- The paper presents a novel multi-granular trajectory alignment (MTA) that aligns teacher-student representations using word-level and phrase-level supervision.
- It introduces dynamic structural and hidden alignment losses to capture the hierarchical evolution of Transformer layers in LLMs.
- Empirical results show that MTA significantly narrows the ROUGE-L gap and outperforms baselines on both in-distribution and out-of-distribution benchmarks.
Multi-Granular Trajectory Alignment for LLM Distillation: An Expert Synthesis
Introduction and Motivation
The paper "MTA: Multi-Granular Trajectory Alignment for LLM Distillation" (2605.01374) addresses the challenge of efficiently compressing LLMs via knowledge distillation (KD). While classical KD focuses primarily on aligning student and teacher output distributions (token-level KL minimization), such approaches fail to leverage the intrinsic hierarchical evolution of representations across layers in deep Transformer models. Existing feature-based KD methods often use static, token-level objectives that disregard the growing abstraction and compositionality manifesting in deeper layers. Consequently, representation transfer is suboptimal, as students are not encouraged to reproduce the depth-dependent internal geometric structure critical for downstream generalization.
The authors propose a modular framework—Multi-Granular Trajectory Alignment (MTA)—that explicitly models and aligns the teacher-student representational trajectory across network depth. MTA introduces a layer-adaptive scheme: lower layers are distilled at the word level to retain lexical fidelity, while upper layers leverage phrase-level (e.g., NP/VP) alignment to capture compositional semantics, following both linguistic theory and empirical analysis of Transformer hierarchies.
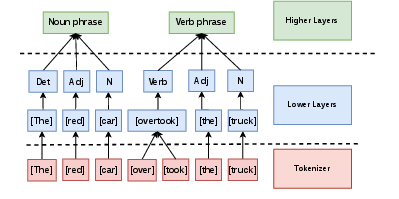
Figure 1: The correspondence between linguistic compositionality and the layer-wise evolution of representations in LLMs.
Methodological Framework
Hierarchical Trajectory and Layer-Adaptive Alignment
MTA is predicated on the observation that Transformer representations evolve from encoding lexical features in early layers to increasingly abstract, compositional features in deeper layers. This insight, grounded in both linguistic theory and Transformer interpretability studies, motivates a distillation strategy that is granular and depth-aware.
Dynamic Structural Alignment Loss (LDSA)
At each designated layer, MTA defines semantic spans—words for lower layers and parser-extracted phrases (NPs/VPs) for upper layers—and constructs a span representation using teacher-derived token importance weights. The central objective, LDSA, enforces consistency between the student and teacher in the pairwise geometric relationships of these span embeddings, effectively distilling the internal relational structure.
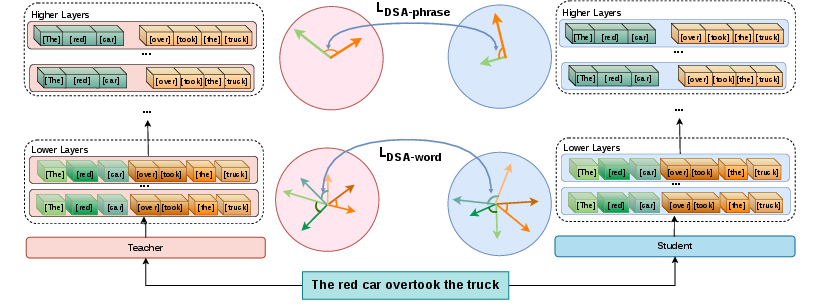
Figure 2: Dynamic Structural Alignment ($\mathcal{L_{\text{DSA}}$): enforces geometric alignment between the pairwise distances of span representations across student and teacher at multiple layers.
Hidden Representation Alignment Loss (LHid)
Complementing LDSA, MTA introduces a hidden-state matching loss for selected layers. Since there is typically a hidden dimension mismatch between student and teacher, a linear projector is trained to align student states with the teacher's, using a salience-weighted cosine distance. This additional supervision is essential to ensure not just relational, but also pointwise feature consistency for salient tokens within key spans.
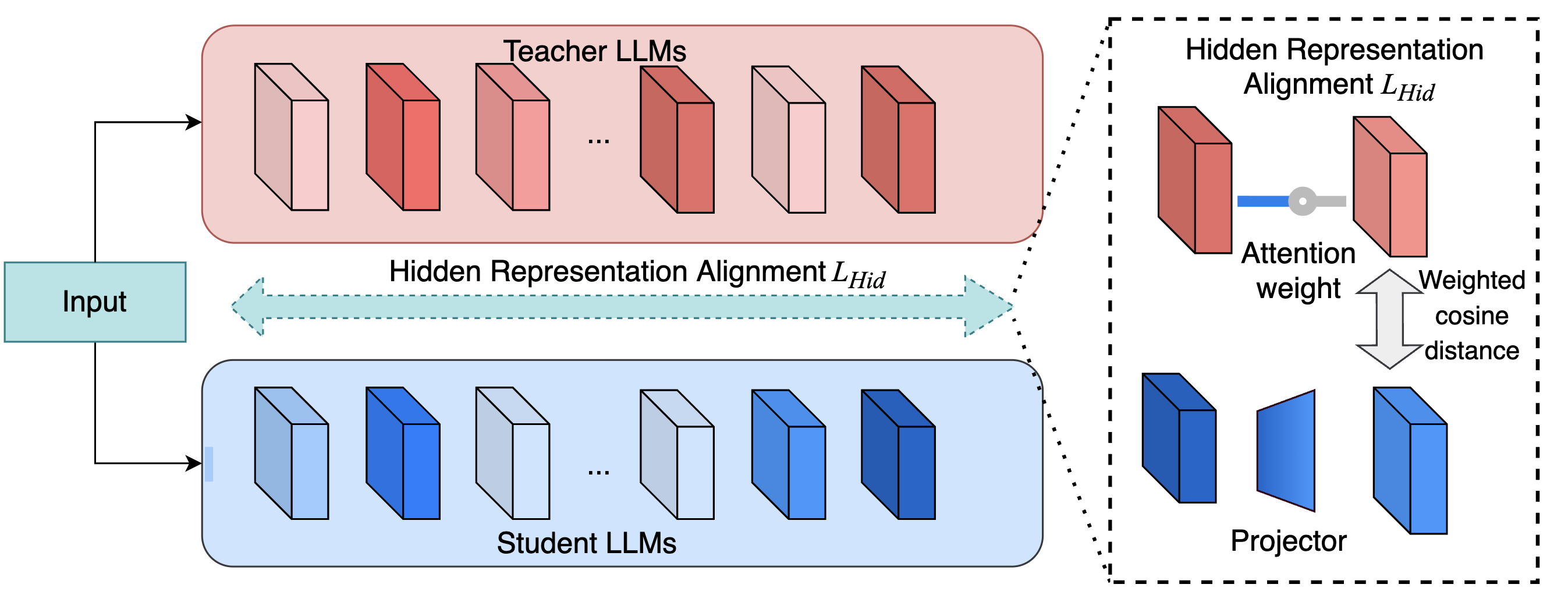
Figure 3: Hidden Representation Alignment: direct feature matching at important positions using a weighted cosine distance.
Integrated Optimization
MTA is designed as a plug-in module for state-of-the-art LLM distillation pipelines (e.g., DistiLLM, DistiLLM-2, FDD), combining the base KD loss with the DSA and hidden alignment losses. Critical hyperparameters govern the weighting of these objectives; empirical validation confirms the importance of tuning these appropriately for model scale.
Experimental Evaluation
Datasets and Model Pairs
MTA is assessed over multiple instruction-following benchmarks, including in- and out-of-distribution (OOD) settings (e.g., Dolly, S-NI, VicunaEval, SelfInst), using the following teacher-student pairs: GPT-2 1.5B → GPT-2 120M, Qwen1.5-1.8B → Qwen1.5-0.5B, and OPT 6.7B → OPT 1.3B. Both full and parameter-efficient fine-tuning protocols are adopted.
Quantitative Results
Across all base frameworks, the integration of MTA yields consistent boosts in ROUGE-L scores and LLM-as-a-judge (GPT-4o-mini) evaluation metrics.
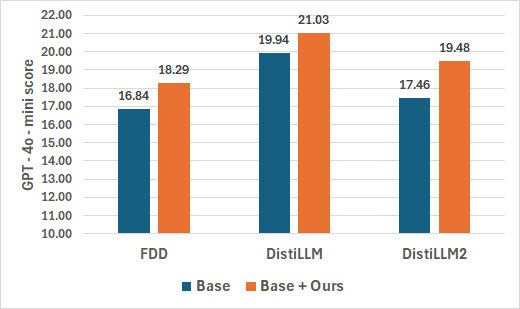
Figure 4: GPT-4o-mini evaluation scores (1-100) for distilling GPT-2 1.5B into GPT-2 120M.
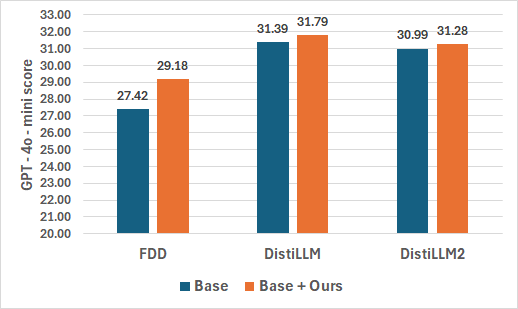
Figure 5: GPT-4o-mini evaluation scores (1-100) for distilling OPT 6.7B into OPT 1.3B.
Notably, MTA closes up to 1.24 points of the student-teacher ROUGE-L gap on Qwen1.5 pairs and outperforms all baselines, including FDD and state-of-the-art DistiLLM-2. On particularly OOD and complex datasets (S-NI), DistiLLM+MTA achieves up to 29.2, substantially better than word- or phrase-level-only alignments.
Ablation and Sensitivity Analysis
Ablations confirm the isolated and synergistic contributions of LDSA and LHid—the combination yields maximal gains. Further, static granularity (all-word or all-phrase) is decisively outperformed by the adaptive hybrid scheme, empirically substantiating the central hypothesis about depth-specific alignment.
Layer allocation studies indicate that utilizing a small, judiciously placed set of intermediate supervision points (e.g., three key layers in GPT-2) achieves a non-monotonic gain, avoiding redundancy. MTA is robust to alternate layer schedules without reliance on extensive hyperparameter searches.
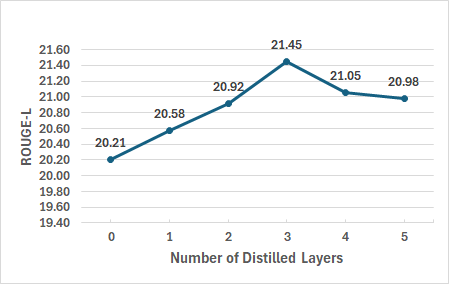
Figure 6: Effect of the number of distilled intermediate layers (ROUGE-L scores with DistiLLM + MTA).
Computational Considerations
MTA introduces moderate training overhead due to span extraction, but the penalty (up to 1.85× vs. base) is eliminated during inference. Time-matched experiments eliminate the confound of additional compute, demonstrating that performance improvements are a direct result of trajectory-aligned supervision, not longer training.
Theoretical and Practical Implications
MTA's approach has several theoretical and practical implications:
- Linguistically Principled Compression: By modeling LLMs' internal evolution as a hierarchical trajectory and aligning representations accordingly, MTA instantiates a distillation paradigm that is more faithful to the underlying compositional mechanisms—promising for robust transfer, especially OOD.
- Plug-and-Play Generality: MTA does not disrupt existing KD frameworks but adds a targeted, lightweight regularizer, ensuring ease of adoption across architectures (decoder-only, different widths/depths).
- Extensibility: The method opens avenues for further study—automated granularity selection, integration of more sophisticated structural parsing, and lightweight geometric approximations for low-resource scenarios.
- Potential for Cross-Tokenizer and Multimodal Distillation: The multi-granular, trajectory-based philosophy is applicable wherever internal structure and dynamic representation evolution are key, including cross-tokenizer and cross-modal transfer.
- Limitations: Current reliance on external parsing and geometric matching increases training complexity. Future work on learnable, efficient in-model parsing or fully differentiable span extraction is warranted.
Conclusion
MTA provides a formally justified, empirically validated strategy for depth-aware, compositional knowledge distillation in LLMs. By simultaneously aligning local lexical grounding and higher-level compositional structure along the representational trajectory, it outperforms static, uniform, or single-granularity objectives. MTA stands as a robust, practical blueprint for effective LLM compression, supporting further theoretical advances in interpretable and structure-aware model distillation.

