RLDX-1 Technical Report
Abstract: While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-LLMs, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, long-term memory, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including data synthesis for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RLDX-1, a new “robot brain” that can see the world (vision), understand instructions (language), and decide what to do next (action). It’s designed to help robots use their hands in skilled, human-like ways in the real world—like picking up moving objects, remembering where things were hidden, or gently inserting a plug without seeing it perfectly.
What questions does it try to answer?
In simple terms, the researchers asked:
- How can we make a robot not just smart about images and words, but also good at using its hands in tricky, real-life situations?
- How can a robot handle moving scenes (like a conveyor belt), remember what happened earlier in a task, and “feel” with touch and force sensors?
- How can we train such a robot using a mix of real, in-house, and AI-generated practice data, and make it fast enough to control a real robot in real time?
How did the researchers approach it?
They built RLDX-1 with four main pieces working together: a new model design, a data pipeline, a training plan, and speed-ups for real-time use.
The robot “brain”: seeing, understanding, and acting
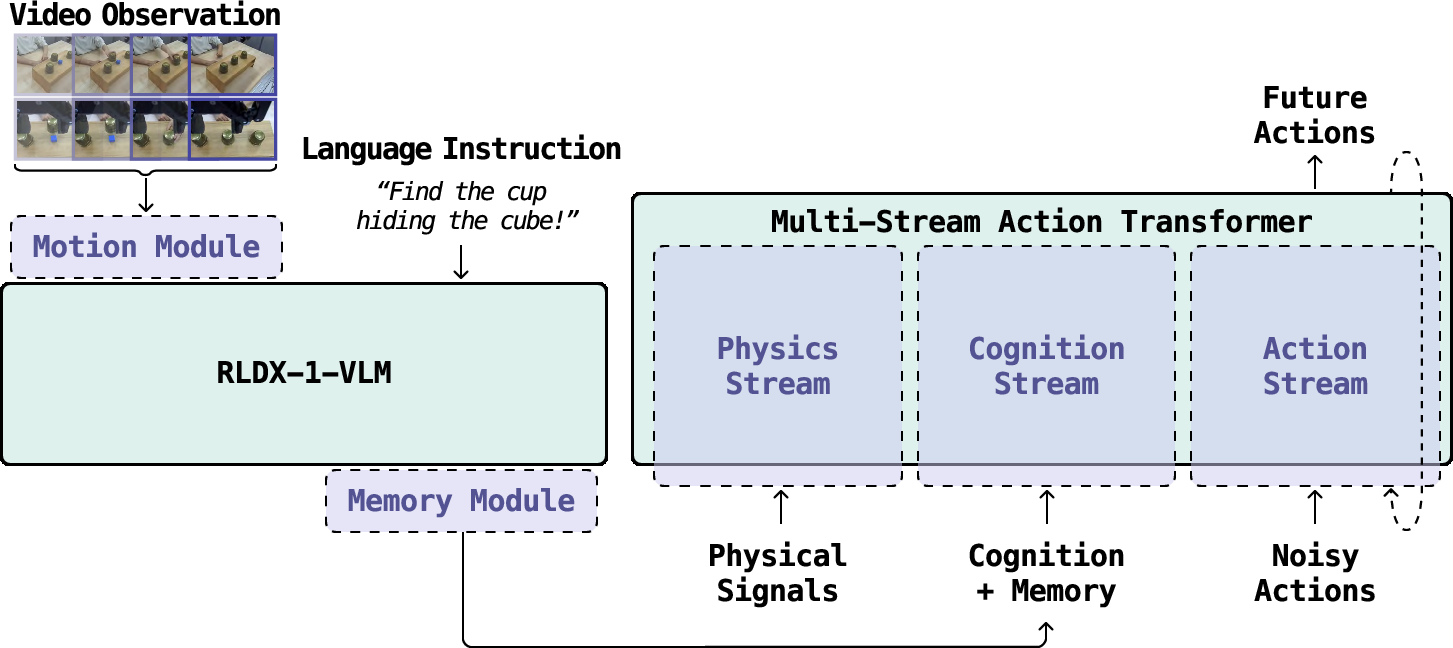
- Vision-Language-Action model (VLA): Think of this as a brain that takes in a short video (not just a single picture) and a written instruction like “put the red block in the box,” then chooses the robot’s next moves.
- Three added abilities:
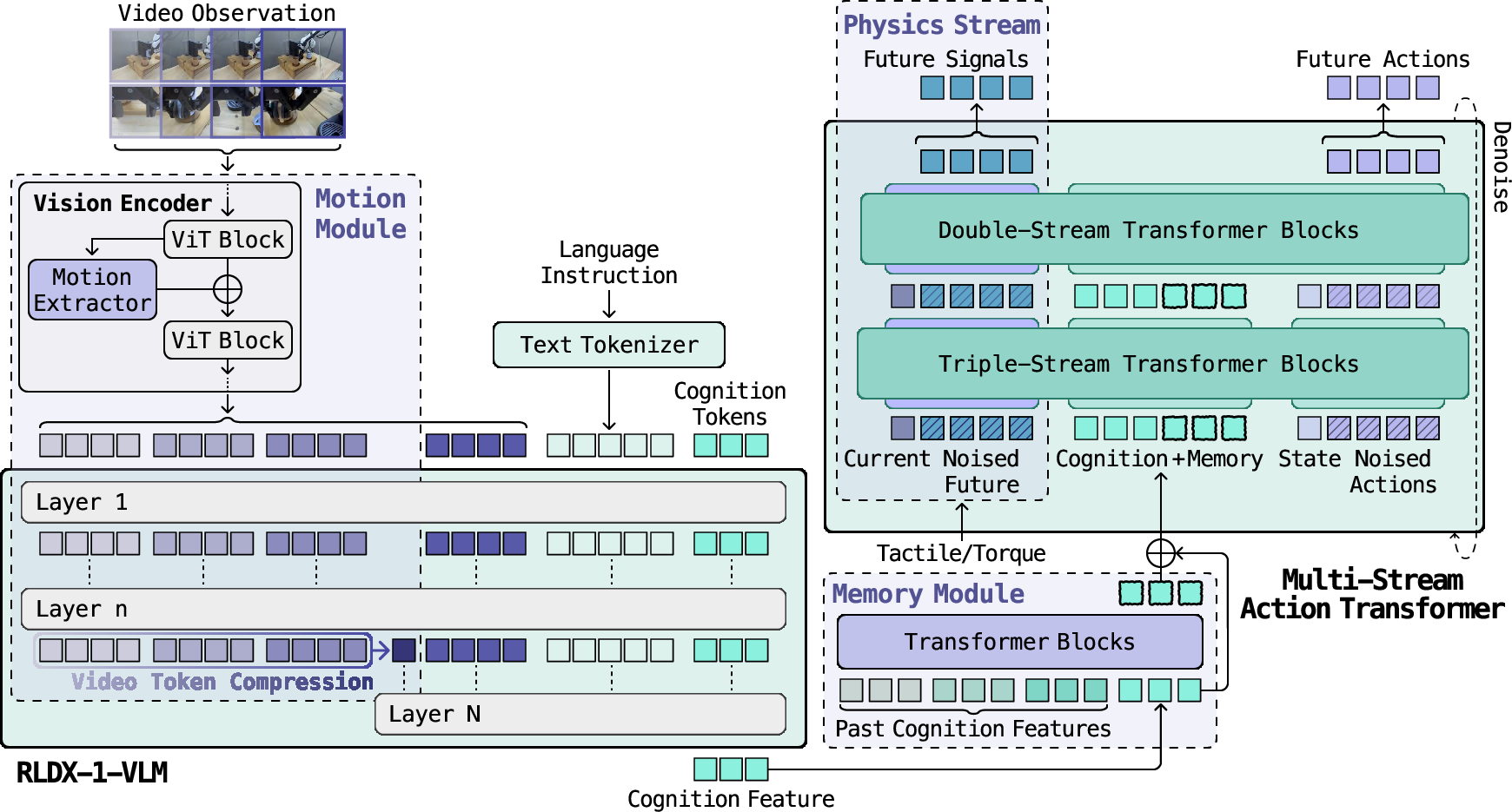
- Motion awareness: It watches short video clips, not snapshots, so it understands movement—like a catcher tracking a fast baseball.
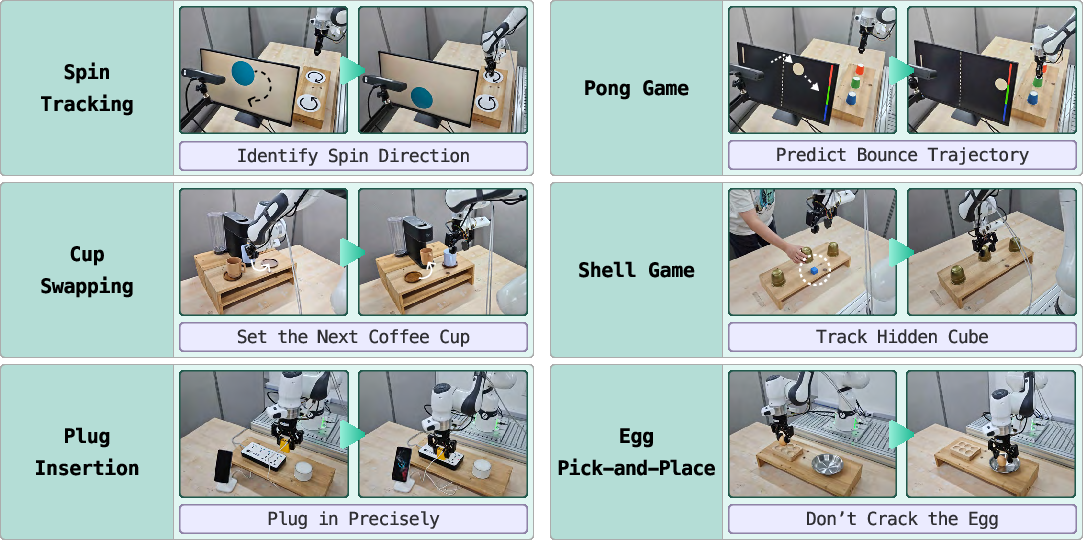
- Long-term memory: It remembers important things that happened earlier—like the “shell game,” where you have to remember which cup hides the ball.
- Physical sensing: It uses “touch” and “muscle effort” signals (tactile and torque) so it can feel forces and gentle contacts that the camera can’t see well.
To combine all these signals, they designed the Multi-Stream Action Transformer (MSAT). Imagine different “lanes” for different inputs (vision-language “cognition,” robot state, and physical sensors). Each lane keeps its own style of information but they still talk to each other, so the final action uses everything that matters.
The action generator uses a “cleaning up noise” idea: it starts from a rough, noisy guess of future robot motions and gradually refines it into a clean, safe plan. You can think of it like unblurring a noisy photo step by step, but for actions.
Training data: lots of practice from many sources
To make the robot skilled and general, they used three kinds of data:
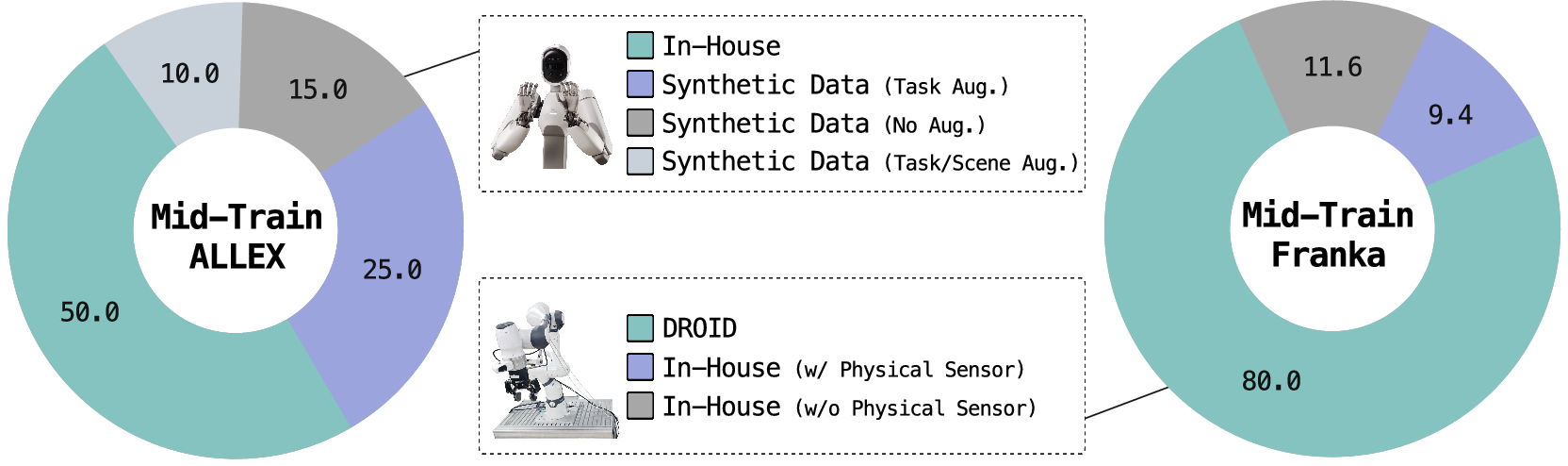
- Public real-robot datasets: Over a million demonstrations from many robot types (single arms, two arms, and humanoids).
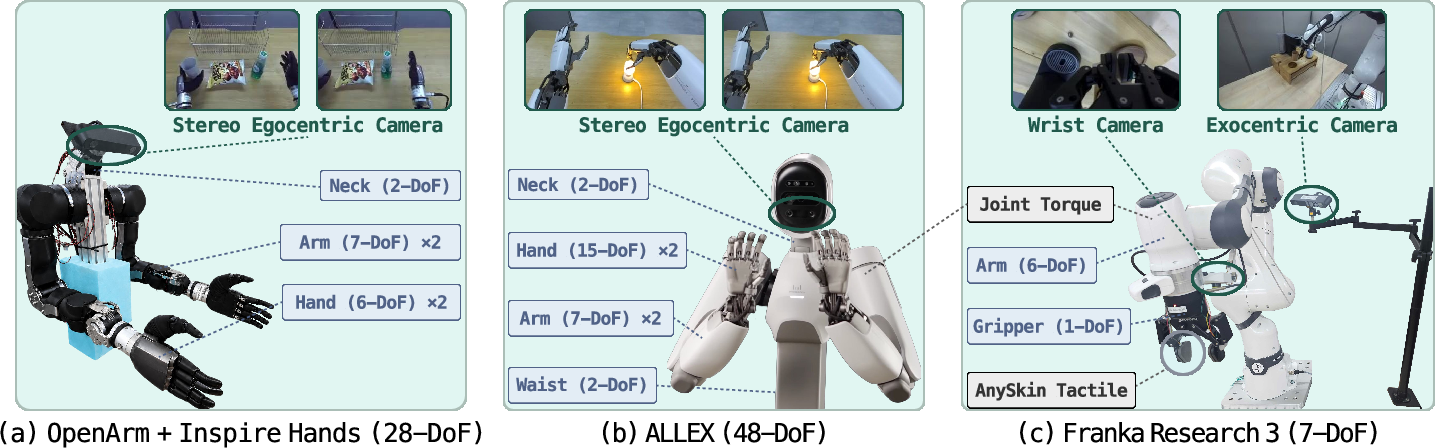
- In-house data: They recorded new demonstrations on two platforms:
- A Franka arm (FR3) upgraded with touch sensors.
- ALLEX, a humanoid robot with dexterous hands and torque sensing.
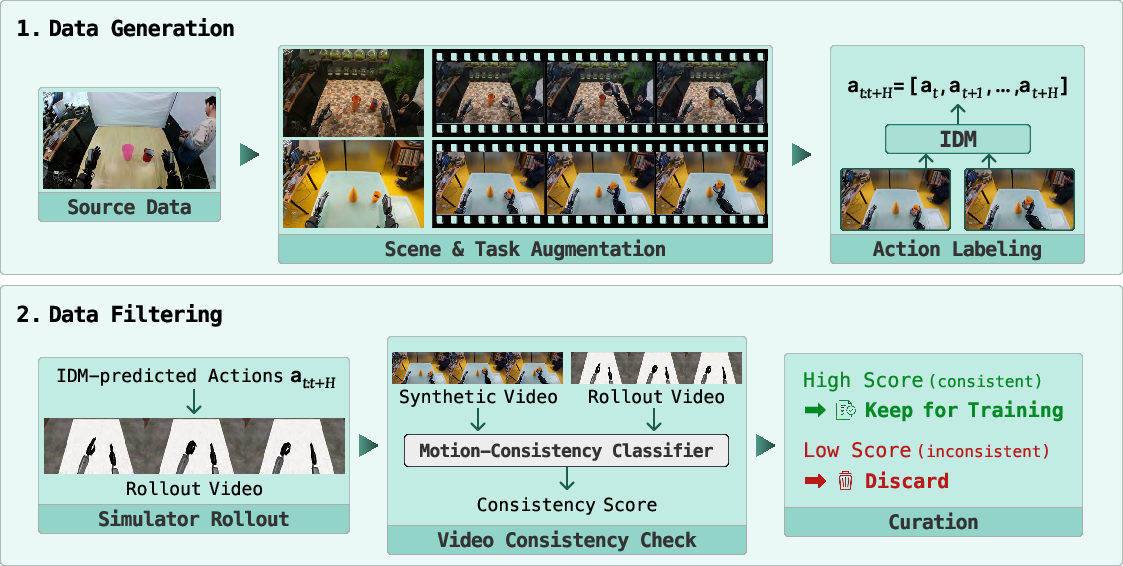
- Synthetic (AI-generated) data: They created new robot videos and instructions using video and image generators, then automatically labeled the actions using an inverse dynamics model (a model that guesses what actions created a motion).
Because AI-generated videos can be messy, they added two filters to keep only good samples:
- Video quality filter: A vision-LLM checks if the robot in the video follows the instruction and looks physically reasonable.
- Motion-consistency filter: They “replay” the predicted actions in a simulator (like testing game controls in a game engine) and compare the replay with the video. If the motions match closely, keep it; otherwise, discard it.
Training plan: from generalist to specialist
They trained RLDX-1 in three stages:
- Pre-training: Learn general robot skills from lots of different robots and tasks (about 1.5 million episodes).
- Mid-training: Focus on each robot type (like ALLEX or FR3) and add the special abilities—motion awareness, long-term memory, and physical sensing—using in-house and synthetic data.
- Post-training: Fine-tune for specific tasks; if needed, use reinforcement learning to polish performance even more.
Making it fast enough for real robots
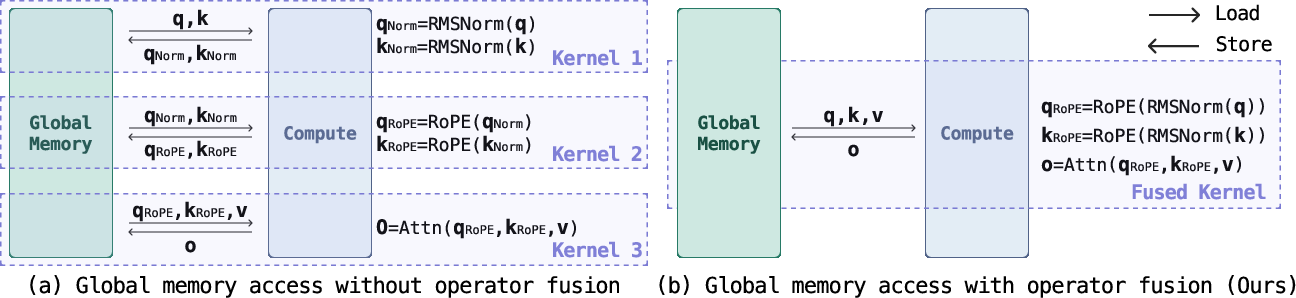
Robots need quick reactions. If the brain is slow, the world changes before the robot moves. The team cut the “thinking delay” per step from about 71 ms to about 44 ms (a 1.63× speed-up) by:
- Turning the model into a “static graph,” so the computer doesn’t waste time repeatedly setting things up.
- Fusing key operations so the computer moves data less and runs fewer separate steps.
What did they find, and why is it important?
RLDX-1 performed better than strong recent models across many tests, both in simulation and on real robots.
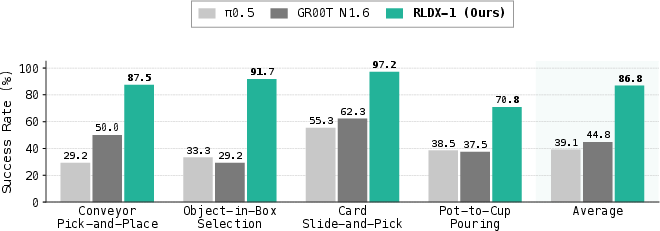
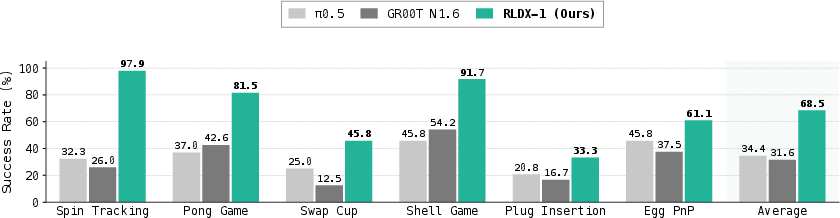
- Catching moving objects (motion awareness): On a conveyor-belt manipulation task, RLDX-1 succeeded over 87.5% of the time, while a leading baseline (π₀.₅) stayed under 29.2%. This shows RLDX-1’s video understanding and tracking really matter.
- Humanoid tabletop tasks: On a benchmark called GR-1 Tabletop, RLDX-1 reached 58.7% success, beating GR00T N1.6 at 47.6%.
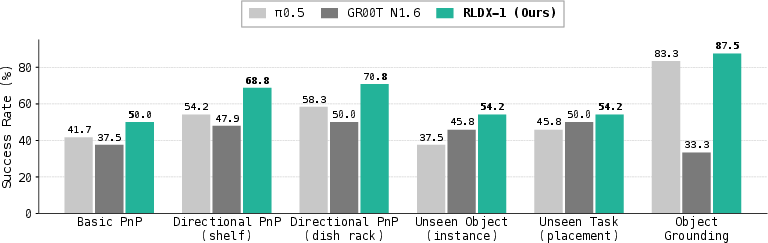
- Generalization to new objects and tasks: On an OpenArm humanoid, RLDX-1 beat π₀.₅ on unseen objects (54.2% vs 37.5%) and unseen tasks (54.2% vs 45.8%).
- Memory-heavy tasks: On ALLEX’s “Object-in-Box Selection,” which needs long-term memory, other models were in the 30% range, while RLDX-1 reached 91.7%.
- Synthetic data helps: Their AI-generated, carefully filtered data improved success rates—e.g., a 9.1% boost on a humanoid tabletop benchmark compared to training only on real data.
- Faster reactions: The speed-ups mean the robot’s decisions better match the live scene, helping it control precisely and safely.
These results matter because they show that adding motion understanding, memory, and physical “feel” on top of vision and language makes a big difference for real-world dexterous tasks.
Why does this research matter?
- More capable robots: RLDX-1 moves us closer to robots that can handle everyday, hands-on tasks—catching moving items, remembering where things are, and working by feel when the camera view is blocked.
- Safer, more reliable performance: Better sensing and faster decisions help robots act more smoothly and avoid mistakes.
- Practical recipe: The paper isn’t just a model—it’s a full recipe (architecture, data, training, and speed-ups) that others can follow to build real-world robot skills, even when special data (like touch) is limited.
- Scalable training: The synthetic data pipeline shows how to safely expand training beyond what’s easy to record in the lab, without filling the dataset with junk.
In short, RLDX-1 shows how to turn a robot from a “good viewer and reader” into a skilled doer that can handle movement, remember important past events, and feel what it’s doing—all fast enough to work in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Component-wise causality: Lack of rigorous ablations that isolate the contribution of each architectural element (motion module, cognition tokens and their count, temporal compression point, memory queue, physics stream, MSAT) across task types and embodiments, including interaction effects and compute–accuracy trade-offs.
- Temporal compression loss: Compressing past frames into a single token may discard motion cues for fast or non-Markovian dynamics; alternatives (learned attention pooling, multi-token summaries, selective keyframe retention) and their impact on latency/accuracy remain unexplored.
- Motion module placement and design: STSS insertion at one vision-encoder depth (9/27) is heuristic; optimal placement, multi-layer insertion, and comparisons against optical-flow, token shift, 3D CNNs, or video transformers are not evaluated.
- Long-horizon memory limits: The memory queue size (n_mem=3) and update cadence (every H+1 steps) are fixed; effects on tasks requiring minutes-long context, memory eviction policies, variable-length memory, and retrieval mechanisms (e.g., key-value memory, RAG over trajectories) are unstudied.
- Memory robustness: How the memory module handles noisy/irrelevant history, distribution drift across episodes, or resets is unclear; mechanisms for memory sanitization and episode boundary detection are not described.
- Physics stream generality: Physical sensing is limited to tactile (AnySkin) and joint torque on specific platforms; generalization to diverse sensors (force-torque, high-res tactile arrays, IMUs, slip detectors), varying sampling rates, and sensor failures/dropouts is untested.
- Auxiliary physics objective: The benefit of future physical-signal prediction (choice of horizon L, weighting) on action success, stability, and safety is not quantified; no study on when auxiliary losses help vs. hurt.
- Cross-modal interference: Joint self-attention in MSAT may cause high-dimension cognition tokens to dominate gradients over low-dimension proprioception/tactile streams; robustness strategies (modality weighting, gating, normalization per stream) and comparisons to cross-attention/FiLM are absent.
- Flow matching vs. alternatives: Rationale for flow matching over diffusion or autoregressive models is not empirically justified across control regimes; denoising step count T vs. latency vs. stability trade-offs are not charted.
- Chunked action reactivity: With H+1-step chunking, responsiveness to unexpected events mid-chunk, adaptive horizon selection, and mechanisms for interrupt/override/replan are unspecified.
- End-to-end latency: Reported 43.7 ms step time is model-only on an RTX 5090; missing end-to-end measurements (camera → preprocessing → model → controller → actuation), variability under ROS/real-time OS, and performance on embedded/edge hardware (Jetson, CPU-only).
- Static graph portability: CUDA graph and custom kernel optimizations’ compatibility across GPUs, PyTorch versions, dynamic input shapes (variable instruction length, variable frames), and model variants is not characterized; fallback performance when static capture is invalid is unknown.
- Dataset harmonization: How heterogeneous action spaces (position/velocity/torque), coordinate frames, control rates, and controller conventions are reconciled is not detailed; risk of conflicting labels and normalization drift remains.
- Embodiment transfer: While embodiment-specific projections are used, adaptation to unseen morphologies with few-shot or zero-shot data is not evaluated; protocols for rapid retargeting and failure cases are missing.
- Synthetic data fidelity: IDM-based action labeling for generated videos—especially for dexterous hand articulation—may be inaccurate; quantitative hand-pose/action verification on real hardware and taxonomy of labeling errors are lacking.
- Simulator dependence in filtering: Motion-consistency filtering hinges on simulator fidelity and V-JEPA2 features; sensitivity to sim-to-real appearance/physics gaps, calibration of acceptance thresholds, and failure modes on complex contacts are unreported.
- VLM-based filtering reliability: Instruction adherence and plausibility scoring via VLMs may inherit biases; human-in-the-loop audits, inter-rater reliability, and adversarial tests for failure cases are not provided.
- Long-horizon synthetic tasks: It is unclear whether the generation pipeline can produce multi-stage, branching, or delayed-reward tasks; synthetic coverage of sequential dependencies and its effect on memory learning is unquantified.
- RL post-training details: The “optional” RECAP-style RL lacks specifics (reward shaping, safety constraints, exploration strategies, sample budgets) and evidence of stable integration with flow-matching policies.
- Robustness to distribution shift: No systematic stress tests for lighting/camera changes, heavy occlusion, background motion, dynamic distractors, or human interference; robustness metrics and recovery behaviors under perturbations are absent.
- Safety and compliance: Formal handling of force/torque limits, collision avoidance, slip detection, and emergency stop policies is not discussed; how physical sensing is used for online safety decisions remains unclear.
- Proprioception/controller heterogeneity: Handling mixed controller modes (impedance, torque, velocity), action bounds, and calibration procedures is not described; impact on cross-dataset generalization is unknown.
- Data scaling laws: Performance scaling with real vs. synthetic data volumes, optimal mixing ratios, and diminishing returns are not characterized; no guidance on where additional data collection yields the most gain.
- Interpretability and diagnostics: What cognition tokens and memory features encode is opaque; probing methods, saliency/attribution, and tools to debug failure cases (e.g., incorrect spatial grounding) are missing.
- Evaluation statistics: Real-robot results lack comprehensive statistics (trial counts per task, confidence intervals, variance across days/operators/sites); reproducibility protocols and seeds are unspecified.
- External validity: Real-world tests focus on ALLEX and FR3; transfer to other hands/grippers, controller stacks, table geometries, and novel objects/clutter remains untested.
- Temporal synchronization: Methods for synchronizing vision, tactility, torque, and proprioception streams and compensating for clock skew/latency are not described; effects on performance are unknown.
- Energy/compute footprint: Training and inference energy costs and accessibility for labs without high-end GPUs are not reported; trade-offs between model size and performance are unexplored.
- Reproducibility constraints: Dependence on third-party models (e.g., I2V/V2V/FLUX/V-JEPA2) may limit open replication; availability of trained filters and synthetic pipelines and licensing considerations are unclear.
- Security/privacy: Risks from using internet-scale models and synthetic data (e.g., unsafe behavior imitation, privacy leakage) and mitigation strategies are not discussed.
- Dynamic task spectrum: Aside from a conveyor-belt example, coverage across motion speeds/accelerations and the role of sensor/compute latency in success rates are not systematically evaluated.
- Hyperparameter choices: Fixed settings (64 cognition tokens, compression after layer 4, STSS after layer 9) are not justified with sensitivity analyses; principled selection procedures are absent.
Practical Applications
Practical Applications Derived from the RLDX-1 Technical Report
Below are concrete, real-world applications that leverage RLDX-1’s findings, methods, and innovations. They are grouped into Immediate and Long-Term Applications and annotated with sector links, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Dynamic conveyor and moving-object manipulation in factories and fulfillment centers
- Sector: Robotics, Manufacturing, Logistics
- What: Deploy RLDX-1’s motion-awareness (multi-frame video + STSS module + temporal compression) for picking, tracking, and placing items on moving belts or carts; catching, sorting, and singulation where target motion is non-stationary.
- Tools/Products/Workflows: ROS2 policy node for FR3/AGV/gantry systems; vision rig with synchronized multi-view cameras; calibration pipeline; prebuilt “Conveyor Pack” policy weights; real-time inference stack (CUDA Graph capture + fused kernels).
- Assumptions/Dependencies: RTX-class GPU (or equivalent accelerator) for ~40–70 ms control loop; reliable extrinsics; consistent belt speed; safety fencing/cobotic safeguards; licensing/compatibility for Qwen3-VL and model weights.
- Contact-rich assembly and insertion (force-aware)
- Sector: Robotics, Manufacturing (electronics, automotive), Hardware assembly
- What: Use the physics stream (tactile + torque) and auxiliary physical-signal forecasting to regulate contact forces for tasks like connector insertion, mating, screwing, and compliant alignment in occluded scenes.
- Tools/Products/Workflows: FR3 gripper retrofitted with AnySkin or similar; torque-logging middleware; MSAT-based policy with physics stream enabled; calibration and slip-detection thresholds; workstation SOPs for operator oversight.
- Assumptions/Dependencies: Availability and robustness of tactile sensors; data to mid/post-train on target fixtures; cycle-time constraints; industrial safety compliance; periodic recalibration.
- Long-horizon, memory-dependent kitting and station handovers
- Sector: Robotics, Manufacturing, Warehousing, Labs
- What: Apply the memory module for tasks requiring state recall (e.g., track which bin received which component, select “object in box” after several subtasks).
- Tools/Products/Workflows: “Memory-enabled” policy release; task graphs that interleave manipulation with inspection steps; logging and replay tools validated by the memory queue.
- Assumptions/Dependencies: Stable perception across lighting/domain shifts; sufficient on-site post-training data; clear task decompositions; guardrails for memory resets or drift.
- Latency-optimized VLA runtime for real-time control
- Sector: Software, Robotics
- What: Adopt the inference optimization stack (static graph capture + custom operator fusion) to cut per-step latency in robot control loops and other time-critical multimodal models.
- Tools/Products/Workflows: Drop-in PyTorch/CUDA Graph wrapper; operator-fusion kernels for attention stacks; profiling toolkit and CI perf tests; deployment playbooks for NVIDIA GPUs.
- Assumptions/Dependencies: NVIDIA CUDA stack; model graph stability; maintenance of fused kernels across framework updates; benchmarking under varied I/O and camera loads.
- Synthetic data generation and curation pipeline for rare dexterous scenarios
- Sector: Academia, Robotics R&D, Software Tools
- What: Use the task augmentation (VLM-based), image/video augmentation (I2I, I2V, V2V), IDM action labeling, and motion-consistency filtering to scale training for long-tail tasks.
- Tools/Products/Workflows: “RoboCurate”-style toolkit: prompts, I2I/I2V recipes (e.g., FLUX.2-dev, Cosmos-Transfer2.5), IDM annotator, V-JEPA2-based alignment probe, and replay-in-simulator filter.
- Assumptions/Dependencies: Access to commercial I2I/I2V models and licenses; reliable simulator for action replay; compute budget for generation and filtering; quality VLM judges.
- Rapid embodiment adaptation using lightweight projection layers
- Sector: Robotics (OEMs, integrators)
- What: Map new arms/grippers/hands into RLDX-1’s shared latent via small embodiment-specific projections, reducing data needs for new hardware.
- Tools/Products/Workflows: Embodiment adapter templates; minimal demo collection protocol; few-shot fine-tuning scripts; acceptance tests on canonical tasks.
- Assumptions/Dependencies: Reasonably similar kinematic structure; sufficient proprioceptive and perception coverage; availability of a small, representative demo set.
- Teleoperation capture stack for high-quality dexterous demonstrations
- Sector: Academia, Robotics R&D, Training Services
- What: Replicate the VR/glove/tracker teleop setup (Meta Quest, Vive Trackers, Manus Pro) to collect human demonstrations with hand pose and tactile/torque streams.
- Tools/Products/Workflows: Hardware BOM and calibration tools; IK solvers; data logging format for synchronized video/action/tactile/torque; quality-control dashboards.
- Assumptions/Dependencies: Operator training time; equipment procurement and maintenance; consistent synchronization and low drift; ergonomic concerns.
- Benchmarking and curriculum design for VLA training
- Sector: Academia, Education, Consortia/Benchmarking Orgs
- What: Use GR-1 Tabletop, RoboCasa Kitchen/365, LIBERO(-Plus), SIMPLER, and in-house tasks to evaluate and teach motion awareness, memory, and physical sensing.
- Tools/Products/Workflows: Unified evaluation harness; standardized success/failure taxonomy; ablation templates for modules (STSS, memory, physics stream).
- Assumptions/Dependencies: Access to simulators and real robots; consistent task definitions across labs; shared metrics and reporting standards.
- Quality assurance and safety checks via motion-consistency verification
- Sector: Policy/Compliance, Industrial QA, Robotics Ops
- What: Integrate the alignment probe and simulator rollouts to validate that planned/learned actions align with video evidence before deployment or for audit trails.
- Tools/Products/Workflows: Pre-deployment “plan vs. replay” gating; on-line spot checks; audit reports for incident review.
- Assumptions/Dependencies: Representative simulators; calibrated thresholds for acceptance; governance on false positives/negatives; data logging policies.
- Compute- and energy-efficiency gains through accelerated inference
- Sector: Energy (indirect), Operations/IT
- What: Lower per-step latency translates to lower GPU duty cycle for equivalent throughput, enabling higher robot density per GPU and reduced energy per action.
- Tools/Products/Workflows: Fleet scheduler aware of model timing; KPI dashboards (latency/energy/throughput); capacity planning models.
- Assumptions/Dependencies: Actual duty-cycle profiles; thermal and power constraints in on-prem facilities; opportunity to batch or pipeline inference.
Long-Term Applications
- Household and office humanoid assistants for multi-step chores
- Sector: Consumer Robotics, Smart Home, Facilities
- What: Leverage motion awareness, long-term memory, and tactile/torque sensing for tasks like tidying, dish handling, folding, and safe object manipulation under occlusion.
- Tools/Products/Workflows: Home-grade dexterous hands; embedded, low-power VLA accelerators; routines that combine perception, memory checkpoints, and fail-safe recovery.
- Assumptions/Dependencies: Affordable, reliable dexterous hardware; robust safety certification; strong on-device inference or fast edge/cloud links; user acceptance and liability frameworks.
- Assistive care and rehabilitation robotics with touch and memory
- Sector: Healthcare
- What: Fine-grained, contact-sensitive help (e.g., feeding assistance, dressing aids, mobility support) with memory of patient-specific preferences and routines.
- Tools/Products/Workflows: Medical-grade haptic sensing; privacy-preserving memory modules; clinician-in-the-loop training and override; incident logging and explainability tools.
- Assumptions/Dependencies: Strict regulatory approval (e.g., FDA, CE); rigorous safety guarantees; extensive clinical trials; infection control and sanitization.
- dexterous surgical or micro-assembly co-pilots
- Sector: Healthcare, Advanced Manufacturing (semiconductor, optics)
- What: Extend MSAT to integrate high-rate haptics, micro-force sensing, and vision for precise, supervised manipulation or co-manipulation.
- Tools/Products/Workflows: High-fidelity physics streams; certified teleop systems with shared control; simulation-to-real pipelines with validated tissue/part models.
- Assumptions/Dependencies: Ultra-low-latency control; high-trust safety envelopes; specialized sensors and sterilizable hardware; stringent validation.
- Cross-embodiment generalist manipulation services
- Sector: Robotics Platforms, Integrators
- What: Provide “universal” policy services that adapt to many robot forms (single-arm, dual-arm, humanoid) via projection/adapters and mid/post-training.
- Tools/Products/Workflows: Marketplace of embodiment adapters; deployment orchestrator; policy versioning and rollback; telemetry for continual improvement.
- Assumptions/Dependencies: Standardized interfaces for states/actions; robust sim-to-real transfer across embodiments; partner ecosystem and support agreements.
- Policy and standards for tactile/torque data and synthetic-data governance
- Sector: Policy/Standards, Public Sector, Industry Consortia
- What: Develop standards for logging, privacy, bias mitigation, and validation of physical-sensing streams; certify synthetic data via action/video consistency audits.
- Tools/Products/Workflows: Draft specs for tactile/torque telemetry; audit checklists for motion-consistency; model cards documenting synthetic data proportions and filtering thresholds.
- Assumptions/Dependencies: Multistakeholder coordination; incentives for compliance; harmonization with safety and privacy regulations.
- Edge deployment of VLAs on mobile/humanoid platforms
- Sector: Robotics, Edge AI, Embedded Systems
- What: Port the latency-optimized stack to lower-power SoCs (Jetson/Orin-class, bespoke NPUs) while retaining motion awareness, memory, and physics streams.
- Tools/Products/Workflows: Mixed-precision kernels, operator fusion for embedded; model distillation/pruning; on-device dataset curation and small-scale post-training.
- Assumptions/Dependencies: Hardware support for required ops; acceptable accuracy/latency trade-offs; thermal budgets; battery life constraints.
- Broadly capable synthetic training at internet scale for manipulation
- Sector: Academia, Foundation Models for Robotics
- What: Scale the I2I/I2V + IDM + filtering loop to millions of curated episodes spanning many homes/factories, reducing human demo costs.
- Tools/Products/Workflows: Data-generation farms; auto-red teaming for failure patterns; uncertainty-aware filters; cross-simulator validation.
- Assumptions/Dependencies: High-fidelity generators; legal clarity on synthetic/augmented data IP; compute budgets; diminishing returns management.
- Closed-loop plant integration with memory-aware, force-aware VLAs
- Sector: Industrial Automation, Energy (indirect), Process Control
- What: Integrate with PLCs/MES for flexible lines where the robot adapts to work-in-progress state and operator intent, using long-term memory and physical feedback.
- Tools/Products/Workflows: Connector kits for PLCs; task-graph + policy orchestration; safety interlocks; explainability for line leads.
- Assumptions/Dependencies: Legacy system interoperability; validated fail-safe behaviors; clear ROI vs. programmable automation; cybersecurity policies.
- Multi-agent humanoid teams in logistics/retail
- Sector: Logistics, Retail, Hospitality
- What: Coordinate memory-enabled humanoids for stocking, picking, and customer-facing tasks with dynamic environments and fine manipulation.
- Tools/Products/Workflows: Fleet manager with shared memory primitives and intent alignment; role-based policies; social compliance modules.
- Assumptions/Dependencies: Social acceptance; local regulations; robust navigation + manipulation integration; cost of hardware and maintenance.
- Generalized MSAT-based control for aerial/legged robots with multi-sensor fusion
- Sector: Robotics (Aerial, Legged), Defense/Public Safety (with safeguards)
- What: Extend the multi-stream architecture to fuse force, IMU, depth, and tactile-like proxies for complex locomotion/manipulation (e.g., drone inspection with contact, legged door opening).
- Tools/Products/Workflows: Stream adapters for IMU and proprioceptive feedback; domain-specific simulators; safety envelopes for contact.
- Assumptions/Dependencies: Reliable sensor calibration; resilient hardware; regulatory approvals (airspace, public spaces); robust domain adaptation.
Notes on cross-cutting assumptions and dependencies:
- Hardware: Dexterous hands, tactile/torque sensors (e.g., AnySkin), synchronized video, and sufficient compute (RTX-class now; embedded accelerators later).
- Software/IP: Licenses and access for Qwen3-VL, I2I/I2V models (e.g., FLUX.2-dev, Cosmos-Transfer2.5); simulator availability and accuracy; ROS2 and control stack integration.
- Data: Task- and site-specific mid/post-training data; curated synthetic data quality; calibration and maintenance of sensors; human demonstrations for edge cases.
- Safety/Regulation: Human-robot collaboration standards, medical/assistive approvals, privacy for recorded streams, incident auditing with motion-consistency tools.
- Operations: Operator training, maintenance workflows, clear KPIs (latency, success rates), and organizational readiness for flexible automation.
Glossary
- Action chunk: A contiguous sequence of future actions predicted as a block. Example: "where denotes the action chunk horizon."
- Auxiliary objective: An additional training loss used to improve learning of specific targets. Example: "we incorporate an auxiliary objective for predicting future physical signals"
- Canny edge map: An edge-detected representation of an image used as conditioning for generation/editing. Example: "We additionally condition on a Canny edge map for editing to preserve the underlying scene structure and maintain a plausible starting state for video generation"
- Causal attention: Attention that only allows tokens to attend to past (or current) positions, preserving temporal order. Example: "Specifically, we use causal attention so that cognition tokens of later timesteps attend only to themselves and earlier ones"
- Cognition tokens: Learnable query tokens appended to the input to extract action-relevant features from a VLM. Example: "we introduce cognition tokens $$, learnable query tokens that are appended to the input token sequence."
- Cross-attention: An attention mechanism where queries from one sequence attend to keys/values from another sequence. Example: "The probe consists of a single cross-attention layer with a learnable query token attending to the concatenated embeddings of the two video clips"
- CUDA Graph: A captured and replayable GPU execution graph that reduces kernel launch overhead. Example: "capturing the entire forward pass as a single CUDA Graph."
- DeepStack design: A model design in which multi-level vision features are fused into early LLM layers. Example: "to use the DeepStack design of Qwen3-VL"
- Diffusion Transformer (DiT): A Transformer architecture used for diffusion-style denoising or flow-matching generation. Example: "We implement the action model as a flow-matching Diffusion Transformer (DiT;"
- DoF (Degrees of Freedom): The number of independent joint or pose parameters of a robot mechanism. Example: "7-DoF arms and 15-DoF five-finger hands."
- Egocentric teleoperation: Remote control from the operator’s viewpoint, often via VR, to collect demonstrations. Example: "via VR-based egocentric teleoperation."
- Embodiment-agnostic projection layer: A shared projection that maps diverse robot embodiments to a common latent space. Example: "we additionally maintain an embodiment-agnostic projection layer"
- Embodiment-specific: Tailored to a particular robot morphology or platform. Example: "embodiment-specific projection layers"
- End-effector: The robot’s terminal manipulator (e.g., gripper or hand) that interacts with objects. Example: "spatial relationships between the robot end-effector and target objects"
- Euler's method: A numerical integration method used to step the generative dynamics. Example: "and use Euler's method to generate action chunks over T denoising steps:"
- Flow matching: A training paradigm that learns a vector field to transport noise to data. Example: "using the following flow-matching objective"
- Graph capture: Recording a static computation graph for efficient repeated execution. Example: "based on graph capture (\Cref{subsec:graph-capture-optimization})"
- Inverse dynamics model (IDM): A model that infers actions from observed state transitions (e.g., video). Example: "an inverse dynamics model (IDM) annotates action labels for the generated videos."
- Inverse kinematics: Computing joint angles that achieve a desired end-effector pose. Example: "inverse kinematics computes the arm joint angles."
- Joint self-attention: Self-attention applied jointly across tokens from multiple modality streams. Example: "couples them through joint self-attention"
- Long-horizon tasks: Tasks requiring reasoning over extended temporal contexts. Example: "sequential and long-horizon tasks often require long-term memory"
- Memory queue: A fixed-size buffer of historical features used for long-term context. Example: "we maintain a memory queue that stores the last cached cognition tokens"
- Motion-consistency filtering: A filter that retains synthetic samples whose actions align with observed motion. Example: "we further introduce video quality filtering and motion-consistency filtering"
- Multi-embodiment: Involving multiple robot morphologies within one training or model framework. Example: "large-scale multi-embodiment dataset"
- Multi-Modal Diffusion Transformer (MM-DiT): A diffusion Transformer architecture handling multiple modalities. Example: "Multi-Modal Diffusion Transformer (MM-DiT;"
- Multi-Stream Action Transformer (MSAT): A multi-stream Transformer that models actions conditioned on heterogeneous modalities. Example: "we propose the Multi-Stream Action Transformer (MSAT)"
- Operator fusion: Combining multiple computational operators into a single kernel to reduce memory traffic. Example: "fails to fully exploit cross-operator fusion"
- Proprioceptive state: Internal robot state signals (e.g., joint angles/velocities) used for control. Example: "the proprioceptive state "
- QKV projections: The linear projections producing queries, keys, and values for attention. Example: "attention input (QKV) projections."
- RECAP-style reinforcement learning: A specific RL fine-tuning approach referenced for post-training improvement. Example: "RECAP-style reinforcement learning"
- RMSNorm: A normalization technique that uses root-mean-square statistics. Example: "we adopt RMSNorm (including on queries and keys;"
- RoPE (Rotary positional embeddings): A positional encoding method that rotates query/key vectors to encode relative positions. Example: "rotary positional embeddings (RoPE;"
- Rollout: A simulated or model-executed trajectory used for evaluation or verification. Example: "replaying predicted actions in a simulator and comparing the rollout against the generated video"
- Space-time self-similarity (STSS): A representation capturing correlations across space and time in video features. Example: "space-time self-similarity (STSS;"
- Static graph: A fixed computation graph enabling optimized execution without dynamic shape changes. Example: "converting the model into a static graph"
- SwiGLU: A gated activation function variant used in Transformer feed-forward layers. Example: "with SwiGLU activation function"
- Tactile sensor: A sensor that measures contact forces or touch at the manipulator. Example: "an AnySkin tactile sensor"
- Teleoperation: Human-controlled operation of a robot, often for data collection. Example: "We collect data through a teleoperation via a Meta Quest VR controller"
- Torque: Rotational force at robot joints, often measured or estimated for control. Example: "joint torque measurements"
- V2V transfer: Video-to-video transformation that alters appearance while preserving motion. Example: "V2V transfer using Cosmos-Transfer2.5-2B"
- V-JEPA2: A specific learned video encoder used for feature extraction. Example: "a frozen V-JEPA2 video encoder"
- Vision-Language-Action (VLA): Models that map vision and language inputs to robot actions. Example: "Vision-Language-Action model (VLA)"
- Vision-LLM (VLM): Models that jointly process visual and textual inputs. Example: "Vision-LLM (VLM)"
- Visual Question Answering (VQA): A task/dataset where models answer questions about images or videos. Example: "Visual Question Answering (VQA) dataset"
Collections
Sign up for free to add this paper to one or more collections.

