- The paper demonstrates that the DoTS framework decouples and integrates SFT and RLVR task vectors while mitigating catastrophic forgetting through calibrated sparsification and Bayesian optimization.
- It quantifies a 30× magnitude disparity and 45% sign interference between the task vectors, underscoring the need for conflict-aware parameter synthesis.
- The approach achieves competitive performance on mathematical reasoning benchmarks with significantly lower computational cost and minimal adaptation queries.
Decoupled Test-time Synthesis of SFT and RLVR Task Vectors for LLM Post-training Integration
Introduction and Motivation
Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR) represent central paradigms for post-training LLMs. SFT is designed to enhance knowledge breadth via direct supervision, whereas RLVR amplifies reasoning depth by leveraging iterative, verifiable feedback. Despite their complementary strengths, integrating SFT and RLVR into a unified model without loss of capability has proven to be non-trivial. The two dominant approaches—sequential training and joint optimization—routinely fail due to catastrophic forgetting or severe gradient conflicts.
This work provides a structural analysis of the parameter-space differences (task vectors) induced by SFT and RLVR. It identifies three principal sources of integration failure: (i) an approximate 30× magnitude disparity between SFT and RLVR task vectors, (ii) ∼45% sign interference—i.e., parameters updated in conflicting directions, and (iii) heterogeneous distributions of task-relevant updates across modules. These findings imply direct merging or training-based integration is fundamentally hampered by deep parameter-space incompatibilities, but also reveal the complementary nature of each paradigm's modifications.
Empirical Task Vector Analysis
The paper formalizes task vectors as the elementwise difference between post-trained and base model weights. The analysis, exemplified on Qwen2.5-Math-7B, surfaces three defining structural characteristics:
- Magnitude Disparity: The L2 norm of the SFT task vector across layers is roughly 30 times larger than RLVR. In naive linear combinations, SFT therefore dominates, effectively muting RLVR-introduced reasoning capabilities.
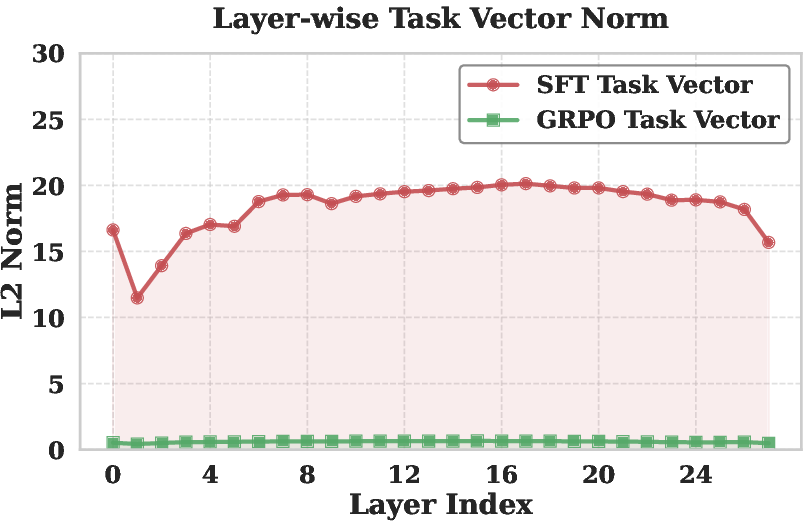
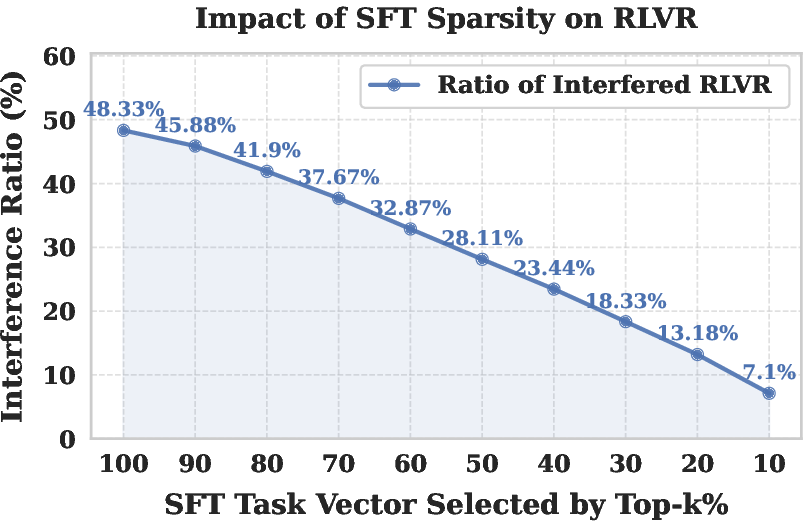
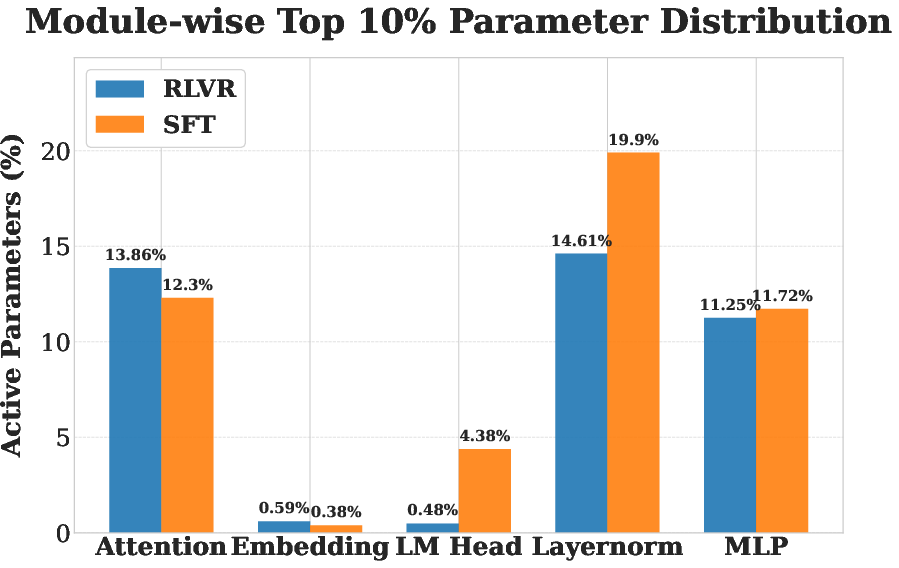
Figure 1: Layer-wise L2 norms of SFT and RLVR task vectors showing the pronounced magnitude gap.
- Sign Interference: A direct comparison of task vector entries shows 44.91% sign disagreement without processing, meaning these updates point in opposite directions. This persistent, parameter-wise conflict accounts for substantial gradient antagonism in joint optimization.
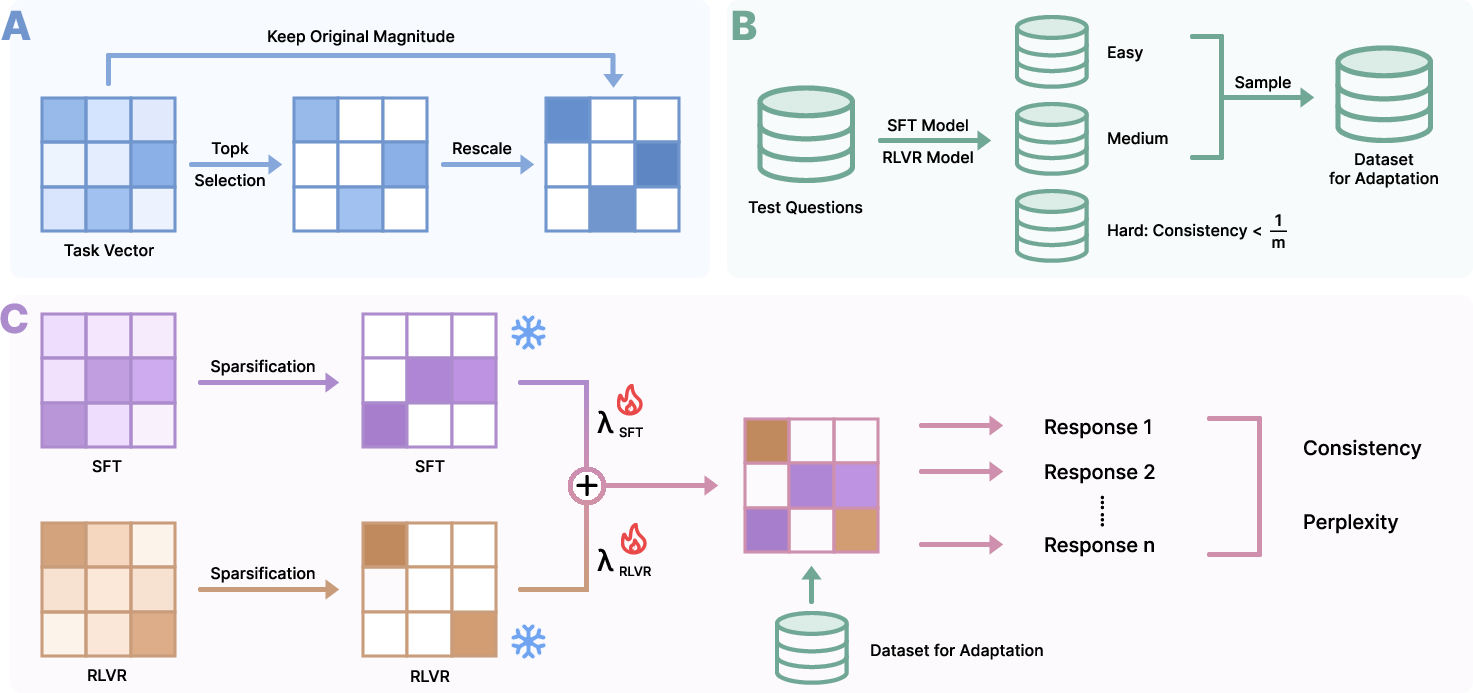
Figure 2: Impact of SFT sparsification on sign interference; pruning reduces sign conflicts from nearly 45% to 7.1% among nonzero entries.
- Heterogeneous Module-wise Updates: Analysis of the top-k% (e.g., top-10%) largest updates reveals that SFT concentrates on LayerNorm parameters, while RLVR distributes its changes over attention, LayerNorm, and the LM head, with little direct overlap.
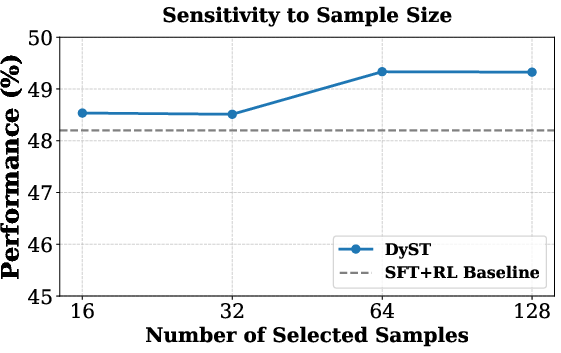
Figure 3: Distribution of significant parameter updates across modules; SFT and RLVR target complementary structures.
These findings indicate that SFT and RLVR bring distinct, module-targeted capacities, and naive parameter-space integration is not feasible without specialized procedures that address interference and balance scale.
DoTS: Decoupled Test-time Synthesis Framework
To exploit the complementarity without joint retraining, the authors introduce Decoupled Test-time Synthesis (DoTS), a post-hoc integration framework. The core insight is to avoid parameter updates during integration, and instead compose independently trained SFT and RLVR checkpoints via calibrated task-vector arithmetic, with minimal computational overhead.
The DoTS workflow comprises three stages:
- Selective Sparsification: Top-k% of each task vector (by absolute magnitude) is retained and rescaled to preserve the original L2 norm, targeting high-signal, low-interference directions and reducing sign conflicts from ~45% to single digits.
- Difficulty-Aware Data Selection: Rather than leveraging all evaluation queries, a small, unlabeled, adaptively sampled set is constructed, stratified by the consistency (stability) of SFT/RLVR model outputs. This set provides an informative signal for synthesis coefficient optimization.
- Bayesian Coefficient Optimization: The sparsified SFT and RLVR task vectors are combined via two scalars λSFT,λRLVR, optimized by black-box Bayesian search to simultaneously maximize answer consistency and minimize perplexity on the adaptation set.
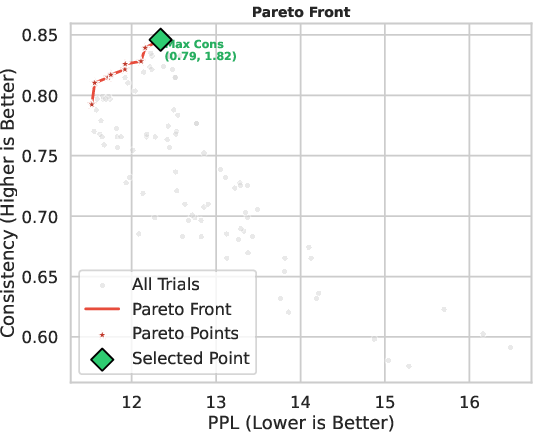
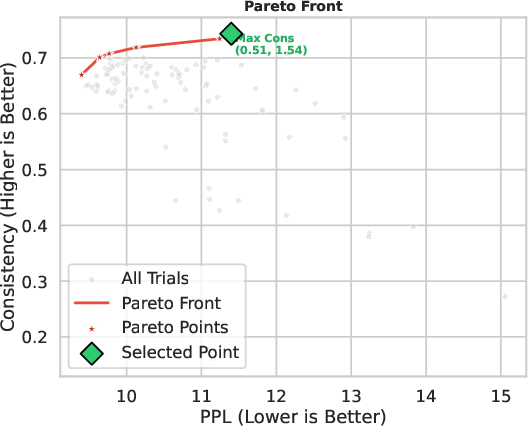
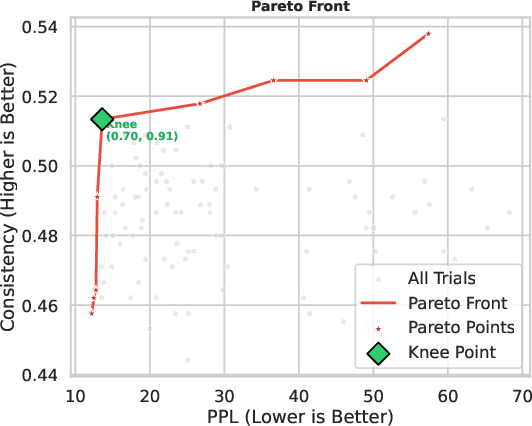
Figure 4: Overview of the DoTS framework illustrating its three functional components.
Experimental Results
Integration Quality vs. Training-based Methods
On Qwen2.5-Math-7B, DoTS not only matches but often exceeds the performance of strong training-based SFT-RLVR integration baselines (e.g., LUFFY, SFT+RL) on a suite of mathematical reasoning benchmarks, with an average score improvement of 1.4–2.7 points in various configurations. Notably, DoTS achieves this with only ∼3% of the computational cost and 64 unlabeled adaptation queries (vs. tens of thousands required for training-based methods).
Merging Robustness
Contrary to standard model-merging methods (e.g., TIES-Merging, DARE), which are designed for more homogeneous task vectors and fail in the presence of large scale and sign misalignments, DoTS delivers reliably high synthesis performance across mathematical reasoning and out-of-domain QA (e.g., ARC-C, GPQA, MMLU-Pro) benchmarks.
Transferability
The coefficients optimized using mathematics queries transfer directly to diverse QA benchmarks without re-tuning, evidencing that DoTS learns a generalizable mode of capability fusion not overfit to the adaptation domain.
Ablation Studies and Efficiency
Ablations show the necessity of each DoTS component: removal of sparsification or use of fixed coefficients degrades final performance by up to 3 points. Notably, DoTS is robust to adaptation set size, saturating its benefit with as few as 16–64 unlabeled data points.
DoTS requires only ∼20 GPU hours, compared to 600–1,000+ GPU hours for iterative retraining in SFT+RLVR integration.
Theoretical and Practical Implications
The DoTS framework demonstrates that test-time functional composition of SFT and RLVR via conflict-aware, sparsified task-vector arithmetic can reliably synthesize heterogeneous capabilities. This suggests future work should consider parameter-space structure and cross-module alignment when merging models trained on conflicting objectives. The methodology highlights that much of the difficulty in LLM post-training integration is intrinsic to the geometry of downstream adaptation, not merely imperfect training schedules.
Practically, DoTS enables rapid, low-resource fusion of capabilities by leveraging existing checkpoints and a small set of queries, particularly essential for production deployments where full retraining is infeasible.
Outlook
This work opens directions for advanced synthesis strategies—for example, learning layer-wise or module-wise scalar coefficients, or extending analysis to open-ended generation and novel tool-use tasks. Moreover, the structural analysis methodology generalizes to model merging scenarios involving even more heterogeneous paradigms.
Conclusion
DoTS establishes a new paradigm in LLM post-training: rather than forcing incompatible objectives into joint optimization, it advocates decoupling and parameter-space synthesis at test time, using conflict-aware sparsification and minimal label-free adaptation. This approach empirically matches or surpasses traditional training-based integration with significantly higher efficiency and transfer potential, delivering both theoretical and practical advance for robust LLM capability integration (2605.00610).