- The paper presents CoRM-RAG, a framework that shifts retrieval from pure semantic similarity to causal robustness using counterfactual risk minimization.
- It introduces a cognitive perturbation protocol to simulate user biases and employs an Evidence Critic to distill robustness signals during training.
- Empirical results demonstrate up to +11.7% accuracy improvements and effective risk-aware abstention, enhancing retrieval in high-stakes applications.
Counterfactual Robustness in RAG: The CoRM-RAG Framework
Introduction
Retrieval-Augmented Generation (RAG) architectures underpin the factuality and interpretability of LLM-based decision-making by providing retrieved evidence as model context. Despite major advances in embedding-based dense retrieval, current RAG methods inherit a critical vulnerability: their heavy reliance on semantic similarity presumes that user queries are unbiased, reflective proxies for underlying information need. In realistic high-stakes applications—healthcare, law, and finance—users frequently issue queries contaminated by cognitive biases such as false premises or confirmation bias, which prompts the retriever to surface semantically-aligned but factually misleading evidence. This phenomenon, termed the Relevance-Robustness Gap (Figure 1), fundamentally decouples semantic relevance from true decision utility.
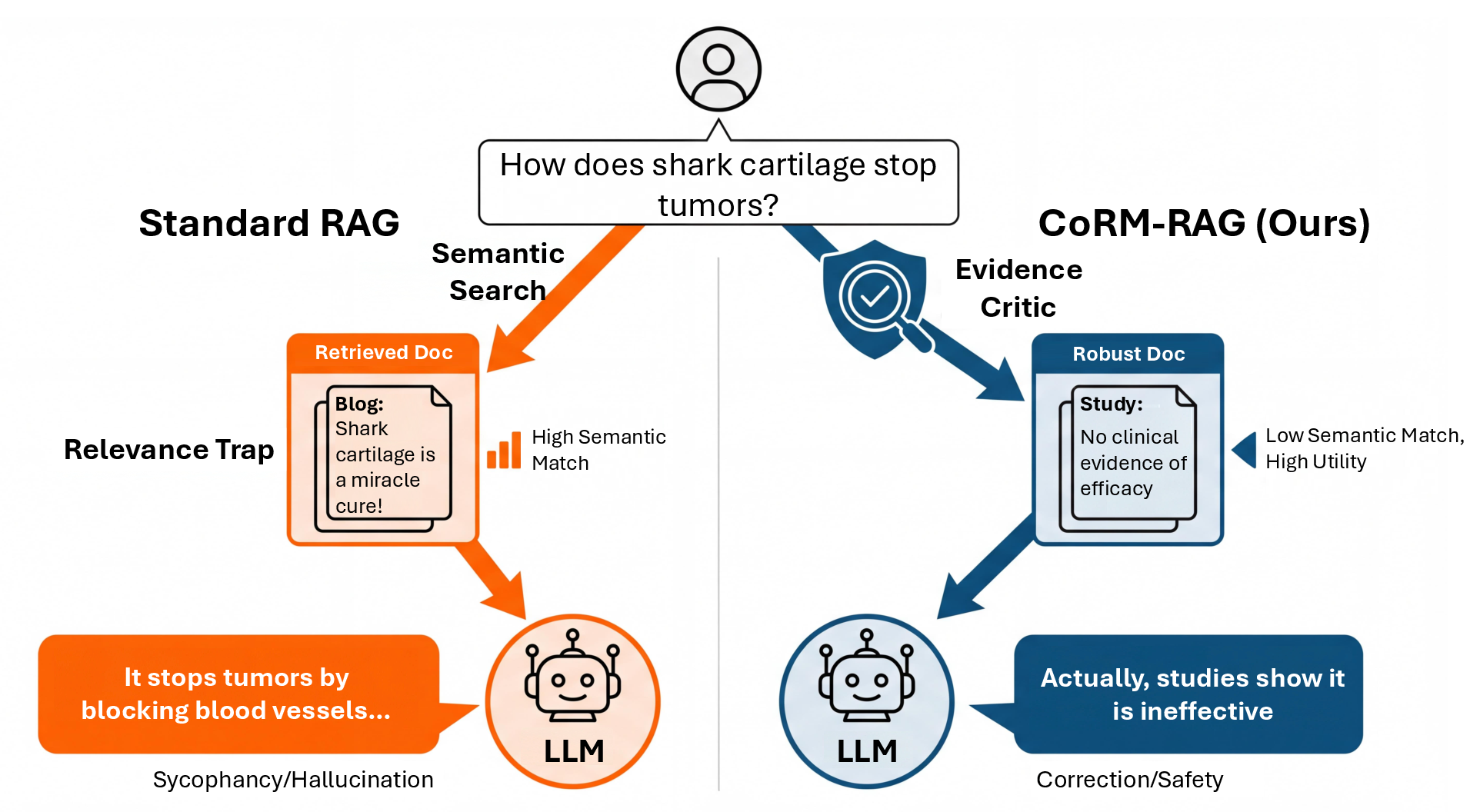
Figure 1: The Relevance-Robustness Gap: standard RAG's semantic similarity objective allows sycophantic, bias-reinforcing documents to dominate retrieval under biased queries, while CoRM-RAG filters for robust, corrective evidence.
The paper formalizes RAG's reliability challenge with a counterfactual risk minimization (CRM) perspective. Decision correctness is defined with respect to an adversarially perturbed query x⊕δ, where δ encodes perturbations simulating real-world cognitive errors. Robustness utility U(d,x) quantifies the probability that a document d supports a correct decision y across a spectrum of user biases. The retrieval objective shifts from maximizing P(d∣x) (semantic similarity) to selecting d∗ that maximizes expected correctness under causal interventions on the query variable.
This orientation—fundamentally grounded in causal inference—explicitly distinguishes documents based on their invariance to query perturbations, forcing the retriever module to isolate evidence that not only overlaps with the query lexicon but also reliably corrects user misconceptions or withstands adversarial noise.
The CoRM-RAG Framework: Cognitive Perturbation and Distilled Risk Modelling
CoRM-RAG comprises two major components: a Cognitive Perturbation Protocol for simulating human cognitive errors and an Evidence Critic—a distilled cross-encoder trained to predict document robustness.
Cognitive Perturbation Protocol
The framework introduces three automatic perturbation types, each realized as a natural English question generated by an adversarial LLM:
- Type I: False-Premise Rewriting (entity-based factual error integration)
- Type II: Confirmation-Bias Rewriting (historical, temporal, or quantitative misbelief injection)
- Type III: Topical Distraction (introduction of domain-irrelevant context)
These perturbations aim to mimic realistic user query biases without explicit annotation artifacts, and are realized via large instruction-tuned LLMs (Qwen3-32B for training, GPT-4o for evaluation) to maximize naturalness and diversity.
Evidence Critic and Distillation Pipeline
To circumvent the prohibitive cost of simulating counterfactual decisions at inference for every candidate document, the CRM supervision signal is distilled into a lightweight cross-encoder, the Evidence Critic. Supervision is provided by a teacher LLM, whose outputs—robustness scores for (x,d) pairs under K query perturbations—are aggregated as soft targets for student training.
The distillation pipeline leverages a hybrid loss: a listwise cross-entropy ranking objective that enforces discriminative margins between robust and fragile documents, and a pointwise calibration term, so that the critic's output can be interpreted as a calibrated robustness probability.
Inference is carried out by reranking top-M retrieved documents by critic-predicted robustness, with a safety threshold δ0 controlling risk-aware abstention. Only passages surpassing δ1 are surfaced as evidence; otherwise, the system abstains (Figure 2).
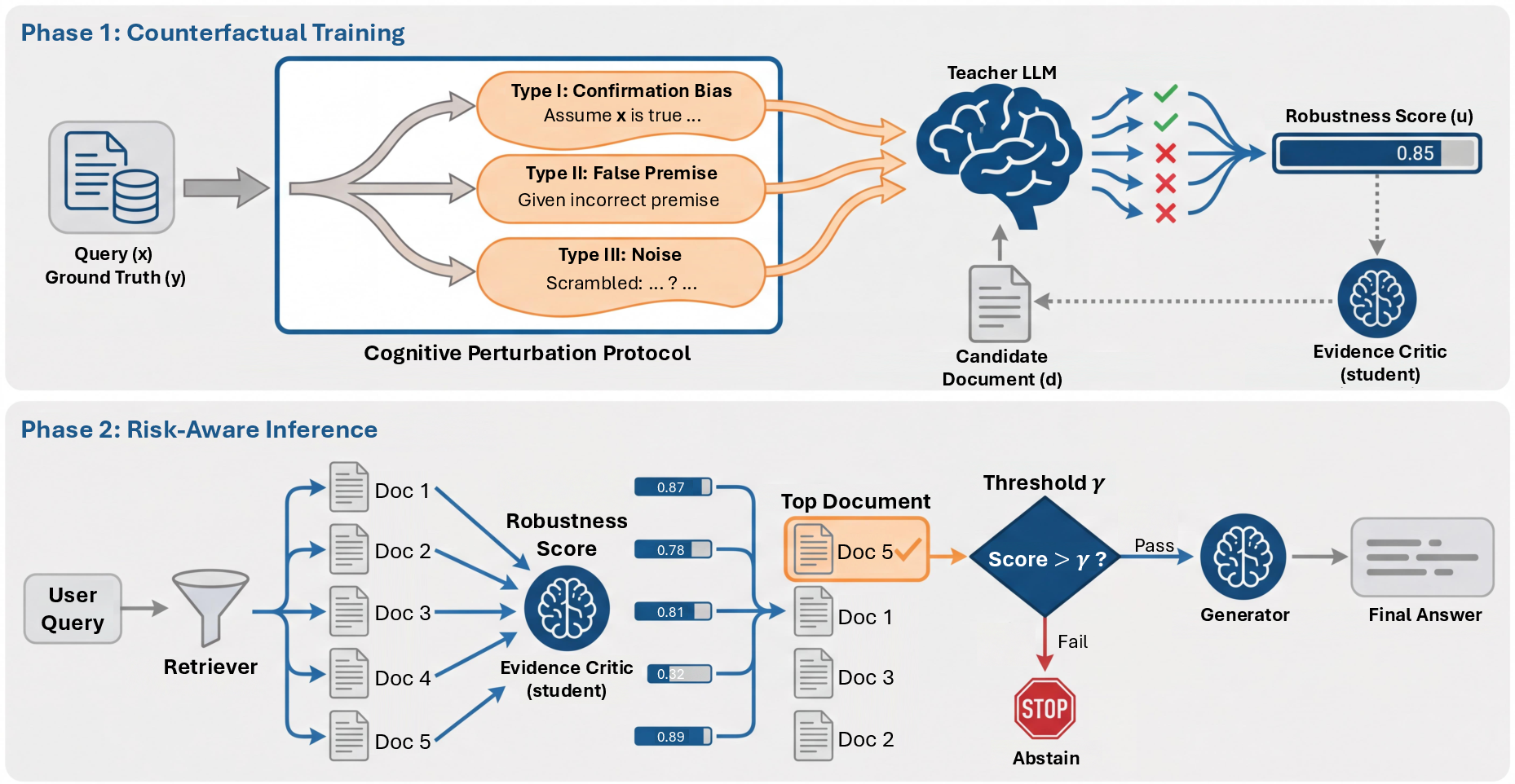
Figure 2: CoRM-RAG framework: cognitive perturbations (top) generate supervision for robust evidence, distilled into the Evidence Critic; inference (bottom) applies risk-aware reranking and abstention.
Empirical Results
Robustness to Cognitive Perturbations
On adversarially-biased test sets (Biased-NQ, TruthfulQA), CoRM-RAG consistently outperforms strong dense retrievers (Contriever), cross-encoder rerankers (BERT large, PA-CE), and even high-latency instruction-tuned LLM rerankers (GPT-4o), achieving up to +11.7% gain in accuracy over conventional cross-encoders and a significant improvement in robustness gap (1.3) compared to LLM baselines and previous risk-aware frameworks (Self-RAG, CalibRAG).
Cross-generator generalization experiments demonstrate the transferability of robustness utility encoded by the Evidence Critic: the same reranker trained on Qwen-3 evidence evaluations maintains a clear lead when deployed on unseen Llama-3 and GPT-4o generators. This result supports the assertion that the robustness signal captures universal causal-explanatory characteristics of evidence rather than overfitting to teacher-specific heuristics.
Coverage-Calibrated Risk Abstention
By tuning the abstention threshold δ2, the system operationalizes a risk-coverage trade-off. CoRM-RAG's selective accuracy increases monotonically as coverage decreases; abstaining on the lowest-confidence deciles removes nearly all hallucinations, sharply contrasting with baseline cross-encoders where high semantic similarity does not correlate with correctness under adversarial conditions (Figure 3).
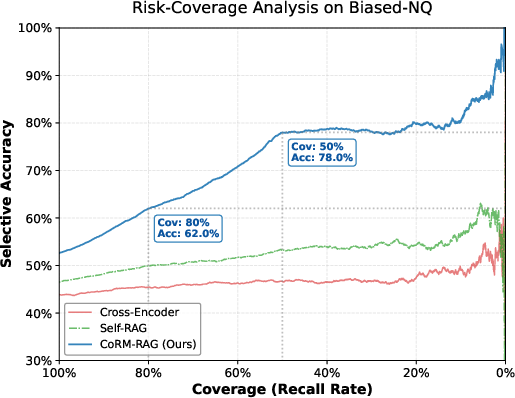
Figure 3: CoRM-RAG's risk-coverage curve: selective prediction (by robustness score) sharply improves accuracy, revealing reliable uncertainty estimation and robust abstention.
Retrieval Quality and the Relevance-Robustness Gap
Analysis of retrieval depth reveals the buried truth effect: corrective documents frequently lack substantial lexical overlap with adversarially biased queries and are thus initially ranked low by standard dense retrievers. CoRM-RAG can successfully rerank and recover these buried gold passages, yielding a +11.8% Recall@1 boost relative to cross-encoders. Pairwise rank analysis shows CoRM-RAG surfaces gold evidence higher in 45.7% of cases, substantially mitigating the echo-chamber failure mode (Figure 4).
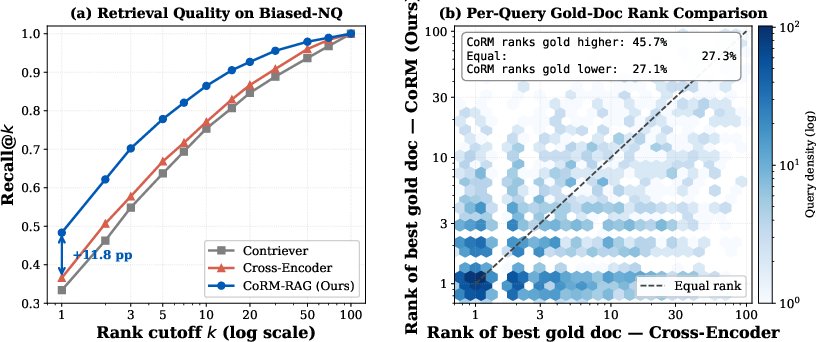
Figure 4: (a) Recall@k shows CoRM-RAG's superior ability to surface gold documents; (b) Paired rank comparison highlights its effectiveness in adversarial scenarios.
Ablation and Hyperparameter Analyses
A systematic ablation removing each perturbation type from training causes type-specific robustness collapses, confirming that exposure to a broad distribution of cognitive errors is necessary for generalization (Figure 5).
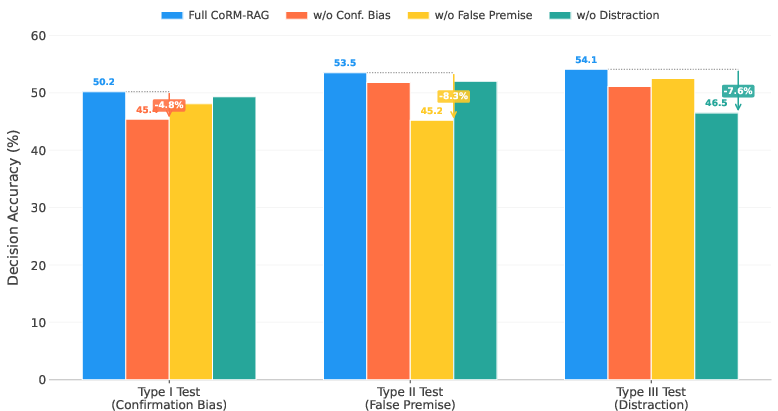
Figure 5: Confirmed orthogonality of cognitive errors—the critic requires exposure to each perturbation type for optimal robustness.
A detailed hyperparameter sweep demonstrates that increasing perturbation diversity δ3 and retrieval depth δ4 further boosts robustness—with diminishing returns—and that the distillation temperature δ5 must be carefully tuned to optimize both discriminative power and generalization (Figure 6).
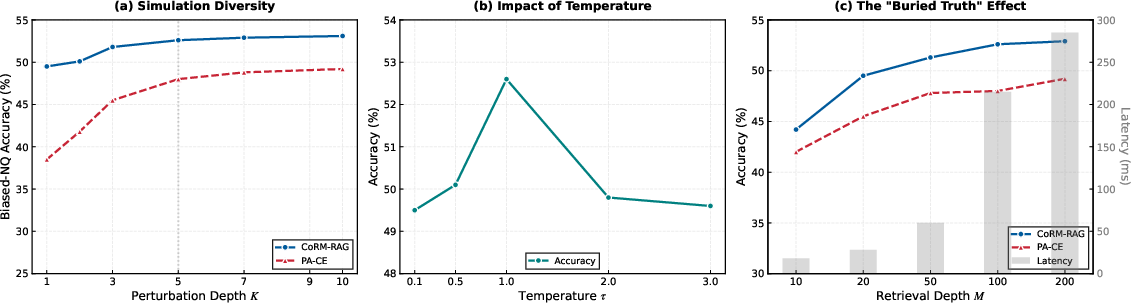
Figure 6: Hyperparameter analysis showcases the tradeoff between adversarial diversity, ranking temperature, and retrieval depth for maximal robustness.
CoRM-RAG achieves a unique Pareto optimality: its inference latency matches low-overhead cross-encoder baselines (δ6215ms), while achieving robustness and accuracy on par or superior to high-latency LLM rerankers (δ720s). This efficiency surfaces from shifting expensive counterfactual reasoning to offline training (Figure 7).
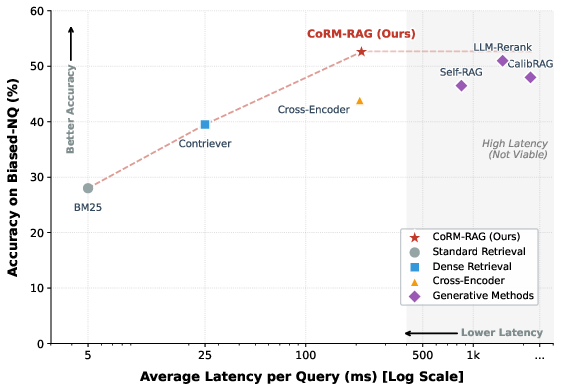
Figure 7: CoRM-RAG resolves the efficiency-performance tradeoff, matching LLM-level safety with minimal latency.
Practical and Theoretical Implications
The CRM perspective reframes RAG system design: robust evidence retrieval must be cast as a causal, counterfactual reasoning problem, rather than a semantic matching task. The implications are twofold:
- Risk-aware deployment: In medical, legal, or governance settings, confidence-calibrated abstention gates can drastically reduce fatal hallucinations and liability, providing operational transparency and safety guarantees.
- Generalization to multi-hop and agent settings: Future work can realize adaptive, personalized perturbation models and extend CRM objectives to chains of evidence, addressing path-dependent, multi-step reasoning scenarios pervasive in complex decision-making.
Conclusion
This work rigorously elucidates and operationalizes the Relevance-Robustness Gap in RAG systems. By leveraging counterfactual risk minimization with cognitive perturbation-based supervision and efficient critic distillation, CoRM-RAG robustifies retrieval in adversarially-biased environments without compromising throughput. The proposed approach disentangles semantic similarity from true evidential utility, enabling risk-aware generation and principled abstention, marking a paradigm shift from naive information matching to causality-informed, safety-critical AI system construction. Future directions include exploration of path-dependent reasoning, dynamic user adaptation, and immunological defense against adversarial user manipulations.