- The paper demonstrates that adaptive RAG systems suffer from retrieval-decision flip rates over 50% under subtle human query variations.
- It shows that minor query perturbations, such as spelling errors or stylistic shifts, can cause answer accuracy drops of 10-20 percentage points.
- The study highlights that increasing LLM size does not improve robustness, pointing to a need for novel training strategies to stabilize multi-hop reasoning.
Robustness of Adaptive Retrieval-Augmented Generation to Query Variations
Introduction
Adaptive Retrieval-Augmented Generation (RAG) architectures dynamically determine when and how to perform retrieval during LLM inference, optimizing for both accuracy and computational efficiency. Despite the prevalence of adaptive RAG systems in production, the stability of these architectures in the face of real-world query variability—where differently phrased questions have identical intent—remains insufficiently explored. This paper, "How You Ask Matters! Adaptive RAG Robustness to Query Variations" (2604.10745), presents a systematic evaluation of adaptive RAG robustness under extensive, controlled query variations, revealing key failures in consistency, answer quality, and computational allocation.
Benchmark and Experimental Protocol
The authors construct a large-scale benchmark consisting of 27,000 QA instances across six prominent QA tasks, covering both single-hop and multi-hop reasoning. For each query, they generate six model-based query rewrites (spanning style, sentence form, and error injection) and collect two human paraphrases per question. Models analyzed include Llama-3.1-8B and QwQ-32B in both logit-based (DRAGIN) and generation-based (Search-o1) adaptive RAG settings, with both sparse (BM25) and dense (Contriever) retrieval backends.
The evaluation is organized along three orthogonal axes:
- Answer Robustness: Metrics include InAccuracy (whether the gold answer appears in the output), answer semantic similarity (SBERT-based), and output diversity across variants.
- Computation Robustness: Measured via call count statistics (retriever and LLM), with metrics such as Relative Error (RE) and coefficient-of-variation robustness (CVR).
- Retrieval Decision Robustness: Stability of retrieve/skip classifications and under-/over-confidence with respect to gold evidence requirements.
The combination of synthetic and human-driven rewrites ensures both fine-grained control and realistic coverage of user query shifts.
Impact of Query Variation on Retrieval Decision and System Stability
A core finding is the severe instability of retrieval triggers to minor query paraphrases. On meaning-preserving human rewrites, the Qwen-32B model exhibits retrieval-decision flip rates exceeding 50%, causing models to inconsistently opt for retrieval or rely solely on parametric knowledge.
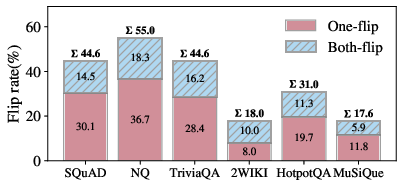
Figure 1: Retrieval-decision flip rates of Qwen-32B under meaning-preserving human rewrites; One-flip means only one rewrite causes a flip, Both-flip means both do, revealing high retrieval decision instability.
This phenomenon is decoding-invariant, persisting across a wide range of sampling temperatures. The instability propagates downstream, yielding large divergences in computational cost for queries with identical semantics, and ultimately manifesting as stochastic answer quality and efficiency.
Answer Robustness under Controlled Variations
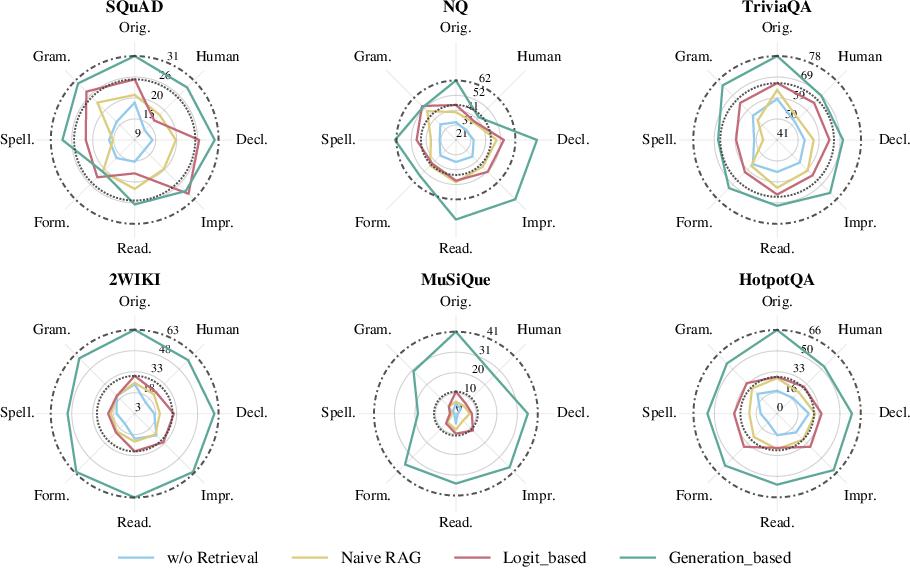
Diagnostic evaluation shows that all classes of query variation—including grammatical or spelling errors, style modifications, and sentence type changes—can precipitate marked accuracy drops. Spelling errors are particularly detrimental (accuracy drops of 10–20 percentage points are common), but even subtle stylistic shifts degrade performance measurably. Notably, these failures are not remedied by scaling LLM size.
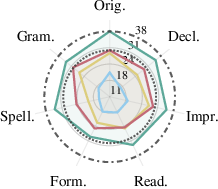
Figure 3: InAccuracy across query variations, Llama-3.1-8B on SQuAD, demonstrating accuracy is highly sensitive to surface-level changes regardless of adaptive method.
Conversely, generation-based adaptive controllers (e.g., Search-o1) are shown to deliver less stable final outputs compared to logit-based controllers (e.g., DRAGIN), as measured by output semantic diversity across paraphrases. These effects persist when using dense retrieval, indicating the issue is not an artifact of lexical retrievers.
Computational Cost and Decisioning Robustness
Even for strong base models and sophisticated controllers, computation robustness is poor: relative error in retriever/LLM invocation across equivalents is much higher for complex QA tasks (e.g., 2WikiMultiHopQA), and is exacerbated by low-fidelity input variants. Critically, high accuracy in some settings does not align with high computation robustness—more performant models are not more stable in their computational pathways.
Multi-hop Adaptive RAG variants demonstrate that semantic drift in generated subqueries (across hops) caused by surface variation propagates to evidence chain collapse, often resulting in top-k retrieved sets failing to recover any gold supporting document in later hops (retrieval failure rate increases with hop index).
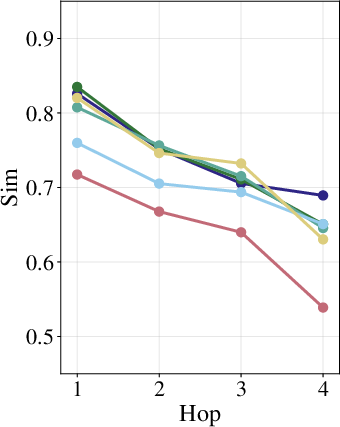
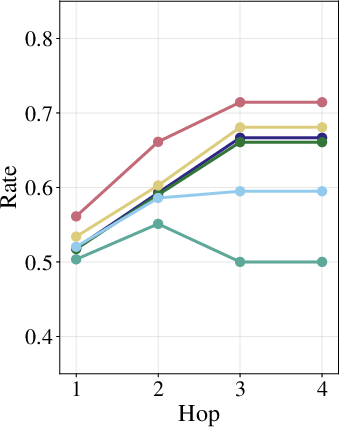
Figure 2: Subquery drift increases with each multi-hop step, and retrieval failures (missing gold documents) rise as subqueries diverge more under query perturbations.
Human-Authored Query Variation: A Realistic Vulnerability
Human rewrites, although semantically faithful, exacerbate robustness issues. They are typically shorter, more compressed, and less likely to contain explicit lexical cues, resulting in:
In direct causal analysis, shorter or more ambiguous phrasings increase the instability of intermediate retrieval substeps, which in turn raises failure rates for critical evidence lookup and reduces end-to-end answer accuracy.
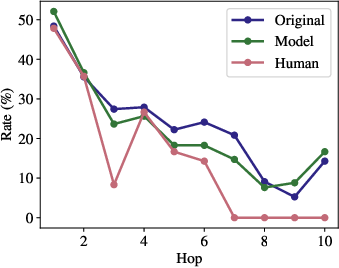
Figure 8: Gold document inclusion rate by hop on 2WikiMultiHopQA; human rewrites sharply decrease gold-hit probability in later reasoning hops.
Under- and Over-Confidence Analysis
Query errors, especially spelling and grammar perturbations, inflate over-confidence, wherein the model erroneously skips retrieval when it is required for answer correctness, causing otherwise answerable queries to become ungrounded and factually incorrect.

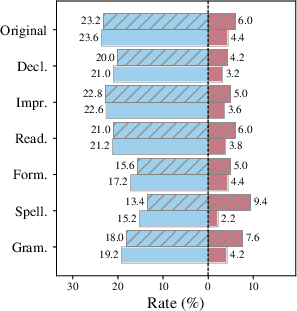
Figure 4: Under- and over-confidence rates (model query variations), showing increased over-confidence for noisier queries, particularly with larger LMs.
Theoretical and Practical Implications
The results have several important implications:
- Model size alone does not yield improved robustness to query variation within Adaptive RAG: scaling LLMs fails to solve retrieval instability.
- Surface-level equivalence is not preserved: All tested adaptive architectures are highly brittle, even to controlled, non-adversarial paraphrases.
- Human-authored variations expose a realism gap: Synthetic benchmarks understate the robustness problem—human-authored queries degrade performance at rates comparable to or worse than engineered typos.
- Intermediate reasoning is a major failure point: In multi-hop Adaptive RAG, even semantically equivalent subquery drift compounds downstream, inducing systematic evidence miss and accuracy collapse.
These findings indicate that naive robustness assumptions for deployed RAG architectures (e.g., assuming LLM or retrieval scaling will deliver input-invariant processing) are unsafe, particularly in high-stakes domains where factuality and reliability are requirements.
Future Directions
Promising future research trajectories inspired by these findings include:
- Robust training regimes incorporating diverse paraphrase augmentation, uncertainty calibration, and retrieval-triggering regularization.
- Fine-grained user query modeling to more accurately simulate the variety and compressive tendencies of real-world prompting.
- Intermediate state consistency metrics that directly regularize the full reasoning/evidence chain in multi-hop QA, not just final answer correctness.
- Adaptive architectures that incorporate robust self-knowledge or explicit verification at each retrieval step, reducing cascade failures.
- Cross-lingual and domain expansion to evaluate whether similar brittleness manifests in non-English and specialized settings.
Conclusion
This work demonstrates that current adaptive RAG architectures are fundamentally fragile to realistic query variation, with practical consequences for reliability in open-domain and high-precision retrieval-augmented reasoning systems. Robustness cannot be assumed, and the development of explicitly stability-aware adaptive controllers remains an unsolved challenge.