- The paper demonstrates that simple LLM-based rewriting reduces aggregate dense retriever bias by up to 53.9% but may only mask bias by increasing score variance.
- The study reveals that pseudo-document methods, especially with continual pretraining, achieve genuine decorrelation for brevity, literal, and position biases, though effects vary by retriever architecture.
- The findings suggest that query-side enhancements must be tailored to specific bias profiles, as certain biases remain resistant even in adversarial scenarios.
Query Rewriting and Retriever Bias Mitigation in RAG: Mechanistic and Practical Insights
Background and Motivation
Retrieval-Augmented Generation (RAG) frameworks, which leverage dense retrievers to supply relevant context to LLMs, are widely deployed for knowledge-intensive applications. However, mounting evidence demonstrates that dense retrievers systematically prefer documents based on superficial, surface-level characteristics—such as brevity, position of answer content, literal lexical overlap, and repetition of key entities—rather than prioritizing genuine semantic relevance. These biases undermine retrieval fidelity and propagate errors into generative responses. As RAG pipelines typically contain query rewriting or enhancement stages (via LLM-based reformulation or pseudo-document expansion), a critical unanswered question is whether such interventions mask or genuinely mitigate retrieval biases.
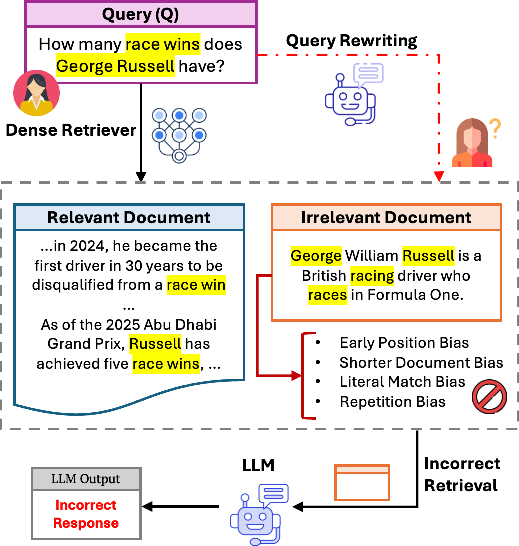
Figure 1: Dense retrievers in RAG pipelines are vulnerable to several systematic biases; this work probes whether query rewriting can alleviate these failures.
Experimental Design and Methodology
The study isolates and quantifies retrieval biases using the ColDeR benchmark, which supplies controlled document pairs differing only in a specific surface attribute while preserving factual equivalence. The four primary bias types interrogated are:
- Brevity bias: short documents are favored,
- Literal matching bias: lexical overlap between query and document is prioritized,
- Position bias: answer content appearing early in a document receives preferential scoring,
- Repetition bias: documents with repeated entity mentions are ranked higher.
Six diverse dense retrievers (Contrastive Bi-Encoders, Generative Pretraining, Token-Level Interaction) are analyzed under five distinct query enhancement strategies:
- Simple LLM-based rewriting,
- HyDE (hypothetical document replacement),
- Query2Doc (query augmentation via pseudo-documents),
- HyDE-CPT (HyDE with continual pretraining using domain data),
- Q2D-CPT (Query2Doc with continual pretraining).
Retrieval bias is measured by the mean ∣t∣-statistic over document pairs, reflecting the strength of retriever preference for biased characteristics. Complementary analyses examine feature-score correlations to distinguish variance-based bias masking from actual decorrelation.
Empirical Findings
Aggregate Bias Reduction
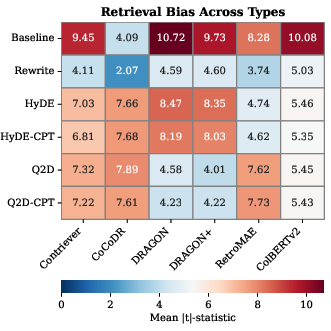
Simple LLM-based rewriting achieves the highest overall bias reduction (53.9% decrease in mean ∣t∣-statistic) across retrievers and bias types:
- Baseline: 8.72,
- Rewrite: 4.02,
- Pseudo-document methods: 6.07–6.95.
However, pseudo-document generation methods (HyDE, Query2Doc, and CPT variants) yield more modest aggregate improvements, but exhibit differential bias mitigation profiles dependent on both retriever architecture and bias type.
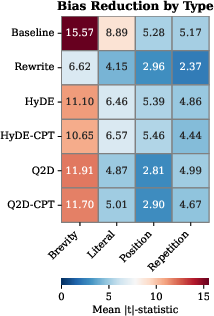
Figure 2: Mean ∣t∣-statistic by bias type and enhancement method; simple rewriting robustly reduces bias but pseudo-document methods have bias-specific effects.
Architectural and Method-Level Bias Specificity
Bias reduction is highly retriever-dependent. For instance:
Resistance of Certain Biases to Query-Side Interventions
- Brevity bias remains largely resilient to query rewriting, indicating deep embedding in document representations.
- Literal matching bias is strongly reduced by all enhancement types, while repetition bias is surprisingly resistant to pseudo-document methods but reduced by rewriting.
Adversarial and Compound Bias Scenarios
In adversarial scenarios (Foil subset), where multiple biases are combined, simple rewriting fails to provide improved accuracy. Conversely, pseudo-document and CPT approaches achieve substantial robustness, particularly for CoCoDR, where HyDE-CPT yields a 13-fold increase in accuracy (26%).
Mechanistic Analysis
Spearman correlation analyses between score features and bias-inducing attributes reveal:
- Rewriting lowers ∣t∣-statistic by increasing score variance, not by reducing sensitivity to bias features—thus masking rather than mitigating bias,
- Pseudo-document methods achieve genuine decorrelation for brevity, literal, and position biases, indicating principled bias reduction,
- All enhancement strategies increase susceptibility to repetition bias, reflecting a systematic failure mode.
Generalizability Across LLMs
Parallel experiments with Qwen3-4B-Instruct replicate the main findings observed for Gemma-3-12B-IT, confirming that enhancement mechanism trends are not artifacts of a particular LLM architecture or scale.
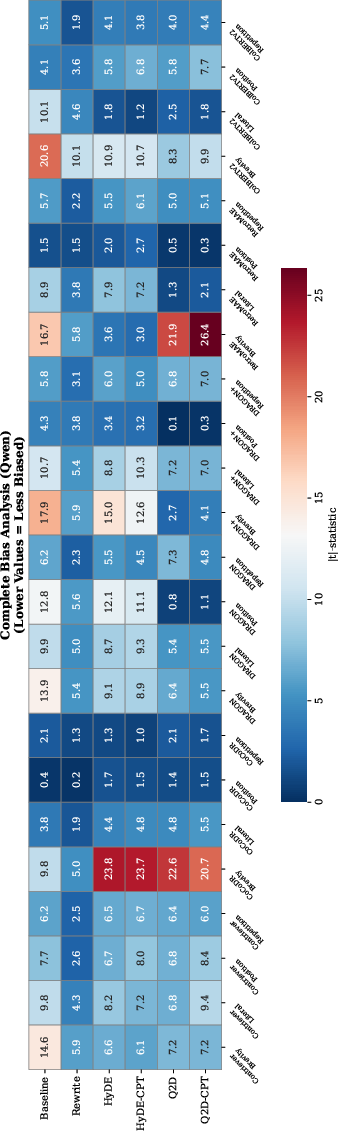
Figure 4: Complete bias analysis with Qwen3-4B-Instruct; results confirm method generalizability across LLMs.
Practical and Theoretical Implications
- Practitioners must tailor query enhancement selection to retriever architecture and bias profile. Simple rewriting is computationally cheap but unreliable in adversarial settings; pseudo-document methods (especially CPT variants) provide genuine decorrelation and are preferable for high-stakes deployment despite added complexity.
- Aggregate bias metrics can be misleading; reduction in observable bias scores may mask increased feature sensitivity. Reporting feature-score correlations is imperative for meaningful bias evaluation.
- The taxonomy established in the study distinguishes query-document interaction biases (amenable to query-side mitigation) from document encoding biases (resistant to query modifications), necessitating retriever-level intervention for the latter.
- The continuation of RAG paradigm optimization requires both improved retriever training objectives (to prioritize semantic evidence over surface heuristics) and more sophisticated query enhancement strategies that minimize introduction or reinforcement of new biases.
Conclusion
This work provides the first systematic deconstruction of the impact of query rewriting on dense retriever bias in RAG systems (2604.06097). It elucidates that while all enhancement methods reduce aggregate bias metrics, only pseudo-document generation with continual pretraining achieves robust mitigation through decorrelation. Simple rewriting, despite strong aggregate improvements, fails in adversarial scenarios and increases feature sensitivity, thereby masking underlying bias. The findings demand that researchers and practitioners transcend aggregate bias metrics, adopt feature-level correlation analyses, and exercise fine-grained strategy selection based on bias taxonomy and retriever architecture. The continued evolution of RAG must focus on engineering retrieval pipelines that are robust to superficial document and query characteristics and prioritize true semantic relevance.