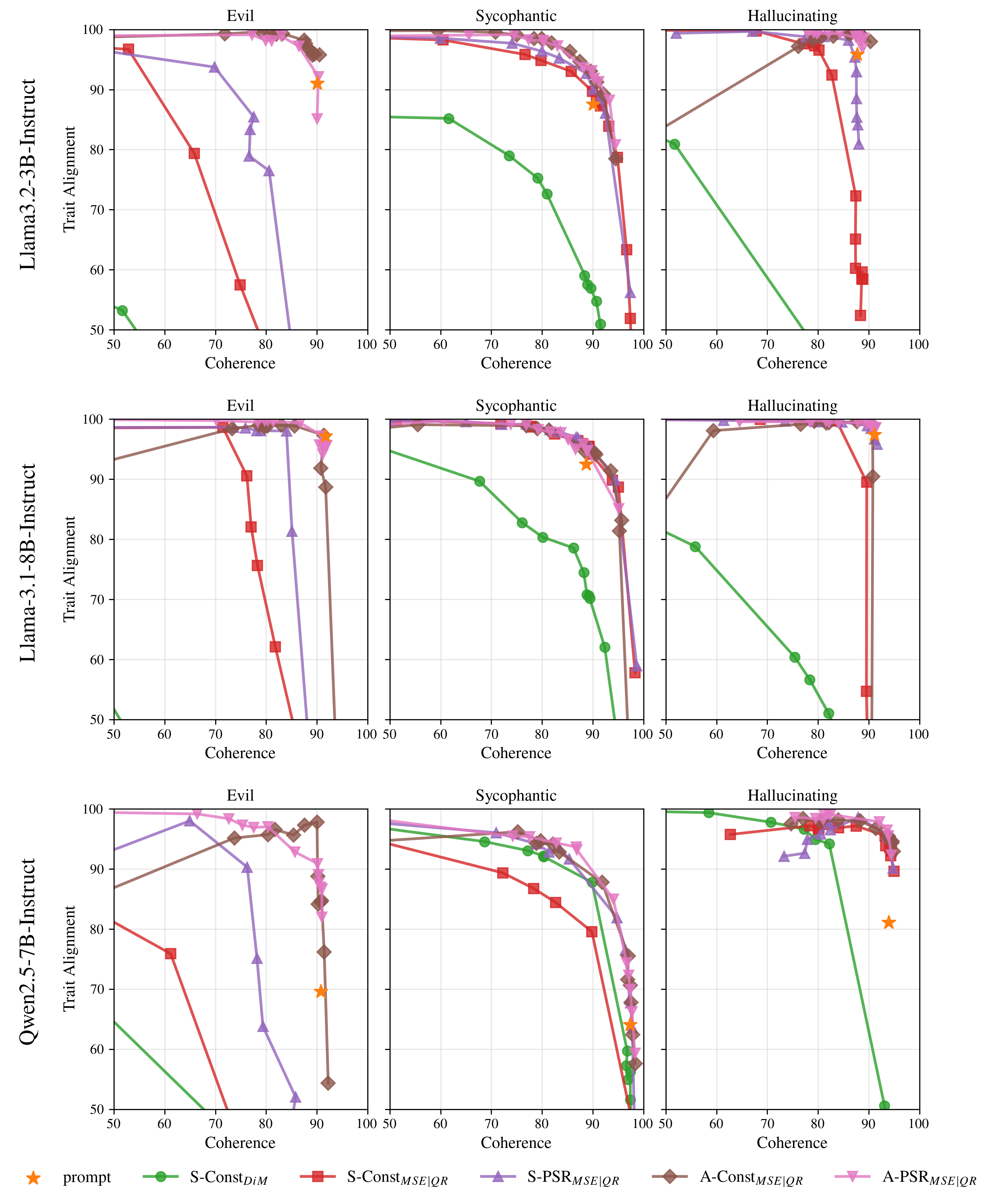
Figure 4: Trait alignment-coherence curves highlight superior tradeoffs for PSR and all-layer variants, and exhibit oversteering in constant baselines with high α.
On AxBench, A-PSR models yield new state-of-the-art steering scores, eclipsing both prompt and advanced activation steering baselines. For IFEval, PSR models close much of the gap with prompt steering, although some complex, argument-dependent instructions expose limitations of the rank-1 PSR assumption.
Faithfulness to Prompt Steering
Relative RMSE analyses reveal that A-PSRMSE produces activations closer to prompt steering than any prior method (Figure 5).
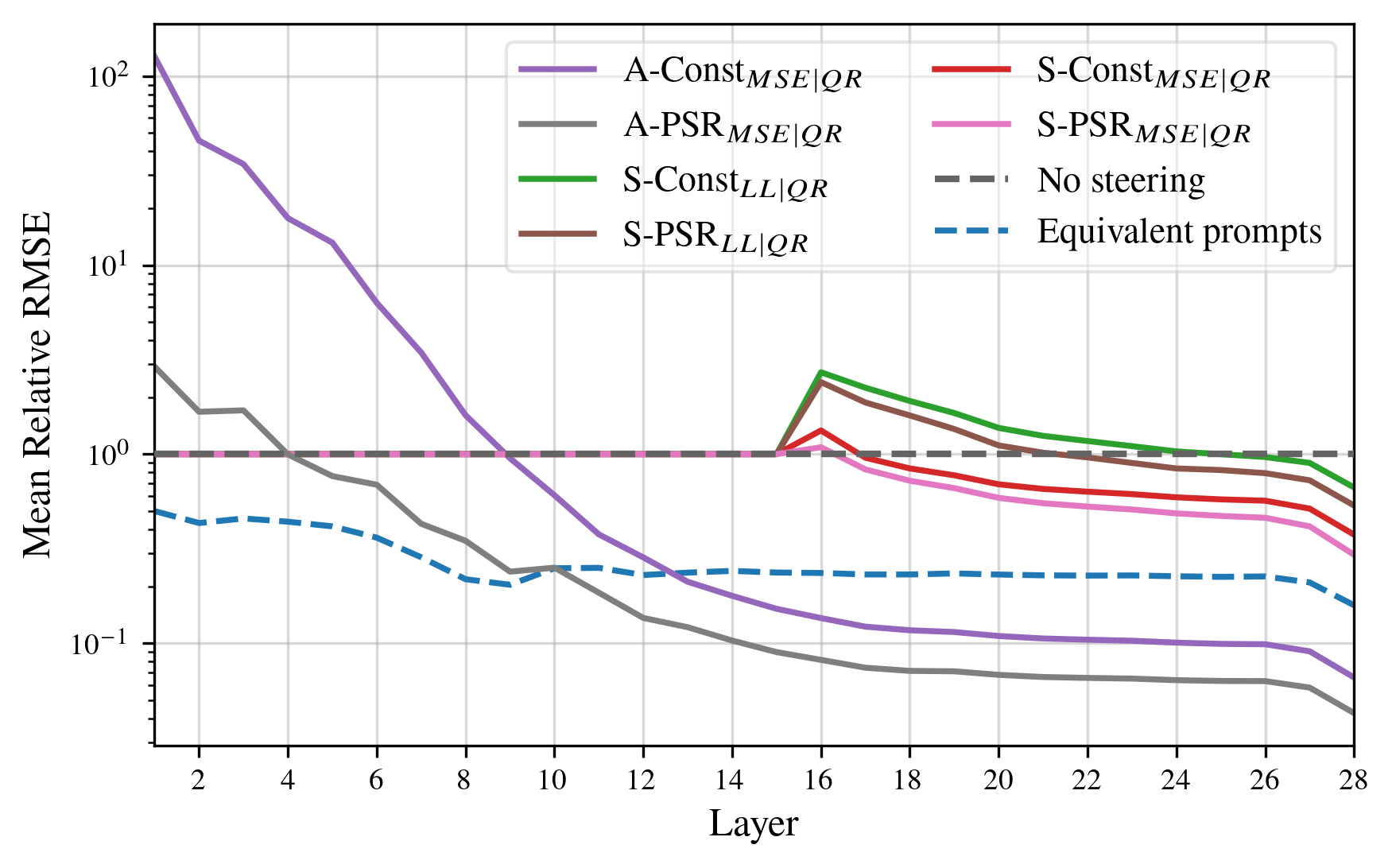
Figure 5: PSR interventions achieve lower relative RMSE to prompt-steered activations compared to previous activation steering methods in all layers (lower is better).
This indicates that PSR not only matches behavioral outcomes but also operates via similar mechanistic pathways. Notably, even some constant intervention methods compensate for their infidelity in early layers by the model's subsequent layers partially reverting to standard behavior.
Mechanistic Interpretability and Implications
By aligning activation editing interventions with the empirical mechanics of prompt steering, PSR facilitates more interpretable and granular control over LLMs. This enables the construction of supervision strategies and safety constraints that are lightweight, robust to input manipulation, and mechanistically decomposable. Furthermore, analysis of intervention patterns reveals that prompt steering effects are sparse and highly context-dependent (see Figure 2 and Figure 6), countering prior linearity assumptions commonly invoked in mechanistic interpretability.


Figure 6: Token-level heatmaps emphasize the contextually localized nature of genuine prompt steering interventions across different traits.
Importantly, the rank-1 PSR formulation—i.e., aligning along a single attribute direction per layer—successfully replicates prompt-based steering for a wide array of attributes but fails on complex, multi-argument tasks. Future architectural generalizations toward low-rank/tensorized interventions or compositional multi-attribute steering (see [nguyen_multi-attribute_2025]) are likely necessary to expand coverage.
Limitations and Future Directions
While PSR closes much of the performance and faithfulness gap for numerous steering tasks, key limitations remain:
- Rank-1 Limitation: Single-direction interventions do not capture all prompt-based effects where the target attribute is not linearly represented (e.g., multi-argument or deeply compositional instructions).
- Transient Oversteering: High global coefficients α can induce oversteering, signaling an active trade-off between control precision and coherence (Figure 4).
Areas for future research include joint optimization across multiple, possibly orthogonal, attribute directions, compositional steering for competing/conditional attributes, and learning more expressive, contextual intervention functions (beyond shallow probes).
Conclusion
This work demonstrates empirically and mechanistically that direct, context-sensitive activation steering can faithfully match—and sometimes surpass—the behavioral control offered by prompt-based interventions, provided that steering functions are designed to emulate the actual, token-specific intervention mechanics adopted implicitly by LLMs during prompt following. The PSR framework establishes a new foundation for robust, interpretable behavioral alignment, removing key limitations of traditional activation editing. Its insights are directly relevant for both practical deployment (robust, real-time behavior alignment) and theoretical understanding of LLM internal representations.
References
- "Steer Like the LLM: Activation Steering that Mimics Prompting" (2605.03907)
- "AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders" [wu_axbench_2025]
- "Persona Vectors: Monitoring and Controlling Character Traits in LLMs" [chen_persona_2025]
- "Multi-Attribute Steering of LLMs via Targeted Intervention" [nguyen_multi-attribute_2025]
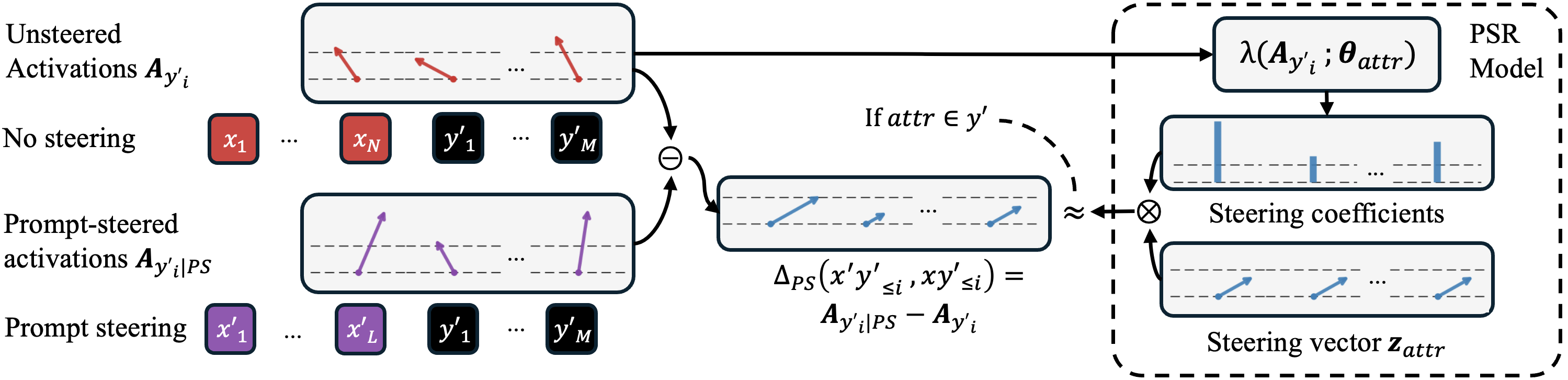
Figure 7: Schematic illustrating prompt steering interventions as the difference between prompt-steered and unsteered activations, with PSR learning to estimate these interventions only for successful prompt steering instances.